[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Il problema di Halloween può avere una serie di effetti importanti sui piani di esecuzione. In questa parte finale della serie, esaminiamo i trucchi che l'ottimizzatore può utilizzare per evitare il problema di Halloween durante la compilazione di piani per query che aggiungono, modificano o eliminano dati.
Sfondo
Nel corso degli anni, sono stati tentati numerosi approcci per evitare il problema di Halloween. Una delle prime tecniche consisteva semplicemente nell'evitare di costruire piani di esecuzione che prevedessero la lettura e la scrittura di chiavi dello stesso indice. Ciò non ha avuto molto successo dal punto di vista delle prestazioni, anche perché spesso significava scansionare la tabella di base invece di utilizzare un indice selettivo non cluster per individuare le righe da modificare.
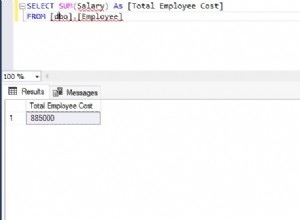
Un secondo approccio consisteva nel separare completamente le fasi di lettura e scrittura di una query di aggiornamento, individuando prima tutte le righe che si qualificano per la modifica, memorizzandole da qualche parte e solo successivamente iniziando a eseguire le modifiche. In SQL Server, questa separazione di fase completa si ottiene posizionando l'ormai familiare Eager Table Spool sul lato di input dell'operatore di aggiornamento:
Lo spool legge tutte le righe dal suo input e le memorizza in un tempdb nascosto tavolo da lavoro. Le pagine di questa tabella di lavoro potrebbero rimanere in memoria o potrebbero richiedere spazio su disco fisico se il set di righe è di grandi dimensioni o se il server è sotto pressione di memoria.
La separazione di fase completa può essere tutt'altro che ideale perché generalmente desideriamo eseguire la maggior parte del piano possibile come una pipeline, in cui ogni riga viene elaborata completamente prima di passare alla successiva. La pipeline presenta molti vantaggi, tra cui evitare la necessità di una conservazione temporanea e toccare ogni riga una sola volta.
L'Ottimizzatore di SQL Server
SQL Server va molto oltre le due tecniche descritte finora, sebbene ovviamente le includa entrambe come opzioni. Query Optimizer di SQL Server rileva le query che richiedono la protezione di Halloween, determina quanto è richiesta la protezione e utilizza basato sui costi analisi per trovare il metodo più economico per fornire tale protezione.
Il modo più semplice per comprendere questo aspetto del problema di Halloween è guardare alcuni esempi. Nelle sezioni seguenti, il compito è aggiungere un intervallo di numeri a una tabella esistente, ma solo numeri che non esistono già:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 righe
Il primo esempio elabora un intervallo di numeri da 1 a 5 inclusi:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
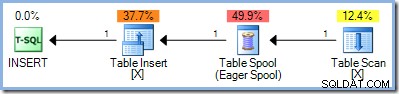
); Poiché questa query legge e scrive nelle chiavi dello stesso indice nella tabella Test, il piano di esecuzione richiede la protezione di Halloween. In questo caso, l'ottimizzatore utilizza la separazione di fase completa utilizzando un Eager Table Spool:
50 righe
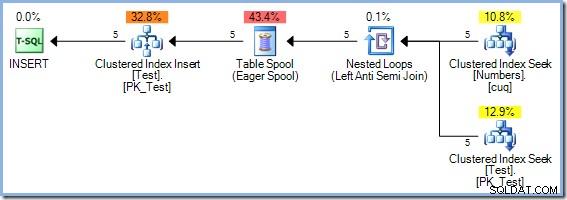
Con cinque righe ora nella tabella Test, eseguiamo di nuovo la stessa query, modificando WHERE clausola per elaborare i numeri da 1 a 50 inclusi :
Questo piano fornisce una protezione corretta contro il problema di Halloween, ma non presenta una bobina da tavolo desiderosa. L'ottimizzatore riconosce che l'operatore di join Hash Match sta bloccando il suo input di compilazione; tutte le righe vengono lette in una tabella hash prima che l'operatore avvii il processo di corrispondenza utilizzando le righe dall'input del probe. Di conseguenza, questo piano prevede naturalmente la separazione di fase (solo per la tabella Test) senza la necessità di una bobina.
