Penso che tutti conoscano già le mie opinioni su MERGE e perché ne sto lontano. Ma ecco un altro modello (anti) che vedo dappertutto quando le persone vogliono eseguire un upsert (aggiornare una riga se esiste e inserirla se non lo fa):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Sembra un flusso abbastanza logico che riflette il modo in cui pensiamo a questo nella vita reale:
- Esiste già una riga per questa chiave?
- SI :OK, aggiorna quella riga.
- NO :OK, quindi aggiungilo.
Ma è uno spreco.
Individuare la riga per confermare che esiste, solo per doverla ritrovare per aggiornarla, sta facendo il doppio del lavoro per niente. Anche se la chiave è indicizzata (cosa che spero sia sempre così). Se inserissi questa logica in un diagramma di flusso e associo, ad ogni passaggio, il tipo di operazione che dovrebbe avvenire all'interno del database, avrei questo:
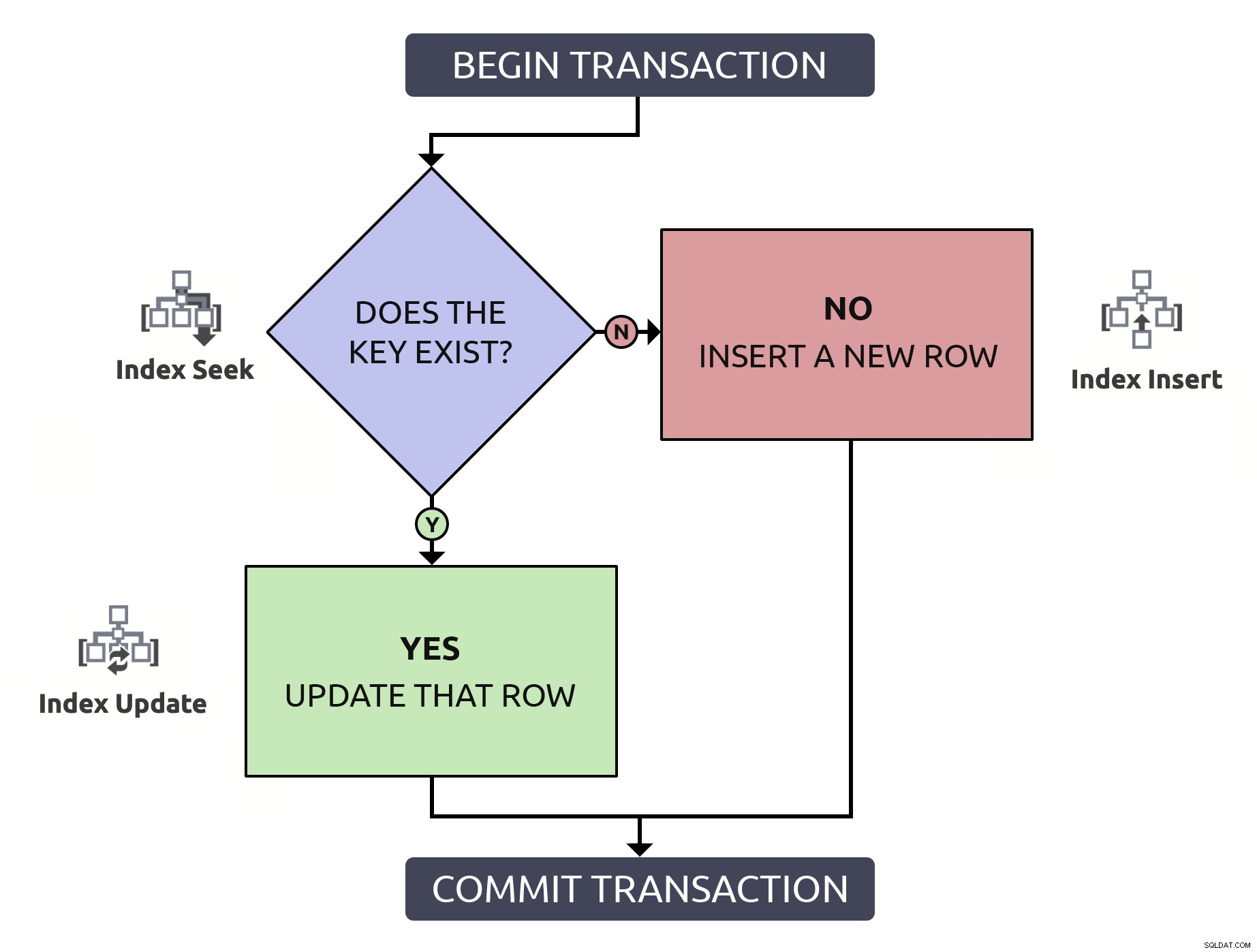 Si noti che tutti i percorsi subiranno due operazioni sull'indice.
