;
Ciò che rende ricorsivo un membro è avere un riferimento al nome CTE. Questo riferimento rappresenta il set di risultati dell'ultima esecuzione. Nella prima esecuzione del membro ricorsivo, il riferimento al nome CTE rappresenta il set di risultati del membro di ancoraggio. Nell'ennesima esecuzione, dove N> 1, il riferimento al nome CTE rappresenta il set di risultati dell'esecuzione (N – 1) del membro ricorsivo. Come accennato, una volta che il membro ricorsivo restituisce un set vuoto, non viene più eseguito. Un riferimento al nome CTE nella query esterna rappresenta i set di risultati unificati della singola esecuzione del membro di ancoraggio e tutte le esecuzioni del membro ricorsivo.
Il codice seguente implementa l'attività sopra menzionata di restituire il sottoalbero dei dipendenti per un determinato gestore di input, passando l'ID dipendente 3 come dipendente root in questo esempio:
DICHIARA @root AS INT =3; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid)SELECT empid, mgrid, empnameDA C;
La query di ancoraggio viene eseguita una sola volta, restituendo la riga per l'impiegato root di input (impiegato 3 nel nostro caso).
La query ricorsiva unisce l'insieme dei dipendenti del livello precedente, rappresentato dal riferimento al nome CTE, alias M per i manager, con i loro diretti subordinati della tabella Impiegati, alias S per i subordinati. Il predicato di join è S.mgrid =M.empid, il che significa che il valore mgrid del subordinato è uguale al valore empid del manager. La query ricorsiva viene eseguita quattro volte come segue:
- Restituire i subordinati del dipendente 3; output:dipendente 7
- Restituire i subordinati del dipendente 7; output:dipendenti 9 e 11
- Ritorno subordinati dei dipendenti 9 e 11; uscita:12, 13 e 14
- Restituire i subordinati dei dipendenti 12, 13 e 14; uscita:insieme vuoto; fermate di ricorsione
Il riferimento al nome CTE nella query esterna rappresenta i risultati unificati della singola esecuzione della query anchor (dipendente 3) con i risultati di tutte le esecuzioni della query ricorsiva (dipendenti 7, 9, 11, 12, 13 e 14). Questo codice genera il seguente output:
empid mgrid empname------ ------ --------3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi
Un problema comune nelle soluzioni di programmazione è il codice in fuga come i loop infiniti in genere causati da un bug. Con le CTE ricorsive, un bug potrebbe portare a un'esecuzione in pista del membro ricorsivo. Ad esempio, supponiamo che nella nostra soluzione per restituire i subordinati di un dipendente di input, tu abbia avuto un bug nel predicato di join del membro ricorsivo. Invece di usare ON S.mgrid =M.empid, hai usato ON S.mgrid =S.mgrid, in questo modo:
DICHIARA @root AS INT =3; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =S .mgrid)SELECT empid, mgrid, empnameDA C;
Dato almeno un dipendente con un ID manager non nullo presente nella tabella, l'esecuzione del membro ricorsivo continuerà a restituire un risultato non vuoto. Ricorda che la condizione di terminazione implicita per il membro ricorsivo è quando la sua esecuzione restituisce un set di risultati vuoto. Se restituisce un set di risultati non vuoto, SQL Server lo esegue nuovamente. Ti rendi conto che se SQL Server non avesse un meccanismo per limitare le esecuzioni ricorsive, continuerebbe a eseguire ripetutamente il membro ricorsivo per sempre. Come misura di sicurezza, T-SQL supporta un'opzione di query MAXRECURSION che limita il numero massimo consentito di esecuzioni del membro ricorsivo. Per impostazione predefinita, questo limite è impostato su 100, ma è possibile modificarlo in qualsiasi valore SMALLINT non negativo, con 0 che non rappresenta alcun limite. L'impostazione del limite di ricorsione massima su un valore N positivo significa che il tentativo di esecuzione N + 1 del membro ricorsivo viene interrotto con un errore. Ad esempio, eseguire il codice con errori di cui sopra così com'è significa fare affidamento sul limite di ricorsione massima predefinito di 100, quindi l'esecuzione 101 del membro ricorsivo non riesce:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...
