[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Molto è stato scritto nel corso degli anni sulla comprensione e l'ottimizzazione di SELECT query, ma piuttosto meno sulla modifica dei dati. Questa serie di post esamina un problema specifico di INSERT , UPDATE , DELETE e MERGE domande:il problema di Halloween.
La frase "Problema di Halloween" è stata originariamente coniata in riferimento a un UPDATE SQL query che avrebbe dovuto dare un aumento del 10% a ogni dipendente che ha guadagnato meno di $ 25.000. Il problema era che la query continuava a dare aumenti del 10% fino a tutti guadagnato almeno $ 25.000. Vedremo più avanti in questa serie che il problema sottostante si applica anche a INSERT , DELETE e MERGE query, ma per questa prima voce sarà utile esaminare UPDATE problema un po' nel dettaglio.
Sfondo
Il linguaggio SQL fornisce agli utenti un modo per specificare le modifiche al database utilizzando un UPDATE istruzione, ma la sintassi non dice nulla su come il motore di database dovrebbe eseguire le modifiche. D'altra parte, lo standard SQL specifica che il risultato di un UPDATE deve essere lo stesso come se fosse stato eseguito in tre fasi separate e non sovrapposte:
- Una ricerca di sola lettura determina i record da modificare ei nuovi valori di colonna
- Le modifiche vengono applicate ai record interessati
- I vincoli di coerenza del database sono verificati
L'implementazione di queste tre fasi letteralmente in un motore di database produrrebbe risultati corretti, ma le prestazioni potrebbero non essere molto buone. I risultati intermedi in ogni fase richiederanno memoria di sistema, riducendo il numero di query che il sistema può eseguire contemporaneamente. La memoria richiesta potrebbe anche superare quella disponibile, richiedendo che almeno una parte del set di aggiornamenti venga scritto nella memoria su disco e riletto in seguito. Ultimo ma non meno importante, ogni riga della tabella deve essere toccata più volte in questo modello di esecuzione.
Una strategia alternativa consiste nell'elaborare l'UPDATE una riga alla volta. Questo ha il vantaggio di toccare ogni riga solo una volta e generalmente non richiede memoria per l'archiviazione (sebbene alcune operazioni, come un ordinamento completo, debbano elaborare l'intero set di input prima di produrre la prima riga di output). Questo modello iterativo è quello utilizzato dal motore di esecuzione delle query di SQL Server.
La sfida per Query Optimizer è trovare un piano di esecuzione iterativo (riga per riga) che soddisfi l'UPDATE semantica richiesta dallo standard SQL, pur mantenendo i vantaggi in termini di prestazioni e concorrenza dell'esecuzione pipeline.
Elaborazione aggiornamento
Per illustrare il problema originale, applicheremo un aumento del 10% a ciascun dipendente che guadagna meno di $ 25.000 utilizzando i Employees tabella seguente:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Strategia di aggiornamento in tre fasi
La prima fase di sola lettura trova tutti i record che soddisfano il WHERE predicato della clausola e salva informazioni sufficienti per consentire alla seconda fase di svolgere il proprio lavoro. In pratica, ciò significa registrare un identificatore univoco per ogni riga qualificante (le chiavi dell'indice cluster o l'identificatore della riga dell'heap) e il nuovo valore di stipendio. Una volta completata la fase uno, l'intero set di informazioni sull'aggiornamento viene passato alla seconda fase, che individua ogni record da aggiornare utilizzando l'identificatore univoco e modifica lo stipendio sul nuovo valore. La terza fase verifica quindi che nessun vincolo di integrità del database venga violato dallo stato finale della tabella.
