Crescendo, amavo i giochi che mettevano alla prova la memoria e le capacità di corrispondenza dei modelli. Molti dei miei amici avevano Simon, mentre io avevo un imitatore chiamato Einstein. Altri avevano un Atari Touch Me, che già allora sapevo fosse una decisione di denominazione discutibile. Al giorno d'oggi, la corrispondenza dei modelli significa qualcosa di molto diverso per me e può essere una parte costosa delle query quotidiane sui database.
Crescendo, amavo i giochi che mettevano alla prova la memoria e le capacità di corrispondenza dei modelli. Molti dei miei amici avevano Simon, mentre io avevo un imitatore chiamato Einstein. Altri avevano un Atari Touch Me, che già allora sapevo fosse una decisione di denominazione discutibile. Al giorno d'oggi, la corrispondenza dei modelli significa qualcosa di molto diverso per me e può essere una parte costosa delle query quotidiane sui database.
Di recente mi sono imbattuto in un paio di commenti su Stack Overflow in cui un utente affermava, come se fosse un dato di fatto, che CHARINDEX funziona meglio di LEFT o LIKE . In un caso, la persona ha citato un articolo di David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX". Sì, l'articolo mostra che, nell'esempio inventato, CHARINDEX ha funzionato meglio. Tuttavia, dal momento che sono sempre scettico su affermazioni generali del genere e non riesco a pensare a un motivo logico per cui una funzione di stringa dovrebbe sempre avere prestazioni migliori di un altro, a parità di condizioni , ho eseguito i suoi test. Abbastanza sicuro, ho avuto risultati ripetutamente diversi sulla mia macchina (clicca per ingrandire):
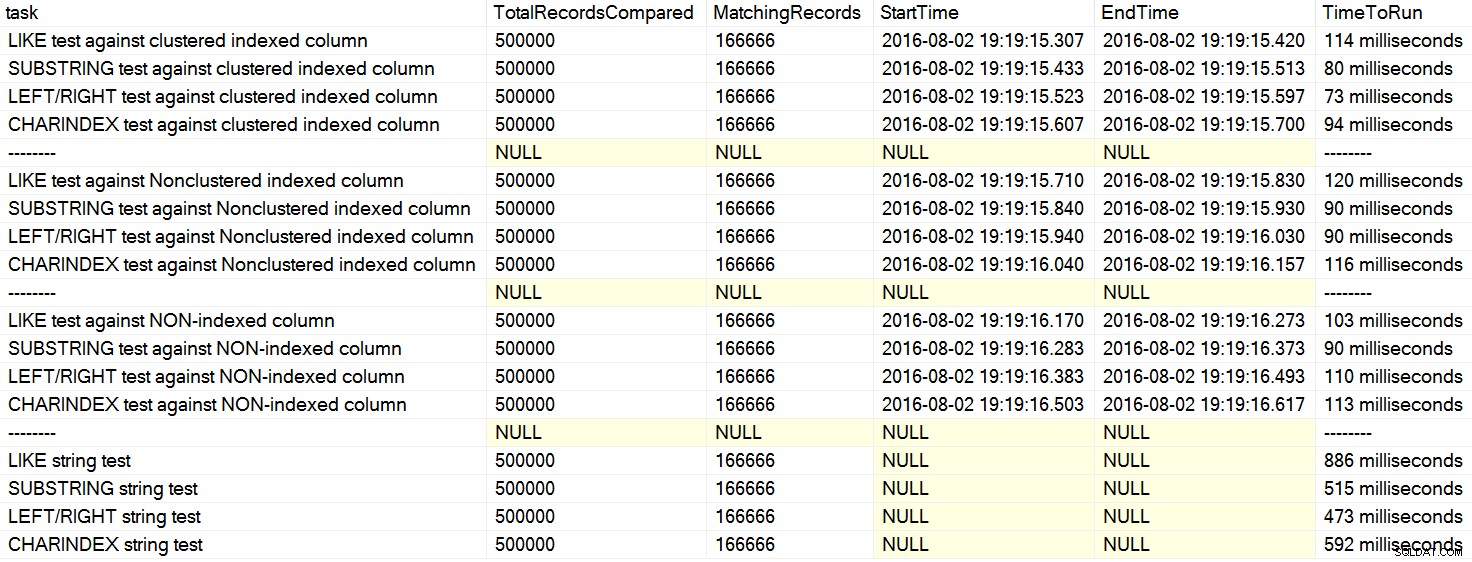 Sulla mia macchina, CHARINDEX era più lento rispetto a SINISTRA/DESTRA/SOTTOSTRINGA.
