Questo articolo è la quarta parte di una serie sulle espressioni di tabella. Nella parte 1 e nella parte 2 ho trattato il trattamento concettuale delle tabelle derivate. Nella parte 3 ho iniziato a trattare le considerazioni sull'ottimizzazione delle tabelle derivate. Questo mese tratterò ulteriori aspetti dell'ottimizzazione delle tabelle derivate; in particolare, mi concentro sulla sostituzione/annullamento dell'annidamento delle tabelle derivate.
Nei miei esempi userò database di esempio chiamati TSQLV5 e PerformanceV5. Puoi trovare lo script che crea e popola TSQLV5 qui e il suo diagramma ER qui. Puoi trovare lo script che crea e popola PerformanceV5 qui.
Disnestamento/sostituzione
L'annullamento dell'annidamento/sostituzione delle espressioni di tabella è un processo di acquisizione di una query che implica l'annidamento di espressioni di tabella e come se la sostituisse con una query in cui la logica annidata viene eliminata. Dovrei sottolineare che, in pratica, non esiste un processo effettivo in cui SQL Server converte la stringa di query originale con la logica nidificata in una nuova stringa di query senza nidificazione. Ciò che accade effettivamente è che il processo di analisi della query produce un albero iniziale di operatori logici che riflette da vicino la query originale. Quindi, SQL Server applica le trasformazioni a questo albero di query, eliminando alcuni dei passaggi non necessari, riducendo più passaggi in meno passaggi e spostando gli operatori. Nelle sue trasformazioni, purché vengano soddisfatte determinate condizioni, SQL Server può spostare le cose attraverso quelli che erano originariamente i limiti delle espressioni di tabella, a volte in modo efficace come se eliminassero le unità nidificate. Tutto questo nel tentativo di trovare un piano ottimale.
In questo articolo tratterò sia i casi in cui avviene tale disinnesto, sia gli inibitori di disinnesto. Cioè, quando si utilizzano determinati elementi di query, SQL Server non può spostare gli operatori logici nell'albero della query, costringendolo a elaborare gli operatori in base ai limiti delle espressioni di tabella utilizzate nella query originale.
Inizierò dimostrando un semplice esempio in cui le tabelle derivate vengono annullate. Dimostrerò anche un esempio per un inibitore disnidante. Parlerò quindi di casi insoliti in cui l'annullamento dell'annidamento può essere indesiderabile, con conseguenti errori o degrado delle prestazioni, e dimostrerò come prevenire l'annidamento in quei casi utilizzando un inibitore dell'annidamento.
La seguente query (la chiameremo Query 1) utilizza più livelli nidificati di tabelle derivate, in cui ciascuna delle espressioni di tabella applica una logica di filtro di base basata su costanti:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Come puoi vedere, ciascuna delle espressioni della tabella filtra un intervallo di date di ordini che iniziano con una data diversa. SQL Server annulla questa logica di query a più livelli, che consente di unire i quattro predicati di filtraggio in uno unico che rappresenta l'intersezione di tutti e quattro i predicati.
Esaminare il piano per la query 1 mostrato nella figura 1.
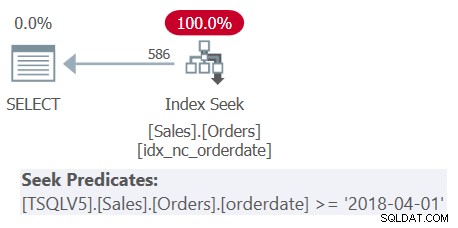 Figura 1:piano per la query 1
Figura 1:piano per la query 1
Osservare che tutti e quattro i predicati di filtraggio sono stati fusi in un unico predicato che rappresenta l'intersezione dei quattro. Il piano applica una ricerca nell'indice idx_nc_orderdate in base al singolo predicato unito come predicato di ricerca. Questo indice è definito su orderdate (esplicitamente), orderid (implicitamente dovuto alla presenza di un indice cluster su orderid) come chiavi dell'indice.
Osservare inoltre che anche se tutte le espressioni di tabella utilizzano SELECT * e solo la query più esterna proietta le due colonne di interesse:orderdate e orderid, l'indice sopra menzionato è considerato coprente. Come spiegato nella parte 3, per scopi di ottimizzazione come la selezione dell'indice, SQL Server ignora le colonne delle espressioni di tabella che in definitiva non sono rilevanti. Ricorda però che devi disporre delle autorizzazioni per eseguire query su quelle colonne.
