[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Il MERGE istruzione (introdotta in SQL Server 2008) ci consente di eseguire una combinazione di INSERTs , UPDATE e DELETE operazioni utilizzando un'unica istruzione. I problemi della protezione di Halloween per MERGE sono principalmente una combinazione dei requisiti delle singole operazioni, ma ci sono alcune differenze importanti e un paio di ottimizzazioni interessanti che si applicano solo a MERGE .
Evitare il problema di Halloween con MERGE
Iniziamo osservando di nuovo l'esempio Demo e Staging della seconda parte:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Come ricorderete, questo esempio è stato utilizzato per mostrare che un INSERTs richiede la protezione di Halloween quando si fa riferimento anche alla tabella di destinazione dell'inserimento in SELECT parte della query (il EXISTS clausola in questo caso). Il comportamento corretto per INSERTs istruzione sopra è provare ad aggiungere entrambi 1234 valori, e di conseguenza fallire con una PRIMARY KEY violazione. Senza separazione di fase, il INSERTs aggiungerebbe erroneamente un valore, completando senza che venga generato un errore.
Il piano di esecuzione INSERT
Il codice sopra ha una differenza rispetto a quello utilizzato nella seconda parte; è stato aggiunto un indice non cluster nella tabella Staging. Il INSERTs piano di esecuzione ancora richiede però la protezione di Halloween:
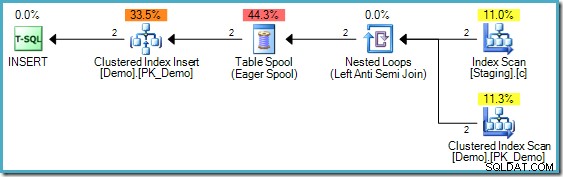
Il piano di esecuzione di MERGE
Ora prova lo stesso inserimento logico espresso usando MERGE sintassi:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Nel caso in cui non si abbia familiarità con la sintassi, la logica esiste per confrontare le righe nelle tabelle Staging e Demo sul valore SomeKey e se non viene trovata alcuna riga corrispondente nella tabella di destinazione (Demo), inseriamo una nuova riga. Questo ha esattamente la stessa semantica del precedente INSERT...WHERE NOT EXISTS codice, ovviamente. Il piano di esecuzione è tuttavia molto diverso:
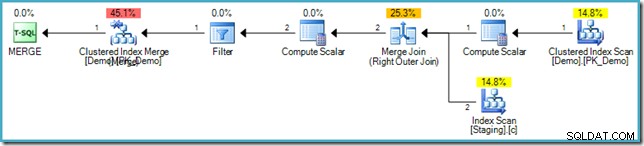
Notare la mancanza di un Eager Table Spool in questo piano. Nonostante ciò, la query continua a produrre il messaggio di errore corretto. Sembra che SQL Server abbia trovato un modo per eseguire MERGE pianificare in modo iterativo rispettando la separazione logica di fase richiesta dallo standard SQL.
L'ottimizzazione del riempimento dei buchi
Nelle giuste circostanze, l'ottimizzatore di SQL Server può riconoscere che MERGE istruzione è riempire i buchi , che è solo un altro modo per dire che l'istruzione aggiunge solo righe in cui è presente uno spazio vuoto nella chiave della tabella di destinazione.
Affinché questa ottimizzazione venga applicata, i valori utilizzati nel WHEN NOT MATCHED BY TARGET la clausola deve esattamente corrisponde a ON parte del USING clausola. Inoltre, la tabella di destinazione deve avere una chiave univoca (requisito soddisfatto dalla PRIMARY KEY nel presente caso). Quando questi requisiti sono soddisfatti, il MERGE dichiarazione non richiede protezione dal problema di Halloween.
Naturalmente, il MERGE affermazione è logicamente né più né meno riempimento di buche rispetto all'originale INSERT...WHERE NOT EXISTS sintassi. La differenza è che l'ottimizzatore ha il controllo completo sull'implementazione di MERGE istruzione, mentre INSERTs la sintassi richiederebbe di ragionare sulla semantica più ampia della query. Un essere umano può facilmente vedere che il INSERTs riempie anche i buchi, ma l'ottimizzatore non pensa alle cose nello stesso modo in cui le pensiamo noi.
Per illustrare la corrispondenza esatta requisito che ho menzionato, considera la seguente sintassi della query, che non beneficiare dell'ottimizzazione del riempimento dei fori. Il risultato è una protezione completa per Halloween fornita da una bobina da tavolo desiderosa:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

L'unica differenza è la moltiplicazione per uno nei VALUES clausola – qualcosa che non cambia la logica della query, ma che è sufficiente per impedire l'applicazione dell'ottimizzazione del riempimento dei buchi.