Msg 530, livello 16, stato 1, riga 121
L'istruzione è terminata. La ricorsione massima 100 è stata esaurita prima del completamento dell'istruzione.
Supponiamo che nella tua organizzazione sia lecito ritenere che la gerarchia dei dipendenti non superi i 6 livelli di gestione. Puoi ridurre il limite di ricorsione massima da 100 a un numero molto più piccolo, ad esempio 10 per sicurezza, in questo modo:
DICHIARA @root AS INT =3; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =S .mgrid)SELECT empid, mgrid, empnameDA COPZIONE (MAXRECURSION 10);
Ora, se c'è un bug che provoca un'esecuzione incontrollata del membro ricorsivo, verrà scoperto all'11 tentativo di esecuzione del membro ricorsivo invece che all'esecuzione 101:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...
Msg 530, livello 16, stato 1, riga 149
L'istruzione è terminata. La ricorsione massima 10 è stata esaurita prima del completamento dell'istruzione.
È importante notare che il limite di ricorsione massima dovrebbe essere utilizzato principalmente come misura di sicurezza per interrompere l'esecuzione di codice runaway buggy. Ricorda che quando il limite viene superato, l'esecuzione del codice viene interrotta con un errore. Non dovresti usare questa opzione per limitare il numero di livelli da visitare a scopo di filtraggio. Non vuoi che venga generato un errore quando non ci sono problemi con il codice.
A scopo di filtraggio, puoi limitare il numero di livelli da visitare a livello di codice. Definisci una colonna chiamata lvl che tiene traccia del numero di livello dell'impiegato corrente rispetto all'impiegato root di input. Nella query anchor imposti la colonna lvl alla costante 0. Nella query ricorsiva la imposti al valore lvl del manager più 1. Per filtrare tanti livelli sotto la radice di input quanti sono @maxlevel, aggiungi il predicato M.lvl <@ maxlevel alla clausola ON della query ricorsiva. Ad esempio, il codice seguente restituisce l'impiegato 3 e due livelli di subordinati dell'impiegato 3:
DICHIARA @root AS INT =3, @maxlevel AS INT =2; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER UNISCITI a dbo.Employees COME S SU S.mgrid =M.empid AND M.lvl <@maxlevel)SELECT empid, mgrid, empname, lvlFROM C;
Questa query genera il seguente output:
empid mgrid empname lvl------ ------ -------- ----3 1 Ina 07 3 Aaron 19 7 Rita 211 7 Gabriel 2
Clausole RICERCA e CICLO standard
Lo standard SQL ISO/IEC definisce due opzioni molto potenti per i CTE ricorsivi. Uno è una clausola chiamata SEARCH che controlla l'ordine di ricerca ricorsivo e un'altra è una clausola chiamata CYCLE che identifica i cicli nei percorsi attraversati. Ecco la sintassi standard per le due clausole:
7.18
Funzione
Specificare la generazione di informazioni sull'ordine e sul rilevamento del ciclo nel risultato di espressioni di query ricorsive.
Formato
::=
[ ]
AS [ ]
::=
| |
::=
SEARCH SET
::=
DEPTH FIRST BY | BREADTH FIRST BY
::=
::=
CYCLE SET TO
DEFAULT USING
::= [ { }… ]
::=
::=
::=
::=
::=
Al momento in cui scrivo T-SQL non supporta queste opzioni, ma nei seguenti link puoi trovare richieste di miglioramento delle funzionalità che richiedono la loro inclusione in T-SQL in futuro e votarle:
- Aggiungere il supporto per la clausola ISO/IEC SQL SEARCH ai CTE ricorsivi in T-SQL
- Aggiungere il supporto per la clausola ISO/IEC SQL CYCLE ai CTE ricorsivi in T-SQL
Nelle sezioni seguenti descriverò le due opzioni standard e fornirò anche soluzioni alternative logicamente equivalenti attualmente disponibili in T-SQL.