Come accennato, SQL Server tenterà di annullare l'annidamento delle espressioni di tabella, ma eviterà l'annullamento dell'annidamento se si imbatte in un inibitore dell'annidamento. Con una certa eccezione che descriverò in seguito, l'uso di TOP o OFFSET FETCH inibirà il disannidamento. Il motivo è che il tentativo di annullare l'annidamento di un'espressione di tabella con TOP o OFFSET FETCH potrebbe comportare una modifica del significato della query originale.
Ad esempio, considera la seguente query (la chiameremo Query 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Il numero di righe di input per il filtro TOP è un valore di tipo BIGINT. In questo esempio sto usando il valore BIGINT massimo (2^63 – 1, calcola in T-SQL usando SELECT POWER(2., 63) – 1). Anche se io e te sappiamo che la nostra tabella Ordini non avrà mai così tante righe, e quindi il filtro TOP è davvero privo di significato, SQL Server deve tenere conto della possibilità teorica che il filtro sia significativo. Di conseguenza, SQL Server non annulla l'annidamento delle espressioni di tabella in questa query. Il piano per la query 2 è mostrato nella Figura 2.
 Figura 2:piano per la query 2
Figura 2:piano per la query 2
Gli inibitori dell'annidamento hanno impedito a SQL Server di essere in grado di unire i predicati di filtraggio, facendo in modo che la forma del piano assomigli maggiormente alla query concettuale. Tuttavia, è interessante osservare che SQL Server ha comunque ignorato le colonne che alla fine non erano rilevanti per la query più esterna e quindi è stato in grado di utilizzare l'indice di copertura su orderdate, orderid.
Per illustrare perché TOP e OFFSET-FETCH sono inibitori disnidanti, prendiamo una semplice tecnica di ottimizzazione pushdown del predicato. Predicato pushdown significa che l'ottimizzatore spinge un predicato di filtro a un punto precedente rispetto al punto originale che appare nell'elaborazione della query logica. Ad esempio, supponiamo di avere una query con un inner join e un filtro WHERE basato su una colonna da uno dei lati del join. In termini di elaborazione logica delle query, il filtro WHERE dovrebbe essere valutato dopo il join. Ma spesso l'ottimizzatore spingerà il predicato del filtro a un passaggio prima del join, poiché questo lascia il join con meno righe con cui lavorare, risultando in genere in un piano più ottimale. Ricorda però che tali trasformazioni sono consentite solo nei casi in cui viene preservato il significato della query originale, nel senso che hai la garanzia di ottenere il set di risultati corretto.
Considera il codice seguente, che ha una query esterna con un filtro WHERE su una tabella derivata, che a sua volta è basata su un'espressione di tabella con un filtro TOP:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; Questa query è ovviamente non deterministica a causa della mancanza di una clausola ORDER BY nell'espressione della tabella. Quando l'ho eseguito, SQL Server ha avuto accesso alle prime tre righe con date degli ordini precedenti al 2018, quindi ho ottenuto un set vuoto come output:
orderid orderdate ----------- ---------- (0 rows affected)
Come accennato, l'uso di TOP nell'espressione della tabella ha impedito il disinnesto/sostituzione dell'espressione della tabella qui. Se SQL Server avesse annullato l'annidamento dell'espressione della tabella, il processo di sostituzione avrebbe prodotto l'equivalente della query seguente:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
Anche questa query non è deterministica a causa della mancanza della clausola ORDER BY, ma chiaramente ha un significato diverso rispetto alla query originale. Se la tabella Sales.Orders ha almeno tre ordini effettuati nel 2018 o versioni successive, e lo fa, questa query restituirà necessariamente tre righe, a differenza della query originale. Ecco il risultato che ho ottenuto quando ho eseguito questa query:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
Nel caso in cui la natura non deterministica delle due query precedenti ti confonda, ecco un esempio con una query deterministica:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; L'espressione della tabella filtra i tre ordini con gli ID ordine più bassi. La query esterna filtra quindi da quei tre ordini solo quelli che sono stati effettuati a partire dall'8 luglio 2017. Si scopre che esiste un solo ordine idoneo. Questa query genera il seguente output:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Si supponga che SQL Server abbia annullato l'annidamento dell'espressione della tabella nella query originale, con il processo di sostituzione risultante nell'equivalente della query seguente:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
Il significato di questa query è diverso dalla query originale. Questa query filtra prima gli ordini effettuati a partire dall'8 luglio 2017, quindi filtra i primi tre tra quelli con gli ID ordine più bassi. Questa query genera il seguente output:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
Per evitare di modificare il significato della query originale, SQL Server non applica qui l'annullamento dell'annidamento/la sostituzione.
