L'anno scorso, Andy Mallon ha scritto sul blog di aumentare le dimensioni di una colonna da int a bigint senza tempi morti. (Il motivo per cui questa non è un'operazione di soli metadati nelle versioni moderne di SQL Server è al di là di me, ma questo è un altro post.)
Di solito quando affrontiamo questo problema, si tratta di tabelle ampie e massicce (sia nel conteggio delle righe che nella dimensione assoluta) e la colonna che dobbiamo modificare è l'unica colonna principale nella chiave di clustering. In genere sono coinvolte anche altre complicazioni:vincoli di chiave esterna in entrata, molti indici non in cluster e un database occupato che è estremamente sensibile all'attività di registro (perché è coinvolto nel rilevamento delle modifiche, nella replica, nei gruppi di disponibilità o in tutti e tre ).
Per questo motivo, dobbiamo adottare un approccio come quello delineato da Andy, in cui costruiamo una tabella shadow con il nuovo schema, creiamo trigger per mantenere sincronizzate entrambe le copie e quindi eseguiamo il batch/backfill al ritmo di quel team finché non sono pronti per lo scambio nella copia come un vero affare.
Ma io sono pigro!
Ci sono alcuni casi in cui puoi cambiare la colonna direttamente, se puoi permetterti una piccola finestra di fermo/blocco, e diventa un'operazione molto più semplice. La scorsa settimana è emerso uno di questi casi, con una tabella di oltre 1 TB, ma solo 100.000 righe. Quasi tutti i dati erano fuori riga (LOB), potevano permettersi una piccola finestra di inattività se necessario e stavano pianificando di disabilitare il rilevamento delle modifiche e riconfigurarlo comunque. Fiducioso che ricreare il cluster PK non avrebbe dovuto toccare i dati LOB (molto), ho suggerito che questo potrebbe essere un caso in cui possiamo semplicemente applicare la modifica direttamente.
In uno scenario isolato (nessuna chiave esterna in entrata, nessun indice aggiuntivo, nessuna attività dipendente dal lettore di log e nessuna preoccupazione per la concorrenza), ho messo insieme alcuni test per vedere, nel vuoto, cosa richiederebbe questo cambiamento in termini di durata e impatto sul registro delle transazioni. La domanda principale a cui non sapevo come rispondere in anticipo era:"Qual è il costo incrementale dell'aggiornamento delle tabelle sul posto quando sono presenti grandi quantità di dati non chiave?"
Cercherò di racchiudere molto in un post qui. Ho fatto molti test ed è tutto correlato, anche se non tutti gli scenari di test si applicano a te. Per favore, abbi pazienza con me.
I tavoli
Ho creato 6 tabelle, inclusa una linea di base che solo aveva la colonna chiave, una tabella con 4K archiviati nella riga, quindi quattro tabelle ciascuna con una colonna varchar(max) popolata con quantità variabili di dati stringa (4K, 16K, 64K e 256K).
CREATE TABLE dbo.withJustId
(
id int NOT NULL,
CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withoutLob
(
id int NOT NULL,
extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob004
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob016
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)),
CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob064
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)),
CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob256
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)),
CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id)
); Ho riempito ciascuno con 100.000 righe:
INSERT dbo.withJustId (id) SELECT TOP (100000) id = ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Riconosco che quanto sopra non è realistico; quanto spesso abbiamo una tabella che è solo un identificatore + dati LOB? Ho eseguito nuovamente i test con queste quattro colonne aggiuntive per dare alle pagine di dati non LOB un po' più di sostanza reale:
fill1 char(320) NOT NULL DEFAULT ('x'),
count1 int NOT NULL DEFAULT (0),
count2 int NOT NULL DEFAULT (0),
dt datetime2 NOT NULL DEFAULT sysutcdatetime(), Queste tabelle sono solo leggermente più grandi in termini di dimensioni complessive, ma l'aumento proporzionale della quantità di dati non LOB (non illustrato in questo grafico) è la differenza grande ma nascosta:
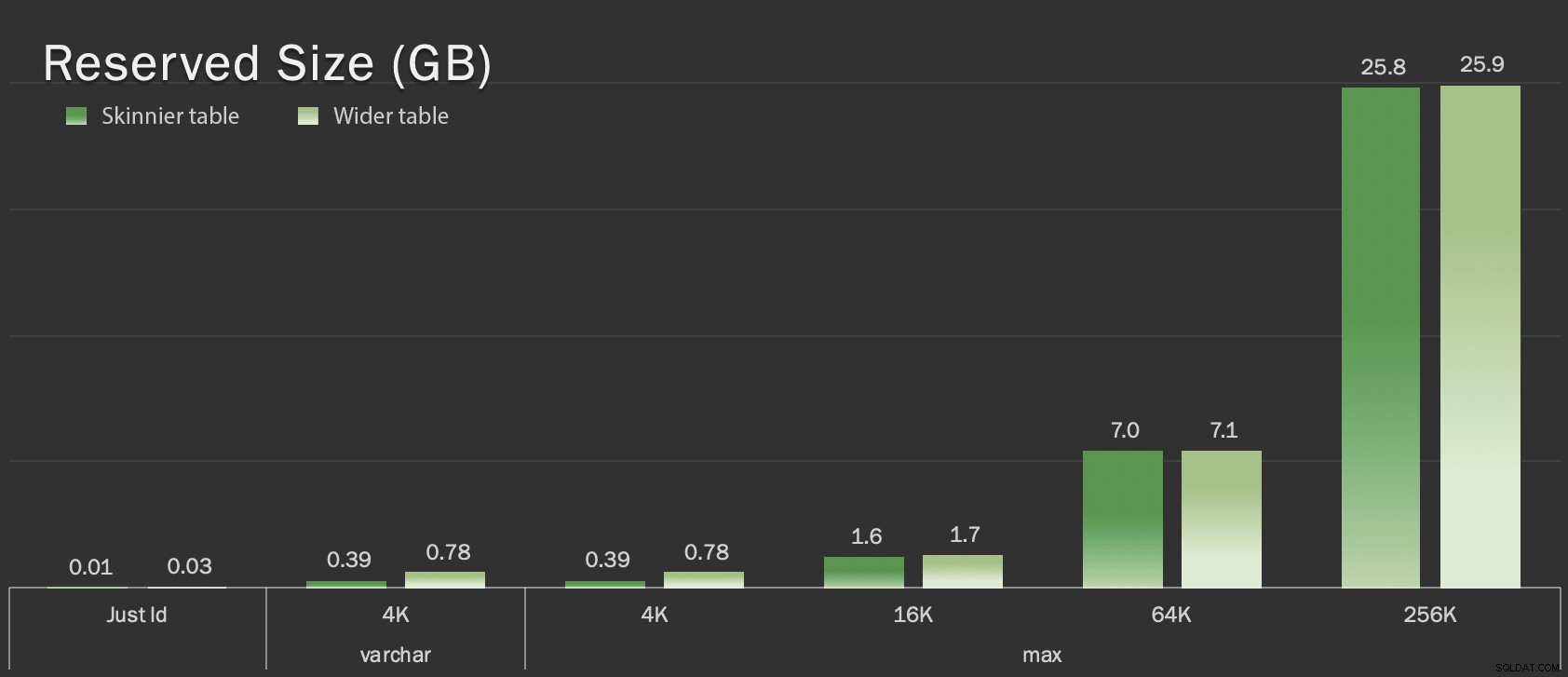 Dimensione riservata delle tabelle, in GB
Dimensione riservata delle tabelle, in GB
I test
Quindi ho cronometrato e raccolto i dati di registro per ciascuna di queste operazioni (con e senza ONLINE = ON ) a fronte di ogni variazione della tabella:
ALTER TABLE dbo.<name> DROP CONSTRAINT pk_<name>; ALTER TABLE dbo.<name> ALTER COLUMN id bigint NOT NULL; -- WITH (ONLINE = ON); ALTER TABLE dbo.<name> ADD CONSTRAINT pk_<name> PRIMARY KEY CLUSTERED (id);
In realtà, ho usato SQL dinamico per generare tutti questi test, in modo da non giocherellare manualmente con gli script prima di ogni test.
In un altro post, condividerò l'SQL dinamico che ho usato per generare quei test e raccoglierò i tempi ad ogni passaggio.
Per fare un confronto, ho anche testato il metodo di Andy (sebbene senza batch e solo sulla versione skinny della tabella):
CREATE TABLE dbo.<name>_copy ( id bigint NOT NULL -- <, extradata column when relevant > CONSTRAINT pk_copy_<name> PRIMARY KEY CLUSTERED (id)); INSERT dbo.<name>_copy SELECT * FROM dbo.<name>; EXEC sys.sp_rename N'dbo.<name>', N'dbo.<name>_old', N'OBJECT'; EXEC sys.sp_rename N'dbo.<name>_copy', N'dbo.<name>', N'OBJECT';
Ho saltato i tavoli più ampi qui; Non volevo introdurre la complessità della codifica e della misurazione delle operazioni batch. L'ovvio punto dolente qui è che, a differenza della modifica della colonna sul posto, con il metodo shadow devi copiare ogni singolo byte di quei dati LOB. Il batch può ridurre al minimo il grande impatto di provare a farlo in una singola transazione, ma alla fine tutto quel rimescolamento dovrà essere rifatto a valle. Il batch alla fonte non può controllare completamente quanto farà male alla destinazione.
