Sono lontani i giorni in cui un database veniva distribuito come un singolo nodo o istanza:un potente server autonomo a cui era assegnato il compito di gestire tutte le richieste al database. Il ridimensionamento verticale era la strada da percorrere:sostituire il server con un altro, ancora più potente. Durante questi periodi, non c'era bisogno di essere disturbati dalle prestazioni della rete. Finché sono arrivate le richieste, è andato tutto bene.
Ma al giorno d'oggi, i database sono costruiti come cluster con nodi interconnessi su una rete. Non è sempre una rete locale veloce. Con le aziende che raggiungono una scala globale, l'infrastruttura del database deve anche estendersi in tutto il mondo, rimanere vicino ai clienti e ridurre la latenza. Viene fornito con ulteriori sfide che dobbiamo affrontare durante la progettazione di un ambiente di database a disponibilità elevata. In questo post del blog esamineremo i problemi di rete che potresti incontrare e forniremo alcuni suggerimenti su come affrontarli.
Due opzioni principali per MySQL o MariaDB HA
Abbiamo trattato questo particolare argomento in modo abbastanza ampio in uno dei whitepaper, ma diamo un'occhiata ai due modi principali per creare un'elevata disponibilità per MySQL e MariaDB.
Galera Cluster
Galera Cluster è una tecnologia cluster praticamente sincrona per MySQL. Consente di creare configurazioni multi-scrittore che possono estendersi in tutto il mondo. Galera prospera in ambienti a bassa latenza, ma può anche essere configurato per funzionare con lunghe connessioni WAN. Galera ha un meccanismo di quorum integrato che assicura che i dati non vengano compromessi in caso di partizionamento di rete di alcuni nodi.
Replica MySQL
MySQL Replication può essere asincrono o semi-sincrono. Entrambi sono progettati per creare cluster di replica su larga scala. Come in qualsiasi altra configurazione di replica master-slave o primaria-secondaria, può esserci un solo writer, il master. Altri nodi, slave, vengono utilizzati per scopi di failover in quanto contengono la copia del set di dati dal maser. Gli slave possono essere utilizzati anche per leggere i dati e scaricare parte del carico di lavoro dal master.
Entrambe le soluzioni hanno i propri limiti e caratteristiche, entrambe soffrono di problemi diversi. Entrambi possono essere interessati da connessioni di rete instabili. Diamo un'occhiata a queste limitazioni e a come possiamo progettare l'ambiente per ridurre al minimo l'impatto di un'infrastruttura di rete instabile.
Galera Cluster - Problemi di rete
Per prima cosa, diamo un'occhiata a Galera Cluster. Come abbiamo discusso, funziona meglio in un ambiente a bassa latenza. Uno dei principali problemi relativi alla latenza in Galera è il modo in cui Galera gestisce le scritture. Non entreremo in tutti i dettagli in questo blog, ma leggeremo ulteriormente nel nostro tutorial su Galera Cluster per MySQL. La linea di fondo è che, a causa del processo di certificazione per le scritture, in cui tutti i nodi del cluster devono concordare se la scrittura può essere applicata o meno, le prestazioni di scrittura per singola riga sono strettamente limitate dal tempo di andata e ritorno della rete tra il writer nodo e il nodo più lontano. Finché la latenza è accettabile e finché non ci sono troppi hot spot nei dati, le configurazioni WAN potrebbero funzionare correttamente. Il problema inizia quando la latenza di rete aumenta di tanto in tanto. Le scritture impiegheranno quindi 3 o 4 volte più tempo del solito e, di conseguenza, i database potrebbero iniziare a essere sovraccaricati con scritture di lunga durata.
Una delle grandi caratteristiche di Galera Cluster è la sua capacità di rilevare lo stato del cluster e reagire al partizionamento della rete. Se un nodo del cluster non può essere raggiunto, verrà rimosso dal cluster e non sarà in grado di eseguire scritture. Questo è fondamentale per mantenere l'integrità dei dati durante il periodo in cui il cluster è diviso:solo la maggior parte del cluster accetterà le scritture. La minoranza si lamenterà. Per gestire questo, Galera introduce una vasta gamma di controlli e timeout configurabili per evitare falsi allarmi su problemi di rete molto transitori. Sfortunatamente, se la rete è inaffidabile, Galera Cluster non sarà in grado di funzionare correttamente - i nodi inizieranno a lasciare il cluster, si uniranno ad esso in un secondo momento. Sarà particolarmente problematico quando avremo Galera Cluster che si estende su WAN:parti separate del cluster potrebbero scomparire casualmente se la rete di interconnessione non funziona correttamente.
