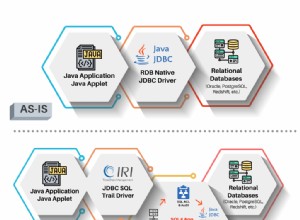
Questo articolo è la quinta parte di una serie sulle espressioni di tabella. Nella parte 1 ho fornito lo sfondo alle espressioni della tabella. Nella Parte 2, Parte 3 e Parte 4, ho trattato sia gli aspetti logici che quelli di ottimizzazione delle tabelle derivate. Questo mese inizio la copertura delle espressioni di tabella comuni (CTE). Come con le tabelle derivate, affronterò prima il trattamento logico dei CTE e in futuro passerò alle considerazioni sull'ottimizzazione.
Nei miei esempi userò un database di esempio chiamato TSQLV5. Puoi trovare lo script che lo crea e lo popola qui e il suo diagramma ER qui.
CTE
Iniziamo con il termine espressione di tabella comune . Né questo termine, né il suo acronimo CTE, compaiono nelle specifiche dello standard SQL ISO/IEC. Quindi potrebbe essere che il termine abbia avuto origine in uno dei prodotti di database e successivamente adottato da alcuni degli altri fornitori di database. Puoi trovarlo nella documentazione di Microsoft SQL Server e del database SQL di Azure. T-SQL lo supporta a partire da SQL Server 2005. Lo standard utilizza il termine espressione di query per rappresentare un'espressione che definisce uno o più CTE, inclusa la query esterna. Usa il termine con elemento elenco per rappresentare ciò che T-SQL chiama CTE. A breve fornirò la sintassi per un'espressione di query.
La fonte del termine a parte, espressione di tabella comune o CTE , è il termine comunemente usato dai professionisti di T-SQL per la struttura oggetto di questo articolo. Quindi, prima, analizziamo se si tratta di un termine appropriato. Abbiamo già concluso che il termine espressione di tabella è appropriato per un'espressione che restituisce concettualmente una tabella. Tabelle derivate, CTE, viste e funzioni con valori di tabelle inline sono tutti i tipi di espressioni di tabelle con nome che T-SQL supporta. Quindi, l'espressione tabella parte di espressione di tabella comune sembra certamente appropriato. Per quanto riguarda il comune parte del termine, probabilmente ha a che fare con uno dei vantaggi di progettazione dei CTE rispetto alle tabelle derivate. Ricorda che non puoi riutilizzare il nome della tabella derivata (o più precisamente il nome della variabile di intervallo) più di una volta nella query esterna. Al contrario, il nome CTE può essere utilizzato più volte nella query esterna. In altre parole, il nome CTE è comune alla query esterna. Ovviamente, dimostrerò questo aspetto del design in questo articolo.
I CTE offrono vantaggi simili alle tabelle derivate, incluso lo sviluppo di soluzioni modulari, il riutilizzo di alias di colonna, l'interazione indiretta con le funzioni della finestra in clausole che normalmente non le consentono, il supporto di modifiche che si basano indirettamente su TOP o OFFSET FETCH con la specifica dell'ordine, e altri. Ma ci sono alcuni vantaggi di progettazione rispetto alle tabelle derivate, che tratterò in dettaglio dopo aver fornito la sintassi per la struttura.
Sintassi
Ecco la sintassi dello standard per un'espressione di query:
7.17
Funzione
Specifica una tabella.
Formato
[
[
AS
|
[
|
[
|
[
|
[
CORRISPONDENTE [ BY
FETCH { FIRST | AVANTI } [
|
7.18
Funzione
Specificare la generazione di informazioni sull'ordinamento e sul rilevamento del ciclo nel risultato di espressioni di query ricorsive.
Formato
SEARCH
DEPTH FIRST BY
CYCLE
PREDEFINITO
7.3
Funzione
Specificare un insieme di
Il termine standard espressione di query rappresenta un'espressione che coinvolge una clausola WITH, un con elenco , che è composto da uno o più con elementi di elenco e una query esterna. T-SQL si riferisce allo standard con elemento elenco come CTE.