Riempimento di fori con anelli nidificati
Nell'esempio precedente, l'ottimizzatore ha scelto di unire le tabelle utilizzando un join Merge. L'ottimizzazione del riempimento dei fori può essere applicata anche quando viene scelto un join Nested Loops, ma ciò richiede una garanzia di unicità aggiuntiva sulla tabella di origine e una ricerca dell'indice sul lato interno del join. Per vederlo in azione, possiamo cancellare i dati di staging esistenti, aggiungere univocità all'indice non cluster e provare MERGE ancora:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Il piano di esecuzione risultante utilizza nuovamente l'ottimizzazione del riempimento dei buchi per evitare la protezione di Halloween, utilizzando un join di loop nidificato e una ricerca interna nella tabella di destinazione:
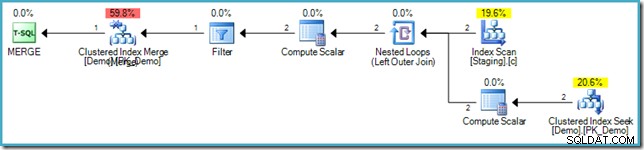
Evitare inutili attraversamenti di indici
Laddove si applica l'ottimizzazione del riempimento delle buche, il motore può anche applicare un'ulteriore ottimizzazione. Può ricordare la posizione attuale dell'indice durante la lettura la tabella di destinazione (elaborando una riga alla volta, ricorda) e riutilizza tali informazioni durante l'esecuzione dell'inserimento, invece di cercare il b-tree per trovare la posizione dell'inserimento. Il ragionamento è che è molto probabile che la posizione di lettura corrente si trovi nella stessa pagina in cui dovrebbe essere inserita la nuova riga. Verificare che la riga appartenga effettivamente a questa pagina è molto veloce, poiché comporta il controllo solo delle chiavi più basse e più alte attualmente memorizzate lì.
La combinazione dell'eliminazione di Eager Table Spool e del salvataggio di una navigazione dell'indice per riga può fornire un vantaggio significativo nei carichi di lavoro OLTP, a condizione che il piano di esecuzione venga recuperato dalla cache. Il costo di compilazione per MERGE istruzioni è piuttosto superiore rispetto a INSERTs , UPDATE e DELETE , quindi pianificare il riutilizzo è una considerazione importante. È anche utile assicurarsi che le pagine dispongano di spazio libero sufficiente per ospitare nuove righe, evitando le divisioni di pagina. Ciò si ottiene in genere attraverso il normale mantenimento dell'indice e l'assegnazione di un FILLFACTOR adatto .
Cito i carichi di lavoro OLTP, che in genere presentano un numero elevato di modifiche relativamente piccole, perché MERGE le ottimizzazioni potrebbero non essere una buona scelta quando viene elaborato un numero elevato di righe per istruzione. Altre ottimizzazioni come INSERTs con registrazione minima attualmente non può essere combinato con il riempimento dei buchi. Come sempre, le caratteristiche delle prestazioni dovrebbero essere confrontate per garantire che i benefici attesi siano realizzati.
L'ottimizzazione del riempimento dei buchi per MERGE gli inserti possono essere combinati con aggiornamenti ed eliminazioni utilizzando MERGE aggiuntivo clausole; ogni operazione di modifica dei dati viene valutata separatamente per il Problema di Halloween.
Evitare l'adesione
L'ottimizzazione finale che esamineremo può essere applicata dove MERGE contiene operazioni di aggiornamento ed eliminazione, nonché un inserto di riempimento dei buchi e la tabella di destinazione ha un indice cluster univoco. L'esempio seguente mostra un comune MERGE modello in cui vengono inserite le righe non corrispondenti e le righe corrispondenti vengono aggiornate o eliminate a seconda di una condizione aggiuntiva:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
Il MERGE l'istruzione necessaria per apportare tutte le modifiche richieste è notevolmente compatta:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Il piano di esecuzione è piuttosto sorprendente:

Nessuna protezione di Halloween, nessun join tra le tabelle di origine e di destinazione e non capita spesso di vedere un operatore di inserimento dell'indice cluster seguito da un'unione di indice cluster nella stessa tabella. Questa è un'altra ottimizzazione mirata ai carichi di lavoro OLTP con un riutilizzo del piano elevato e un'indicizzazione adeguata.
L'idea è quella di leggere una riga dalla tabella di origine e provare subito a inserirla nella destinazione. Se si verifica una violazione della chiave, l'errore viene eliminato, l'operatore Inserisci restituisce la riga in conflitto trovata e tale riga viene quindi elaborata per un'operazione di aggiornamento o eliminazione utilizzando l'operatore del piano Unisci normalmente.
Se l'inserimento originale ha esito positivo (senza una violazione della chiave), l'elaborazione continua con la riga successiva dall'origine (l'operatore Unisci elabora solo gli aggiornamenti e le elimina). Questa ottimizzazione avvantaggia principalmente MERGE query in cui la maggior parte delle righe di origine risulta in un inserto. Anche in questo caso, è necessaria un'analisi comparativa accurata per garantire prestazioni migliori rispetto all'utilizzo di istruzioni separate.
Riepilogo
Il MERGE dichiarazione fornisce diverse opportunità di ottimizzazione uniche. Nelle giuste circostanze, può evitare la necessità di aggiungere una Protezione di Halloween esplicita rispetto a un INSERTs equivalente operazione, o forse anche una combinazione di INSERTs , UPDATE e DELETE dichiarazioni. MERGE aggiuntivo - le ottimizzazioni specifiche possono evitare l'attraversamento dell'albero b dell'indice solitamente necessario per individuare la posizione di inserimento per una nuova riga e possono anche evitare la necessità di unire completamente le tabelle di origine e di destinazione.
Nella parte finale di questa serie, esamineremo come Query Optimizer ragiona sulla necessità della protezione di Halloween e identificheremo altri trucchi che può utilizzare per evitare la necessità di aggiungere Eager Table Spools ai piani di esecuzione che modificano i dati.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]