Gli ultimi due esempi prevedevano un semplice mix di filtraggio WHERE e TOP, ma potrebbero esserci ulteriori elementi di conflitto derivanti dall'annullamento dell'annidamento. Ad esempio, cosa succede se hai specifiche di ordinamento diverse nell'espressione della tabella e nella query esterna, come nell'esempio seguente:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; Ti rendi conto che se SQL Server avesse annullato l'annidamento dell'espressione della tabella, comprimendo le due diverse specifiche di ordinamento in una sola, la query risultante avrebbe avuto un significato diverso rispetto alla query originale. Avrebbe filtrato le righe sbagliate o presentato le righe dei risultati nell'ordine di presentazione errato. In breve, ti rendi conto perché la cosa sicura da fare per SQL Server è evitare di annullare l'annidamento/sostituzione di espressioni di tabella basate su query TOP e OFFSET-FETCH.
Ho accennato in precedenza che esiste un'eccezione alla regola secondo cui l'uso di TOP e OFFSET-FETCH impedisce il disannidamento. Questo è quando usi TOP (100) PERCENT in un'espressione di tabella nidificata, con o senza una clausola ORDER BY. SQL Server si rende conto che non è in corso alcun filtro reale e ottimizza l'opzione in uscita. Ecco un esempio che lo dimostra:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Il filtro TOP viene ignorato, viene annullata l'annidamento e ottieni lo stesso piano mostrato in precedenza per la query 1 nella figura 1.
Quando si utilizza OFFSET 0 ROWS senza clausola FETCH in un'espressione di tabella nidificata, non c'è nemmeno un vero filtro in corso. Quindi, in teoria SQL Server avrebbe potuto ottimizzare anche questa opzione e abilitare il disannidamento, ma alla data in cui scrivo non è così. Ecco un esempio che lo dimostra:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; Ottieni lo stesso piano di quello mostrato in precedenza per la query 2 nella figura 2, a dimostrazione del fatto che non si è verificato alcun annullamento dell'annidamento.
In precedenza ho spiegato che il processo di annullamento dell'annidamento/sostituzione in realtà non genera una nuova stringa di query che viene quindi ottimizzata, ma ha a che fare con le trasformazioni che SQL Server applica all'albero degli operatori logici. Esiste una differenza tra il modo in cui SQL Server ottimizza una query con espressioni di tabella nidificate rispetto a una query logicamente equivalente effettiva senza nidificazione. L'uso di espressioni di tabella come tabelle derivate e sottoquery impedisce la semplice parametrizzazione. Richiama la query 1 mostrata in precedenza nell'articolo:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Poiché la query utilizza tabelle derivate, non viene eseguita una semplice parametrizzazione. In altre parole, SQL Server non sostituisce le costanti con i parametri e quindi ottimizza la query, ma ottimizza la query con le costanti. Con predicati basati su costanti, SQL Server può unire i periodi intersecanti, che nel nostro caso hanno portato a un unico predicato nel piano, come mostrato in precedenza nella Figura 1.
Quindi, considera la seguente query (la chiameremo Query 3), che è un equivalente logico della Query 1, ma in cui applichi tu stesso l'annullamento dell'annidamento:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
Il piano per questa query è mostrato nella Figura 3.
 Figura 3:piano per la query 3
Figura 3:piano per la query 3
Questo piano è considerato sicuro per una semplice parametrizzazione, quindi le costanti vengono sostituite con parametri e, di conseguenza, i predicati non vengono uniti. La motivazione per la parametrizzazione sta ovviamente aumentando la probabilità di riutilizzo del piano durante l'esecuzione di query simili che differiscono solo per le costanti utilizzate.
