I database di serie temporali, come suggerisce il nome, sono progettati per archiviare dati che cambiano nel tempo. Può trattarsi di qualsiasi tipo di dato che è stato raccolto nel tempo. Potrebbero essere metriche raccolte da alcuni sistemi e, in realtà, tutti i sistemi di trend sono esempi di dati di serie temporali.
Abbiamo diversi tipi di database di serie temporali, quali dovremmo usare?
In questo blog vedremo quali sono le principali differenze tra due delle opzioni principali, TimescaleDB e InfluxDB.
Afflusso DB
InfluxDB è stato creato da InfluxData. È un database di serie temporali NoSQL personalizzato, open source, scritto in Go. Il datastore fornisce un linguaggio simile a SQL per interrogare i dati, chiamato InfluxQL, che semplifica l'integrazione degli sviluppatori nelle loro applicazioni. Ha anche un nuovo linguaggio di query personalizzato chiamato Flux, questo linguaggio può semplificare alcune attività, ma c'è sempre una curva di apprendimento quando si adotta un linguaggio di query personalizzato.
Questo è un esempio di query Flux:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()In questo database, ogni misurazione ha un timestamp e un insieme di tag e di campi associati. Il campo rappresenta i valori di lettura delle misurazioni effettive, mentre il tag rappresenta i metadati per descrivere le misurazioni. I tipi di dati del campo sono limitati a float, int, stringhe e booleani e non possono essere modificati senza riscrivere i dati. I valori dei tag sono indicizzati. Sono rappresentati come stringhe e non possono essere aggiornati.
InfluxDB è abbastanza facile da iniziare, poiché non devi preoccuparti di creare schemi o indici. Tuttavia, è piuttosto rigido e limitato, senza possibilità di creare indici aggiuntivi, indici su campi continui, aggiornare i metadati a posteriori, imporre la convalida dei dati, ecc.
Non è senza schema. Esiste uno schema sottostante che viene creato automaticamente dai dati di input.
InfluxDB deve implementare da zero diversi strumenti per la tolleranza agli errori, come replica, alta disponibilità e backup/ripristino, ed è responsabile della sua affidabilità su disco. Ci limitiamo a utilizzare questi strumenti e molte di queste funzionalità, come HA, sono disponibili solo nella versione aziendale.
Lo strumento di backup InfluxDB può eseguire un backup completo o incrementale e può essere utilizzato per il ripristino temporizzato.
InfluxDB offre anche una compressione su disco significativamente migliore rispetto a PostgreSQL e TimescaleDB.
TimescaleDB
TimescaleDB è un database di serie temporali open source ottimizzato per l'acquisizione rapida e query complesse che supporta SQL completo. È basato su PostgreSQL e offre il meglio dei mondi NoSQL e relazionali per i dati delle serie temporali.
Questo è un esempio di query TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, come estensione PostgreSQL, è un database relazionale. Ciò consente di avere una breve curva di apprendimento per i nuovi utenti e di ereditare strumenti come pg_dump o pg_backup per il backup e strumenti ad alta disponibilità, il che è un vantaggio rispetto ad altri database di serie temporali. Supporta anche la replica in streaming come metodo principale di replica, che può essere utilizzato in una configurazione ad alta disponibilità. In termini di failover e backup, puoi automatizzare questo processo utilizzando un sistema esterno come ClusterControl.
In TimescaleDB, ogni misurazione di serie temporali viene registrata nella propria riga, con un campo temporale seguito da un numero qualsiasi di altri campi, che possono essere float, int, stringhe, booleani, array, BLOB JSON, dimensioni geospaziali, data/ora/ timestamp, valute, dati binari e altro.
Puoi creare indici su qualsiasi campo (indici standard) o su più campi (indici compositi) o su espressioni come funzioni o persino limitare un indice a un sottoinsieme di righe (indice parziale). Ognuno di questi campi può essere utilizzato come chiave esterna per le tabelle secondarie, che possono quindi archiviare metadati aggiuntivi.
In questo modo, devi scegliere uno schema e decidere di quali indici avrai bisogno per il tuo sistema.
Prestazioni
Se parliamo di prestazioni, possiamo controllare l'ottimo blog di confronto di TimescaleDB. Lì hai un confronto dettagliato per le prestazioni tra entrambi i database con grafici e metriche. Vediamo alcune delle informazioni più importanti di questo blog.
