
A marzo, ho iniziato una serie sui miti pervasivi sulle prestazioni in SQL Server. Una convinzione che incontro di tanto in tanto è che puoi sovradimensionare le colonne varchar o nvarchar senza alcuna penalità.
Supponiamo che tu stia memorizzando indirizzi e-mail. In una vita precedente, ho affrontato questo problema un po ':all'epoca, la RFC 3696 affermava che un indirizzo e-mail poteva essere di 320 caratteri (64 caratteri @ 255 caratteri). Una nuova RFC, #5321, ora riconosce che 254 caratteri è il massimo che potrebbe essere un indirizzo e-mail. E se qualcuno di voi ha un indirizzo così lungo, beh, forse dovremmo chattare. :-)
Ora, indipendentemente dal fatto che tu segua il vecchio standard o il nuovo, devi supportare la possibilità che qualcuno utilizzi tutti i caratteri consentiti. Ciò significa che devi usare 254 o 320 caratteri. Ma quello che ho visto fare alle persone non è affatto preoccuparsi di ricercare lo standard e presumere che debbano supportare 1.000 caratteri, 4.000 caratteri o anche oltre.
Diamo quindi un'occhiata a cosa succede quando abbiamo tabelle con una colonna di indirizzi e-mail di dimensioni variabili, ma che memorizzano esattamente gli stessi dati:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Ora, generiamo 10.000 indirizzi e-mail fittizi dai metadati di sistema e riempiamo tutte e quattro le tabelle con gli stessi dati:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Per verificare che ogni tabella contenga esattamente gli stessi dati:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Tutti e quattro mi danno 35 e 77; il tuo chilometraggio può variare. Assicuriamoci anche che tutte e quattro le tabelle occupino lo stesso numero di pagine su disco:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Tutte e quattro queste query producono 89 pagine (di nuovo, il tuo chilometraggio può variare).
Ora, prendiamo una query tipica che si traduce in una scansione dell'indice cluster:
SELECT id, email FROM dbo.Email_<size>;
Se osserviamo elementi come durata, letture e costi stimati, sembrano tutti uguali:
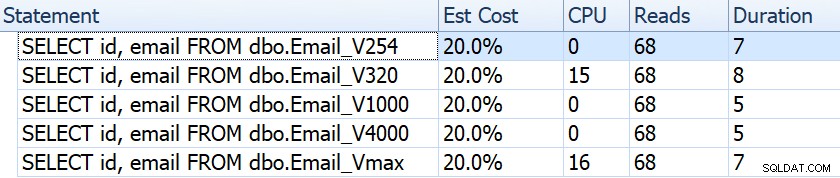
Ciò potrebbe indurre le persone a credere che non vi sia alcun impatto sulle prestazioni. Ma se guardiamo solo un po' più da vicino, sul suggerimento per la scansione dell'indice in cluster in ogni piano, vediamo una differenza che potrebbe entrare in gioco in altre query più elaborate:

Da qui vediamo che, maggiore è la definizione della colonna, maggiore è la riga stimata e la dimensione dei dati. In questa semplice query, il costo di I/O (0,0512731) è lo stesso per tutte le query, indipendentemente dalla definizione, perché la scansione dell'indice cluster deve comunque leggere tutti i dati.
Ma ci sono altri scenari in cui questa riga stimata e la dimensione totale dei dati avranno un impatto:operazioni che richiedono risorse aggiuntive, come gli ordinamenti. Prendiamo questa ridicola query che non ha alcuno scopo reale, oltre a richiedere più operazioni di ordinamento:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Eseguiamo queste quattro query e vediamo che i piani sono tutti così:

Tuttavia, l'icona di avviso sull'operatore SELECT appare solo sulle tabelle 4000/max. Qual è l'avvertimento? È un avviso di concessione di memoria eccessiva, introdotto in SQL Server 2016. Ecco l'avviso per varchar(4000):

E per varchar(max):

Diamo un'occhiata un po' più da vicino e vediamo cosa sta succedendo, almeno secondo sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Risultati:

Nel mio scenario, la durata non è stata influenzata dalle differenze di concessione della memoria (tranne il caso massimo), ma puoi vedere chiaramente la progressione lineare che coincide con la dimensione dichiarata della colonna. Che puoi usare per estrapolare cosa accadrebbe su un sistema con memoria insufficiente. O una query più elaborata su un set di dati molto più ampio. O una significativa concorrenza. Ognuno di questi scenari potrebbe richiedere spill per elaborare le operazioni di smistamento e, di conseguenza, la durata ne risentirebbe quasi sicuramente.
Ma da dove provengono queste sovvenzioni di memoria più grandi? Ricorda, è la stessa query, rispetto agli stessi identici dati. Il problema è che, per determinate operazioni, SQL Server deve prendere in considerazione la quantità di dati *potrebbe* essere in una colonna. Non lo fa in base alla profilazione effettiva dei dati e non può fare ipotesi sulla base dei valori di passaggio dell'istogramma <=201. Invece, deve stimare che ogni riga contenga un valore metà della dimensione dichiarata della colonna . Quindi, per un varchar(4000), presuppone che ogni indirizzo e-mail sia lungo 2.000 caratteri.
Quando non è possibile avere un indirizzo e-mail più lungo di 254 o 320 caratteri, non c'è nulla da guadagnare da un sovradimensionamento e c'è molto da perdere potenzialmente. Aumentare le dimensioni di una colonna a larghezza variabile in un secondo momento è molto più semplice che affrontare tutti gli aspetti negativi ora.
Ovviamente, sovradimensionando char o nchar le colonne possono avere sanzioni molto più evidenti.