Si noti che tutti i percorsi subiranno due operazioni sull'indice.
Ancora più importante, prestazioni a parte, a meno che tu non utilizzi una transazione esplicita e non aumenti il livello di isolamento, più cose potrebbero andare storte quando la riga non esiste già:
- Se la chiave esiste e due sessioni tentano di aggiornarsi contemporaneamente, entrambe si aggiorneranno correttamente (uno "vincerà"; il "perdente" seguirà con il cambiamento che rimane, portando a un "aggiornamento perso"). Questo non è un problema di per sé, ed è come dovremmo aspettarsi che un sistema con concorrenza funzioni. Paul White parla più dettagliatamente della meccanica interna qui, e Martin Smith parla di alcune altre sfumature qui.
- Se la chiave non esiste, ma entrambe le sessioni superano il controllo di esistenza allo stesso modo, potrebbe succedere di tutto quando entrambe tentano di inserire:
- stallo a causa di blocchi incompatibili;
- solleva errori di violazione chiave non sarebbe dovuto succedere; o,
- inserire valori chiave duplicati se quella colonna non è vincolata correttamente.
Quest'ultimo è il peggiore, IMHO, perché è quello che potenzialmente corrompe i dati . I deadlock e le eccezioni possono essere gestiti facilmente con cose come la gestione degli errori, XACT_ABORT e riprovare la logica, a seconda della frequenza con cui si prevedono collisioni. Ma se sei cullato da un senso di sicurezza che il IF EXISTS check ti protegge dai duplicati (o dalle violazioni delle chiavi), che è una sorpresa in attesa di accadere. Se prevedi che una colonna agisca come una chiave, rendila ufficiale e aggiungi un vincolo.
"Molte persone dicono..."
Dan Guzman ha parlato delle condizioni di gara più di dieci anni fa in Conditional INSERT/UPDATE Race Condition e successivamente in "UPSERT" Race Condition With MERGE.
Anche Michael Swart ha trattato questo argomento più volte:
- Mitobusting:soluzioni di aggiornamento/inserimento simultanee – dove ha riconosciuto che lasciare la logica iniziale in atto e solo elevare il livello di isolamento ha appena cambiato le violazioni delle chiavi in deadlock;
- Fai attenzione con la dichiarazione di fusione, dove ha verificato il suo entusiasmo per
MERGE; e, - Cosa evitare se si desidera utilizzare MERGE – dove ha confermato ancora una volta che ci sono ancora molti validi motivi per continuare a evitare
MERGE.
Assicurati di leggere anche tutti i commenti su tutti e tre i post.
La soluzione
Ho risolto molti deadlock nella mia carriera semplicemente adattandomi al seguente schema (abbandona l'assegno ridondante, avvolgi la sequenza in una transazione e proteggi il primo accesso alla tabella con il blocco appropriato):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Perché abbiamo bisogno di due suggerimenti? Non è UPDLOCK abbastanza?
