Le cattive prestazioni delle query sono il problema più comune che i DBA devono affrontare. Esistono numerosi modi per raccogliere, elaborare e analizzare i dati relativi alle prestazioni delle query:abbiamo trattato uno degli strumenti più popolari, pt-query-digest, in alcuni dei nostri precedenti post sul blog:
Diventa una serie di blog MySQL DBA
- Analisi del carico di lavoro SQL utilizzando pt-query-digest
- Analisi approfondita del carico di lavoro SQL utilizzando pt-query-digest
Tuttavia, quando si utilizza ClusterControl, ciò non è sempre necessario. Puoi utilizzare i dati disponibili in ClusterControl per risolvere il tuo problema. In questo post del blog, esamineremo come ClusterControl può aiutarti a risolvere i problemi relativi alle prestazioni delle query.
Può succedere che una query non possa essere completata in modo tempestivo. La query potrebbe essere bloccata a causa di alcuni problemi di blocco, potrebbe non essere ottimale o non essere indicizzata correttamente oppure potrebbe essere troppo pesante per essere completata in un ragionevole lasso di tempo. Tieni presente che un paio di join non indicizzati possono facilmente scansionare miliardi di righe se disponi di un database di produzione di grandi dimensioni. Qualunque cosa sia successa, la query sta probabilmente utilizzando alcune delle risorse, che si tratti di CPU o I/O per una query non ottimizzata o anche solo di blocchi di riga. Tali risorse sono necessarie anche per altre query e potrebbero rallentare seriamente le cose. Uno dei compiti molto semplici ma importanti sarebbe individuare la query offensiva e fermarla.
È abbastanza facile da fare dall'interfaccia ClusterControl. Vai alla scheda Query Monitor -> sezione Query in esecuzione:dovresti vedere un output simile allo screenshot qui sotto.
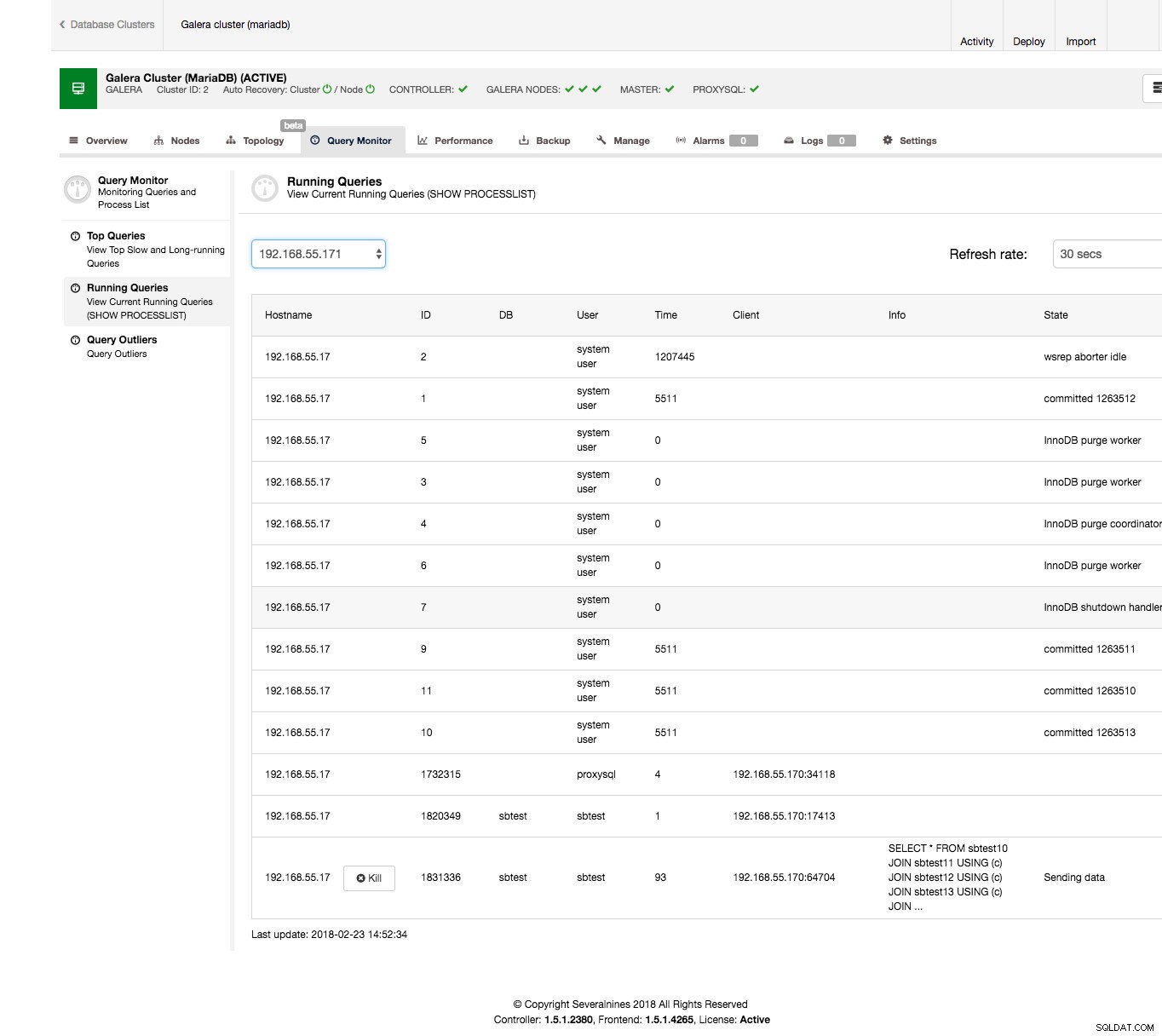
Come puoi vedere, abbiamo un mucchio di domande bloccate. Di solito la query offensiva è quella che richiede molto tempo, potresti volerla uccidere. Potresti anche voler indagare ulteriormente per assicurarti di scegliere quello corretto. Nel nostro caso, vediamo chiaramente un SELECT... FOR UPDATE che unisce un paio di tabelle e che è nello stato "Invio dati", il che significa che sta elaborando i dati, per gli ultimi 90 secondi.
