Introduzione
Di recente abbiamo riscontrato un interessante problema di prestazioni su uno dei nostri database SQL Server che elabora le transazioni a un ritmo serio. La tabella delle transazioni utilizzata per acquisire queste transazioni è diventata una tabella calda. Di conseguenza, il problema si è presentato nel livello dell'applicazione. È stato un timeout intermittente della sessione che cercava di pubblicare transazioni.
Ciò accadeva perché una sessione in genere "reggeva" la tabella e causava una serie di blocchi spuri nel database.
La prima reazione di un tipico amministratore di database sarebbe identificare la sessione di blocco primaria e terminarla in modo sicuro. Questo era sicuro perché in genere era un'istruzione SELECT o una sessione inattiva.
Ci sono stati anche altri tentativi per risolvere il problema:
- Eliminazione del tavolo. Ciò avrebbe dovuto garantire buone prestazioni anche se la query doveva scansionare un'intera tabella.
- Abilitazione del livello di isolamento READ COMMITTED SNAPSHOT per ridurre l'impatto del blocco delle sessioni.
In questo articolo, proveremo a ricreare una versione semplicistica dello scenario e la useremo per mostrare come l'indicizzazione semplice può affrontare situazioni come questa se eseguita correttamente.
Due tabelle correlate
Dai un'occhiata al Listato 1 e al Listato 2. Mostrano le versioni semplificate delle tabelle coinvolte nello scenario in esame.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Il Listato 3 mostra un trigger che inserisce quattro righe in TranDetails tabella per ogni riga inserita nel TranLog tabella.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Unisciti alla query
È tipico trovare tabelle di transazione supportate da tabelle di grandi dimensioni. Lo scopo è conservare transazioni molto più vecchie o memorizzare i dettagli dei record riepilogati nella prima tabella. Pensa a questo come a ordini e dettagli dell'ordine tabelle tipiche nei database di esempio di SQL Server. Nel nostro caso, stiamo considerando il TranLog e DettagliTran tabelle.
In circostanze normali, le transazioni popolano queste due tabelle nel tempo. In termini di report o query semplici, la query eseguirà un join su queste due tabelle. Questo join capitalizzerà su una colonna comune tra le tabelle.
Per prima cosa, riempiamo la tabella usando la query nel Listato 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
Nel nostro esempio, la colonna comune utilizzata dal join è TranID colonna:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Puoi vedere le due semplici query di esempio che utilizzano un join per recuperare i record da TranLog e DettagliTran .
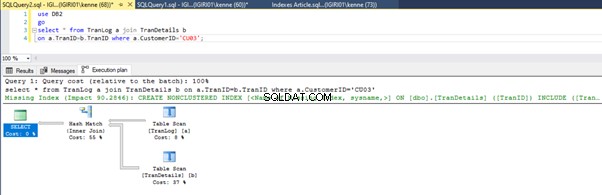
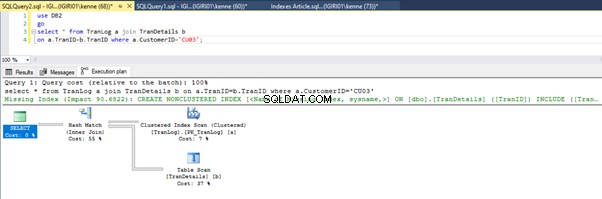
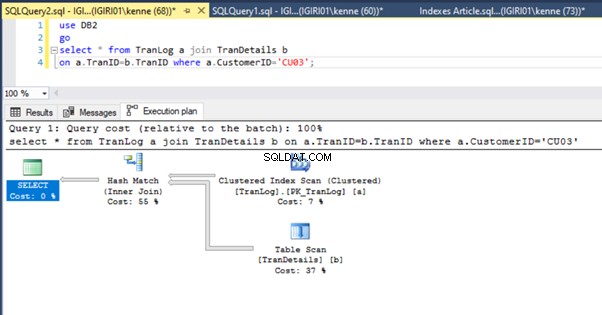
Quando eseguiamo le query nel Listato 5, in entrambi i casi, dobbiamo eseguire una scansione completa della tabella su entrambe le tabelle (vedi Figure 1 e 2). La parte dominante di ogni query sono le operazioni fisiche. Entrambi sono giunti interni. Tuttavia, il Listato 5a utilizza una Corrispondenza hash join, mentre il Listato 5b utilizza un Nested Loop giuntura. Nota:il Listato 5a restituisce 4000 righe mentre il Listato 4b restituisce 4 righe.
Tre passaggi per l'ottimizzazione delle prestazioni
La prima ottimizzazione che facciamo è introdurre un indice (una chiave primaria, per l'esattezza) sul TranID colonna del TranLog tabella:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
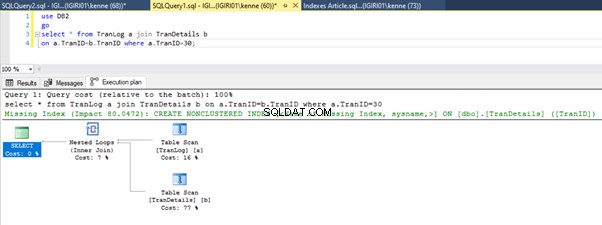
Le figure 3 e 4 mostrano che SQL Server utilizza questo indice in entrambe le query, effettuando una scansione nel Listato 5a e una ricerca nel Listato 5b.