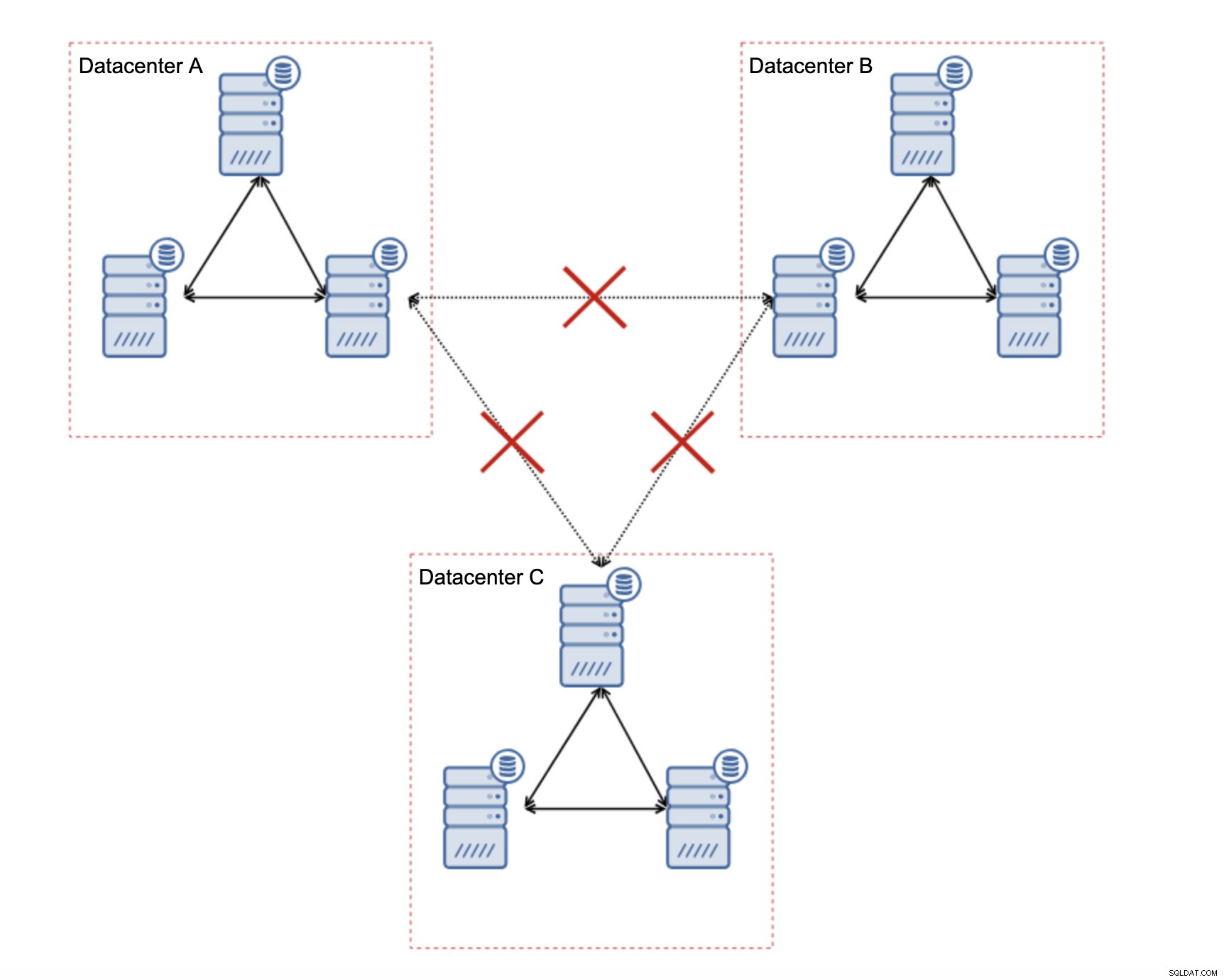
Come progettare un cluster Galera per una rete instabile?
Per prima cosa, se hai problemi di rete all'interno del singolo datacenter, non c'è molto che puoi fare a meno che tu non sia in grado di risolverli in qualche modo. Una rete locale inaffidabile non è una soluzione per Galera Cluster, devi riconsiderare l'utilizzo di qualche altra soluzione (anche se, a dire il vero, una rete inaffidabile sarà sempre un problema). D'altra parte, se i problemi riguardano solo le connessioni WAN (e questo è uno dei casi più tipici), potrebbe essere possibile sostituire i collegamenti WAN Galera con la normale replica asincrona (se l'ottimizzazione WAN Galera non ha aiutato).
