In questo post del blog, esamineremo alcune metriche chiave e lo stato durante il monitoraggio di un server Percona per MySQL per aiutarci a mettere a punto la configurazione del server MySQL a lungo termine. Solo per l'attenzione, Percona Server ha alcune metriche di monitoraggio che sono disponibili solo su questa build. Quando si confronta con la versione 8.0.20, i seguenti 51 stati sono disponibili solo su Percona Server for MySQL, che non sono disponibili nel MySQL Community Server di Oracle a monte:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Consulta la pagina Stato esteso di InnoDB per ulteriori informazioni su ciascuna delle metriche di monitoraggio di cui sopra. Si noti che alcuni stati extra come il pool di thread sono disponibili solo in MySQL Enterprise di Oracle. Consulta la documentazione di Percona Server per MySQL 8.0 per vedere tutti i miglioramenti specifici per questa build rispetto a MySQL Community Server 8.0 di Oracle.
Per recuperare lo stato globale di MySQL, usa semplicemente una delle seguenti istruzioni:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Stato del database e panoramica
Inizieremo con lo stato di uptime, il numero di secondi in cui il server è stato attivo.
Tutti gli stati com_* sono le variabili del contatore delle istruzioni che indicano il numero di volte in cui ciascuna istruzione è stata eseguita. Esiste una variabile di stato per ogni tipo di istruzione. Ad esempio, com_delete e com_update contano rispettivamente le istruzioni DELETE e UPDATE. com_delete_multi e com_update_multi sono simili ma si applicano alle istruzioni DELETE e UPDATE che utilizzano la sintassi a più tabelle.
Per elencare tutto il processo in esecuzione da MySQL, esegui semplicemente una delle seguenti istruzioni:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Connessioni e thread
Connessioni attuali
Il rapporto delle connessioni attualmente aperte (thread di connessione). Se il rapporto è alto, indica che ci sono molte connessioni simultanee al server MySQL e potrebbe causare un errore "Troppe connessioni". Per ottenere la percentuale di connessione:
Current connections(%) = (threads_connected / max_connections) x 100Un buon valore dovrebbe essere 80% e inferiore. Prova ad aumentare la variabile max_connections o controlla le connessioni usando SHOW FULL PROCESSLIST. Quando si verificano errori "Troppe connessioni", il server del database MySQL non sarà disponibile per il non super utente fino a quando alcune connessioni non verranno liberate. Nota che l'aumento della variabile max_connections potrebbe anche aumentare potenzialmente l'impronta di memoria di MySQL.
Connessioni massime mai viste
Il rapporto tra le connessioni massime al server MySQL mai visto. Un semplice calcolo sarebbe:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Il buon valore dovrebbe essere inferiore all'80%. Se il rapporto è alto, indica che MySQL ha raggiunto una volta un numero elevato di connessioni che porterebbe a un errore "troppe connessioni". Ispeziona il rapporto di connessione corrente per vedere se sta effettivamente rimanendo basso in modo coerente. In caso contrario, aumentare la variabile max_connections. Controlla lo stato max_used_connections_time per indicare quando lo stato max_used_connections ha raggiunto il suo valore corrente.
Tasso di successo nella cache dei thread
Lo stato di threads_created è il numero di thread creati per gestire le connessioni. Se threads_created è grande, potresti voler aumentare il valore thread_cache_size. La percentuale di hit/miss della cache può essere calcolata come:
Threads cache hit rate (%) = (threads_created / connections) x 100È una frazione che fornisce un'indicazione del tasso di successo della cache del thread. Più si avvicina meno del 50%, meglio è. Se il tuo server vede centinaia di connessioni al secondo, normalmente dovresti impostare thread_cache_size sufficientemente alto in modo che la maggior parte delle nuove connessioni utilizzi thread memorizzati nella cache.
Rendimento query
Scansioni di tabelle complete
Il rapporto tra le scansioni complete della tabella, un'operazione che richiede la lettura dell'intero contenuto di una tabella, anziché solo le porzioni selezionate utilizzando un indice. Questo valore è alto se si eseguono molte query che richiedono l'ordinamento dei risultati o le scansioni di tabelle. In genere, ciò suggerisce che le tabelle non sono indicizzate correttamente o che le query non vengono scritte per sfruttare gli indici di cui disponi. Per calcolare la percentuale di scansioni di tabelle complete:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Il valore buono dovrebbe essere inferiore al 25%. Esaminare l'output del log delle query lente di MySQL per scoprire le query non ottimali.
