La progettazione del database è uno dei fattori più importanti che contribuiscono alle prestazioni di un'applicazione. Di conseguenza, il modo in cui il database è progettato è della massima importanza. La progettazione del database consiste nell'organizzazione efficiente dei dati in base ai flussi di lavoro dei prodotti, alla roadmap futura e ai modelli di utilizzo previsti.
L'output di un esercizio di progettazione di database è un modello di dati. Un modello dati rappresenta tutti gli oggetti, entità, attributi, relazioni e vincoli nel sistema. In generale, i modelli di dati possono essere di due tipi:logici o fisico . La rappresentazione del modello dati viene eseguita creando un diagramma ER, noto anche come diagramma di relazione entità, diagramma ERD o diagramma di database.
Il modello fisico dei dati si riferisce ai dettagli di implementazione effettivi nel database. Il modello logico dei dati, d'altra parte, astrae gli aspetti tecnici dell'implementazione. Ciò rende il modello di dati logici utilizzabile per l'azienda. Una differenza fondamentale tra i due modelli è che il modello logico è indipendente dal database mentre il modello fisico deve essere specifico per il database in uso.
La corretta progettazione del database è spesso sottovalutata e trascurata durante lo sviluppo dell'applicazione. Il costo di questa negligenza si realizza di solito molto più tardi quando arrivano nuove funzionalità dell'applicazione o quando le vecchie funzionalità richiedono modifiche. Questo è quando la progettazione del database cessa di avere senso. Sebbene non sia possibile rendere a prova di futuro la progettazione di un database, è assolutamente possibile fare lo sforzo di comprendere al meglio i casi d'uso aziendali e progettare il database di conseguenza. Ulteriori informazioni sui suggerimenti per una migliore progettazione del database qui.
Con questo in mente, esaminiamo i passaggi nella progettazione del database.
Fase 1:raccogli i requisiti aziendali
Il primo passo è parlare con l'azienda delle loro esigenze. Se la conversazione è efficace, dovrebbe fornire informazioni sufficienti per iniziare a lavorare su un modello di dati concettuale, che è un'astrazione del modello logico. Parlare con l'azienda, prima di tutto, fornisce un quadro completo dei processi aziendali, che, a sua volta, fornisce informazioni sui vari punti dati che sono importanti per l'azienda da acquisire e monitorare. Ad esempio, in un modello di prenotazione taxi, vale la pena porre le seguenti domande:
- L'azienda desidera i dati di tracciamento del veicolo nel database indipendentemente dal fatto che ci sia un viaggio attivo o meno? Se sì, allora il campo
vehicle_trip_idnella tabellavehicle_tripssarebbe annullabile . In caso contrario, non sarà annullabile . - L'azienda desidera la cronologia delle modifiche a
trip_statusmemorizzato nel database? Se sì, allora ogni volta iltrip_statusmodifiche, ci sarà un altro record neitripstavolo. Altrimenti, ogni volta iltrip_statusmodifiche,trip_statusverrà aggiornato sul posto.
Come mostrato in questo esempio, in base agli input dell'azienda, si finirebbe per scegliere un'opzione rispetto all'altra. Ciò comporterebbe la modifica delle entità interessate e delle loro relazioni.
La raccolta dei requisiti generalmente implica anche l'avvio di una conversazione sulla sicurezza dei dati, ad esempio quali dati devono essere mascherati e crittografati. L'esercizio di raccolta dei requisiti si traduce in un documento dei requisiti spesso supportato da una bozza di lavoro del modello di dati concettuali.
Fase 2:Comprendi la Roadmap aziendale
Le aziende cambiano continuamente i loro processi; la loro capacità di adattamento li rende meno propensi a fallire. Cambiare i processi aziendali significa cambiare i flussi di lavoro e i modelli di dati. Sebbene non sia possibile conoscere questi cambiamenti con largo anticipo, è sicuramente possibile essere aggiornati sulla roadmap aziendale.
Ad esempio, se un'azienda ha in programma di puntare a una nuova regione geografica, il modello dovrebbe soddisfare il supporto linguistico, le valute, i fusi orari e così via. I vantaggi della comprensione della roadmap aziendale a lungo termine si manifestano spesso in una transizione più agevole verso nuovi processi aziendali.
Consentitemi di condividere un altro esempio, che riguarda maggiormente le priorità aziendali in continua evoluzione. L'attività dei taxi è stata gravemente colpita all'inizio del COVID-19. Come compagnia di taxi, vuoi agire preventivamente per assicurare alle persone che stai facendo di tutto per assicurarti che il tuo viaggio in cabina sia il più sicuro possibile, che il veicolo sia disinfettato ogni giorno, che l'autista indossi una maschera volte e che ci sia un disinfettante per le mani disponibile in cabina. Ora, per acquisire tutte queste informazioni, passa a due entità, drivers e vehicles , sarebbe richiesto. Diversi campi flag booleani devono essere aggiunti a queste entità per soddisfare questo caso d'uso aziendale.