Strategia iterativa
Questo approccio legge una riga alla volta dalla tabella di origine. Se la riga soddisfa il WHERE clausola predicativa, si applica l'aumento di stipendio. Questo processo si ripete finché tutte le righe non sono state elaborate dall'origine. Di seguito è riportato un esempio di piano di esecuzione che utilizza questo modello:

Come di consueto per la pipeline basata sulla domanda di SQL Server, l'esecuzione inizia dall'operatore più a sinistra:UPDATE in questo caso. Richiede una riga dall'aggiornamento della tabella, che richiede una riga dal calcolo scalare e lungo la catena fino alla scansione della tabella:
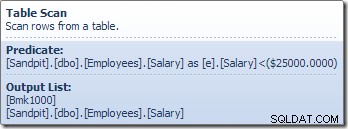
L'operatore Table Scan legge le righe una alla volta dal motore di archiviazione, finché non ne trova una che soddisfi il predicato Salary. L'elenco di output nel grafico sopra mostra l'operatore Table Scan che restituisce un identificatore di riga e il valore corrente della colonna Stipendio per questa riga. Una singola riga contenente riferimenti a queste due informazioni viene passata a Compute Scalar:
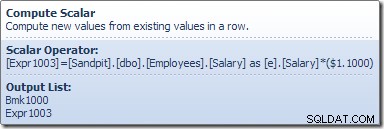
Il calcolo scalare definisce un'espressione che applica l'aumento di stipendio alla riga corrente. Restituisce una riga contenente i riferimenti all'identificatore di riga e lo stipendio modificato in Table Update, che richiama il motore di archiviazione per eseguire la modifica dei dati. Questo processo iterativo continua finché la scansione della tabella non esaurisce le righe. Lo stesso processo di base viene seguito se la tabella ha un indice cluster:
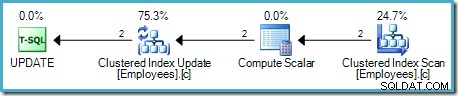
La differenza principale è che le chiavi dell'indice cluster e l'unificatore (se presente) vengono utilizzati come identificatore di riga anziché un RID dell'heap.
Il problema
Il passaggio dall'operazione logica a tre fasi definita nello standard SQL al modello fisico di esecuzione iterativo ha introdotto una serie di sottili modifiche, di cui solo una esamineremo oggi. Un problema può verificarsi nel nostro esempio in esecuzione se è presente un indice non cluster nella colonna Stipendio, che Query Optimizer decide di utilizzare per trovare le righe che si qualificano (salario <$ 25.000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Il modello di esecuzione riga per riga ora può produrre risultati errati o addirittura entrare in un ciclo infinito. Si consideri un (immaginario) piano di esecuzione iterativo che cerca l'indice Stipendio, restituendo una riga alla volta al Calcola scalare e, infine, all'operatore Aggiorna:

Ci sono un paio di scalari di calcolo in più in questo piano a causa di un'ottimizzazione che salta la manutenzione dell'indice non cluster se il valore dello stipendio non è cambiato (possibile solo per uno stipendio zero in questo caso).
Ignorando ciò, la caratteristica importante di questo piano è che ora abbiamo una scansione dell'indice parziale ordinata che passa una riga alla volta a un operatore che modifica lo stesso indice (l'evidenziazione verde nel grafico di SQL Sentry Plan Explorer sopra rende chiaro il L'operatore di aggiornamento dell'indice mantiene sia la tabella di base che l'indice non cluster).
Ad ogni modo, il problema è che elaborando una riga alla volta, l'aggiornamento può spostare la riga corrente davanti alla posizione di scansione utilizzata da Index Seek per individuare le righe da modificare. L'analisi dell'esempio dovrebbe rendere questa affermazione un po' più chiara:
L'indice non cluster viene digitato e ordinato in modo crescente in base al valore dello stipendio. L'indice contiene anche un puntatore alla riga padre nella tabella di base (un RID dell'heap o le chiavi dell'indice cluster più unificatore, se necessario). Per rendere l'esempio più facile da seguire, supponi che la tabella di base ora abbia un indice cluster univoco nella colonna Nome, quindi i contenuti dell'indice non cluster all'inizio dell'elaborazione dell'aggiornamento sono:
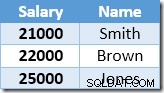
La prima riga restituita da Index Seek è lo stipendio di $ 21.000 per Smith. Questo valore viene aggiornato a $ 23.100 nella tabella di base e nell'indice non cluster dall'operatore Clustered Index. L'indice non cluster ora contiene:
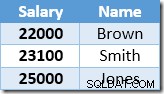
La riga successiva restituita da Index Seek sarà la voce $ 22.000 per Brown, che viene aggiornata a $ 24.200:
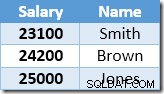
Ora Index Seek trova il valore di $ 23.100 per Smith, che viene aggiornato di nuovo , a $ 25.410. Questo processo continua fino a quando tutti i dipendenti hanno uno stipendio di almeno $ 25.000, che non è un risultato corretto per il dato UPDATE interrogazione. Lo stesso effetto in altre circostanze può portare a un aggiornamento incontrollato che termina solo quando il server esaurisce lo spazio di registro o si verifica un errore di overflow (potrebbe verificarsi in questo caso se qualcuno avesse uno stipendio zero). Questo è il problema di Halloween in quanto si applica agli aggiornamenti.