L'ottimizzatore ha scelto un piano di join Hash Match rispetto al join Nested Loops visto nel piano a 5 righe per motivi basati sui costi. Il piano Hash Match a 50 righe ha un costo totale stimato di 0,0347345 unità. Possiamo forzare il piano Nested Loops utilizzato in precedenza con un suggerimento per vedere perché l'ottimizzatore non ha scelto i loop nidificati:
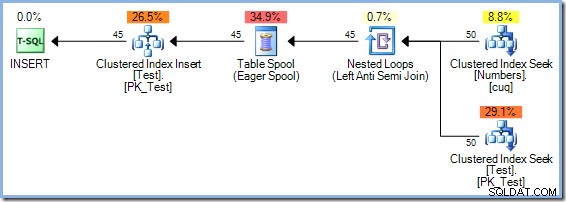
Questo piano ha un costo stimato di 0,0379063 unità compreso lo spool, un po' più del piano Hash Match.
500 righe
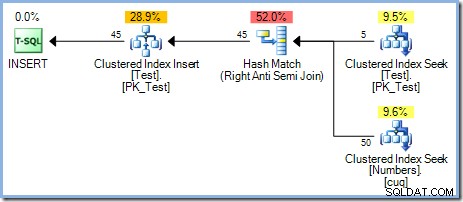
Con 50 righe ora nella tabella Test, aumentiamo ulteriormente l'intervallo di numeri a 500 :
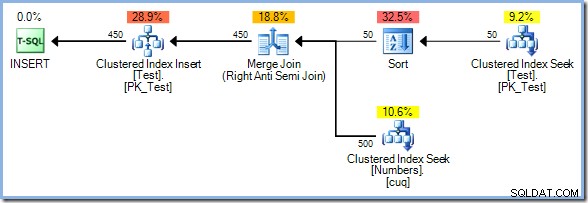
Questa volta, l'ottimizzatore sceglie un Merge Join e ancora una volta non c'è Eager Table Spool. L'operatore Sort fornisce la necessaria separazione di fase in questo piano. Consuma completamente il suo input prima di restituire la prima riga (l'ordinamento non può sapere quale riga ordina per prima finché non sono state visualizzate tutte le righe). L'ottimizzatore ha deciso di ordinare 50 le righe della tabella Test sarebbero più economiche dello spooling ansioso di 450 righe appena prima dell'operatore di aggiornamento.
Il piano Sort plus Merge Join ha un costo stimato di 0,0362708 unità. Le alternative ai piani Hash Match e Nested Loops sono disponibili a 0,0385677 unità e 0,112433 unità rispettivamente.