Un altro tipo di domanda a cui un DBA potrebbe dover rispondere è:quali query richiedono più tempo per essere eseguite? Questa è una domanda comune, poiché tali query possono essere un frutto a basso impatto:possono essere ottimizzabili e maggiore è il tempo di esecuzione di una determinata query in un intero mix di query, maggiore è il guadagno dalla sua ottimizzazione. È un'equazione semplice:se una query è responsabile del 50% del tempo di esecuzione totale, renderla 10 volte più veloce darà risultati molto migliori rispetto all'ottimizzazione di una query che è responsabile solo dell'1% del tempo di esecuzione totale.
ClusterControl può aiutarti a rispondere a tali domande, ma prima dobbiamo assicurarci che Query Monitor sia abilitato. È possibile attivare Query Monitor su ON nella pagina Query Monitor. Inoltre puoi configurare l'opzione "Tempo di query lungo" e "Query di registro che non utilizzano indici" in Impostazioni in base al tuo carico di lavoro:
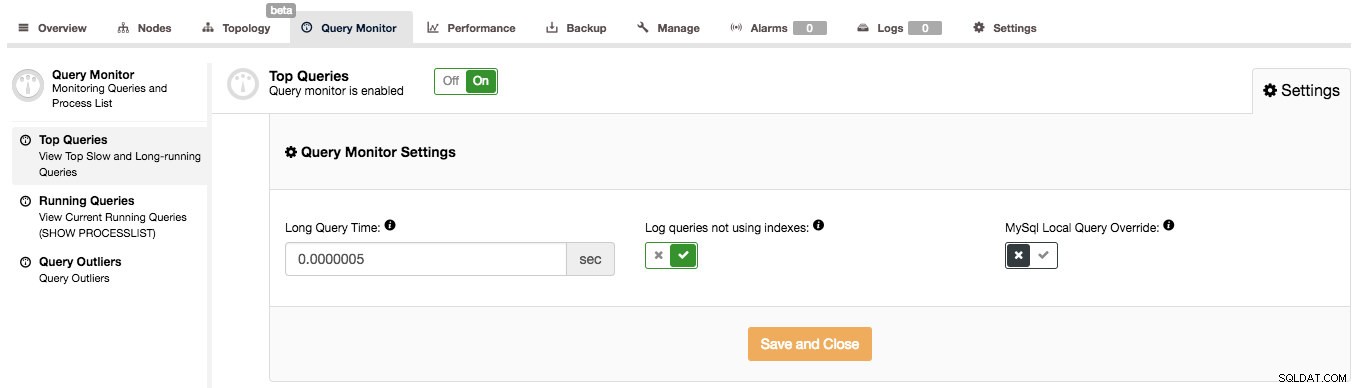
Query Monitor in ClusterControl funziona in due modalità, a seconda che lo schema delle prestazioni sia disponibile con i dati richiesti sulle query in esecuzione o meno. Se è disponibile (e questo è vero per impostazione predefinita in MySQL 5.6 e versioni successive), Performance Schema verrà utilizzato per raccogliere i dati delle query, riducendo al minimo l'impatto sul sistema. In caso contrario, verrà utilizzato il registro delle query lente e verranno utilizzate tutte le impostazioni visibili nello screenshot sopra. Questi sono spiegati abbastanza bene nell'interfaccia utente, quindi non è necessario farlo qui. Quando Query Monitor utilizza Performance Schema, tali impostazioni non vengono utilizzate (tranne per attivare/disattivare Query Monitor per abilitare/disabilitare la raccolta dei dati).