UPDLOCKviene utilizzato per proteggere dai deadlock di conversione nell'istruzione livello (lascia aspettare un'altra sessione invece di incoraggiare una vittima a riprovare).SERIALIZABLEviene utilizzato per proteggere dalle modifiche ai dati sottostanti durante la transazione (assicurati che una riga che non esiste continui a non esistere).
È un po' più di codice, ma è 1000% più sicuro e anche nel peggiore case (la riga non esiste già), funziona come l'anti-pattern. Nel migliore dei casi, se stai aggiornando una riga già esistente, sarà più efficiente individuare quella riga solo una volta. Combinando questa logica con le operazioni di alto livello che dovrebbero avvenire nel database, è leggermente più semplice:
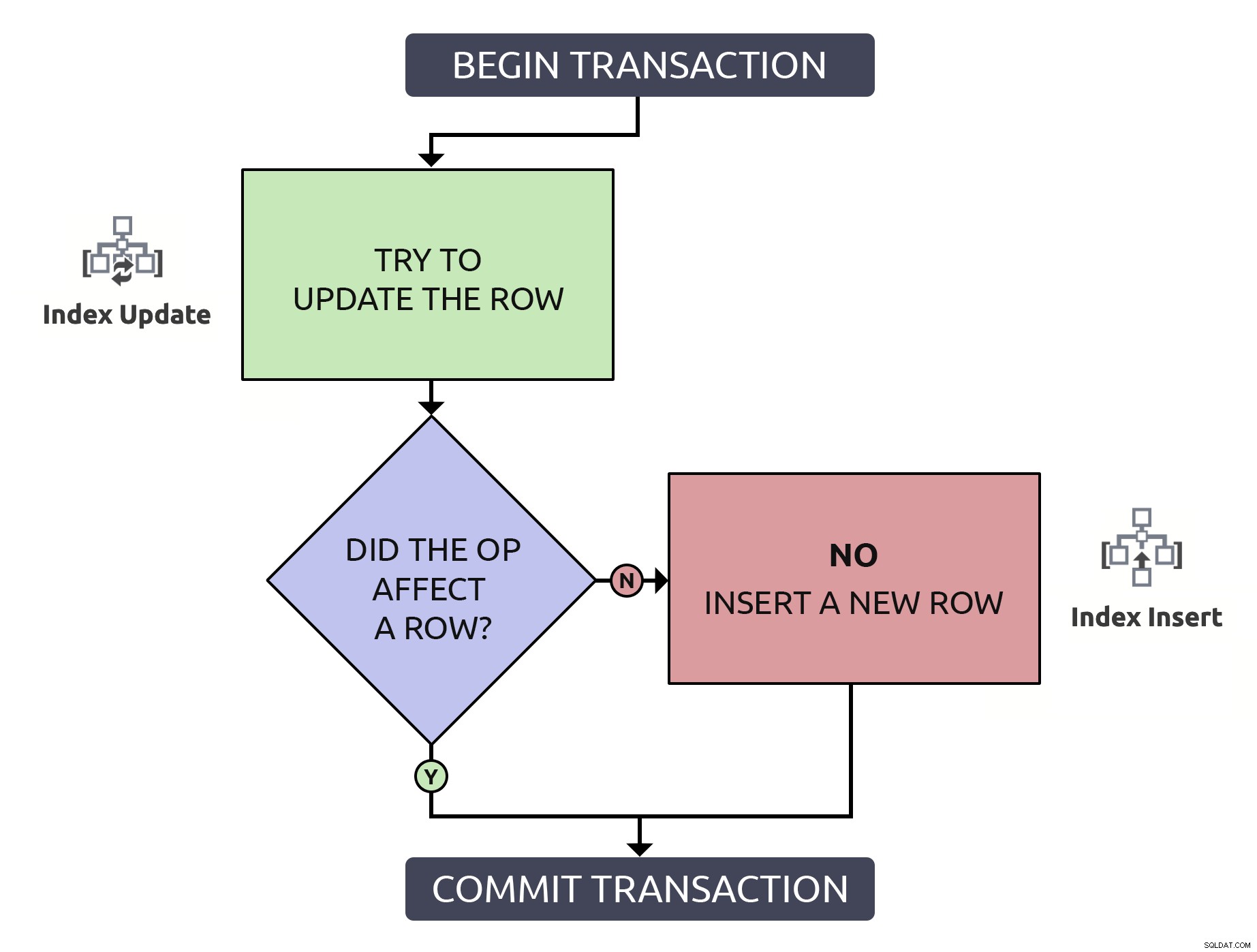 In questo caso, un percorso comporta solo una singola operazione di indice.