Qualcosa di strano nell'ordinamento
Se hai eseguito questi esempi per te stesso, potresti aver notato qualcosa di strano in quell'ultimo esempio, in particolare se hai esaminato i suggerimenti degli strumenti Plan Explorer per la tabella di test Cerca e ordina:
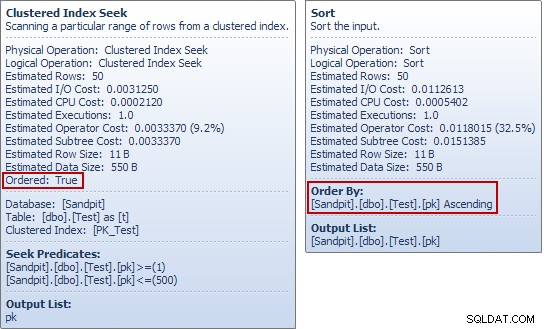
The Seek produce un ordinato flusso di pk valori, quindi qual è il punto di ordinare sulla stessa colonna subito dopo? Per rispondere a questa domanda (molto ragionevole), iniziamo osservando solo il SELECT parte del INSERT domanda:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;
Questa query produce il piano di esecuzione riportato di seguito (con o senza il ORDER BY Ho aggiunto per rispondere ad alcune obiezioni tecniche che potresti avere):
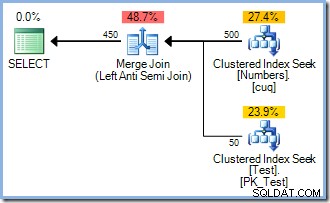
Si noti la mancanza di un operatore di ordinamento. Allora perché il INSERT il piano include un ordinamento? Semplicemente per evitare il problema di Halloween. L'ottimizzatore ha ritenuto che l'esecuzione di un ordinamento ridondante (con la sua separazione di fase incorporata) era il modo più economico per eseguire la query e garantire risultati corretti. Intelligente.
Livelli e proprietà di protezione di Halloween
L'ottimizzatore di SQL Server dispone di funzionalità specifiche che consentono di ragionare sul livello di Halloween Protection (HP) richiesto in ogni punto del piano di query e sull'effetto dettagliato di ciascun operatore. Queste funzionalità extra sono incorporate nello stesso framework di proprietà utilizzato dall'ottimizzatore per tenere traccia di centinaia di altre informazioni importanti durante le sue attività di ricerca.
Ogni operatore ha un richiesto Proprietà HP e un consegnato proprietà HP. Il richiesto la proprietà indica il livello di HP necessario in quel punto dell'albero per ottenere risultati corretti. Il consegnato la proprietà riflette gli HP forniti dall'operatore corrente e il cumulativo Effetti HP forniti dal suo sottoalbero.
L'ottimizzatore contiene la logica per determinare in che modo ogni operatore fisico (ad esempio, un calcolo scalare) influisce sul livello HP. Esplorando un'ampia gamma di alternative di piano e rifiutando i piani in cui l'HP fornito è inferiore all'HP richiesto dall'operatore di aggiornamento, l'ottimizzatore ha un modo flessibile per trovare piani corretti ed efficienti che non richiedono sempre un Eager Table Spool.
Modifiche al piano per la protezione di Halloween
Abbiamo visto l'ottimizzatore aggiungere un ordinamento ridondante per la protezione di Halloween nel precedente esempio di Merge Join. Come possiamo essere sicuri che sia più efficiente di una semplice bobina da tavolo Eager? E come possiamo sapere quali funzionalità di un piano di aggiornamento sono disponibili solo per la protezione di Halloween?
È possibile rispondere a entrambe le domande (in un ambiente di test, naturalmente) utilizzando il flag di traccia non documentato 8692 , che costringe l'ottimizzatore a utilizzare una bobina da tavolo desiderosa per la protezione di Halloween. Ricordiamo che il piano Merge Join con l'ordinamento ridondante aveva un costo stimato di 0,0362708 unità di ottimizzazione magica. Possiamo confrontarlo con l'alternativa Eager Table Spool ricompilando la query con il flag di traccia 8692 abilitato:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
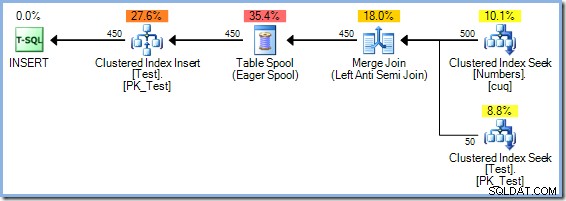
Il piano Eager Spool ha un costo stimato di 0,0378719 unità (da 0,0362708 con l'ordinamento ridondante). Le differenze di costo qui riportate non sono molto significative a causa della banalità del compito e delle ridotte dimensioni dei filari. Le query di aggiornamento del mondo reale con alberi complessi e conteggi di righe più grandi spesso producono piani molto più efficienti grazie alla capacità dell'ottimizzatore di SQL Server di riflettere a fondo su Halloween Protection.