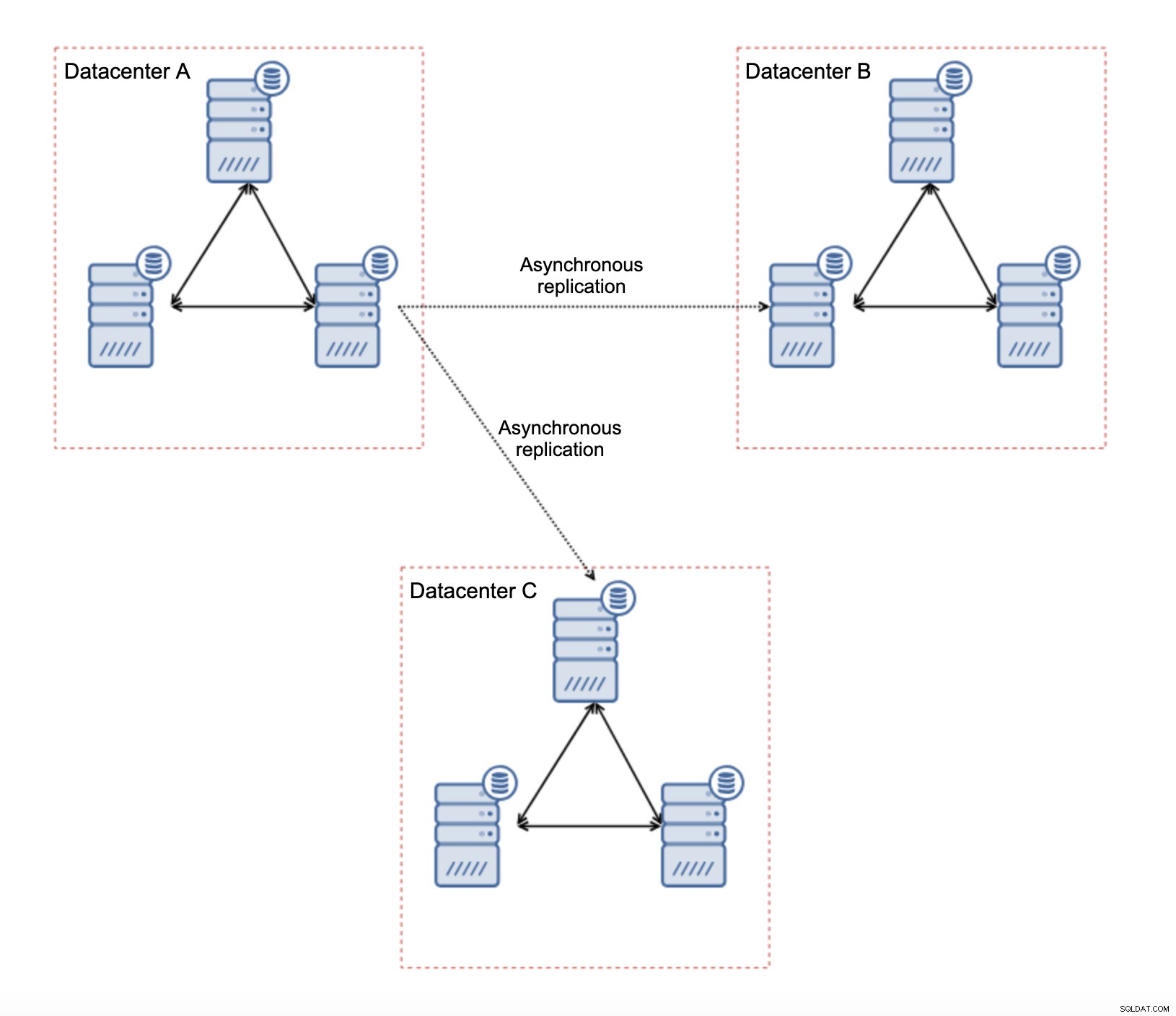
Ci sono diverse limitazioni intrinseche in questa configurazione:il problema principale è che le scritture avvenivano localmente. Ora, tutte le scritture dovranno dirigersi al datacenter "master" (DC A nel nostro caso). Questo non è così male come sembra. Tieni presente che in un ambiente all-Galera, le scritture saranno rallentate dalla latenza tra nodi situati in data center diversi. Anche le scritture locali saranno interessate. Sarà più o meno lo stesso rallentamento della configurazione asincrona in cui invii le scritture attraverso la WAN al data center "master".
L'uso della replica asincrona comporta tutti i problemi tipici della replica asincrona. Il ritardo di replica potrebbe diventare un problema:non che Galera sarebbe più performante, è solo che Galera rallenterebbe il traffico tramite il controllo del flusso mentre la replica non ha alcun meccanismo per limitare il traffico sul master.