I risultati
I primi risultati che mostrerò sono solo le durate medie per le modifiche sul posto, per tutte le 12 configurazioni di tabelle e con e senza ONLINE = ON :
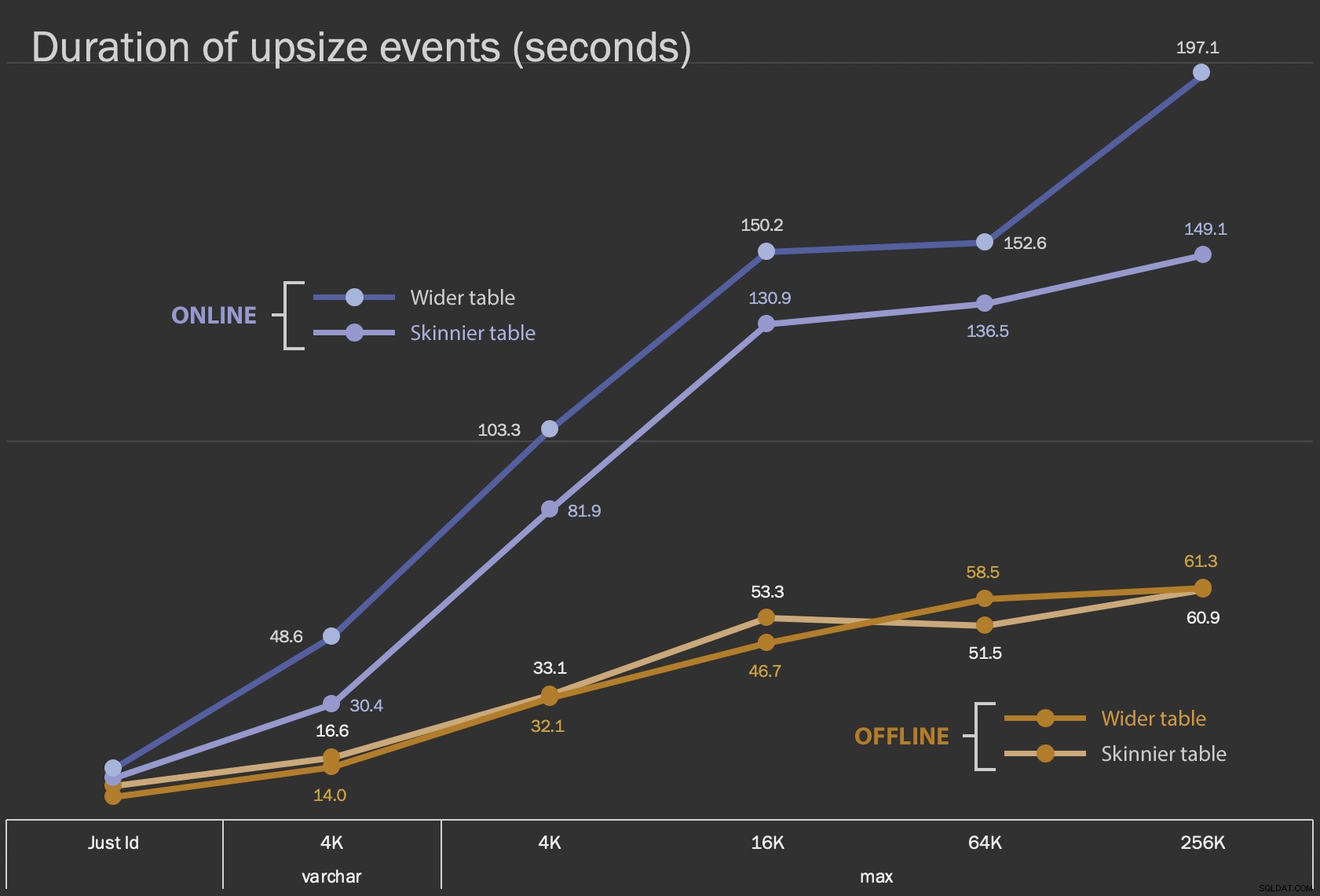 Durata, in secondi, della modifica della colonna sul posto
Durata, in secondi, della modifica della colonna sul posto
L'esecuzione di questa operazione come operazione online richiede più tempo (200 secondi nel peggiore dei casi), ma non blocca gli utenti. Sembra aumentare insieme alle dimensioni, ma non in modo del tutto lineare. L'esecuzione di questa operazione offline provoca il blocco, ma è molto più veloce e non cambia così drasticamente man mano che il tavolo diventa più grande (anche alla dimensione più grande, ciò accadeva comunque in circa un minuto).