Dopo aver confermato che Query Monitor è abilitato in ClusterControl, puoi andare su Query Monitor -> Top Query, dove ti verrà presentata una schermata simile alla seguente:
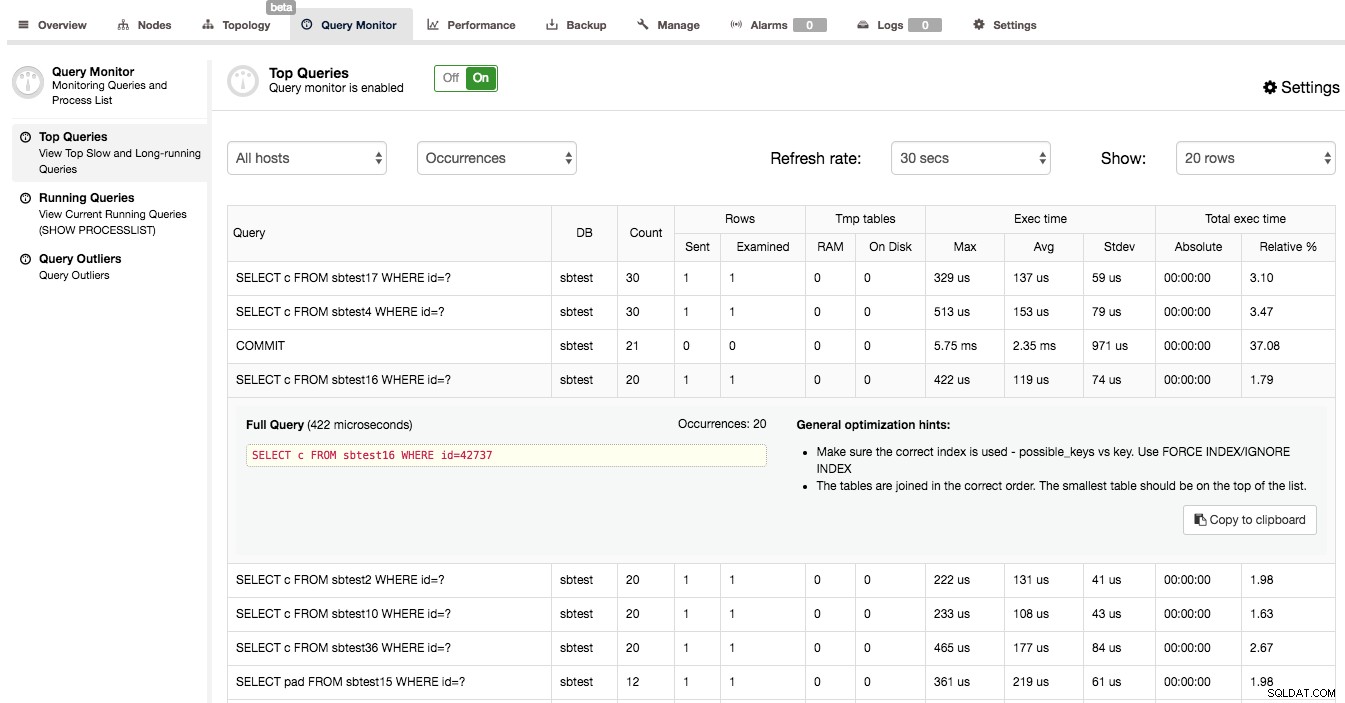
Quello che puoi vedere qui è un elenco delle query più costose (in termini di tempo di esecuzione) che hanno colpito il nostro cluster. Ciascuno di essi ha ulteriori dettagli:quante volte è stato eseguito, quante righe sono state esaminate o inviate al client, come è variato il tempo di esecuzione, quanto tempo il cluster ha impiegato per eseguire un determinato tipo di query. Le query sono raggruppate per tipo e schema di query.
Potresti essere sorpreso di scoprire che il luogo principale in cui viene speso il tempo di esecuzione è una query "COMMIT". In realtà, questo è abbastanza tipico per le query OLTP rapide eseguite sul cluster Galera. Commettere una transazione è un processo costoso perché la certificazione deve avvenire. Questo fa sì che COMMIT sia una delle query che richiedono più tempo nel mix di query.
Quando fai clic su una query, puoi vedere la query completa, il tempo massimo di esecuzione, il numero di occorrenze, alcuni suggerimenti generali per l'ottimizzazione e un output SPIEGAZIONE per essa, molto utile per identificare se c'è qualcosa che non va. Nel nostro esempio abbiamo verificato un SELECT … FOR UPDATE con un numero elevato di righe esaminate. Come previsto, questa query è un esempio di SQL terribile:un JOIN che non utilizza alcun indice. Puoi vedere sull'output di EXPLAIN che non viene utilizzato alcun indice, nemmeno uno solo è stato considerato possibile da usare. Non c'è da stupirsi se questa query ha avuto un grave impatto sulle prestazioni del nostro cluster.
