L'indirizzo IP virtuale è un indirizzo IP che non corrisponde a un'effettiva interfaccia di rete fisica. Fluttua tra più interfacce di rete e solo un'interfaccia attiva conterrà l'indirizzo IP per la tolleranza agli errori e la mobilità. ClusterControl utilizza Keepalived per fornire l'integrazione dell'indirizzo IP virtuale con i servizi di bilanciamento del carico del database per eliminare qualsiasi singolo punto di errore (SPOF) a livello di bilanciamento del carico.
In questo post del blog, ti mostreremo come ClusterControl configura l'indirizzo IP virtuale e cosa puoi aspettarti in caso di failover o failback. Comprendere questo comportamento è fondamentale per ridurre al minimo qualsiasi interruzione del servizio e semplificare le operazioni di manutenzione che devono essere eseguite occasionalmente.
Requisiti
Ci sono alcuni requisiti per eseguire Keepalived nella tua rete:
- Il protocollo IP 112 (Virtual Router Redundancy Protocol - VRRP) deve essere supportato nella rete. Alcune reti disabilitano il supporto per VRRP, in particolare le comunicazioni tra VLAN. Si prega di verificare con l'amministratore di rete.
- Se usi il multicast, la rete deve supportare la richiesta multicast (usa ip a | grep -i multicast). Altrimenti, puoi usare unicast tramite unicast_src_ip e unicast_peer opzioni. L'uso del multicast è utile quando si dispone di un ambiente dinamico come un ambiente cloud o quando l'assegnazione IP viene eseguita tramite DHCP.
- Un set di istanze VRRP deve utilizzare un virtual_router_id univoco valore, che non può essere condiviso tra altre istanze. In caso contrario, vedrai pacchetti fasulli e probabilmente interromperai il passaggio al backup principale.
- Se stai utilizzando un ambiente cloud come AWS, probabilmente dovrai utilizzare uno script esterno (suggerimento:utilizzare l'opzione "notifica") per dissociare e associare l'indirizzo IP virtuale (IP elastico) in modo che sia riconosciuto e instradabile da il router.
Distribuzione di Keepalived
Per installare Keepalived tramite ClusterControl, sono necessari due o più servizi di bilanciamento del carico installati da o importati in ClusterControl. Per l'utilizzo in produzione, consigliamo vivamente di eseguire il software di bilanciamento del carico su un host autonomo e non collocato insieme ai nodi del database.
Dopo aver gestito almeno due sistemi di bilanciamento del carico da ClusterControl, per installare Keepalived e abilitare l'indirizzo IP virtuale, vai su ClusterControl -> scegli il cluster -> Gestisci -> Load Balancer -> Keepalived:
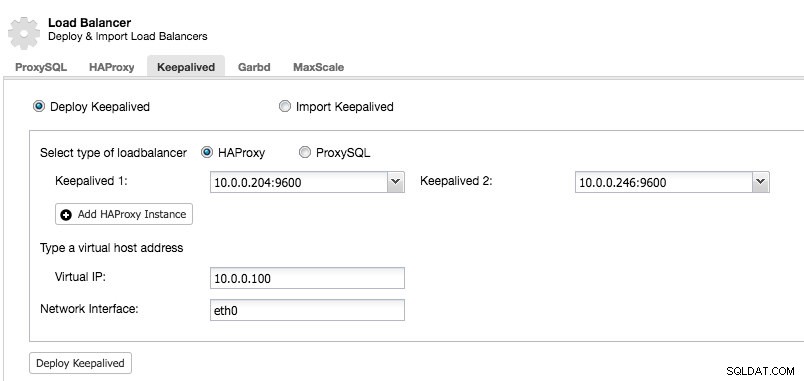
La maggior parte dei campi sono autoesplicativi. Puoi distribuire un nuovo set di Keepalid o importare istanze Keepalived esistenti. I campi importanti includono l'indirizzo IP virtuale effettivo e l'interfaccia di rete in cui esisterà l'indirizzo IP virtuale. Se gli host utilizzano due nomi di interfaccia diversi, specifica il nome dell'interfaccia dell'host Keepalived 1, quindi modifica manualmente il file di configurazione su Keepalived 2 con un nome di interfaccia corretto in seguito.