Inserti
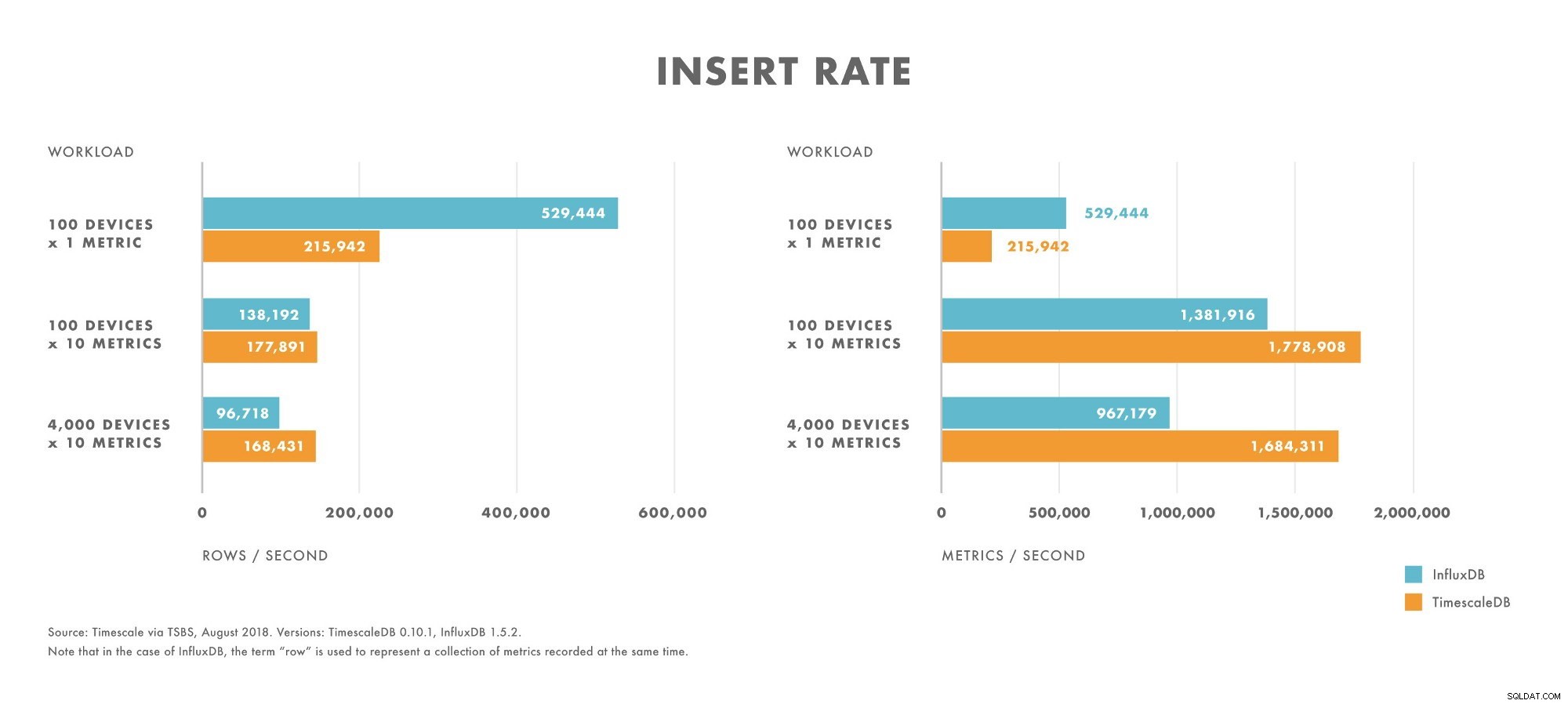
- Per carichi di lavoro con cardinalità molto bassa (ad es. 100 dispositivi), InfluxDB supera TimescaleDB.
- Con l'aumento della cardinalità, le prestazioni di inserimento di InfluxDB diminuiscono più rapidamente rispetto a TimescaleDB.
- Per i carichi di lavoro con cardinalità da moderata ad alta (ad es. 100 dispositivi che inviano 10 metriche), TimescaleDB supera InfluxDB.

