[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Nella prima parte di questa serie, abbiamo visto come il problema di Halloween si applica a UPDATE interrogazioni. Per ricapitolare brevemente, il problema era che un indice utilizzato per individuare i record da aggiornare aveva le chiavi modificate dall'operazione di aggiornamento stessa (un altro buon motivo per utilizzare colonne incluse in un indice anziché estendere le chiavi). Query Optimizer ha introdotto un operatore Eager Table Spool per separare i lati di lettura e scrittura del piano di esecuzione per evitare il problema. In questo post, vedremo in che modo lo stesso problema sottostante può influire su INSERT e DELETE dichiarazioni.
Inserisci dichiarazioni
Ora che conosciamo un po' le condizioni che richiedono la protezione di Halloween, è abbastanza facile creare un INSERT esempio che prevede la lettura e la scrittura sulle chiavi della stessa struttura di indice. L'esempio più semplice è la duplicazione di righe in una tabella (in cui l'aggiunta di nuove righe modifica inevitabilmente le chiavi dell'indice cluster):
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
SELECT SomeKey FROM dbo.Demo; Il problema è che le righe appena inserite potrebbero essere incontrate dal lato di lettura del piano di esecuzione, risultando potenzialmente in un ciclo che aggiunge righe per sempre (o almeno fino al raggiungimento di un limite di risorse). Query Optimizer riconosce questo rischio e aggiunge un Eager Table Spool per fornire la necessaria separazione di fase :
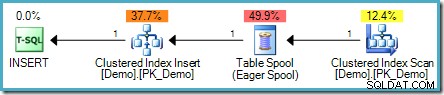
Un esempio più realistico
Probabilmente non scrivi spesso query per duplicare ogni riga in una tabella, ma probabilmente scrivi query in cui la tabella di destinazione per un INSERT appare anche da qualche parte in SELECT clausola. Un esempio è l'aggiunta di righe da una tabella di staging che non esistono già nella destinazione:
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); Il piano di esecuzione è:
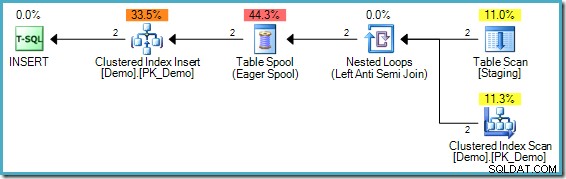
Il problema in questo caso è leggermente diverso, sebbene sia ancora un esempio dello stesso problema centrale. Non è presente alcun valore "1234" nella tabella Demo di destinazione, ma la tabella Staging contiene due di queste voci. Senza la separazione di fase, il primo valore "1234" rilevato verrebbe inserito correttamente, ma il secondo controllo rileverebbe che il valore "1234" ora esiste e non tenterebbe di inserirlo nuovamente. La dichiarazione nel suo insieme verrebbe completata correttamente.
Ciò potrebbe produrre un risultato desiderabile in questo caso particolare (e potrebbe anche sembrare intuitivamente corretto), ma non è un'implementazione corretta. Lo standard SQL richiede che le query di modifica dei dati vengano eseguite come se le tre fasi di lettura, scrittura e verifica dei vincoli avvenissero in modo completamente separato (vedi parte prima).
Cercando tutte le righe da inserire come un'unica operazione, dovremmo selezionare entrambe le righe "1234" dalla tabella Staging, poiché questo valore non esiste ancora nella destinazione. Il piano di esecuzione dovrebbe quindi cercare di inserire entrambi Righe "1234" dalla tabella di staging, con conseguente violazione della chiave primaria:
Msg 2627, livello 14, stato 1, riga 1Violazione del vincolo PRIMARY KEY 'PK_Demo'.
Impossibile inserire la chiave duplicata nell'oggetto 'dbo.Demo'.
Il valore della chiave duplicata è ( 1234).
L'istruzione è stata terminata.
La separazione delle fasi fornita da Table Spool assicura che tutti i controlli di esistenza siano completati prima che vengano apportate modifiche alla tabella di destinazione. Se esegui la query in SQL Server con i dati di esempio sopra, riceverai il messaggio di errore (corretto).
La protezione di Halloween è richiesta per le istruzioni INSERT in cui si fa riferimento anche alla tabella di destinazione nella clausola SELECT.
Elimina dichiarazioni
Potremmo aspettarci che il problema di Halloween non si applichi a DELETE dichiarazioni, dal momento che non dovrebbe importare se proviamo a eliminare una riga più volte. Possiamo modificare il nostro esempio di tabella di staging per rimuovere righe della tabella Demo che non esistono in Staging:
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Questo test sembra convalidare la nostra intuizione perché non c'è Table Spool nel piano di esecuzione:
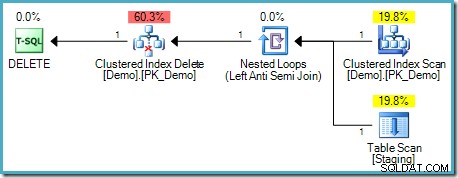
Questo tipo di DELETE non richiede la separazione di fase perché ogni riga ha un identificatore univoco (un RID se la tabella è un heap, chiavi di indice raggruppate ed eventualmente un unificatore in caso contrario). Questo localizzatore di righe univoco è una chiave stabile – non esiste alcun meccanismo attraverso il quale possa cambiare durante l'esecuzione di questo piano, quindi il problema di Halloween non si pone.