Clausola RICERCA
La clausola SEARCH standard definisce l'ordine di ricerca ricorsivo come BREADTH FIRST o DEPTH FIRST da alcune colonne di ordinamento specificate e crea una nuova colonna di sequenza con le posizioni ordinali dei nodi visitati. Specificare BREADTH FIRST per cercare prima in ogni livello (ampiezza) e poi in basso (profondità). Specificare DEPTH FIRST per cercare prima verso il basso (profondità) e poi attraverso (ampiezza).
Specifica la clausola SEARCH subito prima della query esterna.
Inizierò con un esempio per l'ampiezza del primo ordine di ricerca ricorsivo. Ricorda solo che questa funzionalità non è disponibile in T-SQL, quindi non sarai in grado di eseguire effettivamente gli esempi che usano le clausole standard in SQL Server o Database SQL di Azure. Il codice seguente restituisce il sottoalbero dell'impiegato 1, chiedendo un primo ordine di ricerca in ampiezza per empid, creando una colonna di sequenza chiamata seqbreadth con le posizioni ordinali dei nodi visitati:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) RICERCA BREADTH FIRST BY empid SET seqbreadth----------------------------------------- ---- SELECT empid, mgrid, empname, seqbreadthFROM CORDER BY seqbreadth;
Ecco l'output desiderato di questo codice:
empid mgrid empname seqbreadth------ ------ -------- -----------1 NULL David 12 1 Eitan 23 1 Ina 34 2 Seraph 45 2 Jiru 56 2 Steve 67 3 Aaron 78 5 Lilach 89 7 Rita 910 5 Sean 1011 7 Gabriel 1112 9 Emilia 1213 9 Michael 1314 9 Didi 14
Non lasciarti confondere dal fatto che i valori di seqbreadth sembrano essere identici ai valori empid. Questo è solo un caso a causa del modo in cui ho assegnato manualmente i valori empid nei dati di esempio che ho creato.
La Figura 2 ha una rappresentazione grafica della gerarchia dei dipendenti, con una linea tratteggiata che mostra l'ampiezza del primo ordine in cui i nodi sono stati cercati. I valori empid vengono visualizzati subito sotto i nomi dei dipendenti e i valori seqbreadth assegnati vengono visualizzati nell'angolo in basso a sinistra di ciascuna casella.
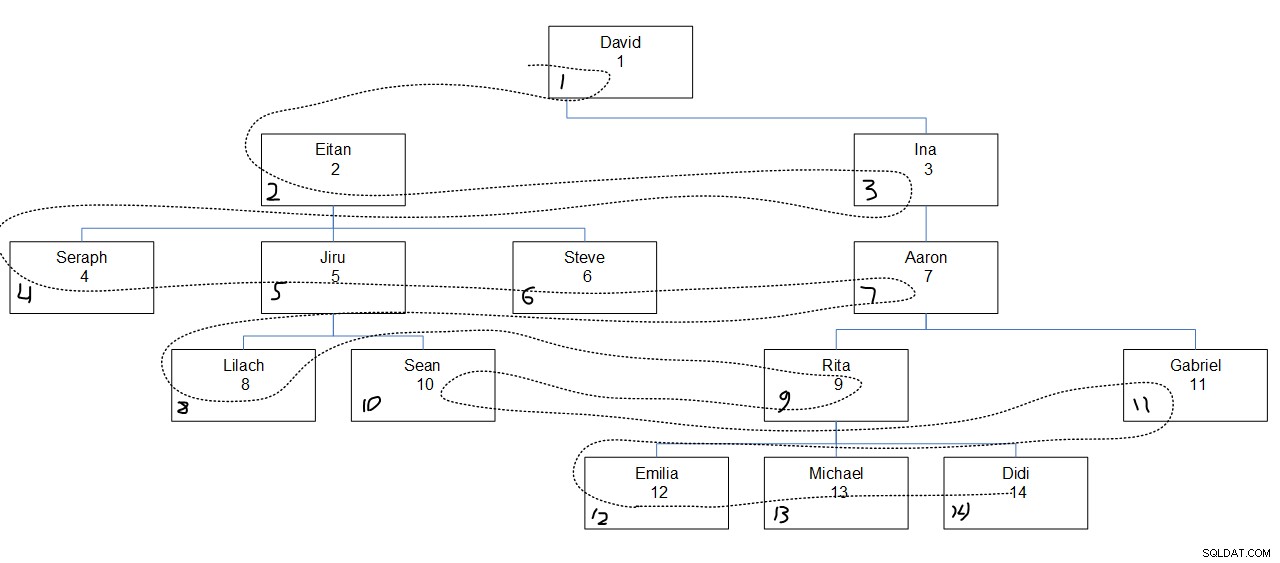 Figura 2:prima l'ampiezza della ricerca
Figura 2:prima l'ampiezza della ricerca