Come accennato, l'uso di tabelle derivate nella query 1 ha impedito la semplice parametrizzazione. Allo stesso modo, l'uso di sottoquery impedirebbe la semplice parametrizzazione. Ad esempio, ecco la nostra precedente Query 3 con un predicato privo di significato basato su una sottoquery aggiunta alla clausola WHERE:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
Questa volta non viene eseguita una semplice parametrizzazione, che consente a SQL Server di unire i periodi intersecanti rappresentati dai predicati con le costanti, ottenendo lo stesso piano mostrato in precedenza nella Figura 1.
Se hai query con espressioni di tabella che utilizzano costanti ed è importante per te che SQL Server abbia parametrizzato il codice e per qualsiasi motivo non puoi parametrizzarlo da solo, ricorda che hai la possibilità di usare la parametrizzazione forzata con una guida del piano. Ad esempio, il codice seguente crea una guida al piano di questo tipo per la query 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; Esegui nuovamente la query 3 dopo aver creato la guida del piano:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Ottieni lo stesso piano di quello mostrato in precedenza nella Figura 3 con i predicati parametrizzati.
Al termine, esegui il codice seguente per eliminare la guida al piano:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
Prevenire lo snidamento
Tenere presente che SQL Server annulla l'annidamento delle espressioni di tabella per motivi di ottimizzazione. L'obiettivo è aumentare la probabilità di trovare un piano con un costo inferiore rispetto a quello senza disnidare. Questo è vero per la maggior parte delle regole di trasformazione applicate dall'ottimizzatore. Tuttavia, potrebbero esserci alcuni casi insoliti in cui vorresti impedire il disannidamento. Questo potrebbe essere per evitare errori (sì, in alcuni casi insoliti, l'annullamento dell'annidamento può causare errori) o per motivi di prestazioni per forzare una determinata forma del piano, in modo simile all'utilizzo di altri suggerimenti per le prestazioni. Ricorda, hai un modo semplice per inibire il disannidamento usando TOP con un numero molto grande.
Esempio per evitare errori
Inizierò con un caso in cui l'annullamento dell'annidamento delle espressioni di tabella può causare errori.
Considera la seguente query (la chiameremo Query 4):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Questo esempio è un po' forzato, nel senso che è facile riscrivere il secondo predicato del filtro in modo che non provochi mai un errore (sconto <0,1), ma è un esempio conveniente per me per illustrare il mio punto. Gli sconti non sono negativi. Quindi, anche se ci sono righe ordine con uno sconto zero, la query dovrebbe filtrarle (il primo predicato del filtro dice che lo sconto deve essere maggiore dello sconto minimo nella tabella). Tuttavia, non vi è alcuna garanzia che SQL Server valuterà i predicati in ordine scritto, quindi non puoi contare su un cortocircuito.
Esaminare il piano per la query 4 mostrato nella figura 4.
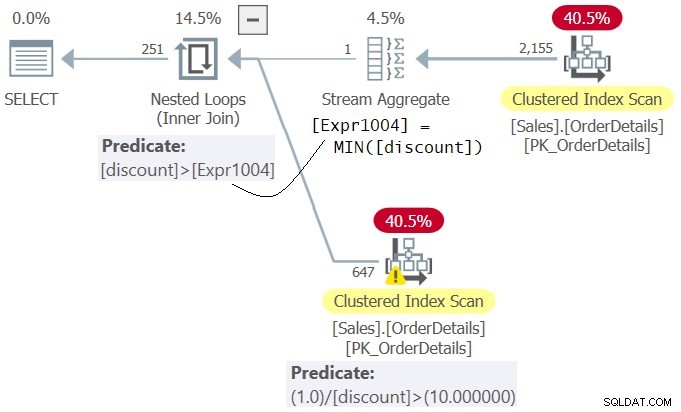 Figura 4:piano per la query 4
Figura 4:piano per la query 4
Si osservi che nel piano il predicato 1.0/sconto> 10.0 (secondo nella clausola WHERE) viene valutato prima dello sconto predicato>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Forse stai pensando di poter evitare l'errore utilizzando una tabella derivata, separando le attività di filtraggio in una interna e una esterna, in questo modo:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Tuttavia, SQL Server applica l'annullamento dell'annidamento della tabella derivata, ottenendo lo stesso piano mostrato in precedenza nella Figura 4 e, di conseguenza, anche questo codice ha esito negativo con un errore di divisione per zero:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Una semplice soluzione qui è introdurre un inibitore di unnesting, in questo modo (chiameremo questa soluzione Query 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Il piano per la query 5 è mostrato nella figura 5.