In questo caso, un percorso comporta solo una singola operazione di indice.
Ma ancora, prestazioni a parte:
- Se la chiave esiste e due sessioni tentano di aggiornarla contemporaneamente, si alterneranno entrambe e aggiorneranno la riga con successo , come prima.
- Se la chiave non esiste, una sessione "vincerà" e inserirà la riga . L'altro dovrà aspettare fino a quando i blocchi non vengono rilasciati per verificarne l'esistenza ed essere costretti ad aggiornare.
In entrambi i casi, lo scrittore che ha vinto la gara perde i propri dati a causa di qualcosa che il "perdente" ha aggiornato dopo di loro.
Tieni presente che il throughput complessivo su un sistema altamente simultaneo potrebbe soffrire, ma questo è un compromesso che dovresti essere disposto a fare. Il fatto che tu stia ricevendo molte vittime di deadlock o errori di violazione delle chiavi, ma si verificano rapidamente, non è una buona metrica delle prestazioni. Ad alcune persone piacerebbe vedere tutti i blocchi rimossi da tutti gli scenari, ma alcuni di questi ti bloccano per l'integrità dei dati.
E se un aggiornamento è meno probabile?
È chiaro che la soluzione di cui sopra ottimizza per gli aggiornamenti e presuppone che una chiave su cui si sta tentando di scrivere esiste già nella tabella tanto spesso quanto non lo è. Se preferisci ottimizzare per gli inserimenti, sapendo o supponendo che gli inserimenti saranno più probabili degli aggiornamenti, puoi capovolgere la logica e avere comunque un'operazione di inserimento sicura:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; C'è anche l'approccio "fallo e basta", in cui inserisci ciecamente e consenti alle collisioni di sollevare eccezioni al chiamante:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Il costo di tali eccezioni spesso supererà il costo del primo controllo; dovrai provarlo con un'ipotesi approssimativamente accurata della percentuale di hit/miss. Ne ho scritto qui e qui.
Che ne dici di inserire più righe?
Quanto sopra riguarda le decisioni di inserimento/aggiornamento singleton, ma Justin Pealing ha chiesto cosa fare quando si elaborano più righe senza sapere quale di esse esiste già?
Supponendo che tu stia inviando un set di righe utilizzando qualcosa come un parametro con valori di tabella, aggiorneresti utilizzando un join e quindi inserirai utilizzando NOT EXISTS, ma il modello sarebbe comunque equivalente al primo approccio sopra:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Se stai mettendo insieme più righe in un modo diverso da un TVP (XML, elenco separato da virgole, voodoo), inseriscile prima in un modulo tabella e unisci a qualunque cosa sia. Fai attenzione a non ottimizzare prima gli inserimenti in questo scenario, altrimenti potresti potenzialmente aggiornare alcune righe due volte.
Conclusione
Questi modelli di upsert sono superiori a quelli che vedo troppo spesso e spero che inizierai a usarli. Indicherò questo post ogni volta che vedo il IF EXISTS modello in natura. E, ehi, un altro ringraziamento a Paul White (sql.kiwi | @SQK_Kiwi), perché è così eccellente nel rendere i concetti difficili facili da capire e, a sua volta, spiegare.
E se ritieni di doverlo usa MERGE , per favore non @ me; o hai una buona ragione (forse hai bisogno di un oscuro MERGE -solo funzionalità), oppure non hai preso sul serio i link sopra.