Sulla mia macchina, CHARINDEX era più lento rispetto a SINISTRA/DESTRA/SOTTOSTRINGA.
I test di David stavano fondamentalmente confrontando queste strutture di query, cercando uno schema di stringhe all'inizio o alla fine di un valore di colonna, in termini di durata grezza:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Solo guardando queste clausole, puoi capire perché CHARINDEX potrebbe essere meno efficiente:effettua più chiamate funzionali aggiuntive che gli altri approcci non devono eseguire. Non sono sicuro del motivo per cui questo approccio ha funzionato meglio sulla macchina di David; forse ha eseguito il codice esattamente come pubblicato e non ha davvero eliminato i buffer tra i test, in modo tale che questi ultimi abbiano beneficiato dei dati memorizzati nella cache.
In teoria, CHARINDEX avrebbe potuto essere espresso in modo più semplice, ad es.:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Ma questo in realtà ha funzionato anche peggio nei miei test casuali.)
E perché questi sono anche OR condizioni, non ne sono sicuro. Realisticamente, la maggior parte delle volte esegui uno dei due tipi di ricerca del modello:inizia con o contiene (è molto meno comune cercare finisce con ). E nella maggior parte di questi casi, l'utente tende a dichiarare in anticipo se desidera iniziare con o contiene , almeno in ogni applicazione in cui sono stato coinvolto nella mia carriera.
Ha senso separarli come tipi separati di query, invece di utilizzare un OR condizionale, poiché inizia con può utilizzare un indice (se ne esiste uno sufficientemente adatto per una ricerca o più magro dell'indice cluster), mentre termina con non può (e O le condizioni tendono a lanciare chiavi all'ottimizzatore in generale). Se posso fidarmi di MI PIACE per utilizzare un indice quando può e per funzionare come o meglio delle altre soluzioni di cui sopra nella maggior parte o in tutti i casi, quindi posso rendere questa logica molto semplice. Una procedura memorizzata può accettare due parametri:il modello cercato e il tipo di ricerca da eseguire (in genere ci sono quattro tipi di corrispondenza di stringhe:inizia con, finisce con, contiene o corrispondenza esatta).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Questo gestisce ogni potenziale caso senza utilizzare SQL dinamico; l'OPTION (RECOMPILE) è lì perché non vorresti che un piano ottimizzato per "finisce con" (che quasi sicuramente dovrà essere scansionato) da riutilizzare per una query "inizia con" o viceversa; assicurerà inoltre che le stime siano corrette ("inizia con S" probabilmente ha una cardinalità molto diversa da "inizia con QX"). Anche se si dispone di uno scenario in cui gli utenti scelgono un tipo di ricerca il 99% delle volte, è possibile utilizzare l'SQL dinamico qui invece di ricompilare, ma in tal caso si sarebbe comunque vulnerabili allo sniffing dei parametri. In molte query di logica condizionale, la ricompilazione e/o l'SQL dinamico completo sono spesso l'approccio più sensato (vedi il mio post su "The Kitchen Sink").
Le prove
Dato che ho recentemente iniziato a guardare il nuovo database di esempio di WideWorldImporters, ho deciso di eseguire i miei test lì. È stato difficile trovare una tabella di dimensioni decenti senza un indice ColumnStore o una tabella della cronologia temporale, ma Sales.Invoices , che ha 70.510 righe, ha un semplice nvarchar(20) colonna denominata CustomerPurchaseOrderNumber che ho deciso di utilizzare per i test. (Perché è nvarchar(20) quando ogni singolo valore è un numero di 5 cifre, non ne ho idea, ma alla corrispondenza dei modelli non importa se i byte sottostanti rappresentano numeri o stringhe.)
| Vendite.Fatture CustomerPurchaseOrderNumber | ||
|---|---|---|
| Modello | # di righe | % della tabella |
| Inizia con "1" | 70.505 | 99,993% |
| Inizia con "2" | 5 | 0,007% |
| Termina con "5" | 6.897 | 9,782% |
| Finisce con "30" | 749 | 1,062% |
Ho dato un'occhiata ai valori nella tabella per trovare più criteri di ricerca che avrebbero prodotto numeri di righe molto diversi, si spera che rivelino qualsiasi comportamento del punto di non ritorno con un determinato approccio. A destra ci sono le query di ricerca su cui sono arrivato.
