 Non è fantastico avere a disposizione una nuova versione di SQL Server? Questo è qualcosa che accade solo ogni due anni e questo mese ne abbiamo visto uno raggiungere la disponibilità generale. (Ok, so che riceviamo quasi continuamente una nuova versione del database SQL in Azure, ma lo considero diverso.) Prendendo atto di questa nuova versione, il T-SQL Tuesday di questo mese (ospitato da Michael Swart – @mjswart) è incentrato su tutto ciò che riguarda SQL Server 2016!
Non è fantastico avere a disposizione una nuova versione di SQL Server? Questo è qualcosa che accade solo ogni due anni e questo mese ne abbiamo visto uno raggiungere la disponibilità generale. (Ok, so che riceviamo quasi continuamente una nuova versione del database SQL in Azure, ma lo considero diverso.) Prendendo atto di questa nuova versione, il T-SQL Tuesday di questo mese (ospitato da Michael Swart – @mjswart) è incentrato su tutto ciò che riguarda SQL Server 2016!
Quindi oggi voglio esaminare la funzione Tabelle temporali di SQL 2016 e dare un'occhiata ad alcune situazioni del piano di query che potresti finire per vedere. Adoro le tabelle temporali, ma mi sono imbattuto in un problema di cui potresti voler essere a conoscenza.
Ora, nonostante SQL Server 2016 sia ora in RTM, sto usando AdventureWorks2016CTP3, che puoi scaricare qui, ma non scaricare semplicemente AdventureWorks2016CTP3.bak , prendi anche SQLServer2016CTP3Samples.zip dallo stesso sito.
Vedete, nell'archivio dei campioni, ci sono alcuni script utili per provare nuove funzionalità, inclusi alcuni per le tabelle temporali. È vantaggioso per tutti:puoi provare un sacco di nuove funzionalità e non devo ripetere così tanto la sceneggiatura in questo post. Ad ogni modo, prendi i due script su Temporal Tables, eseguendo AW 2016 CTP3 Temporal Setup.sql , seguito da Temporal System-Versioning Sample.sql .
Questi script impostano versioni temporali di alcune tabelle, incluso HumanResources.Employee . Crea HumanResources.Employee_Temporal (anche se, tecnicamente, avrebbe potuto essere chiamato qualsiasi cosa). Alla fine del CREATE TABLE istruzione, viene visualizzato questo bit, aggiungendo due colonne nascoste da utilizzare per indicare quando la riga è valida e indicando che è necessario creare una tabella chiamata HumanResources.Employee_Temporal_History per memorizzare le vecchie versioni.
... ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [HumanResources].[Employee_Temporal_History]) );
Quello che voglio esplorare in questo post è cosa succede con i piani di query quando viene utilizzata la cronologia.
Se eseguo una query sulla tabella per visualizzare l'ultima riga per un particolare BusinessEntityID , ottengo una ricerca di indici raggruppati, come previsto.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo FROM HumanResources.Employee_Temporal AS e WHERE e.BusinessEntityID = 4;
Sono sicuro che potrei interrogare questa tabella usando altri indici, se ne avesse. Ma in questo caso, non è così. Creiamone uno.
CREATE UNIQUE INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
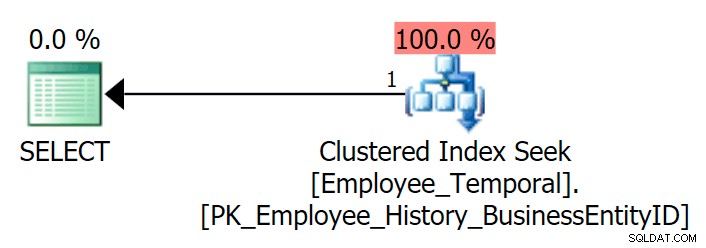
Ora posso interrogare la tabella con LoginID e visualizzerà una ricerca chiave se chiedo colonne diverse da Loginid o BusinessEntityID . Niente di tutto ciò è sorprendente.