Lettura latenza
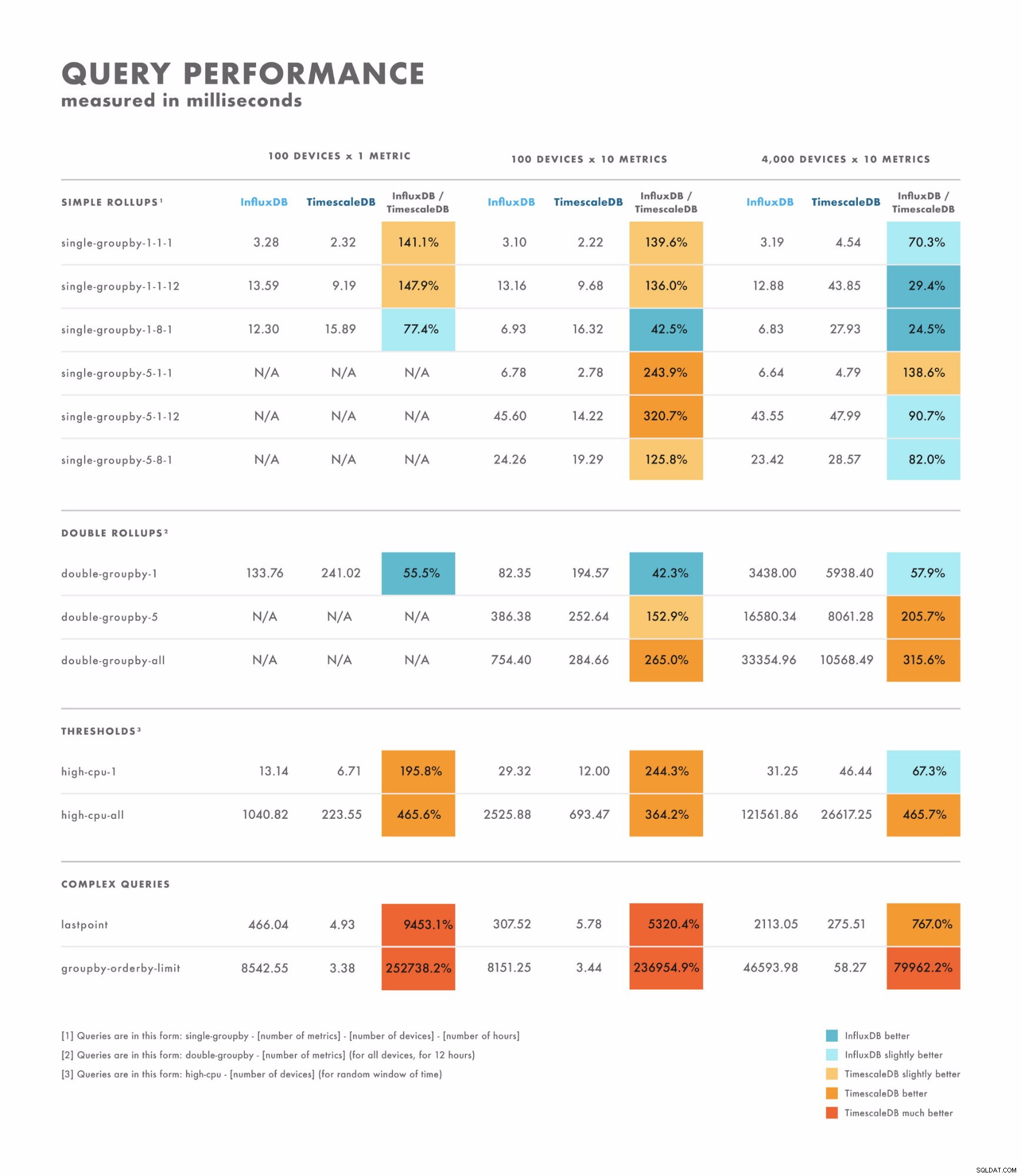
- Per le query semplici, i risultati variano un po':ce ne sono alcuni in cui un database è chiaramente migliore dell'altro, mentre altri dipendono dalla cardinalità del tuo set di dati. La differenza qui è spesso nell'intervallo di millisecondi da una cifra a due cifre.
- Per le query complesse, TimescaleDB supera di gran lunga InfluxDB e supporta una gamma più ampia di tipi di query. La differenza qui è spesso nell'intervallo da secondi a decine di secondi.
- Con questo in mente, il modo migliore per testare correttamente è eseguire un benchmark utilizzando le query che prevedi di eseguire.
Problemi di stabilità
- InfluxDB presenta problemi di stabilità e prestazioni con cardinalità elevate (oltre 100.000).
Conclusione
Se i tuoi dati si adattano al modello di dati InfluxDB e non prevedi di cambiare in futuro, dovresti prendere in considerazione l'utilizzo di InfluxDB poiché questo modello è più facile da iniziare e, come la maggior parte dei database che utilizzano un approccio orientato alle colonne, offre una migliore compressione su disco rispetto a PostgreSQL e TimescaleDB.
Tuttavia, il modello relazionale è più versatile e offre più funzionalità, flessibilità e controllo rispetto al modello InfluxDB. Ciò è particolarmente importante con l'evoluzione dell'applicazione. E quando pianifichi il tuo sistema dovresti considerare sia le sue esigenze attuali che future.
In questo blog, potremmo vedere un breve confronto tra TimescaleDB e InfluxDB, e potremmo dire che TimescaleDB come estensione PostgreSQL, sembra piuttosto maturo e ricco di funzionalità poiché eredita molto da PostgreSQL. Ma puoi prendere la tua decisione in base ai pro e ai contro menzionati in precedenza in questo blog e assicurarti di confrontare il tuo carico di lavoro. Buona fortuna in questo nuovo mondo di database di serie temporali!