Ciò che è interessante notare qui è che all'interno di ogni livello, i nodi vengono cercati in base all'ordine di colonna specificato (nel nostro caso vuoto) indipendentemente dall'associazione padre del nodo. Ad esempio, si noti che nel quarto livello si accede per primo a Lilach, al secondo Rita, al terzo Sean e all'ultimo Gabriel. Questo perché tra tutti i dipendenti del quarto livello, questo è il loro ordine basato sui loro valori empidi. Non è che Lilach e Sean debbano essere perquisiti consecutivamente perché sono diretti subordinati dello stesso manager, Jiru.
È abbastanza semplice trovare una soluzione T-SQL che fornisca l'equivalente logico dell'opzione SAERCH DEPTH FIRST standard. Crei una colonna chiamata lvl come ho mostrato in precedenza per tracciare il livello del nodo rispetto alla radice (0 per il primo livello, 1 per il secondo e così via). Quindi calcola la colonna della sequenza di risultati desiderata nella query esterna utilizzando una funzione ROW_NUMBER. Come ordinamento della finestra si specifica prima lvl, quindi la colonna di ordinamento desiderata (nel nostro caso vuota). Ecco il codice completo della soluzione:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER UNISCITI a dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadthFROM CORDER BY seqbreadth;
Quindi, esaminiamo l'ordine di ricerca DEPTH FIRST. Secondo lo standard, il codice seguente dovrebbe restituire il sottoalbero dell'impiegato 1, chiedendo un ordine di ricerca depth first per empid, creando una colonna di sequenza chiamata seqdepth con le posizioni ordinali dei nodi cercati:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) SEARCH DEPTH FIRST BY empid SET seqdepth---------------------------------------- SELECT empid, mgrid, empname, seqdepthDA CORDER BY seqdepth;
Di seguito è riportato l'output desiderato di questo codice:
empid mgrid empname seqdepth------ ------ -------- ---------1 NULL David 12 1 Eitan 24 2 Seraph 35 2 Jiru 48 5 Lilach 510 5 Sean 66 2 Steve 73 1 Ina 87 3 Aaron 99 7 Rita 1012 9 Emilia 1113 9 Michael 1214 9 Didi 1311 7 Gabriel 14
Osservando l'output della query desiderato è probabilmente difficile capire perché i valori di sequenza sono stati assegnati nel modo in cui erano. La figura 3 dovrebbe aiutare. Ha una rappresentazione grafica della gerarchia dei dipendenti, con una linea tratteggiata che riflette il primo ordine di ricerca della profondità, con i valori di sequenza assegnati nell'angolo in basso a sinistra di ogni casella.