SELECT * FROM HumanResources.Employee_Temporal e WHERE e.LoginID = N'adventure-works\rob0';
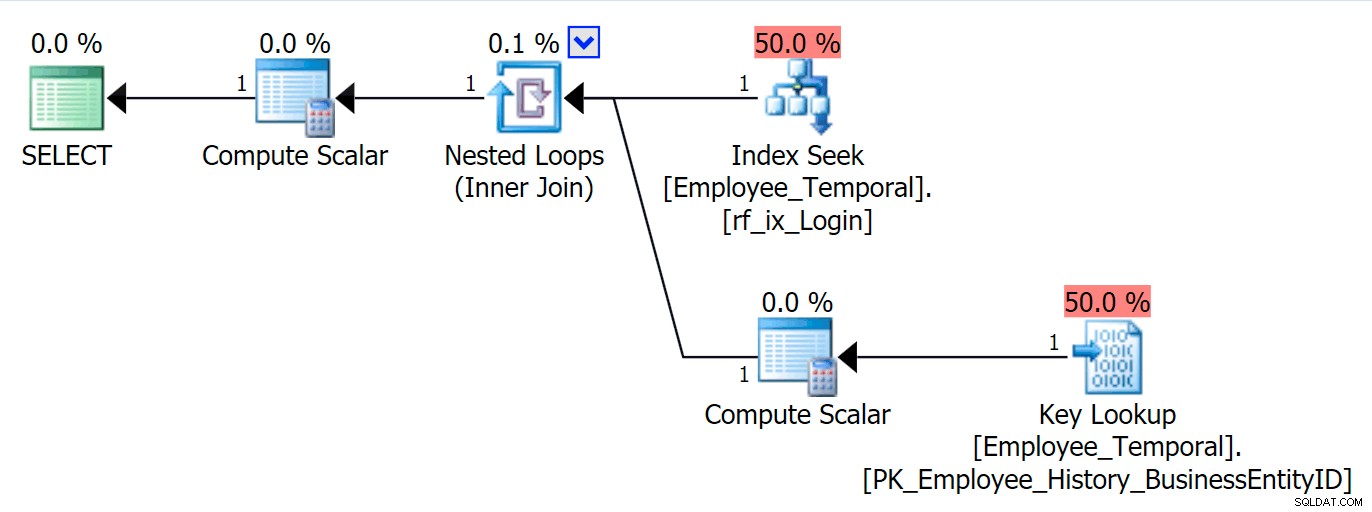
Usiamo SQL Server Management Studio per un minuto e diamo un'occhiata all'aspetto di questa tabella in Esplora oggetti.

Possiamo vedere la tabella Cronologia menzionata in HumanResources.Employee_Temporal e le colonne e gli indici sia della tabella stessa che della tabella della cronologia. Ma mentre gli indici sulla tabella corretta sono la chiave primaria (su BusinessEntityID ) e l'indice che avevo appena creato, la tabella Cronologia non ha indici corrispondenti.
L'indice sulla tabella della cronologia è su ValidTo e ValidFrom . Possiamo fare clic con il pulsante destro del mouse sull'indice e selezionare Proprietà e vediamo questa finestra di dialogo:
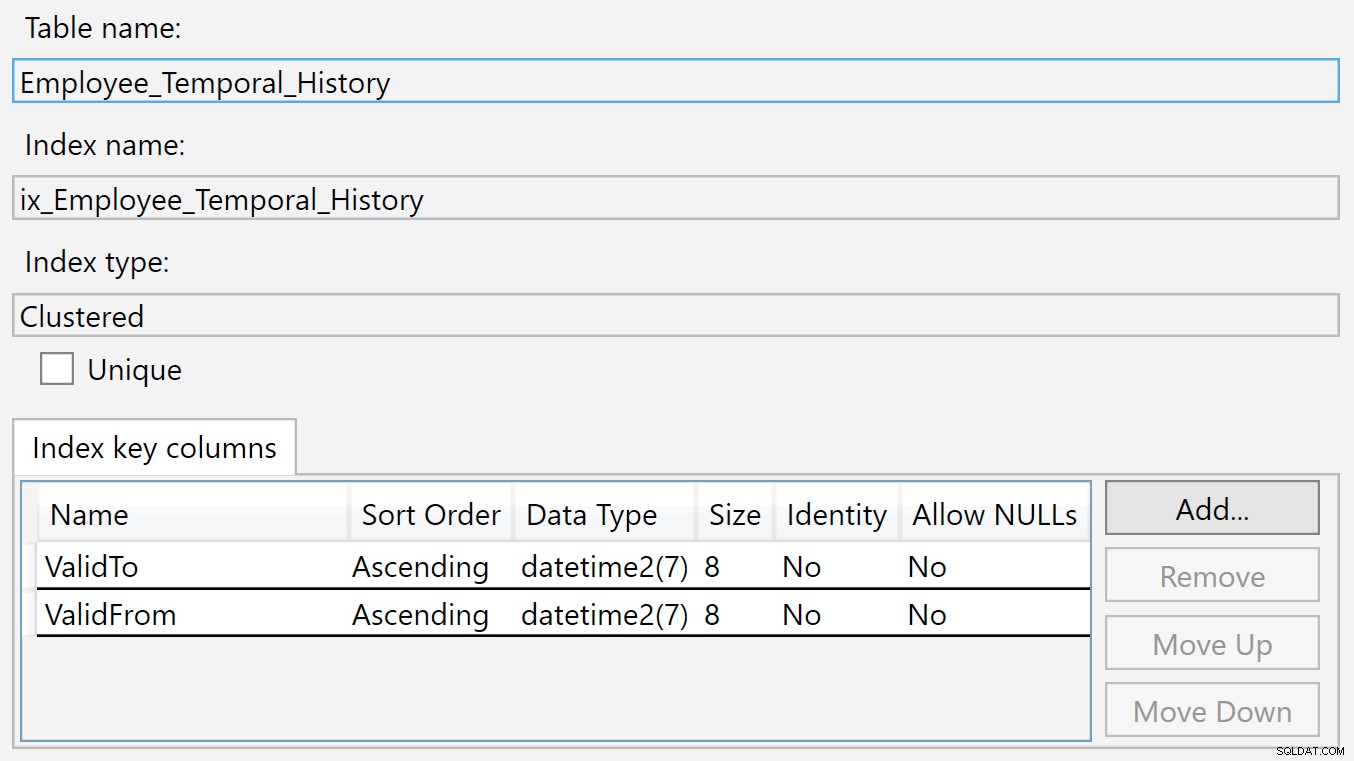
Una nuova riga viene inserita in questa tabella Cronologia quando non è più valida nella tabella principale, perché è stata appena eliminata o modificata. I valori in ValidTo