Nel mio precedente articolo ho dato il via a una nuova serie sui chiavistelli spiegando cosa sono, perché sono necessari e la meccanica di come funzionano, e ti consiglio vivamente di leggere quell'articolo prima di questo. In questo articolo parlerò del latch FGCB_ADD_REMOVE e mostrerò come può essere un collo di bottiglia.
Cos'è il fermo FGCB_ADD_REMOVE?
La maggior parte dei nomi delle classi latch sono legati direttamente alla struttura di dati che proteggono. Il latch FGCB_ADD_REMOVE protegge una struttura di dati denominata FGCB o File Group Control Block e sarà presente uno di questi latch per ogni filegroup online di ogni database online in un'istanza di SQL Server. Ogni volta che un file in un filegroup viene aggiunto, eliminato, cresciuto o ridotto, il latch deve essere acquisito in modalità EX e, quando si calcola il file successivo da cui allocare, il latch deve essere acquisito in modalità SH per impedire qualsiasi modifica al filegroup. (Ricorda che le allocazioni di extent per un filegroup vengono eseguite su base round robin attraverso i file nel filegroup e tengono anche conto del riempimento proporzionale , che spiego qui.)
In che modo il fermo diventa un collo di bottiglia?
Lo scenario più comune in cui questo latch diventa un collo di bottiglia è il seguente:
- Esiste un database a file singolo, quindi tutte le allocazioni devono provenire da quel file di dati
- L'impostazione di aumento automatico per il file è molto piccola (ricorda, prima di SQL Server 2016, l'impostazione di aumento automatico predefinita per i file di dati era 1 MB!)
- Esistono molte operazioni simultanee che richiedono l'allocazione di spazio (ad es. un carico di lavoro di inserimento costante da molte connessioni client)
In questo caso, anche se è presente un solo file, un thread che richiede un'allocazione deve comunque acquisire il latch FGCB_ADD_REMOVE in modalità SH. Proverà quindi ad allocare dal singolo file di dati, si renderà conto che non c'è spazio e quindi acquisirà il latch in modalità EX in modo che possa poi far crescere il file.
Immaginiamo che otto thread in esecuzione su otto schedulatori separati cerchino tutti di eseguire l'allocazione contemporaneamente e tutti si rendano conto che non c'è spazio nel file, quindi hanno bisogno di espanderlo. Ciascuno tenterà di acquisire il fermo in modalità EX. Solo uno di loro potrà acquisirlo e procederà alla crescita del file e gli altri dovranno attendere, con un tipo di attesa di LATCH_EX e una descrizione della risorsa di FGCB_ADD_REMOVE più l'indirizzo di memoria del latch.
I sette thread in attesa si trovano nella coda di attesa FIFO (first-in-first-out) del latch. Quando il thread che esegue la crescita del file è terminato, rilascia il latch e lo concede al primo thread in attesa. Questo nuovo proprietario del latch va a far crescere il file e scopre che è già stato cresciuto e non c'è niente da fare. Quindi rilascia il fermo e lo concede al prossimo thread in attesa. E così via.
I sette thread in attesa hanno tutti aspettato il latch in modalità EX ma hanno finito per non fare nulla una volta che gli è stato concesso il latch, quindi tutti e sette i thread hanno essenzialmente sprecato il tempo trascorso, con la quantità di tempo sprecato che aumentava leggermente per ogni thread più in basso la coda di attesa FIFO era.
Mostra il collo di bottiglia
Ora ti mostrerò lo scenario esatto sopra, usando eventi estesi. Ho creato un database a file singolo con una piccola impostazione di crescita automatica e centinaia di connessioni simultanee inserendo semplicemente i dati in una tabella.
Posso usare la seguente sessione di eventi estesa per vedere cosa sta succedendo:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO La sessione tiene traccia di quando un thread entra nella coda di attesa del latch, quando lascia la coda (ovvero quando gli viene concesso il latch) e quando si verifica una crescita del file di dati. L'uso del monitoraggio della causalità significa che possiamo vedere una sequenza temporale delle azioni di ciascun thread.