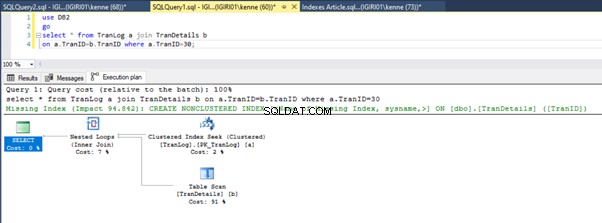
Abbiamo un indice di ricerca nel Listato 5b. Succede a causa della colonna coinvolta nel predicato della clausola WHERE – TranID. È quella colonna su cui abbiamo applicato un indice.
Successivamente, introduciamo una chiave esterna su TranID colonna di TranDetails tabella (Listato 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Questo non cambia molto nel piano di esecuzione. La situazione è praticamente la stessa mostrata in precedenza nelle Figure 3 e 4.
Quindi introduciamo un indice nella colonna della chiave esterna:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
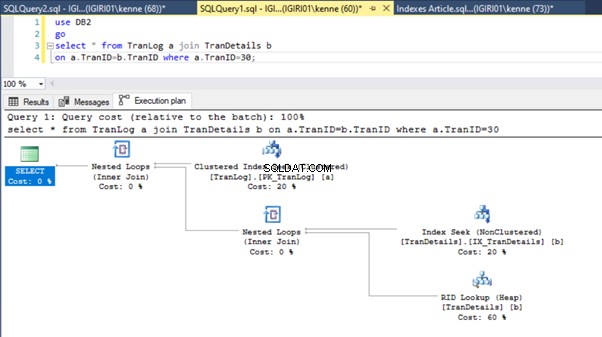
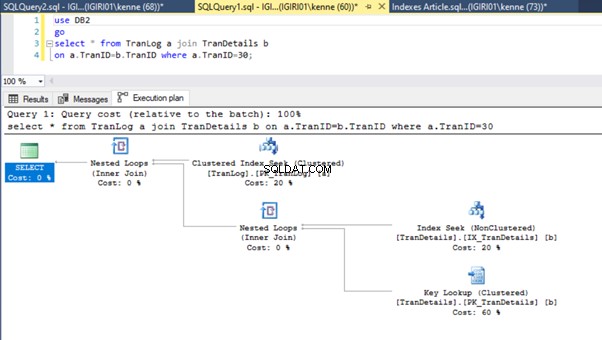
Questa azione cambia drasticamente il piano di esecuzione del Listato 5b (vedi Figura 6). Vediamo che più indice cerca di accadere. Notare anche la ricerca RID nella Figura 6.
Le ricerche RID negli heap si verificano in genere in assenza di una chiave primaria. Un heap è una tabella senza chiave primaria.
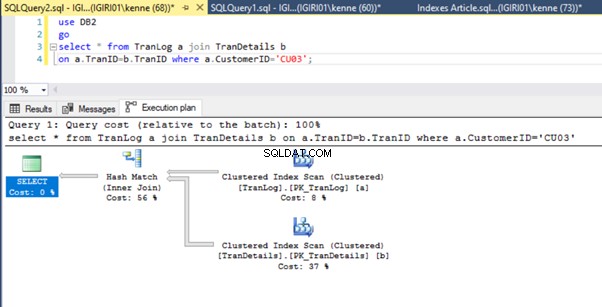
Infine, aggiungiamo una chiave primaria a TranDetails tavolo. Ciò elimina la scansione della tabella e la ricerca dell'heap RID rispettivamente negli elenchi 5a e 5b (vedere le figure 7 e 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Conclusione
Il miglioramento delle prestazioni introdotto dagli indici è noto anche ai DBA inesperti. Tuttavia, desideriamo sottolineare che è necessario esaminare attentamente il modo in cui le query utilizzano gli indici.
Inoltre, l'idea è quella di stabilire la soluzione nel caso particolare in cui abbiamo le query di join tra Registro delle transazioni tabelle e Dettagli transazione tabelle.
In genere ha senso rafforzare la relazione tra tali tabelle utilizzando una chiave e introdurre indici nelle colonne della chiave primaria ed esterna.
Nello sviluppo di applicazioni che utilizzano tale design, gli sviluppatori dovrebbero tenere a mente gli indici e le relazioni richiesti in fase di progettazione. Gli strumenti moderni per gli specialisti di SQL Server rendono molto più semplice soddisfare questi requisiti. Puoi profilare le tue query utilizzando lo strumento specializzato Query Profiler. Fa parte della soluzione professionale multifunzionale dbForge Studio per SQL Server sviluppata da Devart per semplificare la vita di DBA.