colonne sono naturalmente popolate con l'ora corrente, quindi ValidTo funge da chiave ascendente, come una colonna di identità, in modo che i nuovi inserti appaiano alla fine della struttura b-tree.
Ma come funziona quando vuoi interrogare la tabella?
Se vogliamo interrogare la nostra tabella per ciò che era corrente in un determinato momento, allora dovremmo usare una struttura di query come:
SELECT * FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22';
Questa query deve concatenare le righe appropriate della tabella principale con le righe appropriate della tabella della cronologia.
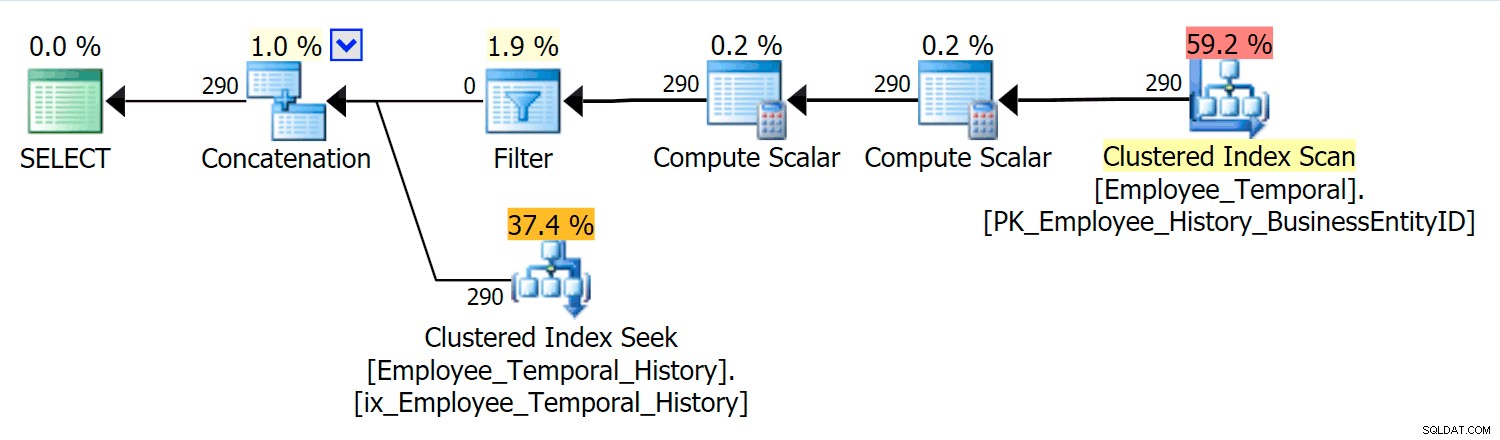
In questo scenario, le righe valide per il momento che ho selezionato provenivano tutte dalla tabella della cronologia, tuttavia, viene visualizzata una scansione dell'indice cluster rispetto alla tabella principale, che è stata filtrata da un operatore di filtro. Il predicato di questo filtro è:
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
Rivediamolo tra un momento.