Evitare il problema di Halloween per gli aggiornamenti
I lettori più attenti avranno notato che le percentuali di costo stimate nell'immaginario piano di ricerca dell'indice non raggiungevano il 100%. Questo non è un problema con Plan Explorer:ho deliberatamente rimosso un operatore chiave dal piano:

Query Optimizer riconosce che questo piano di aggiornamento in pipeline è vulnerabile al problema di Halloween e introduce un Eager Table Spool per evitare che si verifichi. Non vi è alcun suggerimento o flag di traccia per impedire l'inclusione dello spool in questo piano di esecuzione perché è necessario per la correttezza.
Come suggerisce il nome, lo spool consuma avidamente tutte le righe dal suo operatore figlio (l'Indice Seek) prima di restituire una riga al suo padre Compute Scalar. L'effetto è quello di introdurre una separazione di fase completa – tutte le righe qualificanti vengono lette e salvate nella memoria temporanea prima dell'esecuzione di eventuali aggiornamenti.
Questo ci avvicina alla semantica logica a tre fasi dello standard SQL, anche se tieni presente che l'esecuzione del piano è ancora fondamentalmente iterativa, con gli operatori a destra dello spool che formano il cursore di lettura e gli operatori a sinistra che formano il cursore di scrittura . Il contenuto dello spool viene ancora letto ed elaborato riga per riga (non viene passato in massa come potrebbe altrimenti far credere il confronto con lo standard SQL).
Gli svantaggi della separazione di fase sono gli stessi menzionati in precedenza. Lo spool tabella consuma tempdb spazio (pagine nel pool di buffer) e potrebbe richiedere letture e scritture fisiche su disco sotto pressione di memoria. Query Optimizer assegna un costo stimato allo spool (soggetto a tutti i consueti avvertimenti sulle stime) e sceglierà tra i piani che richiedono protezione contro il problema di Halloween rispetto a quelli che non lo fanno sulla base del costo stimato normalmente. Naturalmente, l'ottimizzatore potrebbe scegliere erroneamente tra le opzioni per uno qualsiasi dei normali motivi.
In questo caso, il compromesso è tra l'aumento dell'efficienza cercando direttamente i record di qualificazione (quelli con uno stipendio <$ 25.000) rispetto al costo stimato della bobina richiesta per evitare il problema di Halloween. Un piano alternativo (in questo caso specifico) è una scansione completa dell'indice cluster (o heap). Questa strategia non richiede la stessa protezione di Halloween perché le chiavi dell'indice cluster non vengono modificati:

Poiché le chiavi dell'indice sono stabili, le righe non possono spostare la posizione nell'indice tra le iterazioni, evitando il problema di Halloween nel caso in esame. A seconda del costo di runtime della scansione dell'indice cluster rispetto alla combinazione Index Seek più Eager Table Spool vista in precedenza, un piano potrebbe essere eseguito più velocemente dell'altro. Un'altra considerazione è che il piano con Halloween Protection acquisirà più blocchi rispetto al piano completamente pianificato e i blocchi verranno mantenuti più a lungo.
Pensieri finali
Comprendere il problema di Halloween e gli effetti che può avere sui piani di query di modifica dei dati ti aiuterà ad analizzare i piani di esecuzione di modifica dei dati e può offrire opportunità per evitare i costi e gli effetti collaterali di una protezione non necessaria laddove sia disponibile un'alternativa.
Esistono diverse forme del problema di Halloween, non tutte causate dalla lettura e dalla scrittura sui tasti di un indice comune. Anche il problema di Halloween non è limitato a UPDATE interrogazioni. L'ottimizzatore di query ha più assi nella manica per evitare il problema di Halloween a parte la separazione di fase a forza bruta utilizzando una bobina da tavolo desiderosa. Questi punti (e altro) saranno esplorati nelle prossime puntate di questa serie.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]