Nel mondo di SQL Server, ci sono due tipi di persone:quelli a cui piace che tutti i loro oggetti abbiano un prefisso e quelli che non lo fanno. Il primo gruppo è ulteriormente suddiviso in due categorie:quelli che antepongono alle stored procedure sp_ e quelli che scelgono altri prefissi (come usp_ o proc_ ). Una raccomandazione di vecchia data è stata quella di evitare sp_ prefisso, sia per motivi di prestazioni, sia per evitare ambiguità o collisioni se si sceglie un nome già esistente nel catalogo di sistema. Le collisioni sono certamente ancora un problema, ma supponendo che tu abbia controllato il nome del tuo oggetto, è ancora un problema di prestazioni?
Versione TL;DR:SÌ.
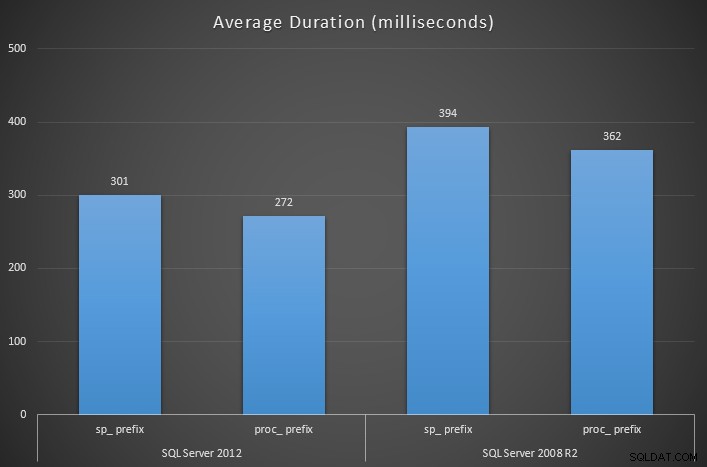
Il prefisso sp_ è ancora un no. Ma in questo post spiegherò perché, come SQL Server 2012 potrebbe portarti a credere che questo consiglio cautelativo non si applichi più e alcuni altri potenziali effetti collaterali della scelta di questa convenzione di denominazione.
Qual è il problema con sp_?
Il sp_ prefix non significa quello che pensi tu:la maggior parte delle persone pensa sp sta per "procedura memorizzata" quando in realtà significa "speciale". Stored procedure (così come tabelle e viste) archiviate nel master con un sp_ prefisso sono accessibili da qualsiasi database senza un riferimento appropriato (supponendo che non esista una versione locale). Se la procedura è contrassegnata come oggetto di sistema (usando sp_MS_marksystemobject (una procedura di sistema non documentata e non supportata che imposta is_ms_shipped a 1), quindi la procedura in master verrà eseguita nel contesto del database chiamante. Diamo un'occhiata a un semplice esempio:
CREATE DATABASE sp_test;
GO
USE sp_test;
GO
CREATE TABLE dbo.foo(id INT);
GO
USE master;
GO
CREATE PROCEDURE dbo.sp_checktable
AS
SELECT DB_NAME(), name
FROM sys.tables WHERE name = N'foo';
GO
USE sp_test;
GO
EXEC dbo.sp_checktable; -- runs but returns 0 results
GO
EXEC master..sp_MS_marksystemobject N'dbo.sp_checktable';
GO
EXEC dbo.sp_checktable; -- runs and returns results
GO Risultati:
(0 row(s) affected) sp_test foo (1 row(s) affected)
Il problema delle prestazioni deriva dal fatto che master potrebbe essere verificato per una stored procedure equivalente, a seconda che esista una versione locale della procedura e se in master sia effettivamente presente un oggetto equivalente. Ciò può comportare un sovraccarico di metadati aggiuntivo e un ulteriore SP:CacheMiss evento. La domanda è se questo sovraccarico è tangibile.
Consideriamo quindi una procedura molto semplice in un database di test:
CREATE DATABASE sp_prefix; GO USE sp_prefix; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
E procedure equivalenti in master:
USE master; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'master', DB_NAME(); END GO EXEC sp_MS_marksystemobject N'sp_something';
CacheMiss:realtà o finzione?