T-SQL non supporta tutti gli elementi di sintassi standard. Ad esempio, non supporta alcuni degli elementi di query ricorsivi più avanzati che consentono di controllare la direzione della ricerca e gestire i cicli in una struttura grafica. Le query ricorsive sono al centro dell'articolo del prossimo mese.
Ecco la sintassi T-SQL per una query semplificata su un CTE:
Ecco un esempio per una semplice query su un CTE che rappresenta i clienti USA:
Troverai le stesse tre parti in una dichiarazione contro un CTE come faresti con una dichiarazione contro una tabella derivata:
La differenza nel design dei CTE rispetto alle tabelle derivate è dove nel codice si trovano questi tre elementi. Con le tabelle derivate, la query interna viene nidificata all'interno della clausola FROM della query esterna e il nome dell'espressione della tabella viene assegnato dopo l'espressione della tabella stessa. Gli elementi sono in qualche modo intrecciati. Al contrario, con le CTE, il codice separa i tre elementi:prima si assegna il nome dell'espressione della tabella; secondo si specifica l'espressione della tabella, dall'inizio alla fine senza interruzioni; terzo si specifica la query esterna, dall'inizio alla fine senza interruzioni. Successivamente, in "Considerazioni sul design", spiegherò le implicazioni di queste differenze di design.
Una parola sui CTE e sull'uso di un punto e virgola come terminatore di istruzioni. Sfortunatamente, a differenza dell'SQL standard, T-SQL non ti obbliga a terminare tutte le istruzioni con un punto e virgola. Tuttavia, ci sono pochissimi casi in T-SQL in cui senza un terminatore il codice è ambiguo. In questi casi, la risoluzione è obbligatoria. Uno di questi casi riguarda il fatto che la clausola WITH viene utilizzata per molteplici scopi. Uno è definire un CTE, un altro è definire un suggerimento tabella per una query e ci sono alcuni casi d'uso aggiuntivi. Ad esempio, nell'istruzione seguente viene utilizzata la clausola WITH per forzare il livello di isolamento serializzabile con un suggerimento di tabella:
Il potenziale di ambiguità è quando hai un'istruzione non terminata che precede una definizione CTE, nel qual caso il parser potrebbe non essere in grado di dire se la clausola WITH appartiene alla prima o alla seconda istruzione. Ecco un esempio che lo dimostra:
Qui il parser non può dire se la clausola WITH deve essere utilizzata per definire un suggerimento di tabella per la tabella Customers nella prima istruzione o avviare una definizione CTE. Viene visualizzato il seguente errore:
La soluzione è ovviamente terminare l'istruzione che precede la definizione CTE, ma come best practice, dovresti davvero terminare tutte le tue affermazioni:
Potresti aver notato che alcune persone iniziano le loro definizioni CTE con un punto e virgola come pratica, in questo modo:
Il punto in questa pratica è ridurre il potenziale di errori futuri. Cosa succede se in un secondo momento qualcuno aggiunge un'istruzione non terminata subito prima della definizione CTE nello script e non si preoccupa di controllare lo script completo, piuttosto solo la sua affermazione? Il tuo punto e virgola subito prima che la clausola WITH diventi effettivamente il loro terminatore di istruzione. Puoi certamente vedere la praticità di questa pratica, ma è un po' innaturale. Ciò che è raccomandato, anche se più difficile da ottenere, è instillare buone pratiche di programmazione nell'organizzazione, inclusa la cessazione di tutte le dichiarazioni.
In termini di regole di sintassi che si applicano all'espressione di tabella utilizzata come query interna nella definizione CTE, sono le stesse che si applicano all'espressione di tabella utilizzata come query interna in una definizione di tabella derivata. Quelli sono:
Per i dettagli, vedere la sezione "Un'espressione di tabella è una tabella" nella Parte 2 della serie.