Volevo dimostrare a me stesso che la procedura di cui sopra era innegabilmente migliore nel complesso per tutte le ricerche possibili rispetto a qualsiasi query che utilizza OR condizionali, indipendentemente dal fatto che utilizzino LIKE , LEFT/RIGHT , SUBSTRING o CHARINDEX . Ho preso le strutture di base delle query di David e le ho inserite nelle procedure memorizzate (con l'avvertenza che non posso davvero testare "contiene" senza il suo input e che dovevo creare il suo OR logica un po' più flessibile per ottenere lo stesso numero di righe), insieme a una versione della mia logica. Ho anche pianificato di testare le procedure con e senza un indice che avrei creato nella colonna di ricerca e in una cache calda e fredda.
Le procedure:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Ho anche creato versioni delle procedure di David fedeli al suo intento originale, supponendo che il requisito sia davvero trovare qualsiasi riga in cui il modello di ricerca si trovi all'inizio *o* alla fine della stringa. L'ho fatto semplicemente in modo da poter confrontare le prestazioni dei diversi approcci, esattamente come li ha scritti lui, per vedere se su questo set di dati i miei risultati corrispondevano ai miei test del suo script originale sul mio sistema. In questo caso non c'era motivo di introdurre una mia versione, poiché corrispondeva semplicemente al suo LIKE % + @pattern OR LIKE @pattern + % variazione.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Con le procedure in atto, potrei generare il codice di test, che spesso è divertente quanto il problema originale. Innanzitutto, una tabella di registrazione:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Quindi il codice che eseguirebbe le operazioni di selezione utilizzando le varie procedure e argomenti:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Risultati
Ho eseguito questi test su una macchina virtuale, con Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), con 4 CPU e 32 GB di RAM. Ho eseguito ogni serie di test 11 volte; per i test della cache a caldo, ho eliminato la prima serie di risultati perché alcuni di questi erano test della cache a freddo.
Ho lottato su come rappresentare graficamente i risultati per mostrare i modelli, principalmente perché semplicemente non c'erano schemi. Quasi ogni metodo era il migliore in uno scenario e il peggiore in un altro. Nelle tabelle seguenti, ho evidenziato la procedura migliore e peggiore per ciascuna colonna e puoi vedere che i risultati sono tutt'altro che conclusivi:
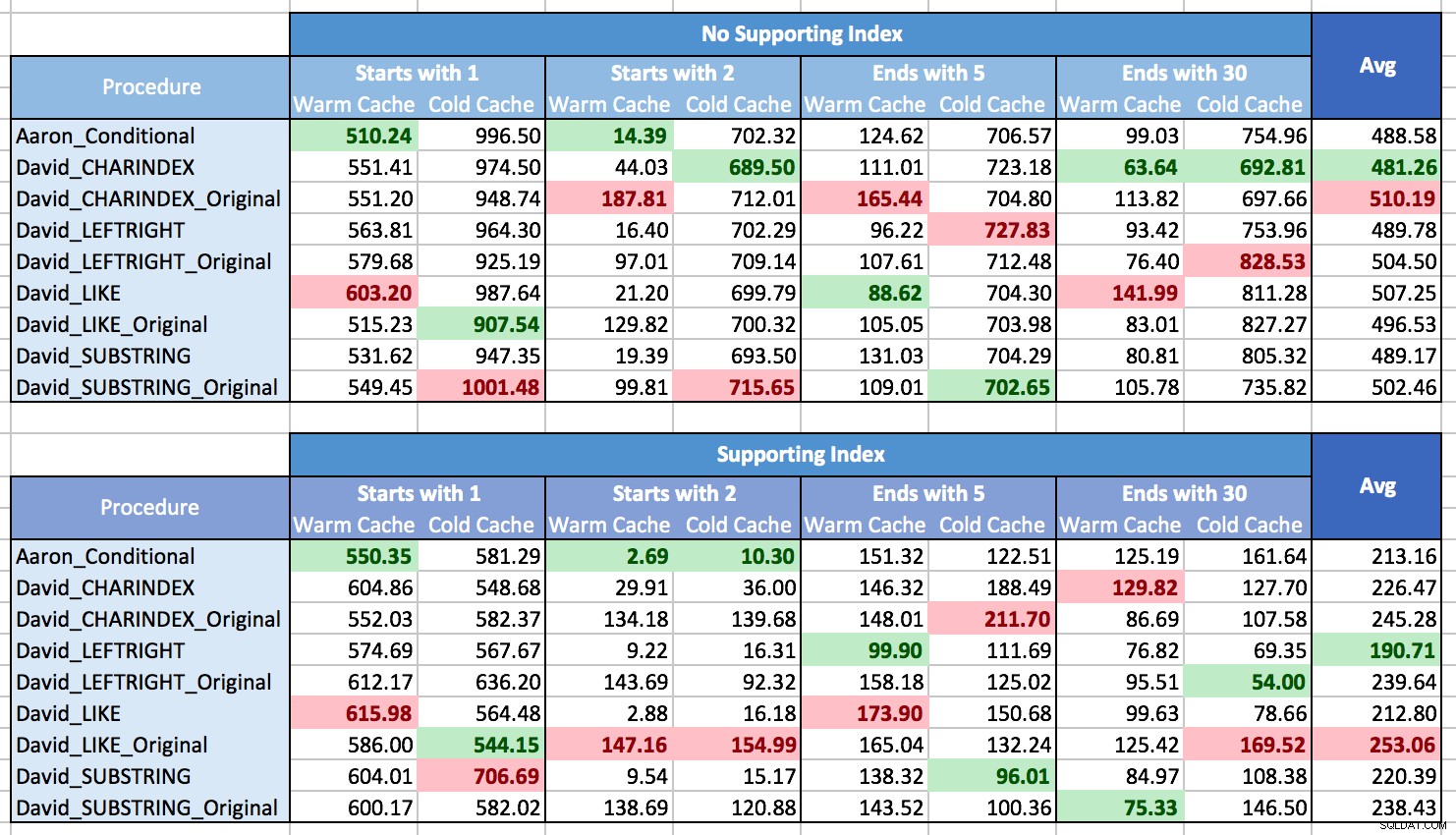 In questi test, a volte CHARINDEX ha vinto ea volte no.
In questi test, a volte CHARINDEX ha vinto ea volte no.