ELIMINA Protezione di Halloween
Tuttavia, c'è almeno un caso in cui un DELETE richiede la protezione di Halloween:quando il piano fa riferimento a una riga della tabella diversa da quella che viene eliminata. Ciò richiede un self-join, che si trova comunemente quando vengono modellate relazioni gerarchiche. Di seguito è riportato un esempio semplificato:
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Dovrebbe davvero esserci un riferimento alla chiave esterna della stessa tabella definito qui, ma ignoriamo per un momento il fallimento del design:la struttura e i dati sono comunque validi (ed è purtroppo abbastanza comune trovare chiavi esterne omesse nel mondo reale). Ad ogni modo, il compito da svolgere è eliminare qualsiasi riga in cui ref la colonna punta a un pk inesistente valore. Il naturale DELETE la query che soddisfa questo requisito è:
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
); Il piano di query è:
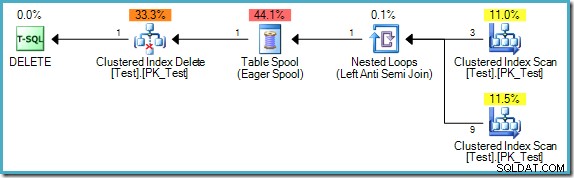
Si noti che questo piano ora include una costosa bobina da tavolo Eager. La separazione delle fasi è richiesta qui perché altrimenti i risultati potrebbero dipendere dall'ordine in cui vengono elaborate le righe:
Se il motore di esecuzione inizia con la riga in cui pk =B, non troverebbe alcuna riga corrispondente (ref =A e non c'è riga dove pk =A). Se l'esecuzione passa alla riga in cui pk =C, verrebbe anche eliminato perché abbiamo appena rimosso la riga B indicata dal suo ref colonna. Il risultato finale sarebbe che l'elaborazione iterativa in questo ordine eliminerebbe tutte le righe dalla tabella, il che è chiaramente errato.
D'altra parte, se il motore di esecuzione ha elaborato la riga con pk =D prima, troverebbe una riga corrispondente (ref =C). Supponendo che l'esecuzione sia continuata al contrario pk order, l'unica riga eliminata dalla tabella sarebbe quella in cui pk =B. Questo è il risultato corretto (ricorda che la query dovrebbe essere eseguita come se le fasi di lettura, scrittura e convalida fossero avvenute in sequenza e senza sovrapposizioni).
Separazione delle fasi per la convalida del vincolo
Per inciso, possiamo vedere un altro esempio di separazione di fase se aggiungiamo un vincolo di chiave esterna della stessa tabella all'esempio precedente:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); Il piano di esecuzione dell'INSERT è:
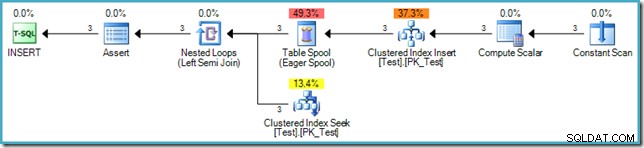
L'inserto stesso non richiede la protezione di Halloween poiché il piano non legge dalla stessa tabella (l'origine dati è una tabella virtuale in memoria rappresentata dall'operatore Constant Scan). Lo standard SQL richiede tuttavia che la fase 3 (controllo dei vincoli) avvenga al termine della fase di scrittura. Per questo motivo, un Eager Table Spool a separazione di fase viene aggiunto al piano dopo l'indice clustered index e subito prima che ogni riga venga controllata per assicurarsi che il vincolo di chiave esterna rimanga valido.
Se stai iniziando a pensare che tradurre una query di modifica SQL dichiarativa basata su set in un solido piano di esecuzione fisica iterativo sia un affare complicato, stai iniziando a capire perché l'elaborazione degli aggiornamenti (di cui Halloween Protection è solo una piccola parte) è il parte più complessa del Query Processor.
Le istruzioni DELETE richiedono la protezione di Halloween quando è presente un'unione automatica della tabella di destinazione.
Riepilogo
La protezione di Halloween può essere una funzionalità costosa (ma necessaria) nei piani di esecuzione che modificano i dati (dove "modifica" include tutta la sintassi SQL che aggiunge, modifica o rimuove righe). La protezione di Halloween è richiesta per UPDATE piani in cui le chiavi di una struttura di indice comune vengono lette e modificate, per INSERT piani in cui si fa riferimento alla tabella di destinazione sul lato di lettura del piano e per DELETE piani in cui viene eseguito un self-join sulla tabella di destinazione.
La parte successiva di questa serie tratterà alcune ottimizzazioni speciali di Halloween Problem che si applicano solo a MERGE dichiarazioni.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]