Se si esaminano sviluppatori T-SQL esperti per sapere se preferiscono utilizzare tabelle derivate o CTE, non tutti saranno d'accordo su quale sia il migliore. Naturalmente, persone diverse hanno preferenze di stile diverse. A volte uso tabelle derivate e talvolta CTE. È utile essere in grado di identificare consapevolmente le differenze di design del linguaggio specifico tra i due strumenti e scegliere in base alle tue priorità in una determinata soluzione. Con il tempo e l'esperienza, fai le tue scelte in modo più intuitivo.
Inoltre, è importante non confondere l'uso di espressioni di tabella e tabelle temporanee, ma questa è una discussione relativa alle prestazioni che affronterò in un prossimo articolo.
I CTE hanno funzionalità di query ricorsive e le tabelle derivate no. Quindi, se hai bisogno di fare affidamento su quelli, andresti naturalmente con i CTE. Le query ricorsive sono al centro dell'articolo del prossimo mese.
Nella parte 2 ho spiegato che vedo l'annidamento di tabelle derivate come un'aggiunta di complessità al codice, poiché rende difficile seguire la logica. Ho fornito il seguente esempio, identificando gli anni dell'ordine in cui più di 70 clienti hanno effettuato ordini:
I CTE non supportano la nidificazione. Quindi, quando esamini o risolvi una soluzione basata su CTE, non ti perdi nella logica annidata. Invece di annidare, crei soluzioni più modulari definendo più CTE sotto la stessa istruzione WITH, separati da virgole. Ciascuno dei CTE si basa su una query scritta dall'inizio alla fine senza interruzioni. Lo vedo come una buona cosa dal punto di vista della chiarezza del codice e della manutenibilità.
Ecco una soluzione all'attività di cui sopra utilizzando CTE:
Mi piace di più la soluzione basata su CTE. Ma ancora una volta, chiedi agli sviluppatori esperti quale delle due soluzioni precedenti preferiscono e non saranno tutti d'accordo. Alcuni in realtà preferiscono la logica annidata e la possibilità di vedere tutto in un unico posto.
Un chiaro vantaggio dei CTE rispetto alle tabelle derivate è quando è necessario interagire con più istanze della stessa espressione di tabella nella soluzione. Ricorda il seguente esempio basato su tabelle derivate dalla Parte 2 della serie:
Questa soluzione restituisce gli anni degli ordini, i conteggi degli ordini per anno e la differenza tra i conteggi dell'anno corrente e dell'anno precedente. Sì, potresti farlo più facilmente con la funzione LAG, ma il mio obiettivo qui non è trovare il modo migliore per svolgere questo compito molto specifico. Uso questo esempio per illustrare alcuni aspetti della progettazione del linguaggio delle espressioni di tabelle con nome.
Il problema con questa soluzione è che non è possibile assegnare un nome a un'espressione di tabella e riutilizzarla nella stessa fase di elaborazione della query logica. Assegna a una tabella derivata il nome dell'espressione della tabella stessa nella clausola FROM. Se si definisce e si denomina una tabella derivata come primo input di un join, non è possibile riutilizzare anche il nome della tabella derivata come secondo input dello stesso join. Se hai bisogno di unire due istanze della stessa espressione di tabella, con le tabelle derivate non hai altra scelta che duplicare il codice. Questo è quello che hai fatto nell'esempio sopra. Al contrario, il nome CTE viene assegnato come primo elemento del codice tra i tre sopra citati (nome CTE, query interna, query esterna). In termini di elaborazione logica della query, quando si arriva alla query esterna, il nome CTE è già definito e disponibile. Ciò significa che puoi interagire con più istanze del nome CTE nella query esterna, in questo modo:
Questa soluzione presenta un chiaro vantaggio di programmabilità rispetto a quella basata su tabelle derivate in quanto non è necessario mantenere due copie della stessa espressione di tabella. C'è altro da dire al riguardo dal punto di vista dell'elaborazione fisica e confrontarlo con l'uso di tabelle temporanee, ma lo farò in un prossimo articolo incentrato sulle prestazioni.