La ricerca dell'indice cluster nella tabella Cronologia deve chiaramente sfruttare un predicato di ricerca su ValidTo. L'inizio della scansione dell'intervallo di ricerca è HumanResources.Employee_Temporal_History.ValidTo > Operatore scalare('2016-06-12 11:22:00') , ma non c'è End, perché ogni riga che ha un ValidTo dopo il tempo che ci interessa è una riga candidata e deve essere testata per un ValidFrom appropriato valore dal predicato residuo, che è HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Ora, gli intervalli sono difficili da indicizzare; questa è una cosa nota che è stata discussa su molti blog. Le soluzioni più efficaci prendono in considerazione modi creativi per scrivere query, ma nessuna intelligenza di questo tipo è stata incorporata nelle tabelle temporali. Tuttavia, puoi inserire indici anche su altre colonne, ad esempio su ValidFrom, o persino avere indici che corrispondono ai tipi di query che potresti avere nella tabella principale. Con un indice cluster che è una chiave composita su entrambi ValidTo e ValidFrom , queste due colonne vengono incluse in ogni altra colonna, fornendo una buona opportunità per alcuni test del predicato residuo.
Se so a quale loginid sono interessato, il mio piano assume una forma diversa.
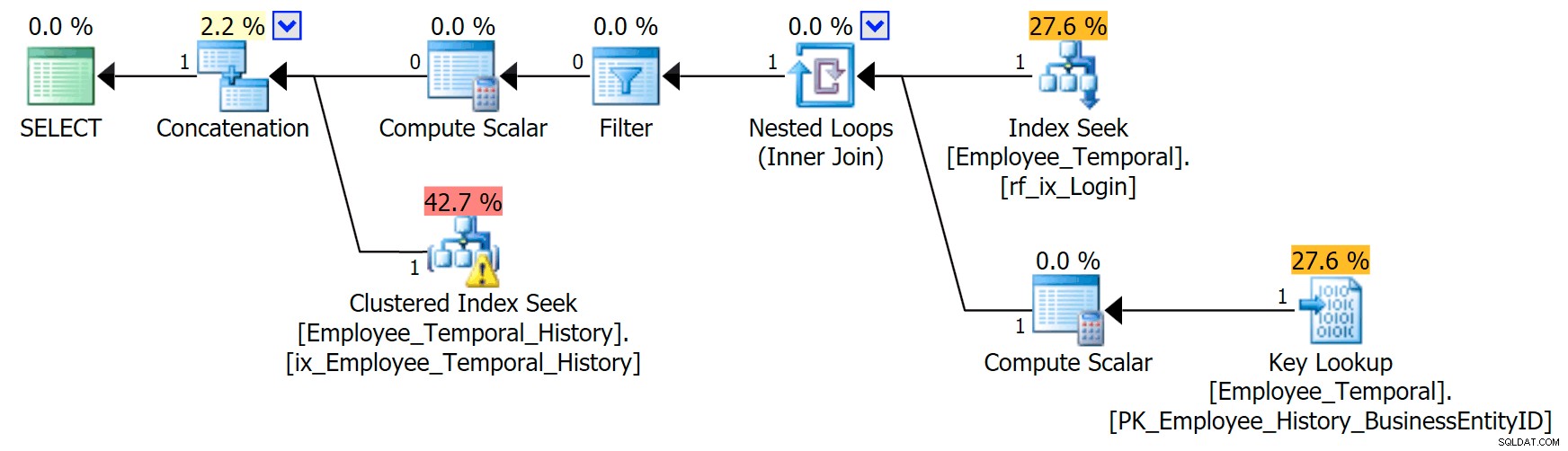
Il ramo superiore dell'operatore di concatenazione è simile a prima, sebbene quell'operatore di filtro sia entrato nella mischia per rimuovere le righe non valide, ma il Clustered Index Seek sul ramo inferiore ha un avviso. Questo è un avviso di predicato residuo, come gli esempi in un mio precedente post. È in grado di filtrare le voci che sono valide fino a un certo punto dopo il tempo che ci interessa, ma il predicato residuo ora filtra in LoginID così come ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
Le modifiche alle righe di rob0 saranno una piccola parte delle righe nella cronologia. Questa colonna non sarà univoca come nella tabella principale, perché la riga potrebbe essere stata modificata più volte, ma c'è ancora un buon candidato per l'indicizzazione.
