Analisi ancora la query chiave sulla popolazione
Nella parte 3 della nostra serie di analisi ODBC, analizzeremo ulteriormente le chiavi di gestione dell'accesso per le tabelle collegate ODBC e il modo in cui ordina e raggruppa le query SELECT insieme. Nell'articolo precedente abbiamo appreso come un recordset di tipo dynaset sia in realtà 2 query separate con la prima query che recupera solo le chiavi della tabella collegata ODBC che viene quindi utilizzata per popolare i dati. In questo articolo, analizzeremo un po' di più come Access gestisce le chiavi e come deduce qual è la chiave da utilizzare per una tabella collegata ODBC tra le ramificazioni che ha. Inizieremo con l'ordinamento.
Aggiunta di un ordinamento alla query
Hai visto nell'articolo precedente che abbiamo iniziato con un semplice SELECT senza alcun ordine particolare. Hai anche visto come Access ha recuperato per la prima volta il CityID e utilizzare il risultato della prima query per popolare quindi le query successive per fornire l'apparenza di essere veloce all'utente quando si apre un recordset di grandi dimensioni. Se hai mai sperimentato una situazione in cui l'aggiunta di un ordinamento o il raggruppamento a una query, cosa improvvisamente rallenta, questo spiegherà perché.
Aggiungiamo un ordinamento su StateProvinceID in una query di Access:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Ora, se tracciamo l'SQL ODBC, dovremmo vedere l'output:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Se confronti con la traccia dell'articolo precedente, puoi vedere che sono gli stessi tranne che per la prima query. Access inserisce l'ordinamento nella prima query in cui utilizza per ottenere le chiavi. Ciò ha senso poiché, applicando l'ordinamento sulle chiavi che utilizza per scorrere i record, è garantito che Access abbia una corrispondenza uno a uno tra la posizione ordinale di un record e il modo in cui dovrebbe essere ordinato. Quindi popola i record esattamente allo stesso modo. L'unica differenza è la sequenza di chiavi che usa per compilare le altre query.
Consideriamo cosa succede quando aggiungiamo un GROUP BY facendo un conteggio delle città per stato:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;La traccia dovrebbe produrre:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Potresti anche aver notato che la query ora si apre lentamente e, anche se può essere impostato come recordset di tipo dynaset, Access ha scelto di ignorarlo e sostanzialmente trattarlo come un recordset di tipo snapshot. Questo ha senso perché la query non è aggiornabile e perché non puoi davvero navigare in una posizione arbitraria in una query come questa. Pertanto, devi attendere che tutte le righe siano state recuperate prima di poter navigare liberamente. Il StateProvinceID non può essere utilizzato per individuare un record poiché ci sarebbero diversi record nelle Cities tavolo. Anche se ho usato un GROUP BY in questo esempio, non deve essere un raggruppamento che fa sì che Access utilizzi invece un recordset di tipo snapshot. Usando DISTINCT ad esempio avrebbe lo stesso effetto. Una regola pratica utile per prevedere se Access utilizzerà recordset di tipo dynaset consiste nel chiedere se una determinata riga nel recordset risultante viene mappata indietro esattamente a una riga nell'origine dati ODBC. In caso contrario, Access utilizzerà il comportamento snapshot anche se la query avrebbe dovuto utilizzare dynaset. Di conseguenza, solo perché l'impostazione predefinita è un recordset di tipo dynaset, non garantisce che sarà effettivamente un recordset di tipo dynaset. È solo una richiesta , non una richiesta.
Determinazione della chiave da utilizzare per la selezione
Potresti aver notato nel precedente SQL tracciato sia in questo articolo che in quelli precedenti, Access utilizzava il CityID come chiave. Quella colonna è stata recuperata nella prima query, quindi utilizzata nelle query preparate successive. Ma come fa Access a sapere quali colonne di una tabella collegata dovrebbe utilizzare? La prima inclinazione sarebbe dire che controlla una chiave primaria e la usa. Tuttavia, ciò non sarebbe corretto. In effetti, il motore di database di Access utilizzerà SQLStatistics di ODBC funzione durante il collegamento o il ricollegamento della tabella per esaminare quali indici sono disponibili. Questa funzione restituirà un set di risultati con una riga per ogni colonna che partecipa a un indice per tutti gli indici. Questo set di risultati è sempre ordinato e, per convenzione, ordinerà sempre indici cluster, indici hash e quindi altri tipi di indici. All'interno di ogni tipo di indice, gli indici saranno ordinati in ordine alfabetico in base al nome. Il motore di database di Access selezionerà il primo indice univoco che trova anche se non è la chiave primaria effettiva. Per dimostrarlo, creeremo una stupida tabella con alcuni indici dispari:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Se quindi popolamo la tabella con alcuni dati e ci colleghiamo ad essa in Access e apriamo una visualizzazione foglio dati sulla tabella collegata, lo vedremo nell'SQL ODBC tracciato. Per brevità, sono inclusi solo i primi 2 comandi.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Perché il