Un vantaggio che il codice basato su tabelle derivate ha rispetto al codice basato su CTE ha a che fare con la proprietà di chiusura che dovrebbe possedere un'espressione di tabella. Ricorda che la proprietà di chiusura di un'espressione relazionale dice che sia gli input che l'output sono relazioni e che un'espressione relazionale può quindi essere utilizzata dove è prevista una relazione, come input per un'altra espressione relazionale. Allo stesso modo, un'espressione di tabella restituisce una tabella e dovrebbe essere disponibile come tabella di input per un'altra espressione di tabella. Questo vale per una query basata su tabelle derivate:puoi usarla dove è prevista una tabella. Ad esempio, puoi utilizzare una query basata su tabelle derivate come query interna di una definizione CTE, come nell'esempio seguente:
Tuttavia, lo stesso non vale per una query basata su CTE. Anche se concettualmente dovrebbe essere considerata un'espressione di tabella, non è possibile utilizzarla come query interna nelle definizioni di tabelle derivate, nelle sottoquery e negli stessi CTE. Ad esempio, il codice seguente non è valido in T-SQL:
La buona notizia è che puoi utilizzare una query basata su CTE come query interna nelle viste e nelle funzioni con valori di tabella in linea, che tratterò in articoli futuri.
Inoltre, ricorda che puoi sempre definire un altro CTE in base all'ultima query, quindi fare in modo che la query più esterna interagisca con quel CTE:
Dal punto di vista della risoluzione dei problemi, come accennato, di solito trovo più facile seguire la logica del codice basata su CTE, rispetto al codice basato su tabelle derivate. Tuttavia, le soluzioni basate su tabelle derivate hanno il vantaggio di poter evidenziare qualsiasi livello di annidamento ed eseguirlo in modo indipendente, come mostrato nella Figura 1.
Con i CTE le cose sono più complicate. Affinché il codice che coinvolge le CTE sia eseguibile, deve iniziare con una clausola WITH, seguita da una o più espressioni di tabella tra parentesi denominate separate da virgole, seguite da una query senza parentesi senza virgola precedente. Sei in grado di evidenziare ed eseguire qualsiasi query interna che sia veramente autonoma, così come il codice completo della soluzione; tuttavia, non è possibile evidenziare ed eseguire correttamente qualsiasi altra parte intermedia della soluzione. Ad esempio, la Figura 2 mostra un tentativo non riuscito di eseguire il codice che rappresenta C2.
Quindi, con i CTE, devi ricorrere a mezzi alquanto scomodi per poter risolvere un passaggio intermedio della soluzione. Ad esempio, una soluzione comune consiste nell'iniettare temporaneamente una query SELECT * FROM your_cte proprio sotto il CTE pertinente. Quindi evidenzi ed esegui il codice inclusa la query iniettata e, quando hai finito, elimini la query iniettata. La figura 3 mostra questa tecnica.
Il problema è che ogni volta che apporti modifiche al codice, anche quelle minori temporanee come quelle sopra, c'è la possibilità che quando tenti di ripristinare il codice originale, finirai per introdurre un nuovo bug.
Un'altra opzione è modellare il codice in modo leggermente diverso, in modo tale che ogni definizione CTE non prima inizi con una riga di codice separata simile a questa:
Quindi, ogni volta che vuoi eseguire una parte intermedia del codice fino a un determinato CTE, puoi farlo con modifiche minime al tuo codice. Usando un commento di riga si commenta solo quella riga di codice che corrisponde a quel CTE. Quindi evidenziare ed eseguire il codice fino a includere la query interna di CTE, che ora è considerata la query più esterna, come illustrato nella Figura 4.
