SQL Server ha introdotto gli oggetti OLTP in memoria in SQL Server 2014. Nella versione iniziale c'erano molte limitazioni; alcuni sono stati affrontati in SQL Server 2016 e si prevede che altri verranno affrontati nella prossima versione man mano che la funzionalità continua a evolversi. Finora, l'adozione di In-Memory OLTP non sembra molto diffusa, ma man mano che la funzionalità matura, mi aspetto che più clienti inizieranno a chiedere informazioni sull'implementazione. Come per qualsiasi modifica importante dello schema o del codice, consiglio di eseguire test approfonditi per determinare se OLTP in memoria fornirà i vantaggi previsti. Con questo in mente, ero interessato a vedere come cambiavano le prestazioni per istruzioni INSERT, UPDATE e DELETE molto semplici con OLTP in memoria. Speravo che se avessi potuto dimostrare il blocco o il blocco come un problema con le tabelle basate su disco, le tabelle in memoria avrebbero fornito una soluzione, poiché sono prive di blocco e blocco.
Ho sviluppato il seguente test casi:
- Una tabella basata su disco con stored procedure tradizionali per DML.
- Una tabella in memoria con stored procedure tradizionali per DML.
- Una tabella in memoria con procedure compilate in modo nativo per DML.
Ero interessato a confrontare le prestazioni delle procedure memorizzate tradizionali e delle procedure compilate in modo nativo, perché una restrizione di una procedura compilata in modo nativo è che tutte le tabelle a cui si fa riferimento devono essere in memoria. Sebbene le modifiche singole e a riga singola possano essere comuni in alcuni sistemi, vedo spesso modifiche che si verificano all'interno di una procedura memorizzata più ampia con più istruzioni (SELECT e DML) che accedono a una o più tabelle. La documentazione In-Memory OLTP consiglia vivamente di utilizzare procedure compilate in modo nativo per ottenere il massimo vantaggio in termini di prestazioni. Volevo capire quanto ha migliorato le prestazioni.
L'allestimento
Ho creato un database con un filegroup ottimizzato per la memoria e quindi ho creato tre diverse tabelle nel database (una basata su disco, due in memoria):
- Tabella Disco
- InMemory_Temp1
- InMemory_Temp2
Il DDL era quasi lo stesso per tutti gli oggetti, tenendo conto del su disco rispetto a quello in memoria, ove appropriato. DiskTable DDL e DDL in memoria:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Ho anche creato nove stored procedure, una per ogni combinazione tabella/modifica.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Aggiorna
- InMemRegularSP _Elimina
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Ogni procedura memorizzata ha accettato un input intero per eseguire il ciclo per quel numero di modifiche. Le procedure memorizzate seguivano lo stesso formato, le variazioni riguardavano solo la tabella a cui si accedeva e se l'oggetto era compilato in modo nativo o meno. Il codice completo per creare il database e gli oggetti può essere trovato qui, con esempi di istruzioni INSERT e UPDATE di seguito:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Nota:le tabelle IDs_* sono state ripopolate dopo il completamento di ogni serie di INSERT ed erano specifiche per i tre diversi scenari.
Metodologia di prova
Il test è stato eseguito utilizzando script .cmd che utilizzavano sqlcmd per chiamare uno script che eseguiva la procedura memorizzata, ad esempio:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"exit
Ho usato questo approccio per creare una o più connessioni al database che sarebbero state eseguite contemporaneamente. Oltre a comprendere le modifiche di base alle prestazioni, volevo anche esaminare l'effetto di diversi carichi di lavoro. Questi script sono stati avviati da una macchina separata per eliminare il sovraccarico delle connessioni istanziate. Ogni stored procedure è stata eseguita 1000 volte da una connessione e ho testato 1 connessione, 10 connessioni e 100 connessioni (rispettivamente 1000, 10000 e 100000). Ho acquisito le metriche delle prestazioni utilizzando Query Store e ho anche acquisito le statistiche di attesa. Con Query Store ho potuto acquisire la durata media e la CPU per ogni stored procedure. I dati delle statistiche di attesa sono stati acquisiti per ogni connessione utilizzando dm_exec_session_wait_stats, quindi aggregati per l'intero test.
Ho eseguito ogni test quattro volte e quindi ho calcolato le medie complessive per i dati utilizzati in questo post. Gli script utilizzati per il test del carico di lavoro possono essere scaricati da qui.
Risultati
Come si poteva prevedere, le prestazioni con gli oggetti in memoria erano migliori rispetto agli oggetti basati su disco. Tuttavia, una tabella in memoria con una procedura memorizzata regolare a volte aveva prestazioni comparabili o solo leggermente migliori rispetto a una tabella basata su disco con una procedura memorizzata regolare. Ricorda:ero interessato a capire se avessi davvero bisogno di una stored procedure compilata per ottenere un grande vantaggio con una tabella in memoria. Per questo scenario, l'ho fatto. In tutti i casi, la tabella in memoria con la procedura compilata in modo nativo ha avuto prestazioni significativamente migliori. I due grafici seguenti mostrano gli stessi dati, ma con scale diverse per l'asse x, per dimostrare che le prestazioni per le procedure archiviate regolari che modificano i dati sono peggiorate con più connessioni simultanee.