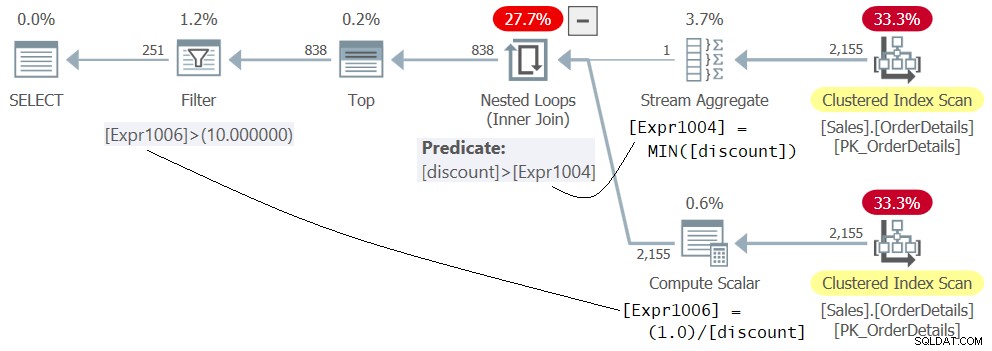 Figura 5:piano per la query 5
Figura 5:piano per la query 5
Non lasciarti confondere dal fatto che l'espressione 1.0 / sconto appare nella parte interna dell'operatore Nested Loops, come se fosse prima valutata. Questa è solo la definizione del membro Expr1006. La valutazione effettiva del predicato Expr1006> 10.0 viene applicata dall'operatore Filter come ultimo passaggio del piano dopo che le righe con lo sconto minimo sono state filtrate in precedenza dall'operatore Nested Loops. Questa soluzione funziona correttamente senza errori.
Esempio per motivi di prestazioni
Continuerò con un caso in cui la rimozione dell'annidamento delle espressioni di tabella può influire negativamente sulle prestazioni.
Inizia eseguendo il codice seguente per cambiare contesto al database PerformanceV5 e abilitare STATISTICS IO e TIME:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Considera la seguente query (la chiameremo Query 6):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
L'ottimizzatore identifica un indice di copertura di supporto con shipperid e orderdate come chiavi principali. Quindi crea un piano con una scansione ordinata dell'indice seguita da un operatore Stream Aggregate basato sull'ordine, come mostrato nel piano per la query 6 nella Figura 6.
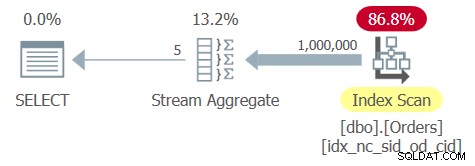 Figura 6:piano per la query 6
Figura 6:piano per la query 6
La tabella Ordini ha 1.000.000 di righe e la colonna di raggruppamento shipperid è molto densa:ci sono solo 5 ID mittente distinti, con una densità del 20% (percentuale media per valore distinto). L'applicazione di una scansione completa della foglia dell'indice comporta la lettura di alcune migliaia di pagine, con un tempo di esecuzione di circa un terzo di secondo sul mio sistema. Ecco le statistiche sulle prestazioni che ho ottenuto per l'esecuzione di questa query:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
L'albero dell'indice è attualmente profondo tre livelli.
Ridimensioniamo il numero di ordini di un fattore da 1.000 a 1.000.000.000, ma sempre con solo 5 spedizionieri distinti. Il numero di pagine nella foglia dell'indice aumenterebbe di un fattore 1.000 e l'albero dell'indice risulterebbe probabilmente in un livello aggiuntivo (quattro livelli di profondità). Questo piano ha un ridimensionamento lineare. Riusciresti a ottenere quasi 4.000.000 di letture logiche e un tempo di esecuzione di pochi minuti.