Se non sei soddisfatto di questo stile, hai ancora un'altra opzione. È possibile utilizzare un commento di blocco che inizia subito prima della virgola che precede il CTE di interesse e termina dopo la parentesi aperta, come illustrato nella Figura 5.
Si riduce alle preferenze personali. In genere utilizzo la tecnica di query SELECT * iniettata temporaneamente.
C'è una certa limitazione nel supporto di T-SQL per i costruttori di valori di tabella rispetto allo standard. Se non hai familiarità con il costrutto, assicurati di controllare prima la Parte 2 della serie, dove lo descrivo in dettaglio. Mentre T-SQL consente di definire una tabella derivata in base a un costruttore di valori di tabella, non consente di definire un CTE in base a un costruttore di valori di tabella.
Ecco un esempio supportato che utilizza una tabella derivata:
Sfortunatamente, un codice simile che utilizza un CTE non è supportato:
Questo codice genera il seguente errore:
Ci sono un paio di soluzioni alternative, però. Uno consiste nell'utilizzare una query su una tabella derivata, che a sua volta è basata su un costruttore di valori di tabella, come query interna del CTE, in questo modo:
Un altro è ricorrere alla tecnica utilizzata dalle persone prima che i costruttori con valori di tabella venissero introdotti in T-SQL, utilizzando una serie di query FROMless separate da operatori UNION ALL, in questo modo:
Si noti che gli alias di colonna vengono assegnati subito dopo il nome CTE.
I due metodi vengono algebrizzati e ottimizzati allo stesso modo, quindi usa quello con cui ti senti più a tuo agio.
Uno strumento che uso abbastanza spesso nelle mie soluzioni è una tabella numerica ausiliaria. Un'opzione è creare una tabella numerica effettiva nel database e popolarla con una sequenza di dimensioni ragionevoli. Un altro è sviluppare una soluzione che produca una sequenza di numeri al volo. Per quest'ultima opzione, vuoi che gli input siano i delimitatori dell'intervallo desiderato (li chiameremo
Questo codice genera il seguente output:
Il primo CTE chiamato L0 si basa su un costruttore di valori di tabella con due righe. I valori effettivi sono insignificanti; l'importante è che abbia due righe. Quindi, c'è una sequenza di cinque CTE aggiuntivi denominati da L1 a L5, ciascuno dei quali applica un cross join tra due istanze del CTE precedente. Il codice seguente calcola il numero di righe potenzialmente generate da ciascuna delle CTE, dove @L è il numero di livello CTE:
Ecco i numeri che ottieni per ogni CTE:
Salire al livello 5 ti dà oltre quattro miliardi di righe. Questo dovrebbe essere sufficiente per qualsiasi caso d'uso pratico che mi viene in mente. Il passaggio successivo avviene nel CTE chiamato Nums. Utilizzare una funzione ROW_NUMBER per generare una sequenza di numeri interi che iniziano con 1 in base a un ordine non definito (ORDER BY (SELECT NULL)) e denominare la colonna del risultato rownum. Infine, la query esterna utilizza un filtro TOP basato sull'ordine rownum per filtrare tanti numeri quanto la cardinalità della sequenza desiderata (@high – @low + 1) e calcola il numero del risultato n come @low + rownum – 1.
Qui puoi davvero apprezzare la bellezza del design CTE e i risparmi che consente quando costruisci soluzioni in modo modulare. Infine, il processo di disnidificazione estrae 32 tabelle, ciascuna composta da due righe basate su costanti. Questo può essere visto chiaramente nel piano di esecuzione di questo codice, come mostrato nella Figura 6 usando SentryOne Plan Explorer.
Ciascun operatore Constant Scan rappresenta una tabella di costanti con due righe. Il fatto è che l'operatore Top è quello che richiede quelle righe e va in cortocircuito dopo aver ottenuto il numero desiderato. Nota le 10 righe indicate sopra la freccia che scorre nell'operatore Top.
