PostgreSQL è un progetto fantastico e si evolve a un ritmo incredibile. Ci concentreremo sull'evoluzione delle capacità di tolleranza agli errori in PostgreSQL in tutte le sue versioni con una serie di post sul blog. Questo è il secondo post della serie e parleremo della replica e della sua importanza sulla tolleranza agli errori e sull'affidabilità di PostgreSQL.
Se desideri assistere ai progressi dell'evoluzione dall'inizio, controlla il primo post del blog della serie:Evolution of Fault Tolerance in PostgreSQL
Replica PostgreSQL
Replica del database è il termine che usiamo per descrivere la tecnologia utilizzata per mantenere una copia di un insieme di dati su un telecomando sistema. Mantenere una copia affidabile di un sistema in esecuzione è una delle maggiori preoccupazioni della ridondanza e a tutti noi piacciono le copie manutenibili, facili da usare e stabili dei nostri dati.
Diamo un'occhiata all'architettura di base. In genere, i singoli server di database sono indicati come nodi . L'intero gruppo di server di database coinvolti nella replica è noto come cluster . Un server di database che consente a un utente di apportare modifiche è noto come master o primario , o può essere descritto come fonte di modifiche. Un server di database che solo consente l'accesso in sola lettura è noto come Hot Standby . (Il termine Hot Standby è spiegato in dettaglio nel titolo Modalità standby. )
L'aspetto chiave della replica è che le modifiche ai dati vengono acquisite su un master e quindi trasferite ad altri nodi. In alcuni casi, un nodo può inviare modifiche ai dati ad altri nodi, processo noto come a cascata o relè . Pertanto, il master è un nodo di invio ma non tutti i nodi di invio devono essere master. La replica è spesso classificata in base al fatto che sia consentito più di un nodo master, nel qual caso sarà noto come replica multimaster .
Vediamo come PostgreSQL gestisce la replica nel tempo e qual è lo stato dell'arte per la tolleranza agli errori in termini di replica.
Cronologia della replica di PostgreSQL
Storicamente (intorno all'anno 2000-2005), Postgres si è concentrato solo nella tolleranza/ripristino degli errori di un singolo nodo, che è principalmente ottenuto dal WAL, il registro delle transazioni. La tolleranza ai guasti è gestita in parte da MVCC (sistema di concorrenza multi-versione), ma è principalmente un'ottimizzazione.
La registrazione write-ahead era ed è tuttora il più grande metodo di tolleranza agli errori in PostgreSQL. Fondamentalmente, basta avere file WAL in cui scrivi tutto e puoi recuperare in termini di errore riproducendoli. Questo era sufficiente per le architetture a nodo singolo e la replica è considerata la migliore soluzione per ottenere la tolleranza agli errori con più nodi.
La comunità di Postgres credeva da molto tempo che la replica fosse qualcosa che Postgres non dovrebbe fornire e dovrebbe essere gestita da strumenti esterni, ecco perché strumenti come Slony e Londiste sono diventati esistenti. (Tratteremo le soluzioni di replica basate su trigger nei prossimi post del blog della serie.)
Alla fine è diventato chiaro che una tolleranza del server non è sufficiente e più persone hanno richiesto un'adeguata tolleranza agli errori dell'hardware e un modo corretto di cambiare, qualcosa integrato in Postgres. È qui che ha preso vita la replica fisica (quindi lo streaming fisico).
Esamineremo tutti i metodi di replica più avanti nel post, ma vediamo gli eventi cronologici della cronologia di replica di PostgreSQL in base alle versioni principali:
- PostgreSQL 7.x (~2000)
- La replica non dovrebbe far parte del core Postgres
- Londiste – Slony (replica logica basata su trigger)
- PostgreSQL 8.0 (2005)
- Recupero point-in-time (WAL)
- PostgreSQL 9.0 (2010)
- Replica in streaming (fisica)
- PostgreSQL 9.4 (2014)
- Decodifica logica (estrazione di changeset)
Replica fisica
PostgreSQL ha risolto l'esigenza di replica principale con ciò che fa la maggior parte dei database relazionali; ha preso il WAL e ha reso possibile inviarlo in rete. Quindi questi file WAL vengono applicati in un'istanza Postgres separata che è in sola lettura.