Quando è necessario calcolare un'aggregazione MIN o MAX rispetto a una tabella di grandi dimensioni, con una densità molto elevata nella colonna di raggruppamento (importante!) e un indice B-tree di supporto inserito nella colonna di raggruppamento e nella colonna di aggregazione, esiste una soluzione molto più ottimale forma del piano rispetto a quella nella Figura 6. Immagina una forma del piano che scansiona il piccolo insieme di ID mittente da un indice nella tabella Utenti e in un ciclo applica a ciascun mittente una ricerca rispetto all'indice di supporto su Ordini per ottenere l'aggregato. Con 1.000.000 di righe nella tabella, 5 ricerche implicherebbero 15 letture. Con 1.000.000.000 di righe, 5 ricerche implicherebbero 20 letture. Con un trilione di righe, 25 letture in totale. Chiaramente, un piano molto più ottimale. Puoi effettivamente ottenere un tale piano interrogando la tabella Shippers e ottenendo l'aggregato utilizzando una sottoquery aggregata scalare rispetto agli ordini, in questo modo (chiameremo questa soluzione Query 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
Il piano per questa query è mostrato nella Figura 7.
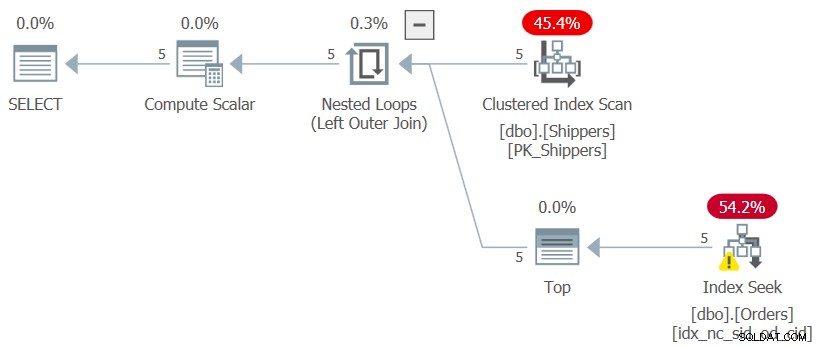 Figura 7:piano per la query 7
Figura 7:piano per la query 7
Viene raggiunta la forma del piano desiderata e i numeri delle prestazioni per l'esecuzione di questa query sono trascurabili come previsto:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Finché la colonna di raggruppamento è molto densa, la dimensione della tabella Ordini diventa praticamente insignificante.
Ma aspetta un momento prima di andare a festeggiare. È necessario mantenere solo i mittenti la cui data massima dell'ordine correlato nella tabella Ordini è successiva al 2018. Sembra un'aggiunta abbastanza semplice. Definisci una tabella derivata basata sulla Query 7 e applica il filtro nella query esterna, in questo modo (chiameremo questa soluzione Query 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Purtroppo, SQL Server annulla la query della tabella derivata, nonché la sottoquery, convertendo la logica di aggregazione nell'equivalente della logica della query raggruppata, con shipperid come colonna di raggruppamento. E il modo in cui SQL Server sa ottimizzare una query raggruppata si basa su un singolo passaggio sui dati di input, risultando in un piano molto simile a quello mostrato in precedenza nella Figura 6, solo con il filtro aggiuntivo. Il piano per la query 8 è mostrato nella figura 8.