Fase 3:Identifica entità e attributi
Una volta raccolti i requisiti aziendali, le informazioni possono essere utilizzate per identificare le entità insieme all'insieme essenziale di attributi. Una o più entità generalmente si associano direttamente ai processi aziendali e anche la relazione tra tali entità imita il flusso di lavoro dei processi aziendali.
Questo passaggio viene utilizzato anche per identificare quali attributi fungeranno da identificatori nelle entità. Gli identificatori si traducono in chiavi primarie nel modello fisico. Inoltre, in questo passaggio è anche comune specificare i tipi di dati per tutti gli attributi.
Ad esempio, nel modello di prenotazione taxi, dovresti identificare gli attributi che fungeranno da campi obbligatori per la registrazione di utenti e conducenti dall'app di prenotazione. La registrazione dell'utente verrà effettuata utilizzando user_phone e la registrazione del conducente verrebbe eseguita utilizzando driver_phone .
Allo stesso modo, altre entità e attributi vengono identificati durante questo passaggio, dopo essere stati mappati ai flussi di lavoro dei processi aziendali.
Fase 4:Identifica le relazioni
Dopo aver identificato le entità e i loro attributi, il passaggio successivo consiste nel definire le relazioni tra le entità in base ai flussi di lavoro aziendali che sono stati documentati nella fase di raccolta dei requisiti. Oltre a stabilire che esiste una relazione tra due entità, è anche importante identificare quale dei seguenti quattro tipi di relazione esiste tra di loro. Considera due entità arbitrarie, A e B:
- Uno a uno → Un record in A corrisponde al massimo a un record in B.
- Uno a molti → Un record in A corrisponde a molti record in B.
- Molti a uno → Molti record in A corrispondono al massimo a un record in B.
- Molti a molti → Molti record in A corrispondono a molti record in B.
Nel modello di prenotazione taxi è stato utilizzato un solo tipo di relazione, ovvero uno a molti. Prendi la relazione tra users e trips come esempio. Nel modello si presuppone che un solo utente possa essere correlato a un viaggio, il che implica che non ci sono taxi condivisi o in pool. Ma se ci fossero taxi condivisi o in pool, ci sarebbe stata probabilmente una relazione molti-a-molti tra gli users e trips , se molti utenti hanno condiviso lo stesso trip_id .
Fase 5:crea un diagramma ER logico
Con entità, attributi e relazioni di entità definite, il passaggio successivo immediato è disegnare il diagramma ER. Tutti i passaggi sopra elencati possono essere eseguiti all'interno di Vertabelo. Non ci sono regole rigide per il modo in cui dovrebbe essere eseguita la modellazione logica, con la possibile eccezione della notazione di riferimento.
Ad esempio, dai un'occhiata al seguente esempio di diagramma ER logico. Cattura un semplice flusso di lavoro aziendale di un'azienda di taxi, in cui un utente può prenotare una corsa con la possibilità di tracciare il veicolo.
Fase 6:convalida del diagramma ER logico
La modellazione logica è un processo in cui molte informazioni aziendali devono essere tradotte in un progetto di database. Senza controlli approfonditi, questa fase di sviluppo del database è soggetta a errori che possono rivelarsi piuttosto costosi in una fase successiva.
Per occuparsi di questo, Vertabelo ha un elenco completo di controlli che possono essere eseguiti su un modello logico. I controlli possono essere eseguiti in tutte le granularità, dal modello nel suo insieme ai singoli attributi e tutto il resto. Alcuni dei semplici controlli sono:
- Nomi di entità, attributi, relazioni, ecc., non possono essere nulli e devono essere univoci.
- Un'entità deve avere almeno 1 attributo.
- Gli identificatori (PK) devono essere definiti per ogni entità.
- Il modello deve utilizzare uno dei tipi di dati elencati per gli attributi.
Tutti questi controlli sono facoltativi e possono essere configurati per essere ignorati, se è disponibile un altro framework di convalida. La corretta convalida da parte di Vertabelo ti aiuta a passare al passaggio successivo con il minimo attrito possibile.
Fase 7:crea un diagramma ER fisico
Una volta creato il diagramma ER logico, il passaggio successivo consiste nel creare un modello di dati fisici. Il modello di dati fisico sarà specifico del database in cui si desidera distribuire il modello di dati. Tutti i database hanno la loro implementazione unica di regole di nomenclatura, tipi di dati e vincoli. Per questo motivo, il Data Definition Language (DDL) spesso differisce da un database all'altro.