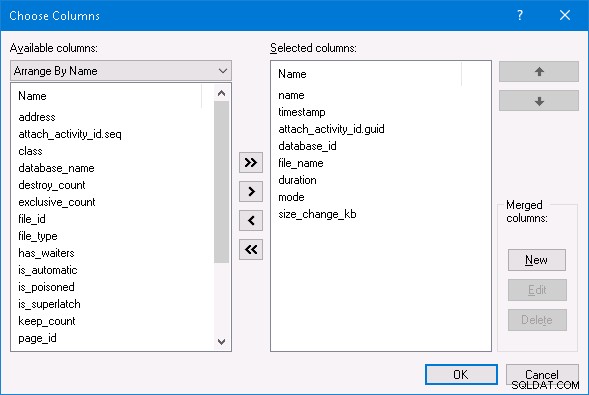
Utilizzando SQL Server Management Studio, posso selezionare l'opzione Guarda dati in tempo reale per la sessione di eventi estesa e vedere tutta l'attività di eventi estesi. Se vuoi fare lo stesso, nella finestra Dati in tempo reale, fai clic con il pulsante destro del mouse su uno dei nomi delle colonne in alto e cambia le colonne selezionate come di seguito:
Ho lasciato eseguire il carico di lavoro per alcuni minuti per raggiungere uno stato stazionario e poi ho visto un perfetto esempio dello scenario che ho descritto sopra:
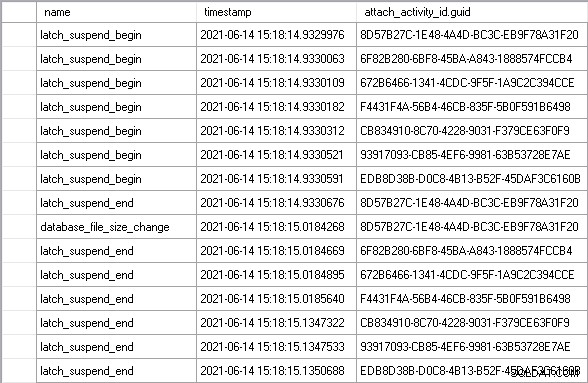
Utilizzando attach_activity_id.guid valori per identificare thread diversi, possiamo vedere che sette thread iniziano ad attendere il latch entro 61,5 microsecondi. Il thread con il valore GUID che inizia con 8D57 acquisisce il latch in modalità EX (il latch_suspend_end event) e quindi fa crescere immediatamente il file (il database_file_size_change evento). Il thread 8D57 rilascia quindi il latch e lo concede in modalità EX al thread 6F82, che ha atteso 85 millisecondi. Non ha nulla a che fare, quindi concede il latch al thread 672B. E così via, finché al thread EDB8 non viene concesso il latch, dopo aver atteso 202 millisecondi.
In totale, i sei thread che hanno aspettato senza motivo hanno aspettato quasi 1 secondo. Parte di questo tempo è il tempo di attesa del segnale, in cui anche se al thread è stato concesso il latch, deve comunque spostarsi in cima alla coda eseguibile dello scheduler prima di poter accedere al processore ed eseguire il codice. Potresti dire che questa non è una misura equa del tempo trascorso ad aspettare il latch, ma lo è assolutamente, perché il tempo di attesa del segnale non sarebbe stato sostenuto se il thread non avesse dovuto attendere in primo luogo.
Inoltre, potresti pensare che un ritardo di 200 millisecondi non sia molto, ma tutto dipende dagli accordi sul livello di servizio delle prestazioni per il carico di lavoro in questione. Abbiamo più client ad alto volume in cui se un batch impiega più di 200 millisecondi per essere eseguito, non è consentito sul sistema di produzione!
Riepilogo
Se stai monitorando le attese sul tuo server e noti che LATCH_EX è una delle attese principali, puoi utilizzare il codice in questo post, quindi verifica se FGCB_ADD_REMOVE è uno dei colpevoli.
Il modo più semplice per assicurarsi che il carico di lavoro non raggiunga un collo di bottiglia FGCB_ADD_REMOVE consiste nell'assicurarsi che non siano presenti impostazioni di aumento automatico dei file di dati configurate utilizzando le impostazioni predefinite precedenti a SQL Server 2016. Nei sys.master_files view, il valore predefinito di 1 MB verrebbe visualizzato come file di dati (type_desc colonna impostata su ROWS) con is_percent_growth colonna impostata su 0 e colonna di crescita impostata su 128.
Dare una raccomandazione su come impostare l'autogrow è tutta un'altra discussione, ma ora sai di un potenziale impatto sulle prestazioni dovuto alla mancata modifica delle impostazioni predefinite nelle versioni precedenti.