Altre opzioni non di spool
Posizionare un operatore di blocco in modo ottimale all'interno di un piano non è l'unica strategia a disposizione dell'ottimizzatore per ridurre al minimo il costo della protezione contro il problema di Halloween. Può anche ragionare sull'intervallo di valori in elaborazione, come dimostra il seguente esempio:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; Il piano di esecuzione non mostra la necessità di Halloween Protection, nonostante stiamo leggendo e aggiornando le chiavi di un indice comune:
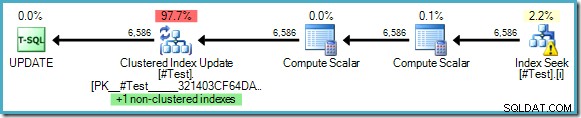
L'ottimizzatore può vedere che la modifica di "some_value" da 5 a 10 non potrebbe mai far visualizzare una riga aggiornata una seconda volta da Index Seek (che cerca solo righe in cui some_value è 5). Questo ragionamento è possibile solo quando nella query vengono utilizzati valori letterali o quando la query specifica OPTION (RECOMPILE) , consentendo all'ottimizzatore di annusare i valori dei parametri per un piano di esecuzione una tantum.
Anche con valori letterali nella query, all'ottimizzatore potrebbe essere impedito di applicare questa logica se l'opzione del database FORCED PARAMETERIZATION è ON . In tal caso, i valori letterali nella query vengono sostituiti da parametri e l'ottimizzatore non può più essere sicuro che la protezione di Halloween non sia richiesta (o non sarà richiesta quando il piano viene riutilizzato con valori di parametro diversi):

Nel caso ti stia chiedendo cosa succede se FORCED PARAMETERIZATION è abilitato e la query specifica OPTION (RECOMPILE) , la risposta è che l'ottimizzatore compila un piano per i valori sniffati e quindi può applicare l'ottimizzazione. Come sempre con OPTION (RECOMPILE) , il piano di query con valore specifico non viene memorizzato nella cache per il riutilizzo.
In alto
Quest'ultimo esempio mostra come il Top l'operatore può eliminare la necessità della protezione di Halloween:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

Non è richiesta alcuna protezione perché stiamo aggiornando solo una riga. Il valore aggiornato non può essere rilevato da Index Seek, perché la pipeline di elaborazione si interrompe non appena viene aggiornata la prima riga. Anche in questo caso, questa ottimizzazione può essere applicata solo se viene utilizzato un valore letterale costante nel TOP o se una variabile che restituisce il valore '1' viene sniffata utilizzando OPTION (RECOMPILE) .
Se cambiamo il TOP (1) nella query a un TOP (2) , l'ottimizzatore sceglie una scansione dell'indice in cluster anziché la ricerca dell'indice:

Non stiamo aggiornando le chiavi dell'indice cluster, quindi questo piano non richiede la protezione di Halloween. Forzare l'uso dell'indice non cluster con un suggerimento nel TOP (2) query rende evidente il costo della protezione:

L'ottimizzatore ha stimato che la scansione dell'indice in cluster sarebbe stata più economica di questo piano (con la sua protezione aggiuntiva per Halloween).
Quote e finali
Ci sono un paio di altri punti che voglio sottolineare su Halloween Protection che non hanno trovato un posto naturale nella serie prima d'ora. La prima è la questione della protezione di Halloween quando è in uso un livello di isolamento del controllo delle versioni delle righe.