Un altro problema è il failover:se il nodo Galera "master" (quello che funge da master per gli slave in altri datacenter) dovesse fallire, è necessario creare un meccanismo per ricollegare gli slave a un altro nodo master funzionante. Potrebbe essere una sorta di script, è anche possibile provare qualcosa con VIP in cui il cluster Galera "slave" disattiva l'IP virtuale che è sempre assegnato al nodo Galera vivo nel cluster "master".
Il vantaggio principale di tale configurazione è che rimuoviamo il collegamento WAN Galera, il che significa che il nostro cluster "master" non sarà rallentato dal fatto che alcuni nodi sono separati geograficamente. Come accennato, perdiamo la capacità di scrivere in tutti i data center, ma la scrittura in termini di latenza sulla WAN equivale a scrivere localmente sul cluster Galera che si estende su tutta la WAN. Di conseguenza, la latenza complessiva dovrebbe migliorare. La replica asincrona è anche meno vulnerabile alle reti instabili. Nel peggiore dei casi, il collegamento di replica si interromperà e verrà ricreato quando le reti convergeranno.
Come progettare la replica MySQL per una rete instabile?
Nella sezione precedente, abbiamo trattato il cluster Galera e una soluzione consisteva nell'usare la replica asincrona. Come appare in una semplice configurazione di replica asincrona? Diamo un'occhiata a come una rete instabile può causare le maggiori interruzioni nella configurazione della replica.
Prima di tutto, la latenza, uno dei principali punti deboli di Galera Cluster. In caso di replica, è quasi un non problema. A meno che non si utilizzi la replica semisincrona, in tal caso, una maggiore latenza rallenterà le scritture. Nella replica asincrona, la latenza non ha alcun impatto sulle prestazioni di scrittura. Tuttavia, potrebbe avere un certo impatto sul ritardo di replica. Non è niente di così significativo come lo era per Galera, ma potresti aspettarti più picchi di ritardo e prestazioni di replica complessive meno stabili se la rete tra i nodi soffre di latenza elevata. Ciò è dovuto principalmente al fatto che il master può anche servire diverse scritture prima che il trasferimento dei dati allo slave possa essere avviato su una rete ad alta latenza.
L'instabilità della rete può sicuramente influire sui collegamenti di replica ma, ancora una volta, non è così critica. Gli slave MySQL tenteranno di riconnettersi ai loro master e la replica avrà inizio.
Il problema principale con la replica di MySQL è in realtà qualcosa che Galera Cluster risolve internamente:il partizionamento di rete. Parliamo del partizionamento della rete come della condizione in cui i segmenti della rete sono separati l'uno dall'altro. La replica di MySQL utilizza un singolo nodo di scrittura:il master. Non importa come progetti il tuo ambiente, devi inviare le tue scritture al master. Se il master non è disponibile (per qualsiasi motivo), l'applicazione non può svolgere il suo lavoro a meno che non venga eseguita in una sorta di modalità di sola lettura. Pertanto è necessario scegliere il nuovo master il prima possibile. È qui che si presentano i problemi.
Innanzitutto, come dire quale host è un master e quale no. Uno dei metodi usuali consiste nell'usare la variabile “read_only” per distinguere gli slave dal master. Se il nodo ha read_only abilitato (imposta read_only=1), è uno slave (poiché gli slave non dovrebbero gestire alcuna scrittura diretta). Se il nodo ha read_only disabilitato (imposta read_only=0), è un master. Per rendere le cose più sicure, un approccio comune è impostare read_only=1 nella configurazione di MySQL:in caso di riavvio, è più sicuro se il nodo si presenta come slave. Tale "linguaggio" può essere compreso da proxy come ProxySQL o MaxScale.
Diamo un'occhiata a un esempio.