Istanza VRRP
Al momento della scrittura, ClusterControl v1.5.1 installa Keepalived v1.3.5 (a seconda del sistema operativo host) e quanto segue è ciò che è configurato per l'istanza VRRP:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl configura l'istanza VRRP per comunicare tramite unicast. Con unicast, dobbiamo definire tutti i peer unicast degli altri nodi Keepalived. È meno dinamico ma funziona la maggior parte del tempo. Con il multicast, puoi rimuovere quelle linee (unicast_*) e fare affidamento sull'indirizzo IP multicast per il rilevamento e il peering dell'host. È più semplice ma è comunemente bloccato dagli amministratori di rete.
La parte successiva è l'indirizzo IP virtuale. Puoi specificare più indirizzi IP virtuali per istanza VRRP, separati da una nuova riga. Il bilanciamento del carico in HAProxy/ProxySQL e Keepalived allo stesso tempo richiede anche la possibilità di collegarsi a un indirizzo IP non locale, il che significa che non è assegnato a un dispositivo sul sistema locale. Ciò consente a un'istanza del servizio di bilanciamento del carico in esecuzione di associarsi a un IP che non è locale per il failover. Pertanto ClusterControl configura anche net.ipv4.ip_nonlocal_bind=1 dentro /etc/sysctl.conf.
La prossima direttiva è track_script , dove puoi specificare lo script per il processo di controllo dello stato che viene spiegato nella sezione successiva.
Controlli sanitari
ClusterControl configura Keepalived per eseguire controlli di integrità esaminando il codice di errore restituito da track_script. Nel file di configurazione di Keepalived, che per impostazione predefinita, si trova in /etc/keepalived/keepalived.conf, dovresti vedere qualcosa del genere:
track_script {
chk_proxysql
}Dove chiama chk_proxysql che contiene:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}Il comando "killall -0" restituisce il codice di uscita 0 se è presente un processo chiamato "proxysql" in esecuzione sull'host. In caso contrario, l'istanza dovrebbe retrocedere e iniziare ad avviare il failover come spiegato nella sezione successiva. Tieni presente che Keepalived supporta anche i componenti Linux Virtual Server (LVS) per eseguire controlli di integrità, dove è anche in grado di bilanciare il carico delle connessioni TCP/IP, in modo simile a HAProxy, ma questo non rientra nell'ambito di questo post del blog.
Simulare il failover
Per i componenti VRRP, Keepalived utilizza il protocollo VRRP (protocollo IP 112) per comunicare tra le istanze VRRP. Il valore di priorità più alto di un MASTER significa che il master avrà sempre il privilegio più elevato per mantenere l'indirizzo IP virtuale, a meno che non si configuri l'istanza con "nopreempt". Usiamo un esempio per spiegare meglio il flusso di failover e failback. Considera il seguente diagramma:
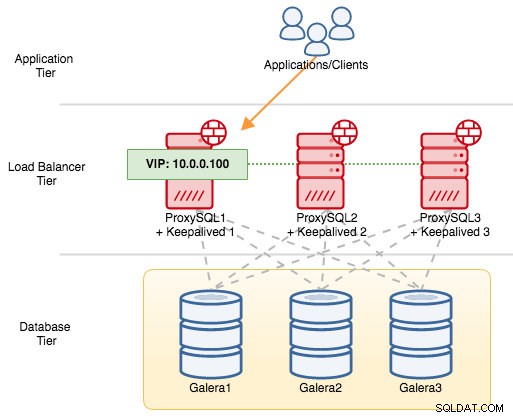
Ci sono tre istanze ProxySQL davanti a tre nodi MySQL Galera. Ogni host ProxySQL è configurato con Keepalived come MASTER con il seguente numero di priorità:
- ProxySQL1 - priorità 101
- ProxySQL2 - priorità 100
- ProxySQL3 - priorità 99
Quando Keepalived viene avviato come MASTER, prima pubblicizzerà il numero di priorità ai membri e quindi si assocerà all'indirizzo IP virtuale. A differenza dell'istanza BACKUP, osserverà l'annuncio e assegnerà l'indirizzo IP virtuale solo dopo aver confermato di potersi elevare a MASTER.