OtherStuff partecipa a un indice cluster, è arrivato prima della chiave primaria effettiva ed è stato quindi selezionato dal motore di database di Access per essere utilizzato nel recordset di tipo dynaset per la selezione di una singola riga. Ciò è anche malgrado il fatto che il nome dell'indice cluster univoco sarebbe seguito al nome dell'indice primario. Una tattica per forzare il motore di database di Access a selezionare un particolare indice per una tabella consiste nel modificarne il tipo o rinominare il nome in modo che venga ordinato alfabeticamente all'interno del gruppo del tipo di indice. Nel caso di SQL Server, le chiavi primarie sono in genere raggruppate e può esserci un solo indice cluster, quindi è un felice incidente che di solito è l'indice corretto da utilizzare per il motore di database di Access. Tuttavia, se il database di SQL Server contiene tabelle con chiavi primarie non in cluster ed è presente un indice univoco in cluster, potrebbe non essere la scelta ottimale. Nei casi in cui non sono presenti indici raggruppati, puoi influenzare quali indici univoci vengono utilizzati nominando l'indice in modo che venga ordinato prima di altri indici. Ciò può essere utile con altri software RDBMS in cui la creazione di un indice cluster per la chiave primaria non è pratica o possibile. Indice lato accesso per vista SQL collegata o tabella senza indici
Quando ci si collega a una vista SQL o a una tabella SQL che non dispone di alcun indice o chiave primaria definita, non saranno disponibili indici per il motore di database di Access da utilizzare. Se hai utilizzato il gestore tabelle collegato per collegare una tabella o una vista SQL senza indici, potresti aver visto una finestra di dialogo come questa:
 Se selezioniamo l'
Se selezioniamo l'ID , completa il collegamento, apri la tabella collegata in visualizzazione struttura, quindi la finestra di dialogo degli indici, dovremmo vedere questo:
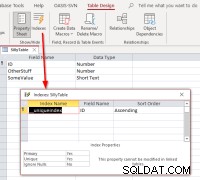 Mostra che la tabella ha un indice chiamato
Mostra che la tabella ha un indice chiamato __uniqueindex ma non esiste nell'origine dati originale. Cosa sta succedendo? La risposta è che Access ha creato un lato accesso index per il suo utilizzo per aiutare a identificare quale può essere utilizzato come identificatore di record per tali tabelle o viste. Se ti capita di ricollegare le tabelle in modo programmatico anziché utilizzare il Linked Table Manager, troverai necessario replicare il comportamento per rendere aggiornabili tali tabelle collegate. Questo può essere fatto eseguendo un comando Access SQL:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Ad esempio, puoi usare
CurrentDb.Execute per eseguire Access SQL per creare l'indice sulla tabella collegata. Tuttavia, non dovresti eseguirlo come una query pass-through perché l'indice non è effettivamente creato sul server. È solo per i vantaggi di Access consentire l'aggiornamento su quella tabella collegata. Vale la pena notare che Access consentirà esattamente un solo indice per tale tabella collegata e solo se non ha già indici. Tuttavia, puoi vedere che l'utilizzo di una vista SQL può essere un'opzione desiderabile nei casi in cui la progettazione del database non consente di utilizzare indici cluster e non si desidera giocherellare con il nome dell'indice per convincere il motore del database di Access a utilizzare questo indice, non quell'indice. Puoi controllare in modo esplicito l'indice e le colonne che dovrebbe includere quando colleghi la vista SQL.
Conclusioni
Dall'articolo precedente abbiamo visto che un recordset di tipo dynaset di solito emette 2 query. La prima query di solito riguarda il popolamento. Abbiamo esaminato più da vicino come Access gestisce la popolazione di chiavi che utilizzerà per un recordset di tipo dynaset. Abbiamo visto come Access convertirà effettivamente qualsiasi ordinamento dalla query di Access originale e quindi lo utilizzerà nella query di popolazione chiave. Abbiamo visto che l'ordine della query di popolazione chiave influisce direttamente sul modo in cui i dati nel recordset verranno ordinati e presentati all'utente. Ciò consente all'utente di eseguire operazioni come passare a un record abritrary in base alla posizione ordinale dell'elenco.
Abbiamo quindi visto che il raggruppamento e altre operazioni SQL che impediscono il mapping univoco tra la riga restituita e la riga originale faranno sì che Access consideri la query di Access come se fosse un recordset di tipo snapshot nonostante la richiesta di un recordset di tipo dynaset.
Abbiamo quindi esaminato il modo in cui Access determina la chiave da utilizzare per la gestione degli aggiornamenti con una tabella collegata ODBC. Contrariamente a quanto ci si potrebbe aspettare, non selezionerà necessariamente la chiave primaria della tabella ma piuttosto il primo indice univoco che trova, a seconda del tipo di indice e del nome dell'indice. Abbiamo discusso le strategie per garantire che Access selezioni l'indice univoco corretto. Abbiamo esaminato la vista SQL che normalmente non ha indici e discusso un metodo per informare Access su come digitare una vista SQL o una tabella che non ha alcuna chiave primaria, consentendoci un maggiore controllo su come Access gestirà gli aggiornamenti per quelle tabelle collegate ODBC.
Nel prossimo articolo vedremo come Access esegue effettivamente gli aggiornamenti sui dati quando gli utenti apportano modifiche tramite la query di Access o l'origine record.
I nostri esperti di accesso sono disponibili ad aiutare. Chiamaci al 773-809-5456 o inviaci un'e-mail a sales@itimpact.com.