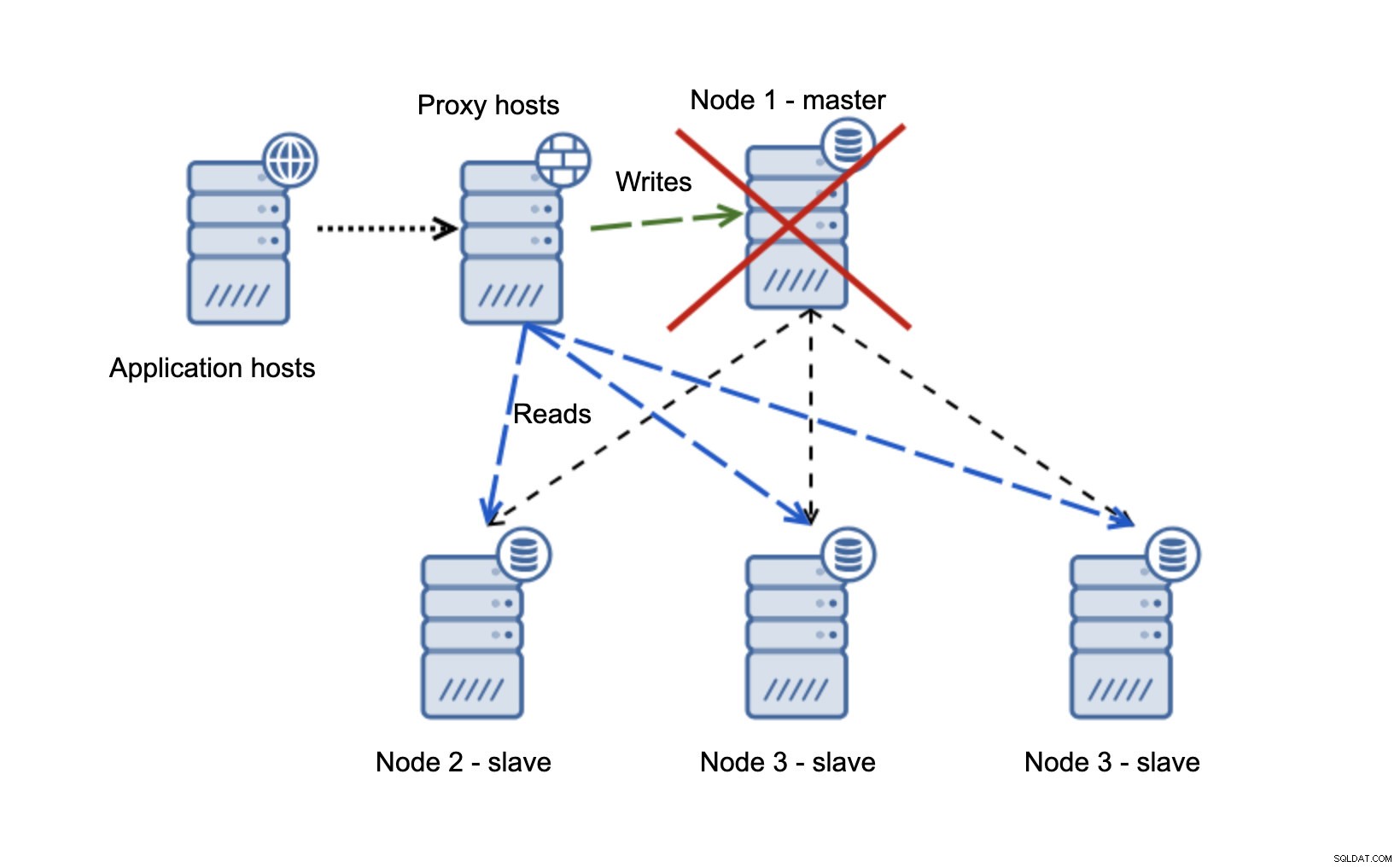
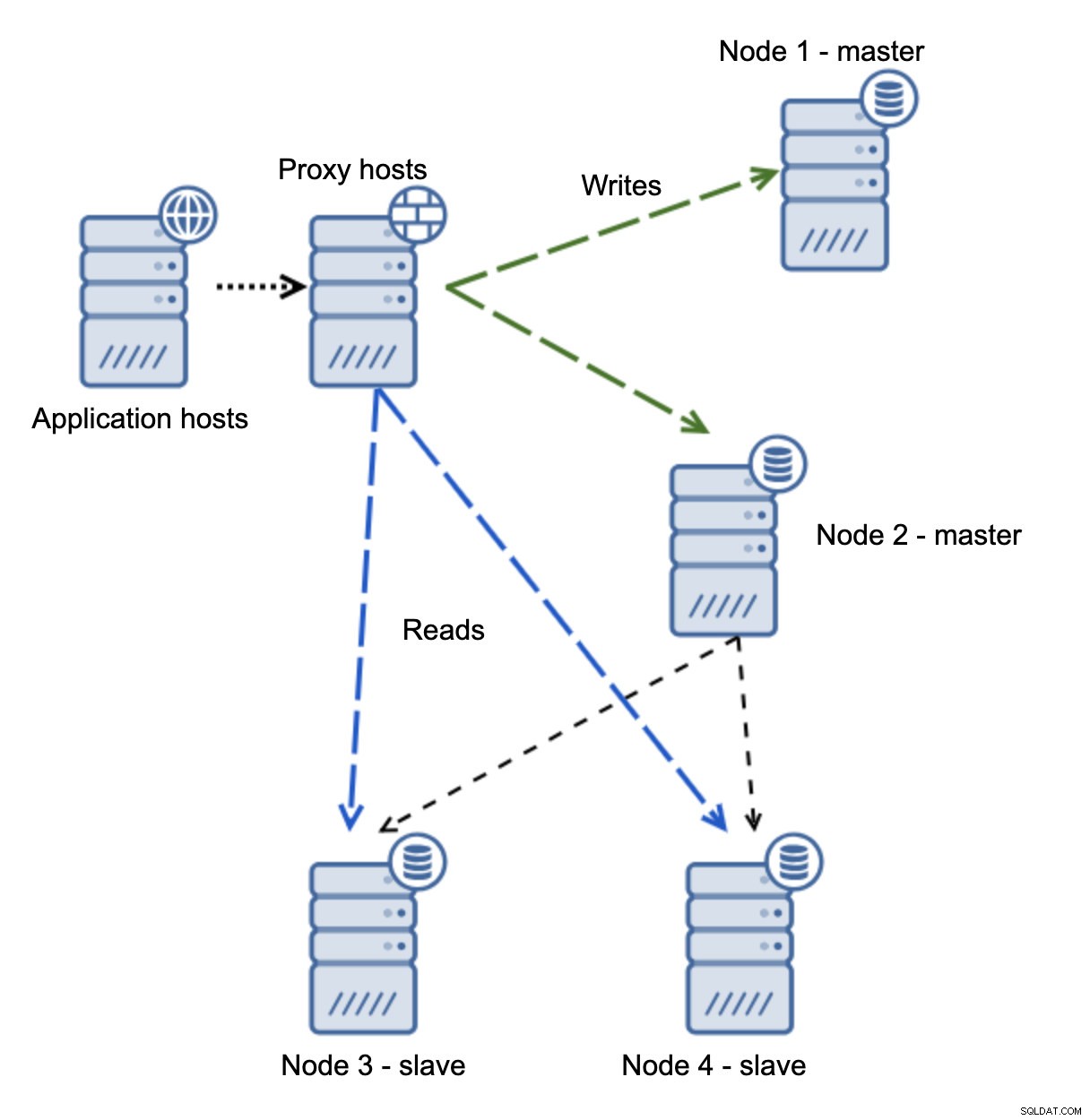
Abbiamo host di applicazioni che si connettono al livello proxy. I proxy eseguono la suddivisione in lettura/scrittura inviando SELECT agli slave e scrivendo al master. Se il master è inattivo, viene eseguito il failover, il nuovo master viene promosso, il livello proxy lo rileva e inizia a inviare le scritture a un altro nodo.
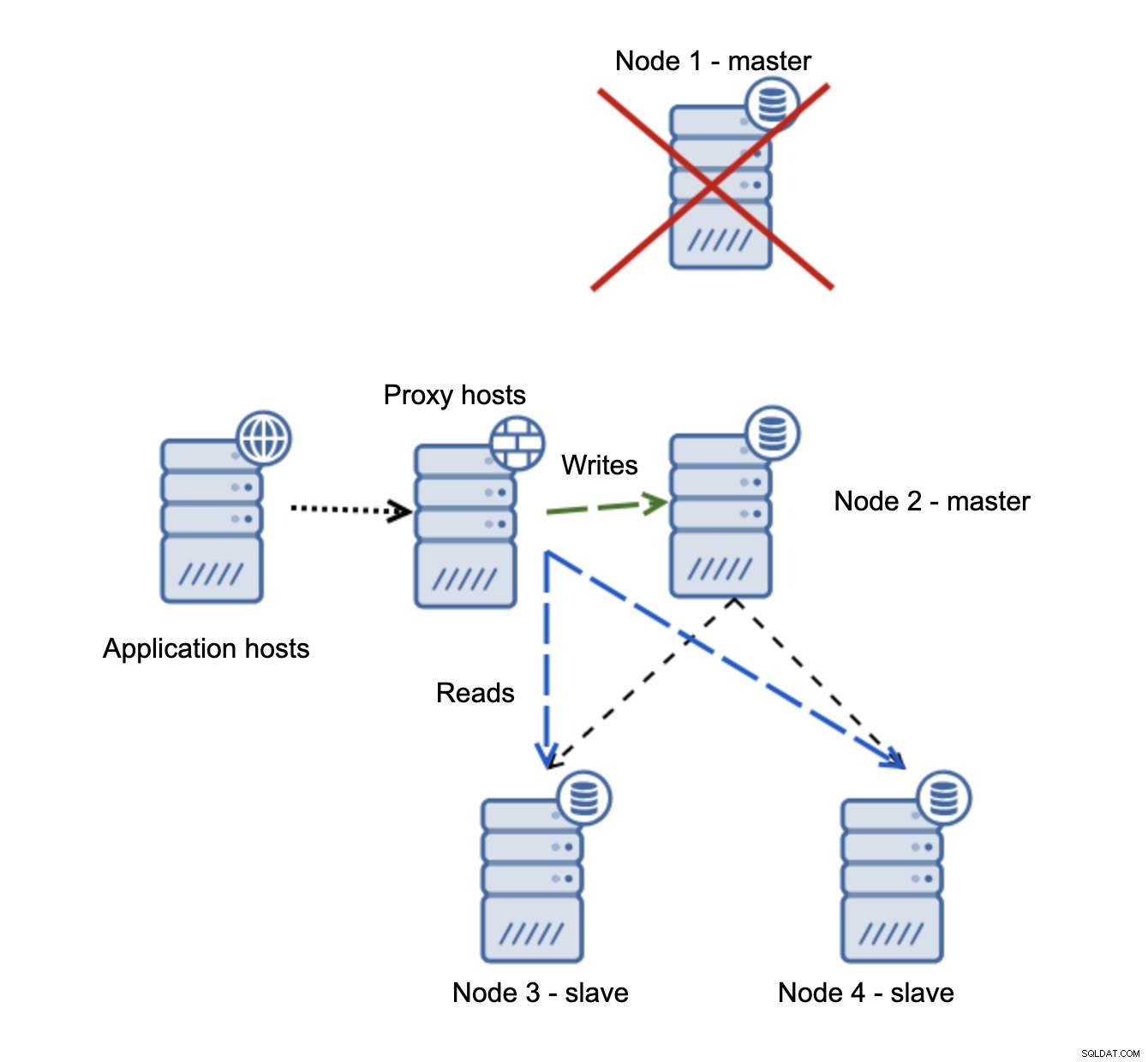
Se node1 si riavvia, verrà visualizzato read_only=1 e verrà rilevato come slave. Non è l'ideale in quanto non si replica ma è accettabile. Idealmente, il vecchio master non dovrebbe presentarsi affatto fino a quando non viene ricostruito e asservito al nuovo master.
Una situazione molto più problematica è se dobbiamo occuparci del partizionamento della rete. Consideriamo la stessa configurazione:livello applicazione, livello proxy e database.
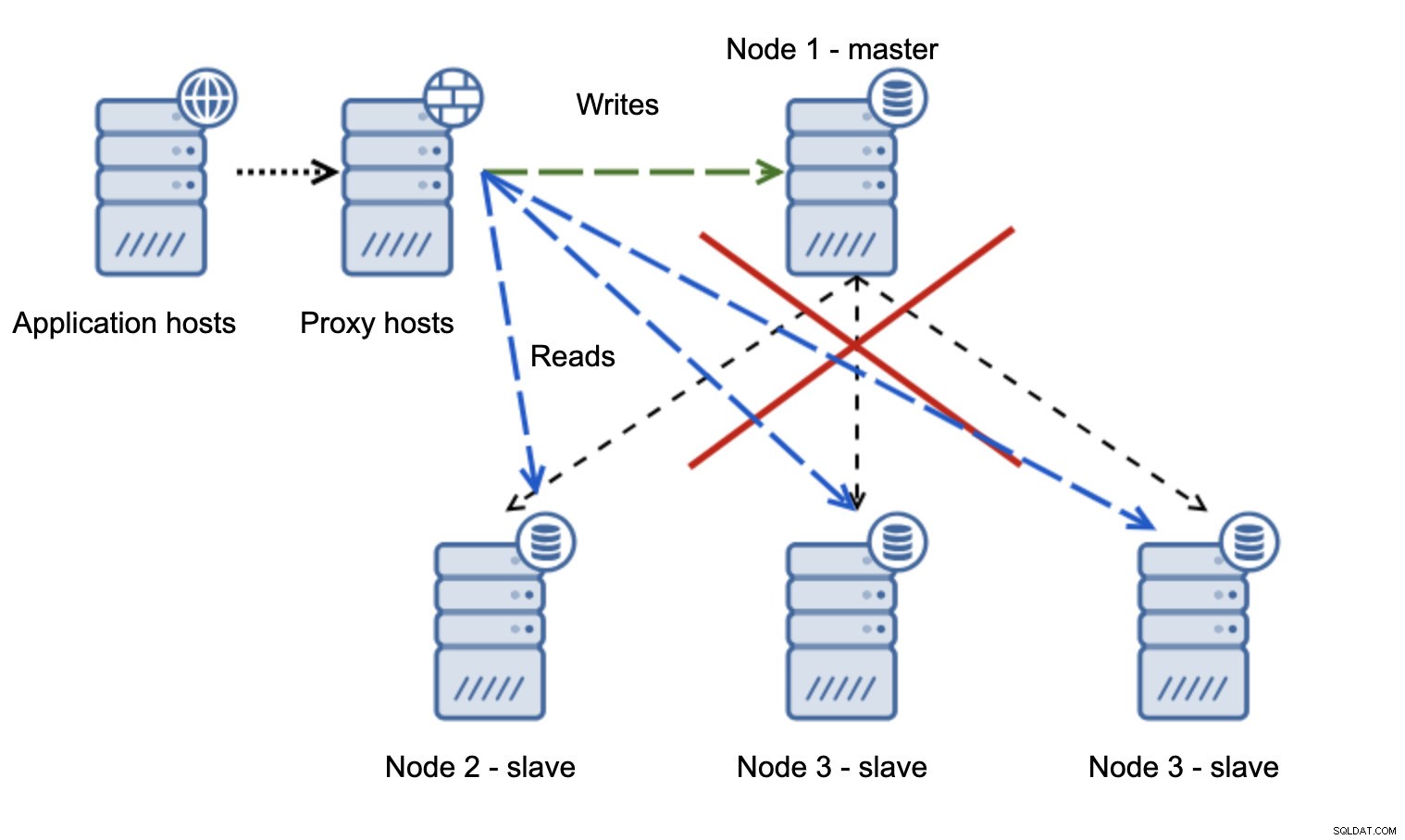