Se eseguiamo un rapido test dal nostro database di test, vediamo che l'esecuzione di queste procedure memorizzate non invocherà mai effettivamente le versioni dal master, indipendentemente dal fatto che la procedura sia qualificata correttamente come database o schema (un malinteso comune) o se contrassegniamo il versione master come oggetto di sistema:
USE sp_prefix; GO EXEC sp_prefix.dbo.sp_something; GO EXEC dbo.sp_something; GO EXEC sp_something;
Risultati:
sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix
Eseguiamo anche un Quick TraceSP:CacheMiss eventi:
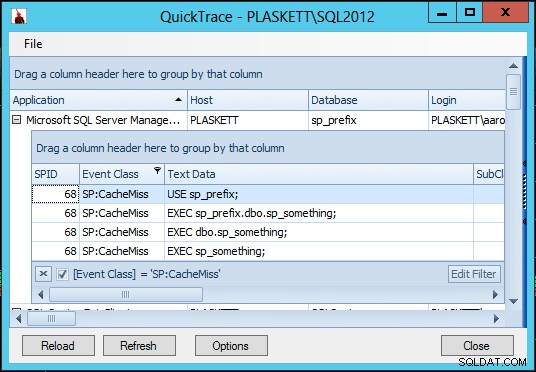
Vediamo CacheMiss eventi per il batch ad hoc che chiama la stored procedure (poiché SQL Server in genere non si preoccupa di memorizzare nella cache un batch costituito principalmente da chiamate di procedure), ma non per la stored procedure stessa. Sia con che senza sp_something procedura esistente in master (e quando esiste, sia con che senza che sia contrassegnata come oggetto di sistema), le chiamate a sp_something nel database utente non chiamare mai "accidentalmente" la procedura in master e non generare mai alcun CacheMiss eventi per la procedura.
Questo era su SQL Server 2012. Ho ripetuto gli stessi test sopra su SQL Server 2008 R2 e ho trovato risultati leggermente diversi:
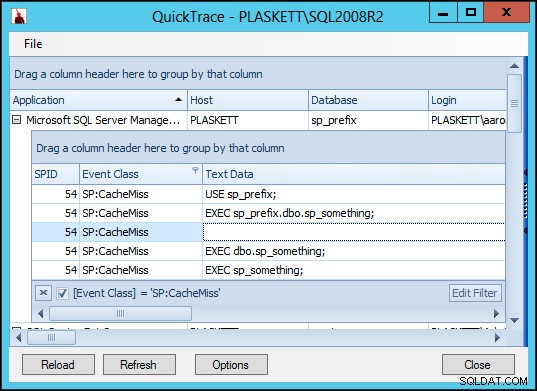
Quindi su SQL Server 2008 R2 vediamo un ulteriore CacheMiss evento che non si verifica in SQL Server 2012. Ciò si verifica in tutti gli scenari (nessun oggetto master equivalente, un oggetto nel master contrassegnato come oggetto di sistema e un oggetto nel master non contrassegnato come oggetto di sistema). Immediatamente sono stato curioso di sapere se questo evento aggiuntivo avrebbe avuto un impatto notevole sulle prestazioni.
Problemi di prestazioni:realtà o finzione?
Ho eseguito una procedura aggiuntiva senza sp_ prefisso per confrontare le prestazioni grezze, CacheMiss a parte:
USE sp_prefix; GO CREATE PROCEDURE dbo.proc_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
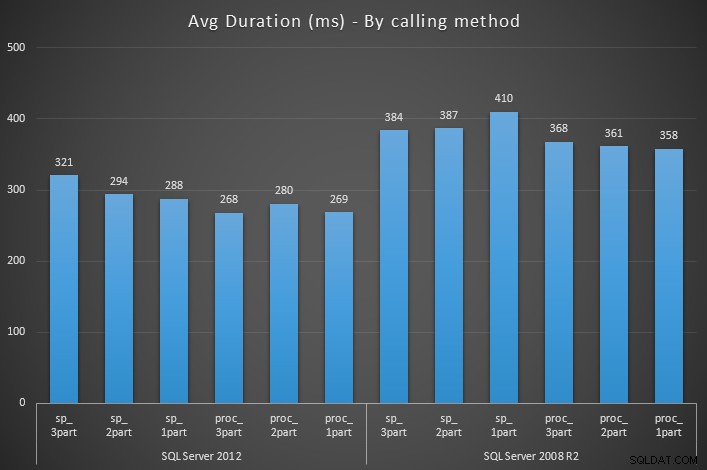
Quindi l'unica differenza tra sp_something e proc_something . Ho quindi creato procedure wrapper per eseguirle 1000 volte ciascuna, utilizzando EXEC sp_prefix.dbo.<procname> , EXEC dbo.<procname> e EXEC <procname> sintassi, con procedure memorizzate equivalenti che vivono in master e contrassegnate come oggetto di sistema, che vivono in master ma non sono contrassegnate come oggetto di sistema e non vivono affatto in master.
USE sp_prefix;
GO
CREATE PROCEDURE dbo.wrap_sp_3part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_prefix.dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_2part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_1part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_something;
SET @i += 1;
END
END
GO
-- repeat for proc_something
Misurando la durata del runtime di ciascuna procedura wrapper con SQL Sentry Plan Explorer, i risultati mostrano che utilizzando sp_ prefisso ha un impatto significativo sulla durata media in quasi tutti i casi (e sicuramente in media):