L'istanza standby di sola lettura applica solo le modifiche (tramite WAL) e le uniche operazioni di scrittura provengono di nuovo dallo stesso registro WAL. Questo è fondamentalmente il modo in cui trasmettere la replica in streaming meccanismo funziona. All'inizio, la replica originariamente spediva tutti i file –spedizione log- , ma in seguito si è evoluto in streaming.
Nella spedizione dei log, stavamo inviando file interi tramite archive_command . La logica è piuttosto semplice:basta inviare l'archivio e il registro da qualche parte, come l'intero file WAL da 16 MB, e quindi applica da qualche parte, e poi recupera quello successivo e applica quello e va così. Successivamente, è diventato streaming su rete utilizzando il protocollo libpq in PostgreSQL versione 9.0.
La replica esistente è più propriamente nota come Replica in streaming fisico poiché stiamo trasmettendo in streaming una serie di modifiche fisiche da un nodo all'altro. Ciò significa che quando inseriamo una riga in una tabella generiamo record di modifiche per l' inserto più tutte le voci dell'indice .
Quando VACUUM una tabella generiamo anche record di modifiche.
Inoltre, Physical Streaming Replication registra tutte le modifiche a livello di byte/blocco , rendendo molto difficile fare qualcosa di diverso dalla semplice riproduzione di tutto
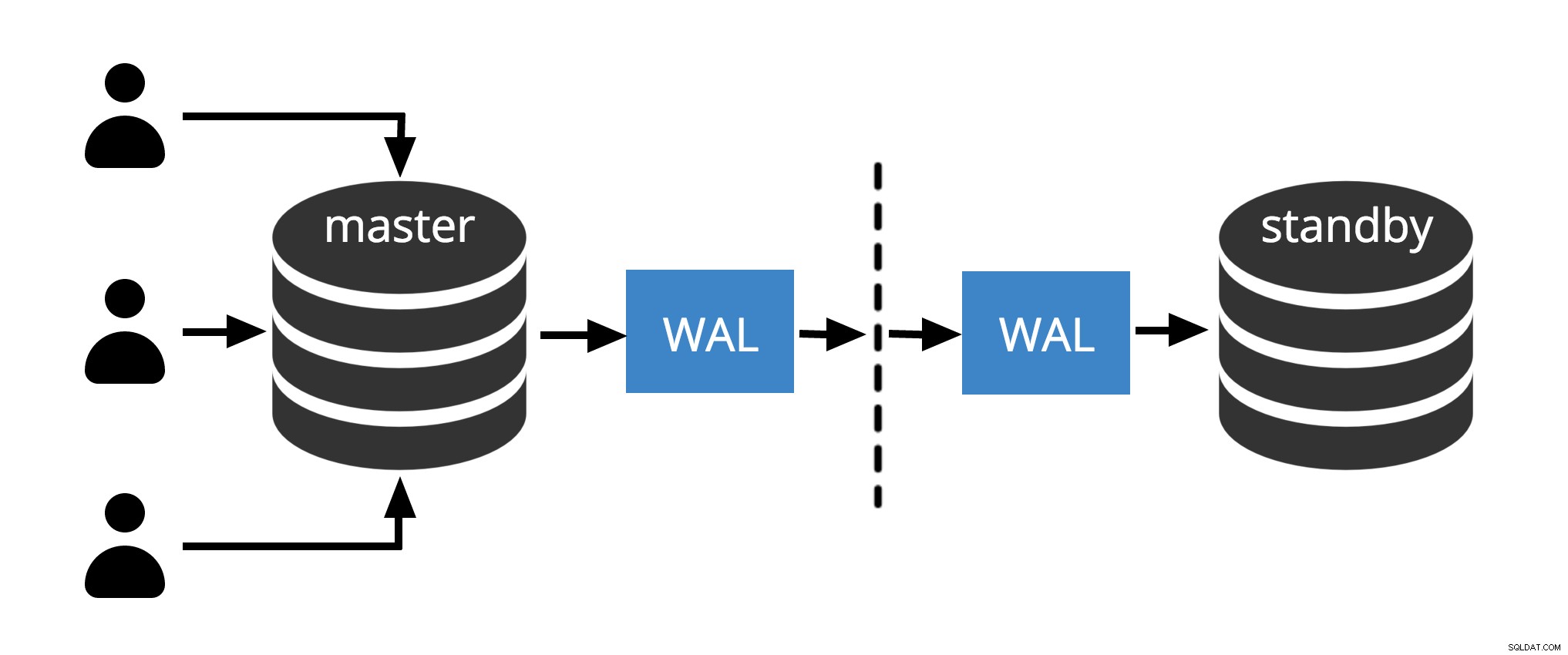
Fig.1 Replica fisica