Quando la rete rende il master non raggiungibile, l'applicazione non è utilizzabile poiché nessuna scrittura arriva a destinazione. Il nuovo master viene promosso, le scritture vengono reindirizzate ad esso. Cosa accadrà quindi se i problemi di rete cessano e il vecchio master diventa raggiungibile? Non è stato interrotto, quindi sta ancora utilizzando read_only=0:
Ora sei finito in un cervello diviso, quando le scritture erano dirette a due nodi. Questa situazione è piuttosto grave in quanto l'unione di set di dati divergenti potrebbe richiedere del tempo ed è un processo piuttosto complesso.
Cosa si può fare per evitare questo problema? Non esiste un proiettile d'argento, ma è possibile intraprendere alcune azioni per ridurre al minimo la probabilità che si verifichi una divisione del cervello.
Prima di tutto, puoi essere più intelligente nel rilevare lo stato del master. Come lo vedono gli schiavi? Possono replicare da esso? Forse alcuni degli slave possono ancora connettersi al master, il che significa che il master è attivo e funzionante o, almeno, rendendo possibile l'arresto se necessario. E il livello proxy? Tutti i nodi proxy vedono il master come non disponibile? Se alcuni possono ancora connettersi, allora puoi provare a utilizzare quei nodi per entrare nel master e fermarlo prima del failover?
Il software di gestione del failover può anche essere più intelligente nel rilevare lo stato della rete. Forse utilizza RAFT o qualche altro protocollo di clustering per creare un cluster quorum-aware. Se un software di gestione del failover è in grado di rilevare il cervello diviso, può anche eseguire alcune azioni basate su questo, ad esempio, impostare tutti i nodi nel segmento partizionato in sola lettura assicurandosi che il vecchio master non venga visualizzato come scrivibile quando le reti convergono.
Puoi anche includere strumenti come Consul o Etcd per memorizzare lo stato del cluster. Il livello proxy può essere configurato per utilizzare i dati di Consul, non lo stato della variabile read_only. Spetterà quindi al software di gestione del failover apportare le modifiche necessarie in Consul in modo che tutti i proxy inviino il traffico a un nuovo master corretto.
Alcuni di questi suggerimenti possono anche essere combinati insieme per rendere il rilevamento dei guasti ancora più affidabile. Tutto sommato, è possibile ridurre al minimo le possibilità che il cluster di replica soffra di reti inaffidabili.
Come puoi vedere, non importa se stiamo parlando di Galera o MySQL Replication, le reti instabili possono diventare un problema serio. D'altra parte, se progetti l'ambiente correttamente, puoi comunque farlo funzionare. Ci auguriamo che questo post sul blog ti aiuti a creare ambienti che funzionino in modo stabile anche se le reti non lo sono.