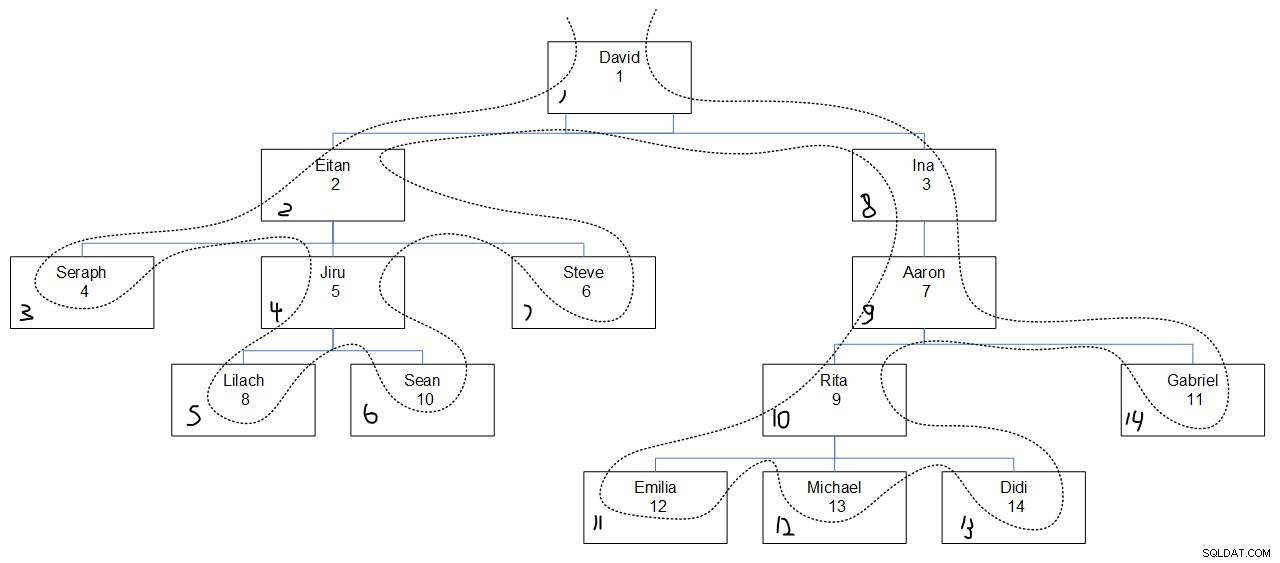 Figura 3:prima la profondità di ricerca
Figura 3:prima la profondità di ricerca
Trovare una soluzione T-SQL che fornisca l'equivalente logico dell'opzione standard SEARCH DEPTH FIRST è un po' complicato, ma fattibile. Descriverò la soluzione in due passaggi.
Nel passaggio 1, per ogni nodo si calcola un percorso di ordinamento binario composto da un segmento per antenato del nodo, con ogni segmento che riflette la posizione di ordinamento dell'antenato tra i suoi fratelli. Costruisci questo percorso in modo simile al modo in cui calcoli la colonna lvl. Cioè, inizia con una stringa binaria vuota per il nodo radice nella query di ancoraggio. Quindi, nella query ricorsiva concateni il percorso del genitore con la posizione di ordinamento del nodo tra fratelli dopo averlo convertito in un segmento binario. Si utilizza la funzione ROW_NUMBER per calcolare la posizione, partizionata dal genitore (mgrid nel nostro caso) e ordinata dalla relativa colonna di ordinamento (empid nel nostro caso). Converti il numero di riga in un valore binario di dimensioni sufficienti a seconda del numero massimo di figli diretti che un genitore può avere nel tuo grafico. BINARY(1) supporta fino a 255 figli per genitore, BINARY(2) supporta 65.535, BINARY(3):16.777.215, BINARY(4):4.294.967.295. In un CTE ricorsivo, le colonne corrispondenti nelle query anchor e ricorsive devono essere dello stesso tipo e dimensione , quindi assicurati di convertire il percorso di ordinamento in un valore binario della stessa dimensione in entrambi.