Seleziona Partecipazione completa
Lo stato di select_full_join è il numero di join che eseguono scansioni di tabelle perché non utilizzano indici. Se questo valore non è 0, dovresti controllare attentamente gli indici delle tue tabelle.
Seleziona Controllo intervallo
Lo stato di select_range_check è il numero di join senza chiavi che controllano l'utilizzo delle chiavi dopo ogni riga. Se questo non è 0, dovresti controllare attentamente gli indici delle tue tabelle.
Ordina i pass
Il rapporto di unione passa che l'algoritmo di ordinamento ha dovuto fare. Se questo valore è alto, dovresti considerare di aumentare il valore di sort_buffer_size e read_rnd_buffer_size. Un semplice calcolo del rapporto è:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Un valore di rapporto inferiore a 3 dovrebbe essere un buon valore. Se vuoi aumentare sort_buffer_size o read_rnd_buffer_size, prova ad aumentare con piccoli incrementi fino a raggiungere il rapporto accettabile.
Prestazioni InnoDB
Percentuale di successo del pool di buffer InnoDB
Il rapporto tra la frequenza con cui le tue pagine vengono recuperate dalla memoria anziché dal disco. Se il valore è basso durante l'avvio anticipato di MySQL, attendere un po' di tempo per il riscaldamento del pool di buffer. Per ottenere la percentuale di hit del pool di buffer, utilizzare l'istruzione SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Il valore migliore è 1000/10000 hit rate. Per un valore più basso, ad esempio, il tasso di successo di 986/1000 indica che su 1000 pagine lette, è stato in grado di leggere le pagine nella RAM 986 volte. Le restanti 14 volte, MySQL ha dovuto leggere le pagine dal disco. Detto semplicemente, 1000/1000 è il miglior valore che stiamo cercando di ottenere qui, il che significa che i dati a cui si accede di frequente si adattano completamente alla RAM.
Aumentare la variabile innodb_buffer_pool_size aiuterà molto ad avere più spazio su cui lavorare MySQL. Tuttavia, assicurati di avere risorse RAM sufficienti in anticipo. Anche la rimozione degli indici ridondanti potrebbe aiutare. Se disponi di più istanze di pool di buffer, assicurati che la frequenza di risposta per ogni istanza raggiunga 1000/1000.
Pagine sporche di InnoDB
Il rapporto tra la frequenza con cui InnoDB deve essere svuotato. Durante il carico di scrittura pesante, è normale che questa percentuale aumenti.
Un semplice calcolo sarebbe:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Un buon valore dovrebbe essere del 75% e inferiore. Se la percentuale di pagine sporche rimane elevata per molto tempo, potresti voler aumentare il pool di buffer o ottenere dischi più veloci per evitare colli di bottiglia nelle prestazioni.
InnoDB attende il checkpoint
Il rapporto tra la frequenza con cui InnoDB ha bisogno di leggere o creare una pagina in cui non sono disponibili pagine pulite. Normalmente, le scritture nel pool di buffer InnoDB avvengono in background. Tuttavia, se è necessario leggere o creare una pagina e non sono disponibili pagine pulite, è anche necessario attendere che le pagine vengano prima svuotate. Il contatore innodb_buffer_pool_wait_free conta quante volte è successo. Per calcolare il rapporto di attesa di InnoDB per il checkpoint, possiamo utilizzare il seguente calcolo:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsSe innodb_buffer_pool_wait_free è maggiore di 0, è un forte indicatore che il pool di buffer InnoDB è troppo piccolo e che le operazioni hanno dovuto attendere un checkpoint. L'aumento di innodb_buffer_pool_size di solito diminuirà innodb_buffer_pool_wait_free, così come questo rapporto. Un buon rapporto dovrebbe rimanere al di sotto di 1.
InnoDB attende Redolog
Il rapporto di contesa del registro di ripristino. Controlla innodb_log_waits e se continua ad aumentare, aumenta innodb_log_buffer_size. Può anche significare che i dischi sono troppo lenti e non possono sostenere l'IO del disco, forse a causa del carico di scrittura di picco. Utilizzare il seguente calcolo per calcolare il rapporto di attesa del registro di ripristino:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesUn buon rapporto dovrebbe essere inferiore a 1. Altrimenti, aumenta innodb_log_buffer_size.