Per creare un modello di dati fisico, procedi nel seguente modo:
- Trova il tipo di dati più vicino nel database di destinazione per sostituire il tipo di dati generico selezionato nel modello di dati logici.
- Segui le regole di nomenclatura per tabelle, colonne e vincoli come prescritto dal database di destinazione.
- Modifica il modello per allinearlo ai flussi di lavoro di query predefiniti. Ciò si traduce generalmente in un aumento della ridondanza per salvare i join.
- Infine, puoi creare indici, partizioni, chiavi di distribuzione e chiavi di ordinamento. Questo è il momento in cui puoi creare modifiche al modello per migliorare le prestazioni.
Questi passaggi possono essere eseguiti utilizzando qualsiasi strumento di modellazione dei dati che puoi utilizzare per creare un modello di dati da zero. Tuttavia, Vertabelo ha un'opzione per convertire un modello di dati logico in un modello di dati fisici a tutti gli effetti per tutti i principali sistemi di database come MySQL, PostgreSQL, Oracle, Microsoft SQL Server, Amazon Redshift, Google BigQuery e altri. Una volta che il modello di dati logici è stato convertito in un modello di dati fisico, puoi continuare con i quattro passaggi discussi.
Vertabelo ha anche un'opzione per aggiungere script pre e post-distribuzione a livello di tabella insieme a eventuali commenti a livello molto granulare del modello. I commenti risultano utili quando viene utilizzata la funzione di generazione della documentazione offerta da Vertabelo. Il documento del database può essere esportato in uno dei seguenti tre formati:HTML, PDF o DOCX.
Continuando con l'esempio di prenotazione del taxi, diamo un'occhiata al modello di dati fisico generato da Vertabelo.
Fase 8:convalida del diagramma ER fisico
Proprio come il diagramma ER logico è stato convalidato, Vertabelo ha uno strumento per convalidare i diagrammi ER fisici con diversi controlli aggiuntivi, ad esempio se esistono o meno FK e se la lunghezza del nome di una tabella o di una colonna supera il limite in base al database selezionato.
Non è necessario eseguire la convalida in modo esplicito. Succede quando il diagramma viene modificato. I problemi con il modello rientrano in una delle tre categorie:errori, avvisi e suggerimenti, in ordine di gravità decrescente. C'è un articolo utile e ben scritto che parla degli errori comuni commessi durante il processo di progettazione del database.
Fase 9:risolvi i problemi con il diagramma ER fisico
I risultati della convalida possono identificare problemi che devono essere risolti. Alcuni dei problemi più comuni sono:
- Chiavi esterne mancanti in cui sono state definite relazioni di entità.
- Chiavi primarie mancanti dalle tabelle.
- Tipi di dati non supportati per il database selezionato.
Una volta risolti questi e altri problemi simili, il modello è pronto per essere esportato in uno script SQL distribuibile per il sistema di gestione del database selezionato.
Fase 10:Genera gli script DDL per la distribuzione del modello
La progettazione del database non riguarda solo la creazione di diagrammi ER. Un esercizio di modellazione dei dati che utilizza i diagrammi ER ha esito positivo solo se risulta in qualcosa di distribuibile. Vertabelo offre una comoda opzione per esportare il modello fisico in uno script SQL pronto per la distribuzione. Una volta generato, eventuali problemi in sospeso possono essere risolti direttamente nello script SQL.
Tuttavia, non è consigliabile modificare lo script SQL generato. Provoca una deriva tra il modello fisico dei dati e lo script SQL distribuito sul database, il che può anche significare una deriva tra le tabelle effettive e la documentazione del database.
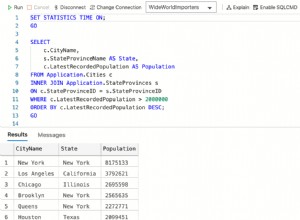
Ora che abbiamo raggiunto la fine del processo di progettazione del database, diamo un'occhiata al codice SQL generato da Vertabelo.
Condividi i tuoi pensieri
La progettazione di database è un'attività ad alto impatto nello sviluppo di software. Il campo della progettazione di database si è evoluto nel corso degli anni con nuovi modi di rappresentare il design per il business, per gli ingegneri e per gli analisti di dati. Ciò ha spesso portato a nuovi tipi di diagrammi, standard di modellazione e notazioni. Gran parte dell'evoluzione è stata trattata nella sezione sui fondamenti del design.
Saremo felici di vedere quali sono state le tue esperienze nella progettazione di database. Scrivici a contact@vertabello.com.