Ecco il codice che implementa il passaggio 1 nella nostra soluzione (supponendo che BINARY(1) sia sufficiente per segmento, il che significa che non hai più di 255 subordinati diretti per manager):
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, sortpathFROM C;
Questo codice genera il seguente output:
empid mgrid empname sortpath------ ------ -------- ------------1 NULL David 0x2 1 Eitan 0x013 1 Ina 0x027 3 Aaron 0x02019 7 Rita 0x02010111 7 Gabriel 0x02010212 9 Emilia 0x0201010113 9 Michael 0x0201010214 9 Didi 0x020101034 2 Seraph 0x01015 2 Jiru 0x01026 2 Steve 0x01038 5 Lilach 0x010110.
Nota che ho usato una stringa binaria vuota come percorso di ordinamento per il nodo radice del singolo sottoalbero che stiamo interrogando qui. Nel caso in cui il membro di ancoraggio possa potenzialmente restituire più radici di sottoalbero, inizia semplicemente con un segmento basato su un calcolo ROW_NUMBER nella query di ancoraggio, in modo simile al modo in cui lo calcoli nella query ricorsiva. In tal caso, il percorso di ordinamento sarà più lungo di un segmento.
Quello che resta da fare nel passaggio 2 è creare la colonna seqdepth del risultato desiderato calcolando i numeri di riga che sono ordinati in base al percorso di ordinamento nella query esterna, in questo modo
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepthFROM CORDER BY seqdepth;
Questa soluzione è l'equivalente logico dell'utilizzo dell'opzione standard SEARCH DEPTH FIRST mostrata in precedenza insieme all'output desiderato.
Una volta che hai una colonna di sequenza che riflette la profondità prima dell'ordine di ricerca (seqdepth nel nostro caso), con un po' più di sforzo puoi generare una rappresentazione visiva molto bella della gerarchia. Avrai anche bisogno della suddetta colonna lvl. Ordina la query esterna in base alla colonna della sequenza. Restituisci un attributo che vuoi usare per rappresentare il nodo (diciamo, empname nel nostro caso), preceduto da una stringa (diciamo ' | ') replicata lvl volte. Ecco il codice completo per ottenere tale rappresentazione visiva:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, empname, 0 AS lvl, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.empname, M.lvl + 1 AS lvl, CAST(M.sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth, REPLICATE(' | ', lvl) + empname AS empFROM CORDER BY seqdepth;
Questo codice genera il seguente output:
empid seqdepth emp------ --------- --------------------1 1 David2 2 | Eitan4 3 | | Serafino5 4 | | Jiru8 5 | | | Lilla10 6 | | | Sean6 7 | | Steve3 8 | Ina7 9 | | Aaron9 10 | | | Rita12 11 | | | | Emilia13 12 | | | | Michele14 13 | | | | Didi11 14 | | | Gabriele
È davvero fantastico!
Clausola CICLO
Le strutture dei grafi possono avere dei cicli. Tali cicli potrebbero essere validi o non validi. Un esempio di cicli validi è un grafico che rappresenta autostrade e strade che collegano città e paesi. Questo è ciò che viene chiamato grafico ciclico . Al contrario, un grafico che rappresenta una gerarchia di dipendenti come nel nostro caso non dovrebbe avere cicli. Questo è ciò che viene definito un aciclico grafico. Tuttavia, supponiamo che a causa di un aggiornamento errato, finisca con un ciclo involontariamente. Ad esempio, supponiamo di aggiornare per errore l'ID manager del CEO (dipendente 1) al dipendente 14 eseguendo il codice seguente:
UPDATE Impiegati SET mgrid =14WHERE empid =1;
Ora hai un ciclo non valido nella gerarchia dei dipendenti.
Indipendentemente dal fatto che i cicli siano validi o non validi, quando si attraversa la struttura del grafico, di certo non si vuole continuare a perseguire ripetutamente un percorso ciclico. In entrambi i casi si desidera interrompere la ricerca di un percorso una volta trovata una non prima occorrenza dello stesso nodo e contrassegnare tale percorso come ciclico.