Tabelle
Utilizzo della cache della tabella
Il rapporto di utilizzo della cache della tabella per tutti i thread. Un semplice calcolo sarebbe:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Il buon valore dovrebbe essere inferiore all'80%. Aumenta la variabile table_open_cache finché la percentuale non raggiunge un buon valore.
Rapporto hit cache tabella
Il rapporto tra l'utilizzo della cache della tabella. Un semplice calcolo sarebbe:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Un buon rapporto di successo dovrebbe essere del 90% e oltre. In caso contrario, aumenta la variabile table_open_cache finché la percentuale di risultati non raggiunge un buon valore.
Monitoraggio delle metriche con ClusterControl
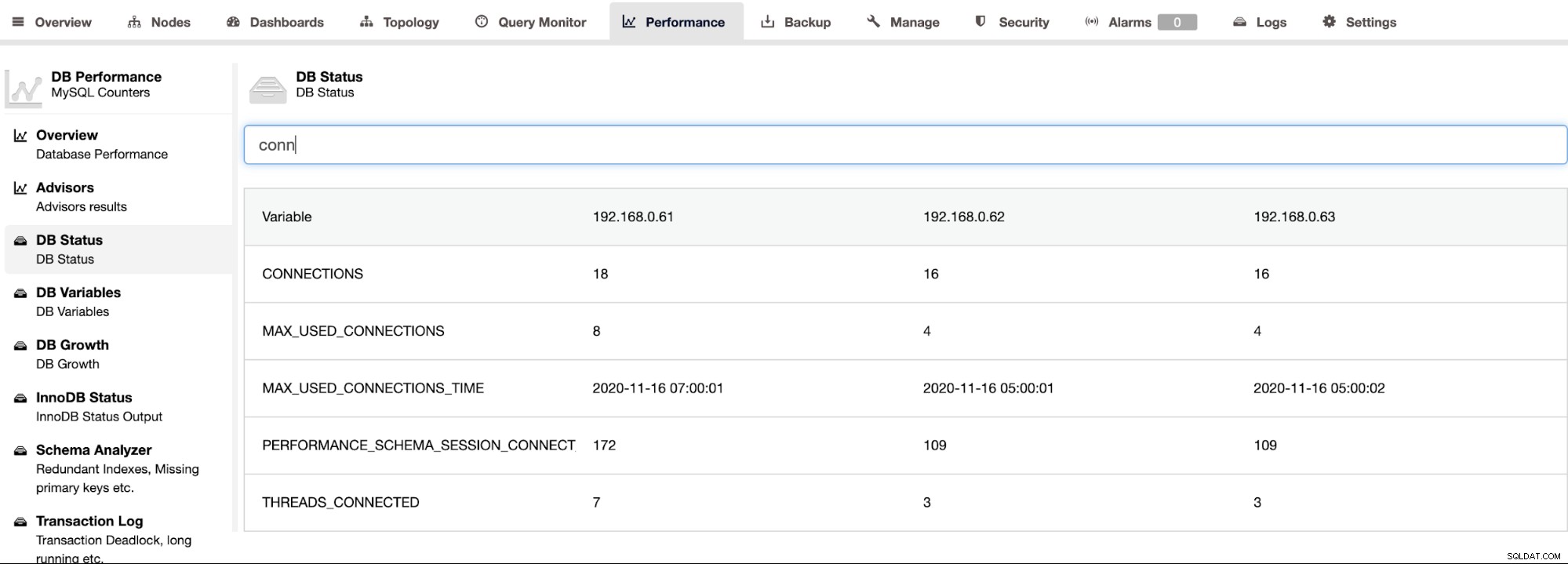
ClusterControl supporta Percona Server per MySQL e fornisce una vista aggregata di tutti i nodi in un cluster nella pagina ClusterControl -> Performance -> DB Status. Ciò fornisce un approccio centralizzato per cercare tutto lo stato su tutti gli host con la possibilità di filtrare lo stato, come mostrato nella schermata seguente:
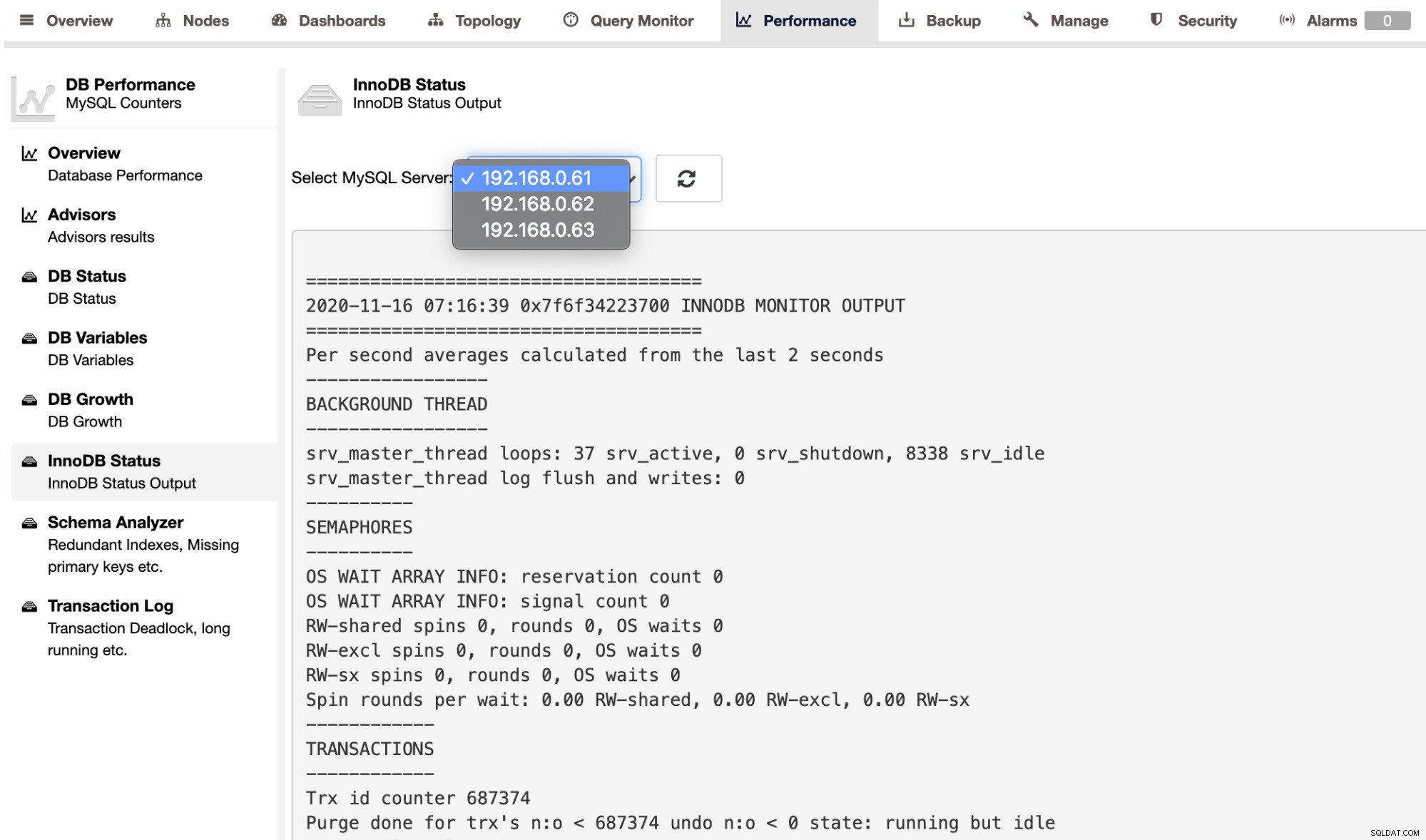
Per recuperare l'output di SHOW ENGINE INNODB STATUS per un singolo server, è possibile utilizzare la pagina Performance -> InnoDB Status, come mostrato di seguito:
ClusterControl fornisce anche consulenti integrati che puoi utilizzare per tenere traccia del tuo database prestazione. Questa funzione è accessibile in ClusterControl -> Performance -> Advisors:
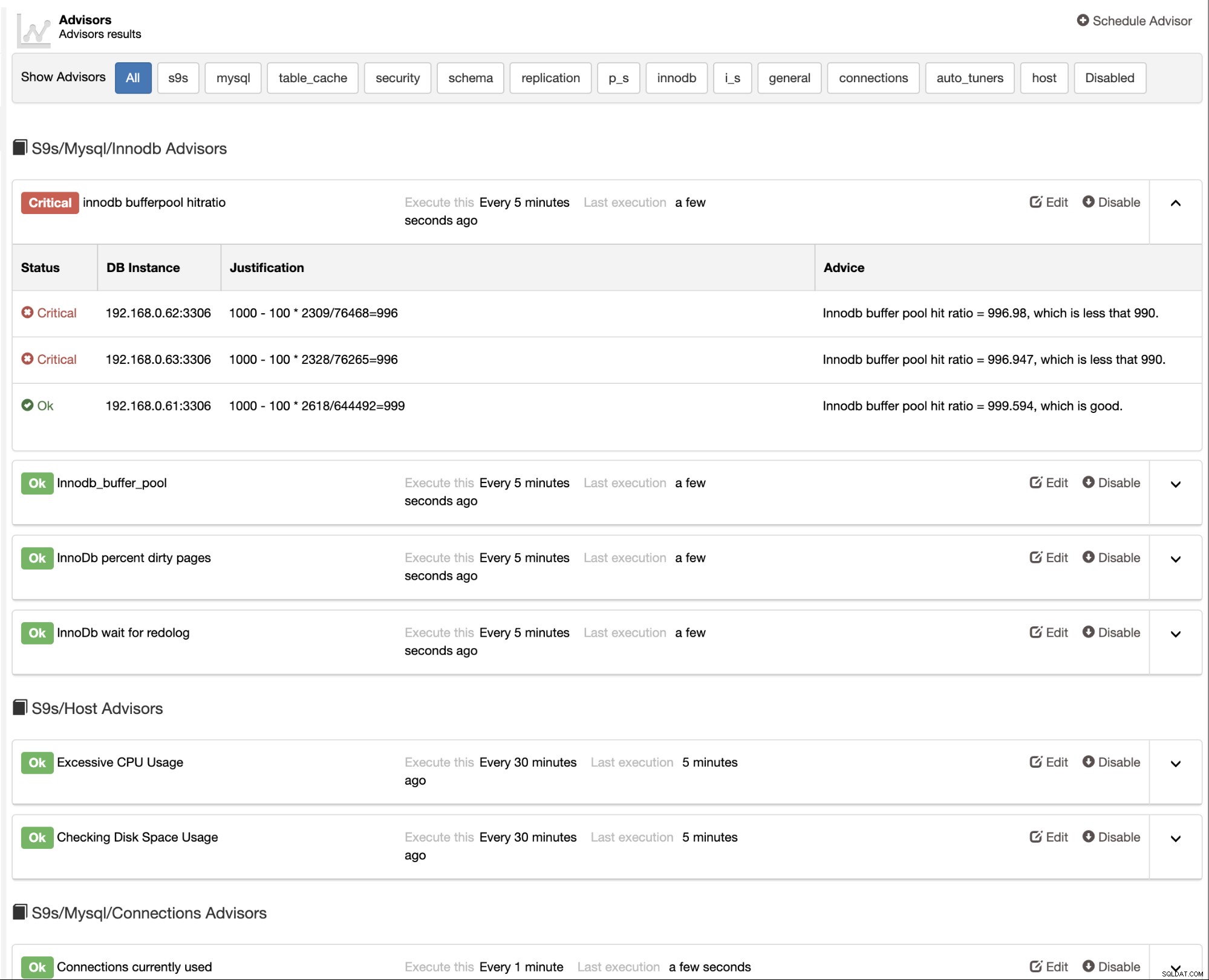
Gli advisor sono fondamentalmente dei mini-programmi eseguiti da ClusterControl in un tempo programmato come cron lavori. Puoi pianificare un advisor facendo clic sul pulsante "Schedule Advisor" e scegliere qualsiasi advisor esistente dall'albero degli oggetti di Developer Studio:
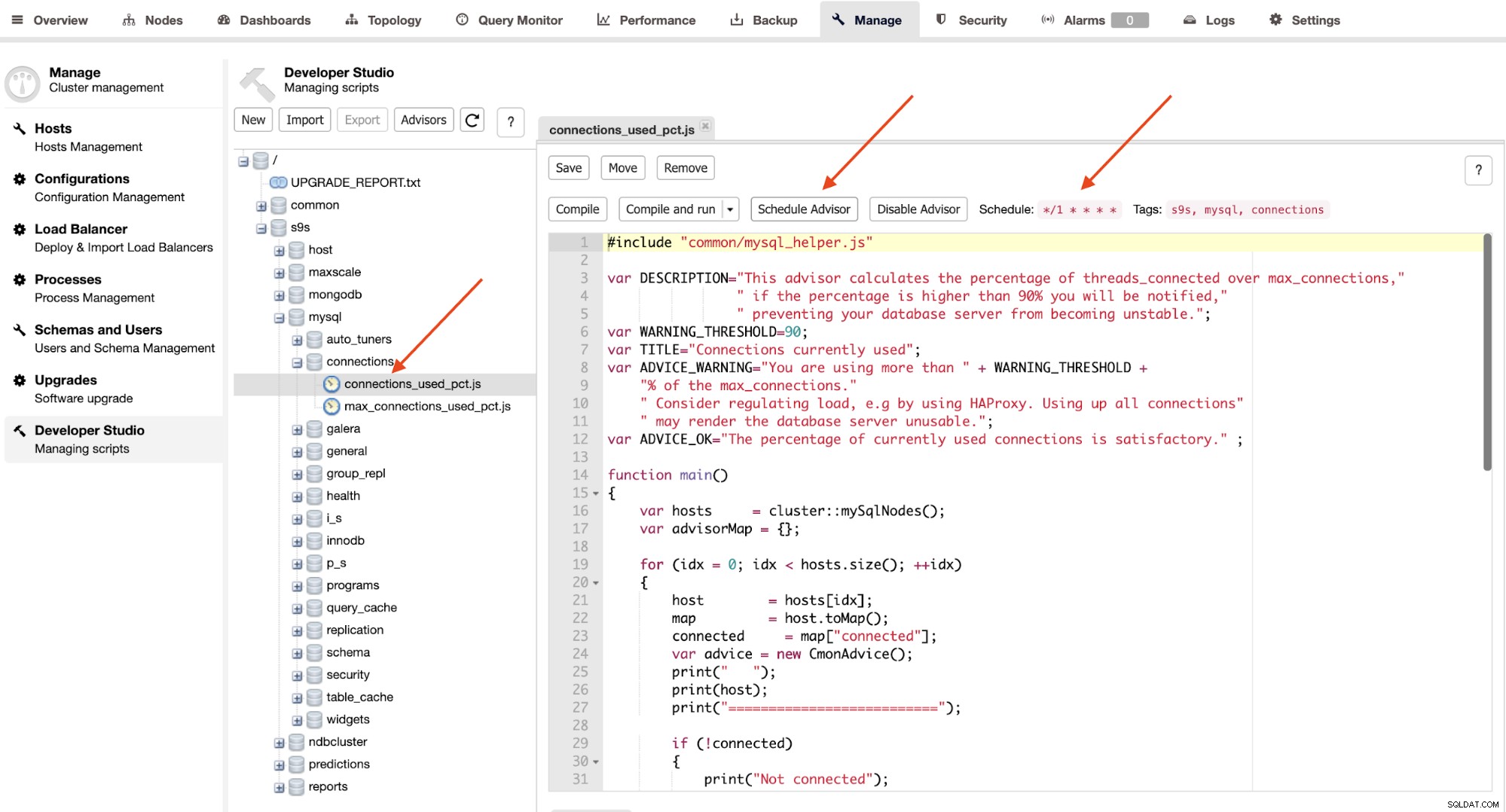
Fare clic sul pulsante "Schedule Advisor" per impostare la pianificazione, argomento su pass e anche i tag dell'advisor. Puoi anche compilare l'advisor per vedere l'output immediatamente facendo clic sul pulsante "Compila ed esegui", dove dovresti vedere il seguente output sotto i "Messaggi" sotto di esso:

Puoi creare il tuo consulente facendo riferimento a questa Guida per gli sviluppatori, scritta in ClusterControl Domain Specific Language (molto simile a Javascript) o personalizza un advisor esistente per adattarlo alle tue politiche di monitoraggio. In breve, il servizio di monitoraggio ClusterControl può essere esteso con possibilità illimitate tramite ClusterControl Advisors.