La Fig.1 mostra come funziona la replica fisica con solo due nodi. Il client esegue le query sul nodo master, le modifiche vengono scritte in un registro delle transazioni (WAL) e copiate sulla rete in WAL sul nodo di standby. Il processo di ripristino sul nodo di standby legge quindi le modifiche da WAL e le applica ai file di dati proprio come durante il ripristino di emergenza. Se lo standby è in hot standby modalità, i client possono emettere query di sola lettura sul nodo mentre ciò sta accadendo.
Nota: La replica fisica si riferisce semplicemente all'invio di file WAL in rete dal master al nodo standby. I file possono essere inviati con diversi protocolli come scp, rsync, ftp... La differenza tra Replica fisica e Replica fisica in streaming is Streaming Replication utilizza un protocollo interno per l'invio di file WAL (mittente e processi del destinatario )
Modalità standby
Più nodi forniscono un'elevata disponibilità. Per questo motivo le architetture moderne di solito hanno nodi in standby. Esistono diverse modalità per i nodi in standby (warm e hot standby). L'elenco seguente spiega le differenze di base tra le diverse modalità standby e mostra anche il caso dell'architettura multi-master.
Standby caldo
Può essere attivato immediatamente, ma non può svolgere un lavoro utile finché non viene attivato. Se alimentiamo continuamente la serie di file WAL su un'altra macchina che è stata caricata con lo stesso file di backup di base, abbiamo un sistema di warm standby:in qualsiasi momento possiamo far apparire la seconda macchina e questa avrà una copia quasi attuale di la banca dati. Warm standby non consente query di sola lettura, la Fig.2 rappresenta semplicemente questo fatto.