Quindi cosa succede quando si interroga un grafico che ha cicli utilizzando una query ricorsiva, senza alcun meccanismo in atto per rilevarli? Questo dipende dall'implementazione. In SQL Server, a un certo punto raggiungerai il limite massimo di ricorsione e la tua query verrà interrotta. Ad esempio, supponendo che tu abbia eseguito l'aggiornamento precedente che ha introdotto il ciclo, prova a eseguire la seguente query ricorsiva per identificare il sottoalbero del dipendente 1:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid)SELECT empid, mgrid, empnameDA C;
Poiché questo codice non imposta un limite di ricorsione massima esplicito, viene assunto il limite predefinito di 100. SQL Server interrompe l'esecuzione di questo codice prima del completamento e genera un errore:
empid mgrid empname------ ------ --------1 14 David2 1 Eitan3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi1 14 David2 1 Eitan3 1 Ina7 3 Aaron...
Msg 530, livello 16, stato 1, riga 432
L'istruzione è terminata. La ricorsione massima 100 è stata esaurita prima del completamento dell'istruzione.
Lo standard SQL definisce una clausola chiamata CYCLE per CTE ricorsivi, consentendoti di gestire i cicli nel tuo grafico. Specificare questa clausola subito prima della query esterna. Se è presente anche una clausola SEARCH, la specifichi prima e poi la clausola CYCLE. Ecco la sintassi della clausola CYCLE:
CICLO
IMPOSTA TO DEFAULT
USING
Il rilevamento di un ciclo si basa sull'elenco di colonne ciclo specificato . Ad esempio, nella nostra gerarchia dei dipendenti, probabilmente vorrai utilizzare la colonna empid per questo scopo. Quando lo stesso valore empid appare per la seconda volta, viene rilevato un ciclo e la query non segue più tale percorso. Specifica una nuova colonna contrassegno ciclo che indicherà se un ciclo è stato trovato o meno e i tuoi valori come segno di ciclo e segno di non ciclo valori. Ad esempio, potrebbero essere 1 e 0 o "Sì" e "No" o qualsiasi altro valore a tua scelta. Nella clausola USING specifichi un nuovo nome di colonna dell'array che conterrà il percorso dei nodi trovati finora.
Ecco come gestiresti una richiesta di subordinati di un dipendente root di input, con la possibilità di rilevare i cicli in base alla colonna empid, indicando 1 nella colonna del contrassegno del ciclo quando viene rilevato un ciclo e 0 in caso contrario:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) CYCLE empid SET cycle TO 1 DEFAULT 0------------------------------------- SELECT empid, mgrid, empnameDA C;
Ecco l'output desiderato di questo codice:
empid mgrid empname cycle------ ------ -------- ------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0
T-SQL attualmente non supporta la clausola CYCLE, ma esiste una soluzione alternativa che fornisce un equivalente logico. Prevede tre passaggi. Ricorda che in precedenza hai creato un percorso di ordinamento binario per gestire l'ordine di ricerca ricorsivo. In modo simile, come primo passaggio della soluzione, costruisci un percorso degli antenati basato su una stringa di caratteri composto dagli ID dei nodi (ID dei dipendenti nel nostro caso) degli antenati che portano al nodo corrente, incluso il nodo corrente. Vuoi dei separatori tra gli ID dei nodi, inclusi uno all'inizio e uno alla fine.
Ecco il codice per costruire un tale percorso degli antenati:
DICHIARA @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpathFROM C;
Questo codice genera il seguente output, continuando a perseguire percorsi ciclici, e quindi interrompendo prima del completamento una volta superato il limite massimo di ricorsione:
empid mgrid empname ancpath------ ------ -------- -------------------1 14 David . 1.2 1 Eitan .1.2.3 1 Ina .1.3.7 3 Aaron .1.3.7.9 7 Rita .1.3.7.9.11 7 Gabriel .1.3.7.11.12 9 Emilia .1.3.7.9.12.13 9 Michael .1.3.7.9. 13.14 9 Didi .1.3.7.9.14.1 14 David .1.3.7.9.14.1.2 1 Eitan .1.3.7.9.14.1.2.3 1 Ina .1.3.7.9.14.1.3.7 3 Aaron .1.3.7.9.14.1.3.7. ...