Tieni presente che se uccidi manualmente il processo "proxysql" o "haproxy" tramite il comando kill, systemd process manager tenterà per impostazione predefinita di ripristinare il processo che è stato interrotto in modo sgraziato. Inoltre, se il ripristino automatico di ClusterControl è attivato, ClusterControl tenterà sempre di avviare il processo anche se si esegue un arresto pulito tramite systemd (systemctl stop proxysql). Per simulare al meglio l'errore, suggeriamo all'utente di disattivare la funzione di ripristino automatico di ClusterControl o semplicemente di spegnere il server ProxySQL per interrompere la comunicazione.
Se chiudiamo ProxySQL1, l'indirizzo IP virtuale verrà sottoposto a failover sull'host successivo che ha una priorità più alta in quel particolare momento (che è ProxySQL2):
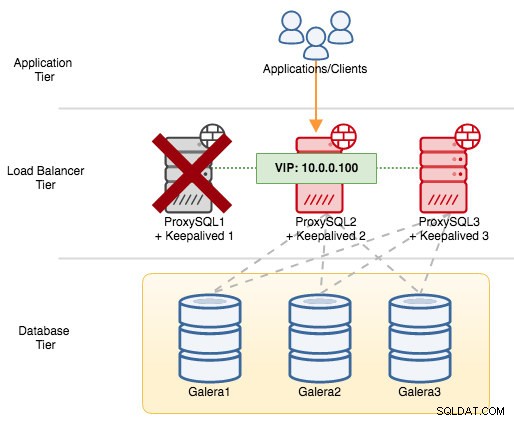
Vedresti quanto segue nel syslog del nodo guasto:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Mentre si trovava sul nodo secondario, si è verificato quanto segue:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.In questo caso, il failover ha richiesto circa 3 secondi, con un tempo massimo di failover intervallo + int_annuncio . Dietro le quinte, l'endpoint del database è cambiato e il traffico del database viene instradato tramite ProxySQL2 senza che le applicazioni se ne accorgano.
Quando ProxySQL1 torna online, imporrà una nuova elezione MASTER e acquisirà l'indirizzo IP a causa della priorità più elevata:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Allo stesso tempo, ProxySQL2 si retrocede allo stato BACKUP e rimuove l'indirizzo IP virtuale dall'interfaccia di rete:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.A questo punto, ProxySQL1 è di nuovo online e diventa il servizio di bilanciamento del carico attivo che serve le connessioni da applicazioni e client. VRRP normalmente preleverà un server con priorità più bassa quando un server con priorità più alta è online. Se desideri che l'indirizzo IP rimanga su ProxySQL2 dopo che ProxySQL1 è tornato online, usa l'opzione "nopreempt". Ciò consente alla macchina con priorità più bassa di mantenere il ruolo principale, anche quando una macchina con priorità più alta torna in linea. Tuttavia, affinché ciò funzioni, lo stato iniziale di questa voce deve essere BACKUP. In caso contrario, noterai la seguente riga:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERPoiché per impostazione predefinita ClusterControl configura tutti i nodi come MASTER, è necessario configurare di conseguenza la seguente opzione di configurazione per la rispettiva istanza VRRP:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Riavvia il processo Keepalived per caricare queste modifiche. L'indirizzo IP virtuale verrà sottoposto a failover su ProxySQL1 o ProxySQL3 (a seconda della priorità e del nodo disponibile in quel momento) se il controllo dello stato ha esito negativo su ProxySQL2. In molti casi, è sufficiente eseguire Keepalived su due host.