Il confronto di queste operazioni sul posto con l'operazione di scambio e rilascio è difficile utilizzando un grafico a linee a causa dell'enorme differenza di scala. Mostrerò invece un grafico a barre orizzontale per la durata coinvolta con ciascuna configurazione di tabella. Quando la ricreazione è più veloce, dipingerò di verde lo sfondo di quella riga; quando è più lento (o rientra tra i metodi offline e online), probabilmente non è necessario, ma dipingerò di rosso lo sfondo di quella riga.
| dimensione LOB | Avvicinamento | Configurazione tabella | Durata (secondi) | ||
|---|---|---|---|
| Solo ID | ALTER Offline | Tabella più magra (10 MB) | 8.8 |
| Tabella più ampia (30 MB) | 6.3 | ||
| ALTER Online | Tavolo più magro | 11.0 | |
| Tabella più ampia | 13.6 | ||
| Ricrea | Tavolo più magro | 3.4 | |
| varchar 4K | Non in linea | Tabella più magra (390 MB) | 16.6 |
| Tabella più ampia (780 MB) | 14.0 | ||
| In linea | Tavolo più magro | 30.4 | |
| Tabella più ampia | 48.6 | ||
| Ricrea | Tavolo più magro | 1.290,0 | |
| max 4k | Non in linea | Tabella più magra (390 MB) | 33.1 |
| Tabella più ampia (780 MB) | 32.1 | ||
| In linea | Tavolo più magro | 81,9 | |
| Tabella più ampia | 103.3 | ||
| Ricrea | Tavolo più magro | 28,9 | |
| max 16k | Non in linea | Tavolo più magro (1,6 GB) | 53.3 |
| Tabella più ampia (1,7 GB) | 46,7 | ||
| In linea | Tavolo più magro | 130,9 | |
| Tabella più ampia | 150,2 | ||
| Ricrea | Tavolo più magro | 81.8 | |
| max 64k | Non in linea | Tavolo più magro (7,0 GB) | 51,5 |
| Tabella più ampia (7,1 GB) | 58,5 | ||
| In linea | Tavolo più magro | 136,5 | |
| Tabella più ampia | 152,6 | ||
| Ricrea | Tavolo più magro | 226,5 | |
| max 256k | Non in linea | Tavolo più magro (25,8 GB) | 60,9 |
| Tabella più ampia (25,9 GB) | 61.3 | ||
| In linea | Tavolo più magro | 149.1 | |
| Tabella più ampia | 197.1 | ||
| Ricrea | Tavolo più magro | 1.576,7 | |
Questa è una scossa ingiusta al metodo di Andy, perché – nel mondo reale – non eseguiresti l'intera operazione in un colpo solo. Non ho mostrato l'utilizzo del registro delle transazioni qui per brevità, ma sarebbe più facile controllarlo anche attraverso il batch in un'operazione side-by-side. Sebbene il suo approccio richieda più lavoro in anticipo, è molto più sicuro in termini di tempi di fermo e/o blocco. Ma puoi vedere nei casi in cui hai molti dati fuori riga e puoi permetterti una breve interruzione, che alterare direttamente la colonna è molto meno doloroso. "Troppo grande per cambiare sul posto" è soggettivo e può produrre risultati diversi a seconda del significato di "grande". Prima di adottare un approccio, potrebbe avere senso testare la modifica rispetto a una copia ragionevole, poiché l'operazione sul posto potrebbe rappresentare un compromesso accettabile.
Conclusione
Non l'ho scritto per discutere con Andy. L'approccio nel post originale è valido, affidabile al 100% e lo usiamo sempre. Tuttavia, quando la forza bruta viene valutata rispetto alla precisione chirurgica, e soprattutto se puoi prendere una fetta di tempo di inattività, può esserci valore nell'approccio più semplice per determinate forme di tavoli.