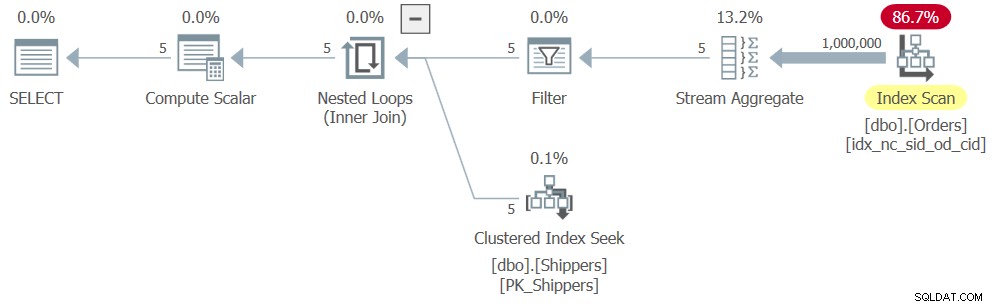 Figura 8:piano per la query 8
Figura 8:piano per la query 8
Di conseguenza, il ridimensionamento è lineare e i numeri delle prestazioni sono simili a quelli della query 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
La soluzione è introdurre un inibitore disnidante. Questo può essere fatto aggiungendo un filtro TOP all'espressione della tabella su cui si basa la tabella derivata, in questo modo (chiameremo questa soluzione Query 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Il piano per questa query è mostrato nella Figura 9 e ha la forma del piano desiderata con le ricerche:
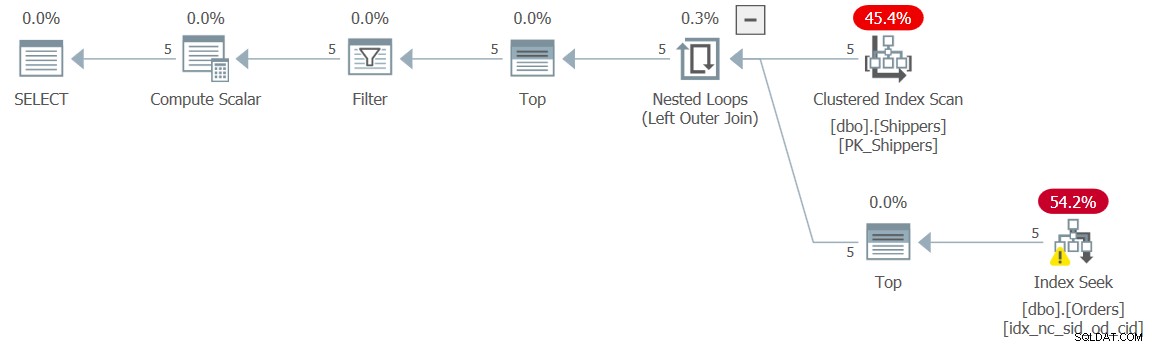 Figura 9:piano per la query 9
Figura 9:piano per la query 9
I numeri delle prestazioni per questa esecuzione sono quindi ovviamente trascurabili:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Un'altra opzione ancora è impedire l'annullamento dell'annidamento della sottoquery, sostituendo l'aggregato MAX con un filtro TOP (1) equivalente, in questo modo (chiameremo questa soluzione Query 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Il piano per questa query è mostrato nella Figura 10 e, di nuovo, ha la forma desiderata con le ricerche.
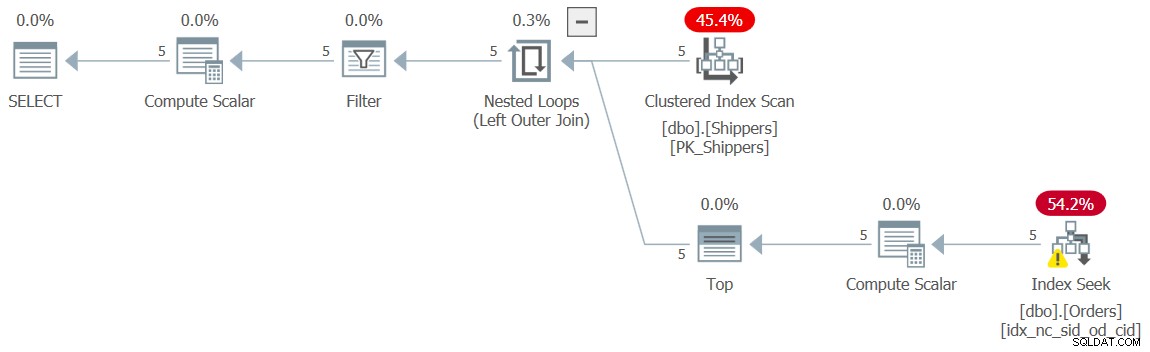 Figura 10:piano per la query 10
Figura 10:piano per la query 10
Ho ottenuto i noti numeri di prestazioni trascurabili per questa esecuzione:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Al termine, esegui il codice seguente per interrompere la segnalazione delle statistiche sul rendimento:
SET STATISTICS IO, TIME OFF;
Riepilogo
In questo articolo ho continuato la discussione iniziata il mese scorso sull'ottimizzazione delle tabelle derivate. Questo mese mi sono concentrato sull'annullamento dell'annidamento delle tabelle derivate. Ho spiegato che in genere il disannidamento si traduce in un piano più ottimale rispetto a senza disannidamento, ma ho anche trattato esempi in cui è indesiderabile. Ho mostrato un esempio in cui l'annullamento dell'annidamento ha provocato un errore e un esempio con conseguente degrado delle prestazioni. Ho dimostrato come prevenire il disinnesto applicando un inibitore di disinnesto come TOP.
Il mese prossimo continuerò l'esplorazione delle espressioni di tabelle con nome, spostando l'attenzione sui CTE.