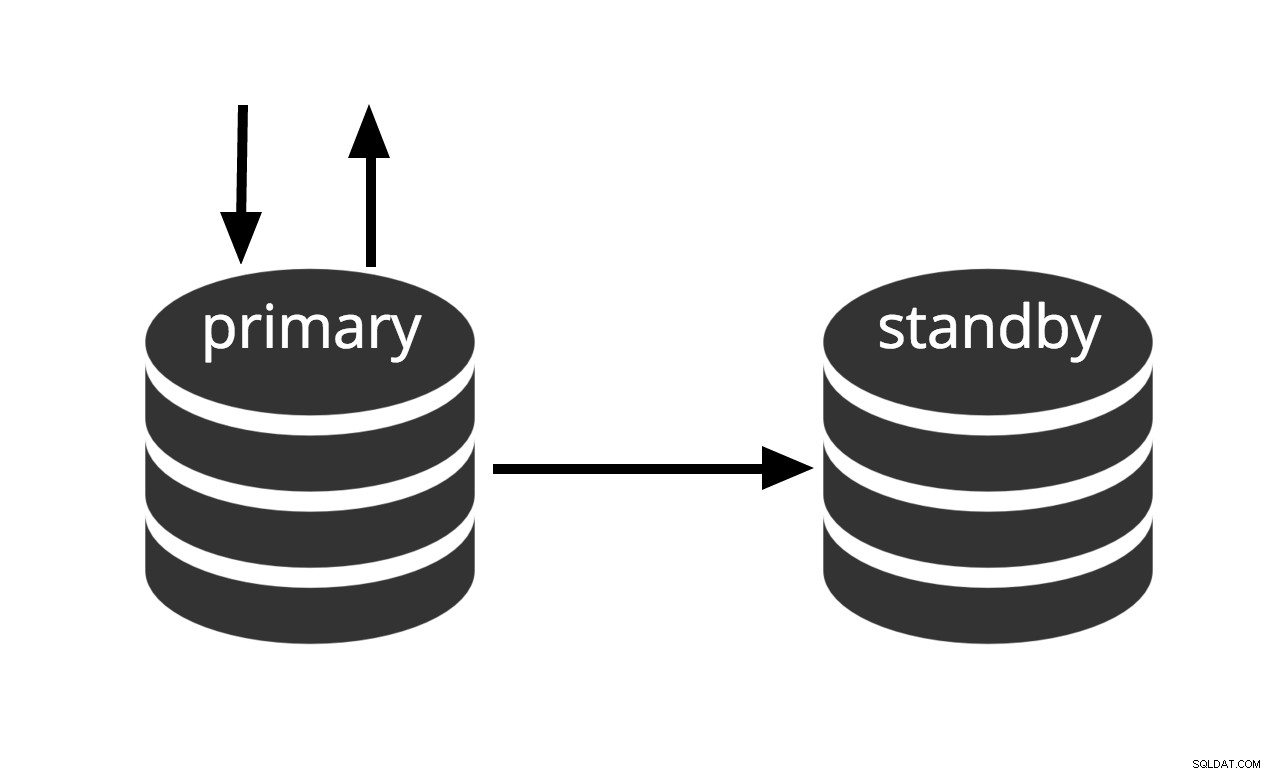
Fig.2 Warm Standby
Le prestazioni di ripristino di un warm standby sono sufficientemente buone che lo standby sarà in genere solo a pochi istanti dalla piena disponibilità una volta attivato. Di conseguenza, questa è chiamata configurazione warm standby che offre un'elevata disponibilità.
Hot Standby
Hot standby è il termine utilizzato per descrivere la capacità di connettersi al server ed eseguire query di sola lettura mentre il server è in modalità di ripristino dell'archivio o standby. Ciò è utile sia per scopi di replica che per ripristinare un backup allo stato desiderato con grande precisione.
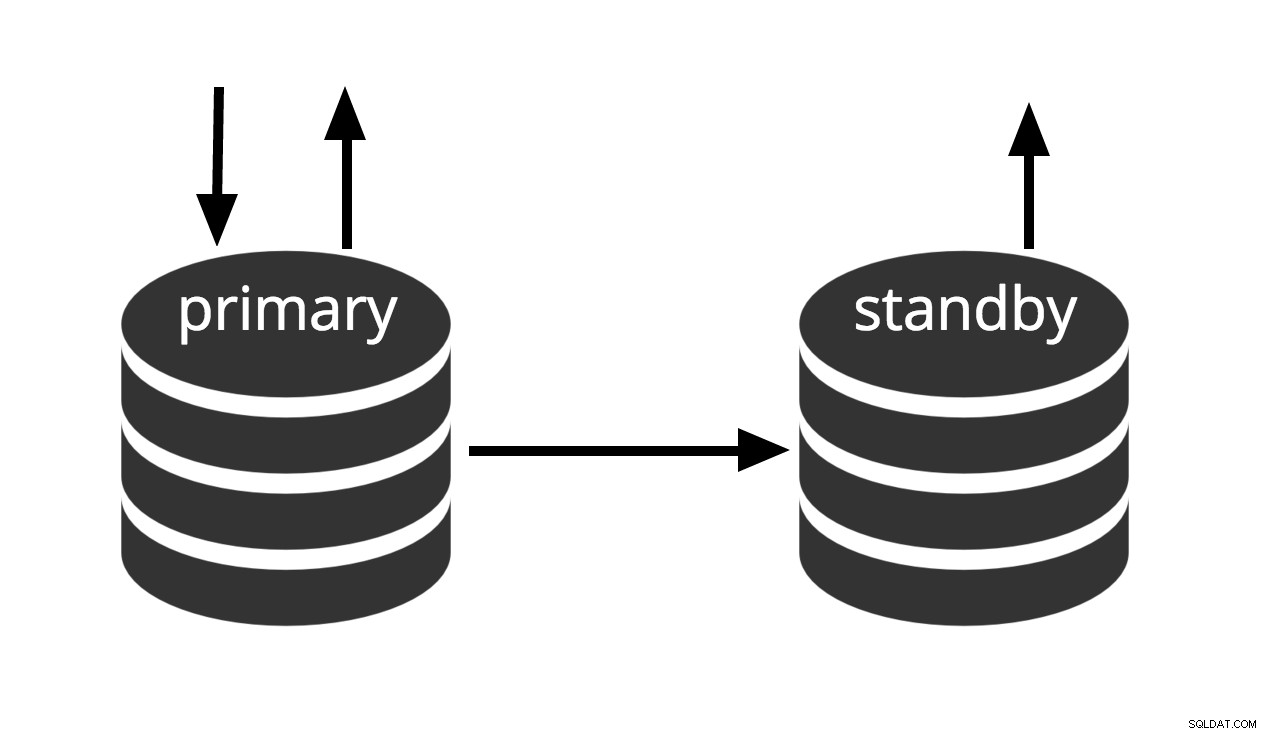 Fig.3 Hot Standby
Fig.3 Hot Standby
Il termine hot standby si riferisce anche alla capacità del server di passare dal ripristino al normale funzionamento mentre gli utenti continuano a eseguire query e/o mantengono aperte le connessioni. La Fig.3 mostra che la modalità standby consente query di sola lettura.
Multi-Master
Tutti i nodi possono eseguire lavori di lettura/scrittura. (Tratteremo le architetture multi-master nei prossimi post del blog della serie.)
Parametro livello WAL
Esiste una relazione tra l'impostazione di wal_level parametro nel file postgresql.conf e per cosa è adatta questa impostazione. Ho creato una tabella per mostrare la relazione per PostgreSQL versione 9.6.