CREATE INDEX rf_ixHist_loginid ON HumanResources.Employee_Temporal_History(LoginID);
Questo nuovo indice ha un effetto notevole sul nostro piano.
Ora è stata modificata la ricerca di indici raggruppati in una scansione di indici raggruppata!!
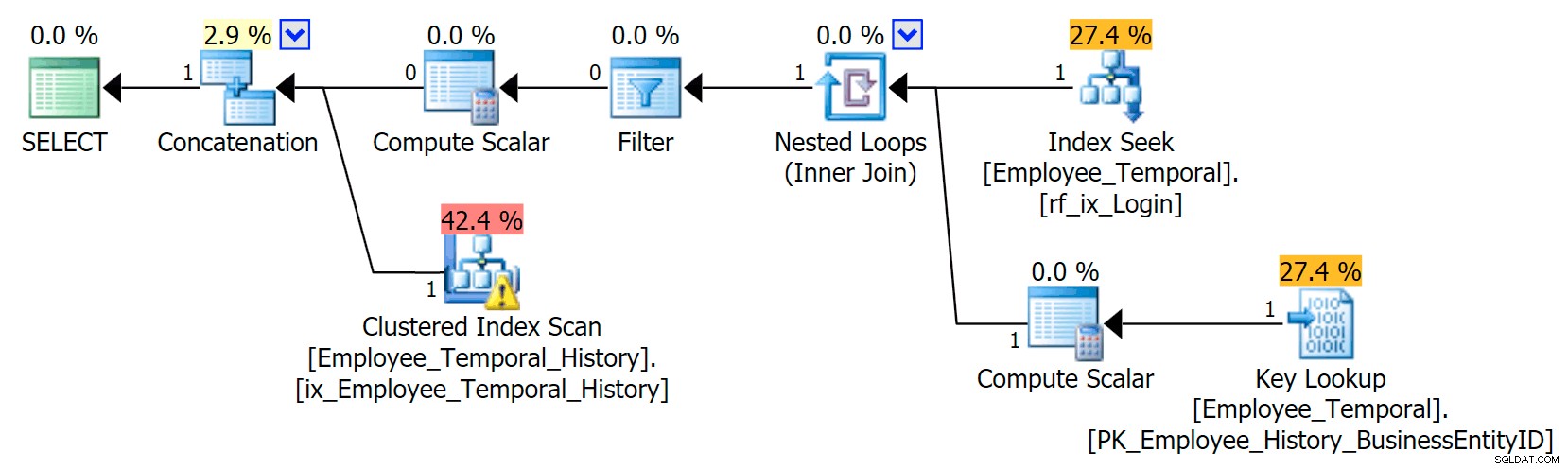
Vedete, Query Optimizer ora ha capito che la cosa migliore da fare sarebbe usare il nuovo indice. Ma decide anche che lo sforzo di dover fare ricerche per ottenere tutte le altre colonne (perché stavo chiedendo tutte le colonne) sarebbe semplicemente troppo faticoso. È stato raggiunto il punto critico (purtroppo un'ipotesi errata in questo caso) e invece è stato scelto uno SCAN indice cluster. Anche se senza l'indice non cluster, l'opzione migliore sarebbe stata quella di utilizzare un Clustered Index Seek, quando l'indice non cluster è stato considerato e rifiutato per motivi di non ritorno, sceglie di eseguire la scansione.