Versionamento delle righe
SQL Server fornisce due livelli di isolamento, READ COMMITTED SNAPSHOT e SNAPSHOT ISOLATION che utilizzano un archivio versioni in tempdb per fornire una visualizzazione coerente a livello di istruzione o transazione del database. SQL Server potrebbe evitare completamente la protezione di Halloween in questi livelli di isolamento, poiché l'archivio versioni può fornire dati non interessati da eventuali modifiche apportate dall'istruzione attualmente in esecuzione. Questa idea non è attualmente implementata in una versione rilasciata di SQL Server, sebbene Microsoft abbia depositato un brevetto che descrive come funzionerebbe, quindi forse una versione futura incorporerà questa tecnologia.
Heap e record inoltrati
Se hai familiarità con gli interni delle strutture heap, ti starai chiedendo se potrebbe verificarsi un particolare problema di Halloween quando i record inoltrati vengono generati in una tabella heap. Nel caso in cui questo sia nuovo per te, un record heap verrà inoltrato se una riga esistente viene aggiornata in modo tale che non rientri più nella pagina dei dati originale. Il motore lascia uno stub di inoltro e sposta il record espanso in un'altra pagina.
Potrebbe verificarsi un problema se un piano contenente una scansione heap aggiorna un record in modo che venga inoltrato. La scansione heap potrebbe incontrare nuovamente la riga quando la posizione di scansione raggiunge la pagina con il record inoltrato. In SQL Server questo problema viene evitato perché Storage Engine garantisce di seguire sempre immediatamente i puntatori di inoltro. Se la scansione rileva un record che è stato inoltrato, lo ignora. Con questa protezione in atto, Query Optimizer non deve preoccuparsi di questo scenario.
SCHEMABINDING e funzioni scalari T-SQL
Ci sono pochissime occasioni in cui l'utilizzo di una funzione scalare T-SQL è una buona idea, ma se devi usarne una dovresti essere consapevole di un effetto importante che può avere sulla protezione di Halloween. A meno che una funzione scalare non sia dichiarata con SCHEMABINDING opzione, SQL Server presuppone che la funzione acceda alle tabelle. Per illustrare, considera la semplice funzione scalare T-SQL di seguito:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Questa funzione non accede ad alcuna tabella; infatti non fa altro che restituire il valore del parametro passatogli. Ora guarda il seguente INSERT domanda:
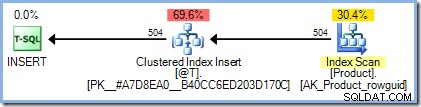
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
Il piano di esecuzione è esattamente come ci si aspetterebbe, senza la protezione di Halloween necessaria:
Tuttavia, l'aggiunta della nostra funzione di non fare nulla ha un effetto drammatico:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

Il piano di esecuzione ora include una bobina da tavolo desiderosa per la protezione di Halloween. SQL Server presuppone che la funzione acceda ai dati, che potrebbero includere nuovamente la lettura dalla tabella Product. Come ricorderete, un INSERT il piano che contiene un riferimento alla tabella di destinazione sul lato di lettura del piano richiede la protezione completa di Halloween e, per quanto ne sa l'ottimizzatore, potrebbe essere il caso qui.
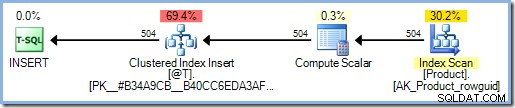
Aggiunta di SCHEMABINDING opzione per la definizione della funzione significa che SQL Server esamina il corpo della funzione per determinare a quali tabelle accede. Non trova tale accesso e quindi non aggiunge alcuna protezione di Halloween:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
Questo problema con le funzioni scalari T-SQL interessa tutte le query di aggiornamento:INSERT , UPDATE , DELETE e MERGE . Sapere quando stai riscontrando questo problema è reso più difficile perché la protezione di Halloween non necessaria non verrà sempre visualizzata come uno spool di tabella Eager aggiuntivo e le chiamate di funzioni scalari potrebbero essere nascoste nelle viste o nelle definizioni di colonne calcolate, ad esempio.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]