Msg 530, livello 16, stato 1, riga 492
L'istruzione è terminata. La ricorsione massima 100 è stata esaurita prima del completamento dell'istruzione.
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' .
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpath, cycleFROM C;
This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle------ ------ -------- ------------------- ------1 14 David .1. 02 1 Eitan .1.2. 03 1 Ina .1.3. 07 3 Aaron .1.3.7. 09 7 Rita .1.3.7.9. 011 7 Gabriel .1.3.7.11. 012 9 Emilia .1.3.7.9.12. 013 9 Michael .1.3.7.9.13. 014 9 Didi .1.3.7.9.14. 01 14 David .1.3.7.9.14.1. 12 1 Eitan .1.3.7.9.14.1.2. 03 1 Ina .1.3.7.9.14.1.3. 17 3 Aaron .1.3.7.9.14.1.3.7. 1...
Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.cycle =0)SELECT empid, mgrid, empname, cycleFROM C;
This code runs to completion, and generates the following output:
empid mgrid empname cycle------ ------ -------- -----------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid =NULLWHERE empid =1;
Run the recursive query and you will find that there are no cycles present.
Conclusione
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.
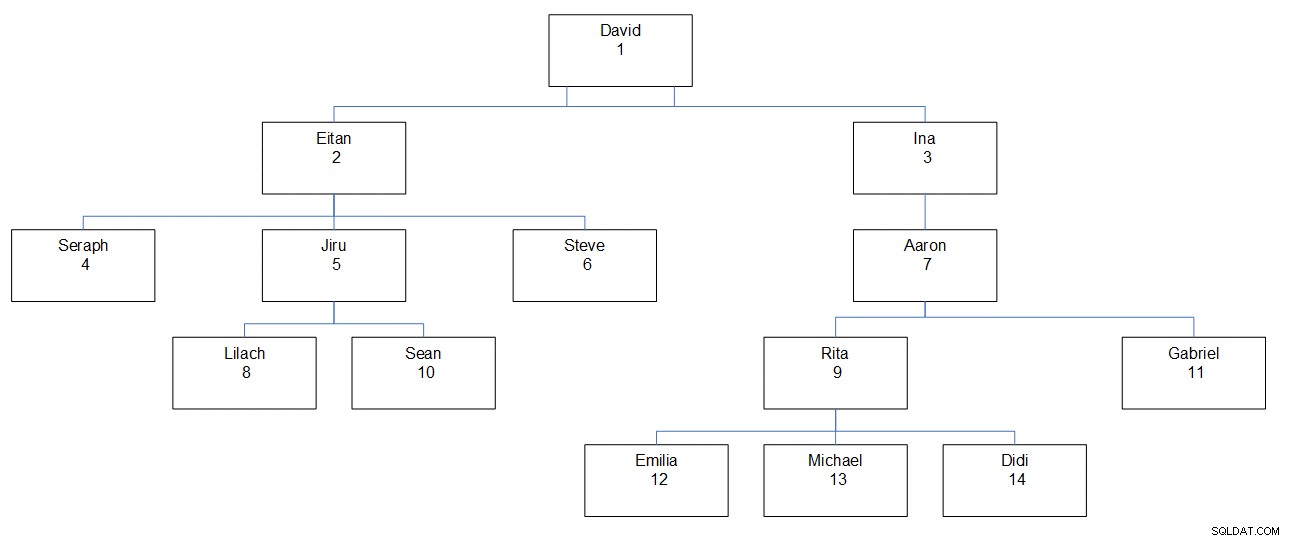 Figura 1:Gerarchia dei dipendenti
Figura 1:Gerarchia dei dipendenti