Frustrante, ho appena creato questo indice e le sue statistiche dovrebbero essere buone. Dovrebbe sapere che una ricerca che richiede esattamente una ricerca dovrebbe essere migliore di una scansione dell'indice cluster (solo in base alle statistiche, se stavi pensando che dovrebbe saperlo perché LoginID è unico nella tabella principale, ricorda che potrebbe non essere sempre stato). Quindi sospetto che le ricerche dovrebbero essere evitate nelle tabelle della cronologia, anche se non ho ancora svolto abbastanza ricerche al riguardo.
Ora, se dovessimo interrogare solo le colonne che appaiono nel nostro indice non cluster, otterremmo un comportamento molto migliore. Ora che non è richiesta alcuna ricerca, il nostro nuovo indice nella tabella della cronologia viene utilizzato felicemente. Deve ancora applicare un predicato residuo basato sulla possibilità di filtrare solo su LoginID e ValidTo , ma si comporta molto meglio di una scansione dell'indice cluster.
SELECT LoginID, ValidFrom, ValidTo FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22' WHERE LoginID = N'adventure-works\rob0'
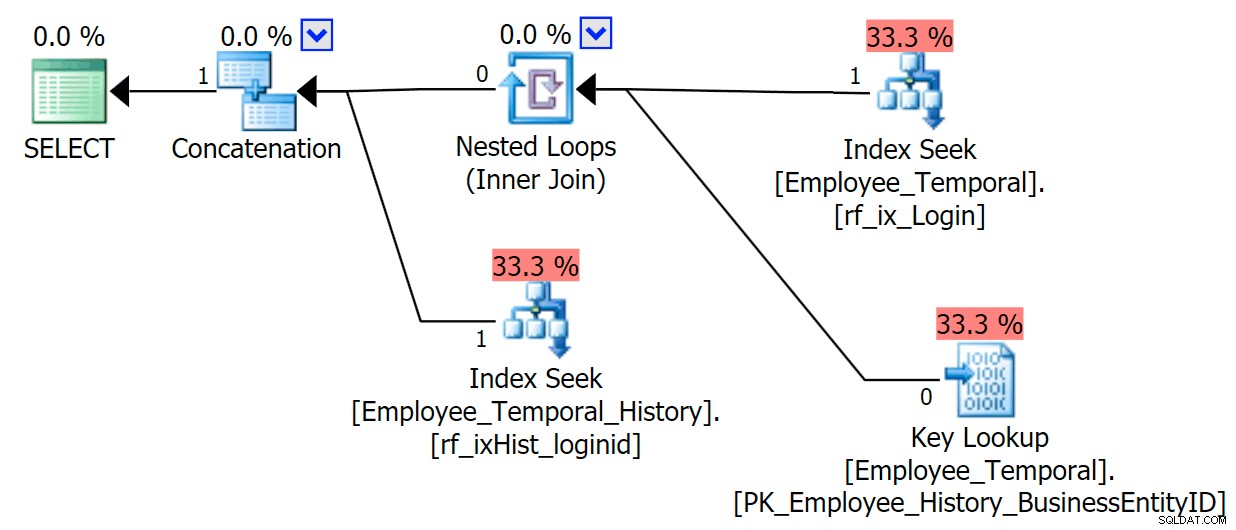
Quindi indicizza le tue tabelle della cronologia in modi extra, considerando come le interrogherai. Includi le colonne necessarie per evitare le ricerche, perché stai davvero evitando le scansioni.
Queste tabelle cronologiche possono aumentare di dimensioni se i dati cambiano frequentemente. Quindi fai attenzione a come vengono gestiti. Questa stessa situazione si verifica quando si utilizza l'altro FOR SYSTEM_TIME costrutti, quindi dovresti (come sempre) rivedere i piani che le tue query stanno producendo e indicizzare per assicurarti di essere ben posizionato per sfruttare quella che è una funzionalità molto potente di SQL Server 2016.