Failover e passaggio
Nella replica a master singolo, se il master muore, deve prendere il suo posto uno degli standbys (promozione ). In caso contrario, non saremo in grado di accettare nuove transazioni di scrittura. Pertanto, i termini designazioni, master e standby, sono solo ruoli che qualsiasi nodo può assumere a un certo punto. Per spostare il ruolo principale su un altro nodo, eseguiamo una procedura denominata Switchover .
Se il master muore e non si riprende, il cambio di ruolo più grave è noto come Failover . In molti modi, questi possono essere simili, ma aiuta a utilizzare termini diversi per ogni evento. (Conoscere i termini di failover e switchover ci aiuterà a comprendere i problemi della sequenza temporale nel prossimo post del blog.)
Conclusione
In questo post del blog abbiamo discusso della replica di PostgreSQL e della sua importanza per fornire tolleranza agli errori e affidabilità. Abbiamo trattato la replica dello streaming fisico e abbiamo parlato delle modalità standby per PostgreSQL. Abbiamo menzionato Failover e Switchover. Continueremo con le timeline di PostgreSQL nel prossimo post del blog.
Riferimenti
Documentazione PostgreSQL
Replica logica in PostgreSQL 5432... Presentazione MeetUs di Petr Jelinek
Ricettario amministrativo di PostgreSQL 9 – Seconda edizione