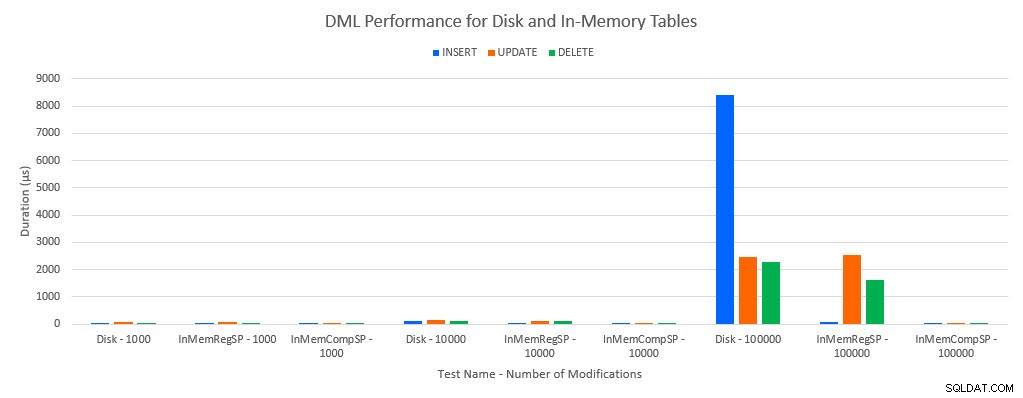
Prestazioni DML per test e carico di lavoro
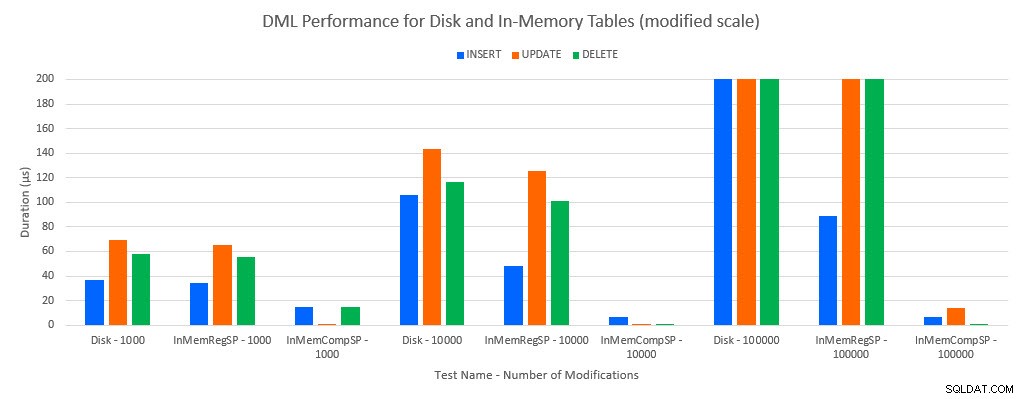
Prestazioni DML per test e carico di lavoro [scala modificata]
L'eccezione è INSERT nella tabella In-Memory con la normale procedura memorizzata. Con 100 connessioni la durata media è di oltre 8 ms per una tabella basata su disco, ma inferiore a 100 microsecondi per la tabella In-Memory. Il motivo probabile è l'assenza di blocco e latch con la tabella In-Memory, e questo è supportato con i dati delle statistiche di attesa:
| Test | INSERIRE | AGGIORNAMENTO | ELIMINA |
|---|---|---|---|
| Tabella Disco – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Tabella Disco – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10.000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Tabella Disco – 100.000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
Attesa statistiche per test
I dati delle statistiche di attesa sono elencati qui in base al tempo di attesa totale delle risorse (che generalmente si è tradotto anche nel tempo medio più alto delle risorse, ma c'erano delle eccezioni). Il tipo di attesa WRITELOG è il fattore limitante in questo sistema per la maggior parte del tempo. Tuttavia, PAGELATCH_EX attende 100 connessioni simultanee che eseguono istruzioni INSERT suggerisce che con un carico aggiuntivo il comportamento di blocco e latch che esiste con le tabelle basate su disco potrebbe essere un fattore limitante. Negli scenari UPDATE ed DELETE con 10 e 100 connessioni per i test delle tabelle basate su disco, il tempo di attesa medio delle risorse era più alto per i blocchi (LCK_M_X).
Conclusione
In-Memory OLTP può assolutamente fornire un aumento delle prestazioni per il giusto carico di lavoro. Gli esempi qui testati, tuttavia, sono estremamente semplici e non dovrebbero essere giudicati solo come motivo per migrare a una soluzione In-Memory. Esistono ancora più limitazioni che devono essere considerate ed è necessario eseguire test approfonditi prima che si verifichi una migrazione (in particolare perché la migrazione a una tabella in memoria è un processo offline). Ma per lo scenario giusto, questa nuova funzionalità può fornire un aumento delle prestazioni. A patto di comprendere che alcune limitazioni sottostanti continueranno a esistere, come la velocità del registro delle transazioni per le tabelle durevoli, anche se molto probabilmente in modo ridotto, indipendentemente dal fatto che la tabella esista su disco o in memoria.