Un altro modo per ottenere informazioni dettagliate sulle prestazioni delle query è guardare Query Monitor -> Query Outliers. Questo è fondamentalmente un elenco di query le cui prestazioni differiscono in modo significativo dalla loro media.
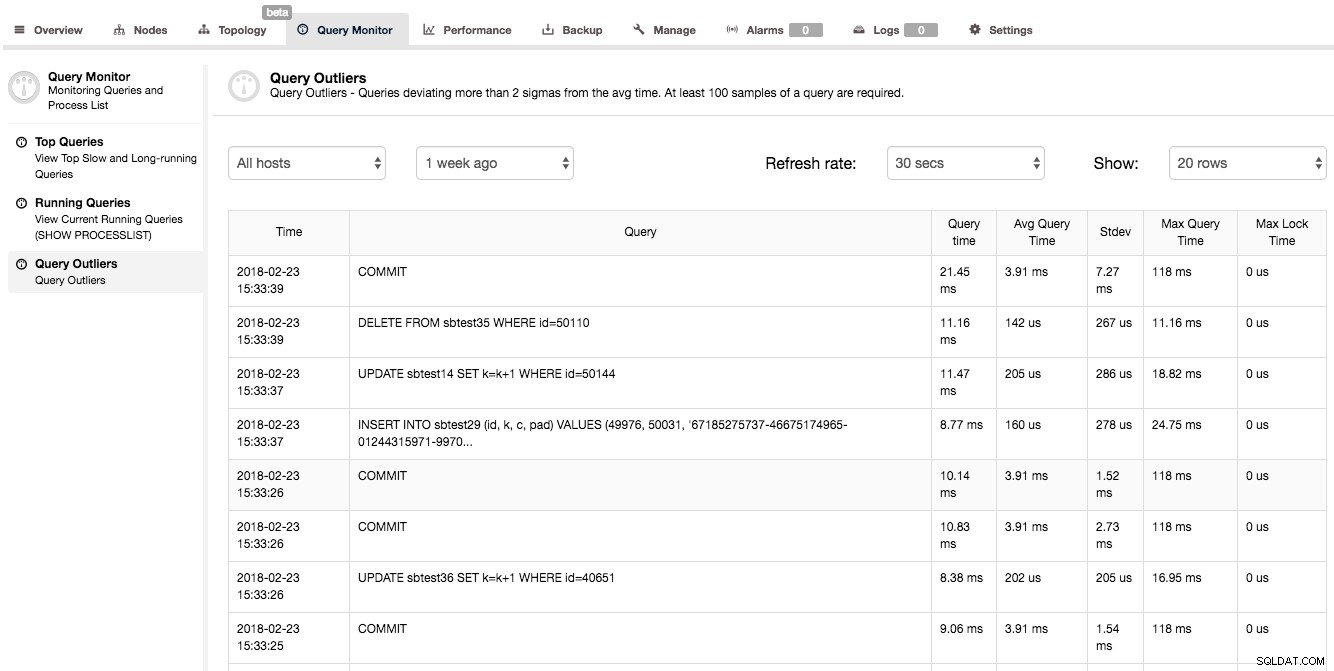
Come puoi vedere nello screenshot sopra, la seconda query ha impiegato 0,01116 s (il tempo è mostrato in millisecondi) mentre il tempo medio di esecuzione per quella query è molto più basso (0,000142 s). Abbiamo anche alcune informazioni statistiche aggiuntive sulla deviazione standard e sul tempo massimo di esecuzione delle query. Tale elenco di query potrebbe sembrare non molto utile - non è proprio vero. Quando vedi una query in questo elenco, significa che qualcosa era diverso dal solito:la query non è stata completata in tempo normale. Potrebbe essere un'indicazione di alcuni problemi di prestazioni sul tuo sistema e un segnale che dovresti esaminare altre metriche e verificare se è successo qualcos'altro in quel momento.
Le persone tendono a concentrarsi sul raggiungimento delle massime prestazioni, dimenticando che non è sufficiente avere un throughput elevato, ma deve anche essere coerente. Agli utenti piace che le prestazioni siano stabili:potresti essere in grado di spremere più transazioni al secondo dal tuo sistema, ma se ciò significa che alcune transazioni inizieranno a bloccarsi per secondi, non ne vale la pena. L'esame dell'istogramma delle query in ClusterControl consente di identificare tali problemi di coerenza nel mix di query.
Buon monitoraggio delle query!
PS.:Per iniziare con ClusterControl, fai clic qui!