Quello che ho imparato è che, nel complesso, se ti trovi ad affrontare molte situazioni diverse (diversi tipi di pattern matching, con un indice di supporto o meno, i dati non possono essere sempre in memoria), non c'è davvero chiaro vincitore e la gamma di prestazioni in media è piuttosto piccola (in effetti, dal momento che una cache calda non ha sempre aiutato, sospetterei che i risultati siano stati influenzati più dal costo del rendering dei risultati che dal loro recupero). Per i singoli scenari, non fare affidamento sui miei test; esegui tu stesso alcuni benchmark in base all'hardware, alla configurazione, ai dati e ai modelli di utilizzo.
Avvertenze
Alcune cose che non ho considerato per questi test:
- In cluster e non in cluster . Poiché è improbabile che il tuo indice cluster si trovi su una colonna in cui stai eseguendo ricerche di corrispondenza dei modelli rispetto all'inizio o alla fine della stringa e poiché una ricerca sarà sostanzialmente la stessa in entrambi i casi (e le differenze tra le scansioni saranno in gran parte essere funzione della larghezza dell'indice rispetto alla larghezza della tabella), ho testato le prestazioni solo utilizzando un indice non cluster. Se hai scenari specifici in cui questa differenza da sola fa una profonda differenza sulla corrispondenza dei modelli, faccelo sapere.
- Tipi MAX . Se stai cercando stringhe all'interno di
varchar(max)/nvarchar(max), quelli non possono essere indicizzati, quindi, a meno che tu non utilizzi colonne calcolate per rappresentare parti del valore, sarà necessaria una scansione, indipendentemente dal fatto che tu stia cercando inizia con, finisce con o contiene. Non ho testato se l'overhead delle prestazioni è correlato alla dimensione della stringa o se viene introdotto un sovraccarico aggiuntivo semplicemente a causa del tipo.
- Ricerca full-text . Ho giocato con questa funzione qui e là, e posso scriverla, ma se la mia comprensione è corretta, questo potrebbe essere utile solo se stai cercando parole intere senza interruzioni e non sei preoccupato di dove fossero nella stringa trovato. Non sarebbe utile se stessi archiviando paragrafi di testo e volessi trovare tutti quelli che iniziano con "Y", contengono la parola "il" o terminano con un punto interrogativo.
Riepilogo
L'unica affermazione generale che posso fare allontanandomi da questo test è che non ci sono affermazioni generali su quale sia il modo più efficiente per eseguire la corrispondenza di schemi di stringhe. Sebbene io sia prevenuto verso il mio approccio condizionale per flessibilità e manutenibilità, non è stato il vincitore delle prestazioni in tutti gli scenari. Per quanto mi riguarda, a meno che non stia incontrando un collo di bottiglia delle prestazioni e non stia perseguendo tutte le strade, continuerò a utilizzare il mio approccio per coerenza. Come ho suggerito sopra, se hai uno scenario molto ristretto e sei molto sensibile a piccole differenze di durata, ti consigliamo di eseguire i tuoi test per determinare quale metodo è costantemente il migliore per te.