So che l'obiettivo di questo articolo è il trattamento concettuale dei CTE e non considerazioni fisiche/prestazioni, ma guardando il piano puoi davvero apprezzare la brevità del codice rispetto alla prolissità di ciò che si traduce dietro le quinte.
Utilizzando le tabelle derivate, puoi effettivamente scrivere una soluzione che sostituisce ogni riferimento CTE con la query sottostante che rappresenta. Quello che ottieni è abbastanza spaventoso:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Formato
VALUES
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Sintassi errata vicino a 'UC'. Se questa deve essere un'espressione di tabella comune, è necessario terminare in modo esplicito l'istruzione precedente con un punto e virgola. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Considerazioni di progettazione
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Figura 1:può evidenziare ed eseguire parte del codice con tabelle derivate
Figura 1:può evidenziare ed eseguire parte del codice con tabelle derivate  Figura 2:impossibile evidenziare ed eseguire parte del codice con le CTE
Figura 2:impossibile evidenziare ed eseguire parte del codice con le CTE  Figura 3:Inietta SELECT * sotto il CTE pertinente
Figura 3:Inietta SELECT * sotto il CTE pertinente , cte_name AS (
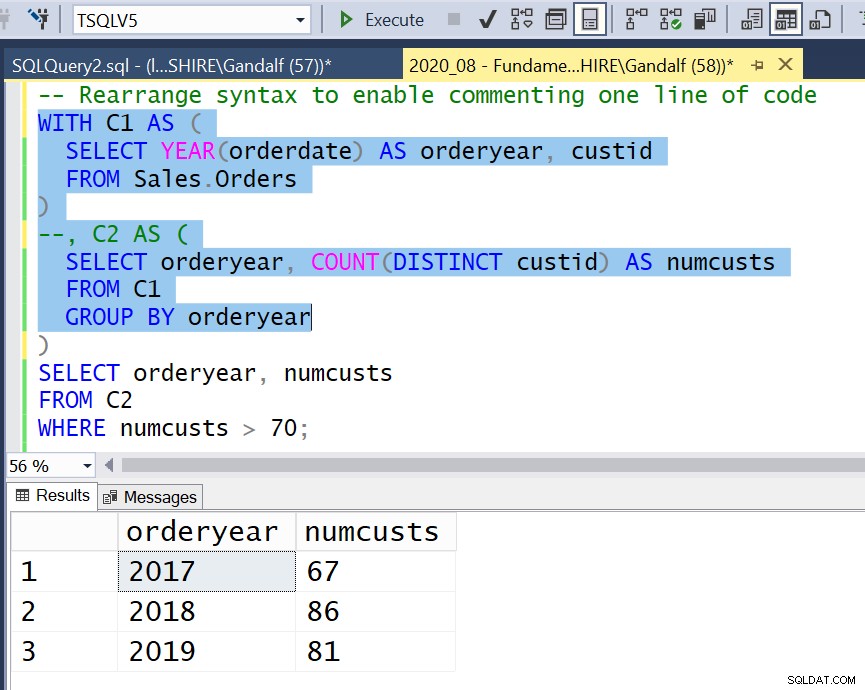 Figura 4:riorganizzare la sintassi per abilitare il commento di una riga di codice
Figura 4:riorganizzare la sintassi per abilitare il commento di una riga di codice  Figura 5:usa il commento del blocco
Figura 5:usa il commento del blocco Costruttore di valori di tabella
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Sintassi errata vicino alla parola chiave 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Produrre una sequenza di numeri
@low e @high ). Vuoi che la tua soluzione supporti gamme potenzialmente ampi. Ecco la mia soluzione per questo scopo, utilizzando CTE, con una richiesta per l'intervallo da 1001 a 1010 in questo esempio specifico:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Cardinalità L0 2 L1 4 L2 16 L3 256 L4 65.536 L5 4.294.967.296  Figura 6:piano per la generazione di query sequenza di numeri
Figura 6:piano per la generazione di query sequenza di numeri DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Riepilogo
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes