PostgreSQL Streaming Replication è un ottimo modo per ridimensionare i cluster PostgreSQL e aggiungervi un'elevata disponibilità. Come per ogni replica, l'idea è che lo slave sia una copia del master e che lo slave sia costantemente aggiornato con le modifiche avvenute sul master utilizzando una sorta di meccanismo di replica.
Può succedere che lo slave, per qualche motivo, non sia sincronizzato con il master. Come posso riportarlo alla catena di replica? Come posso assicurarmi che lo slave sia di nuovo sincronizzato con il master? Diamo un'occhiata a questo breve post sul blog.
Ciò che è molto utile, non c'è modo di scrivere su uno slave se è in modalità di ripristino. Puoi testarlo in questo modo:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionPuò ancora accadere che lo slave non sia sincronizzato con il master. Corruzione dei dati:né l'hardware né il software sono privi di bug e problemi. Alcuni problemi con l'unità disco possono causare il danneggiamento dei dati sullo slave. Alcuni problemi con il processo di "vuoto" possono causare l'alterazione dei dati. Come recuperare da quello stato?
Ricostruire lo slave usando pg_basebackup
Il passaggio principale consiste nel fornire lo slave utilizzando i dati del master. Dato che utilizzeremo la replica in streaming, non possiamo utilizzare il backup logico. Fortunatamente c'è uno strumento pronto che può essere utilizzato per impostare le cose:pg_basebackup. Vediamo quali sarebbero i passaggi necessari per eseguire il provisioning di un server slave. Per chiarire, stiamo usando PostgreSQL 12 ai fini di questo post sul blog.
Lo stato iniziale è semplice. Il nostro schiavo non si sta replicando dal suo padrone. I dati in esso contenuti sono danneggiati e non possono essere utilizzati né attendibili. Pertanto il primo passo che faremo sarà fermare PostgreSQL sul nostro slave e rimuovere i dati in esso contenuti:
example@sqldat.com:~# systemctl stop postgresqlO anche:
example@sqldat.com:~# killall -9 postgresOra, controlliamo il contenuto del file postgresql.auto.conf, possiamo utilizzare le credenziali di replica memorizzate in quel file in un secondo momento, per pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Siamo interessati all'utente e alla password utilizzati per impostare la replica.
Finalmente possiamo rimuovere i dati:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Una volta rimossi i dati, dobbiamo usare pg_basebackup per ottenere i dati dal master:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointI flag che abbiamo utilizzato hanno il seguente significato:
- -Xs: vorremmo eseguire lo streaming WAL durante la creazione del backup. Questo aiuta a evitare problemi con la rimozione dei file WAL quando si dispone di un set di dati di grandi dimensioni.
- -P: vorremmo vedere lo stato di avanzamento del backup.
- -R: vogliamo che pg_basebackup crei il file standby.signal e prepari il file postgresql.auto.conf con le impostazioni di connessione.
pg_basebackup attenderà il checkpoint prima di avviare il backup. Se impiega troppo tempo, puoi utilizzare due opzioni. Innanzitutto, è possibile impostare la modalità checkpoint su fast in pg_basebackup utilizzando l'opzione '-c fast'. In alternativa, puoi forzare il checkpoint eseguendo:
postgres=# CHECKPOINT;
CHECKPOINTIn un modo o nell'altro, si avvierà pg_basebackup. Con il flag -P possiamo tenere traccia dei progressi:
416906/1588478 kB (26%), 0/1 tablespaceceaceUna volta che il backup è pronto, tutto ciò che dobbiamo fare è assicurarci che il contenuto della directory dei dati abbia l'utente e il gruppo corretti assegnati - abbiamo eseguito pg_basebackup come 'root' quindi vogliamo cambiarlo in 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Questo è tutto, possiamo avviare lo slave e dovrebbe iniziare a replicarsi dal master.
example@sqldat.com:~# systemctl start postgresqlPuoi ricontrollare l'avanzamento della replica eseguendo la seguente query sul master:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Come puoi vedere, entrambi gli slave si stanno replicando correttamente.
Ricostruire lo slave utilizzando ClusterControl
Se sei un utente ClusterControl puoi facilmente ottenere esattamente lo stesso semplicemente selezionando un'opzione dall'interfaccia utente.
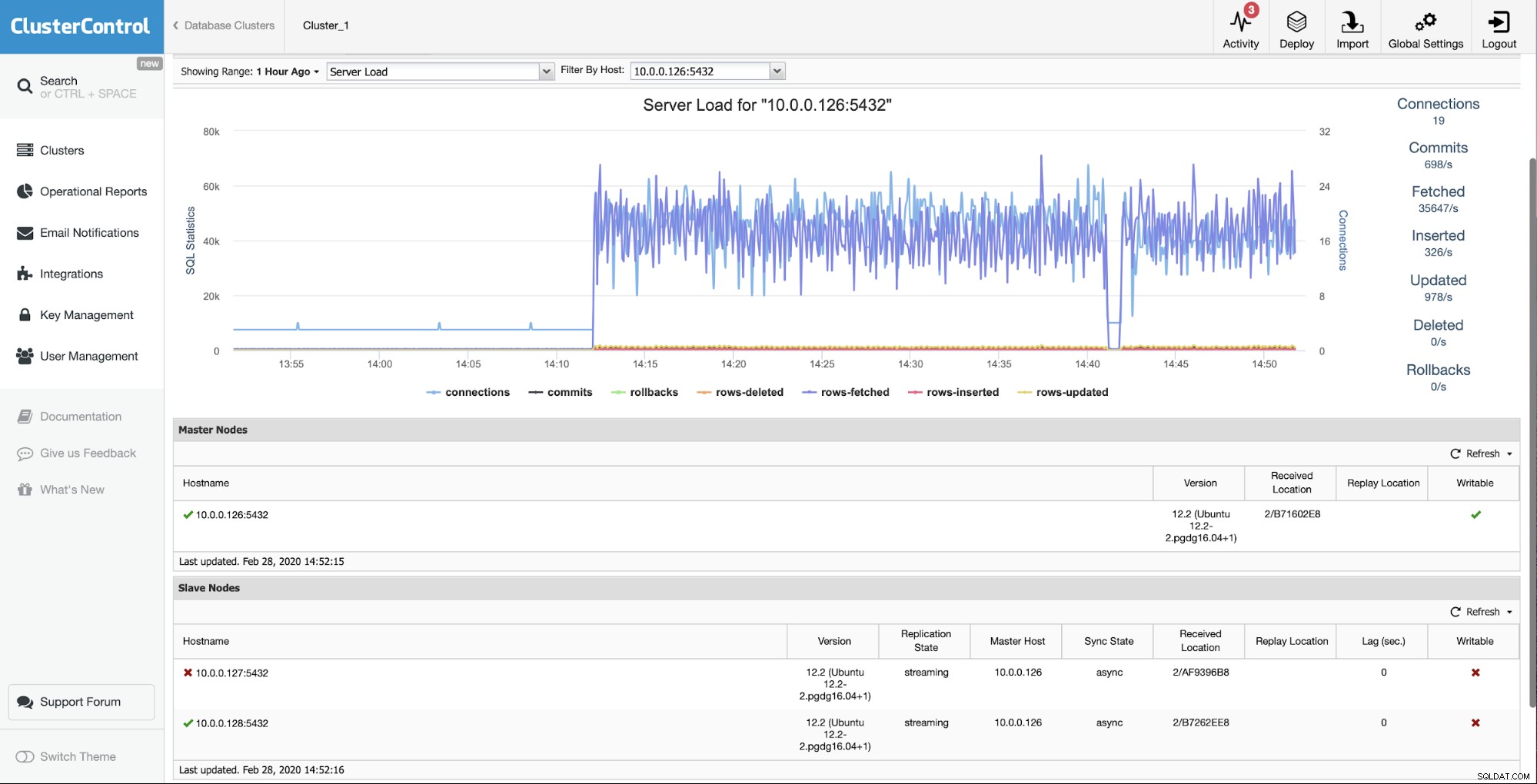
La situazione iniziale è che uno degli slave (10.0.0.127) sia non funziona e non si replica. Abbiamo ritenuto che la ricostruzione fosse l'opzione migliore per noi.
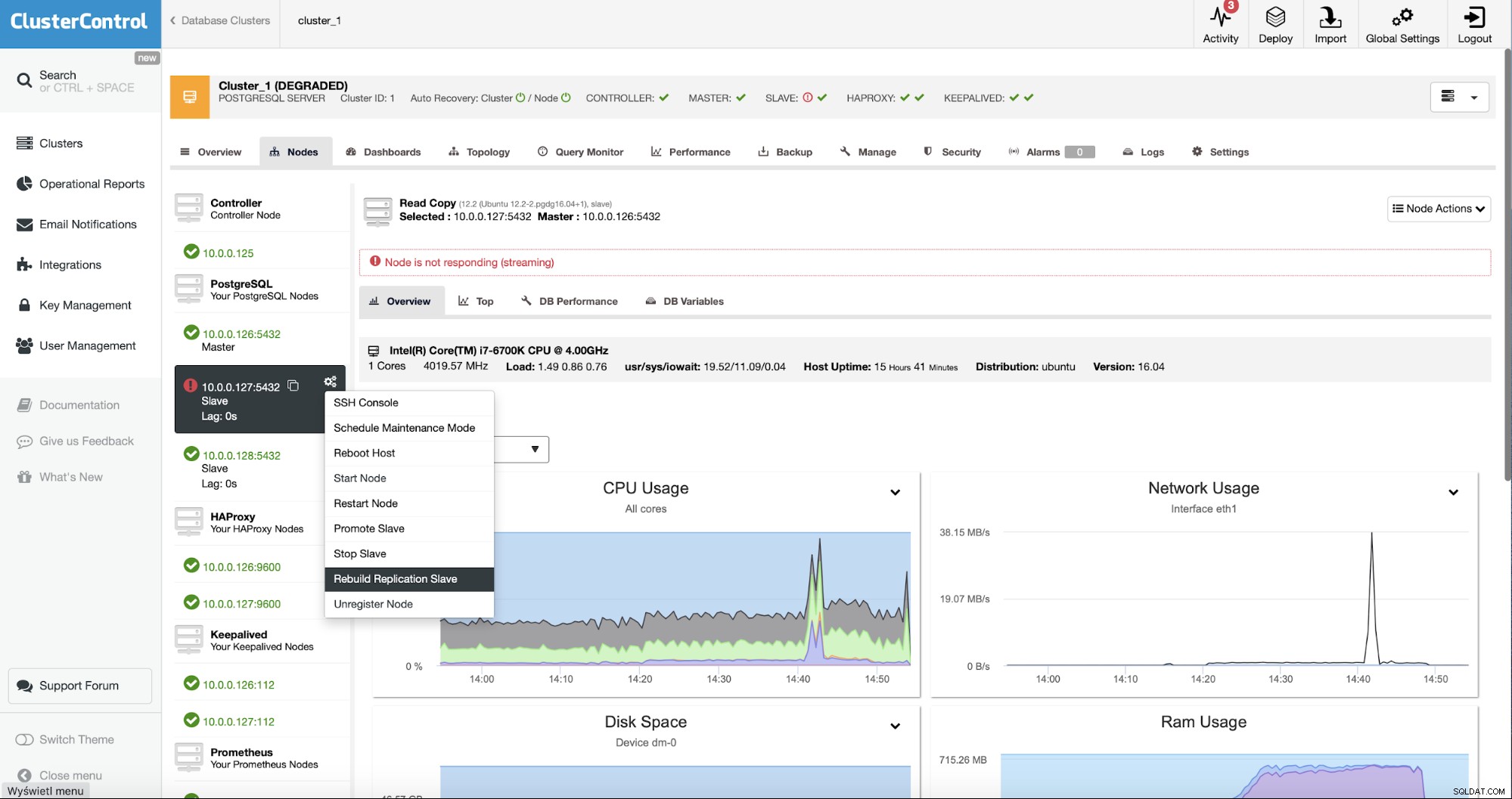
Come utenti ClusterControl tutto ciò che dobbiamo fare è accedere ai "Nodi ” ed esegui il lavoro “Rebuild Replication Slave”.
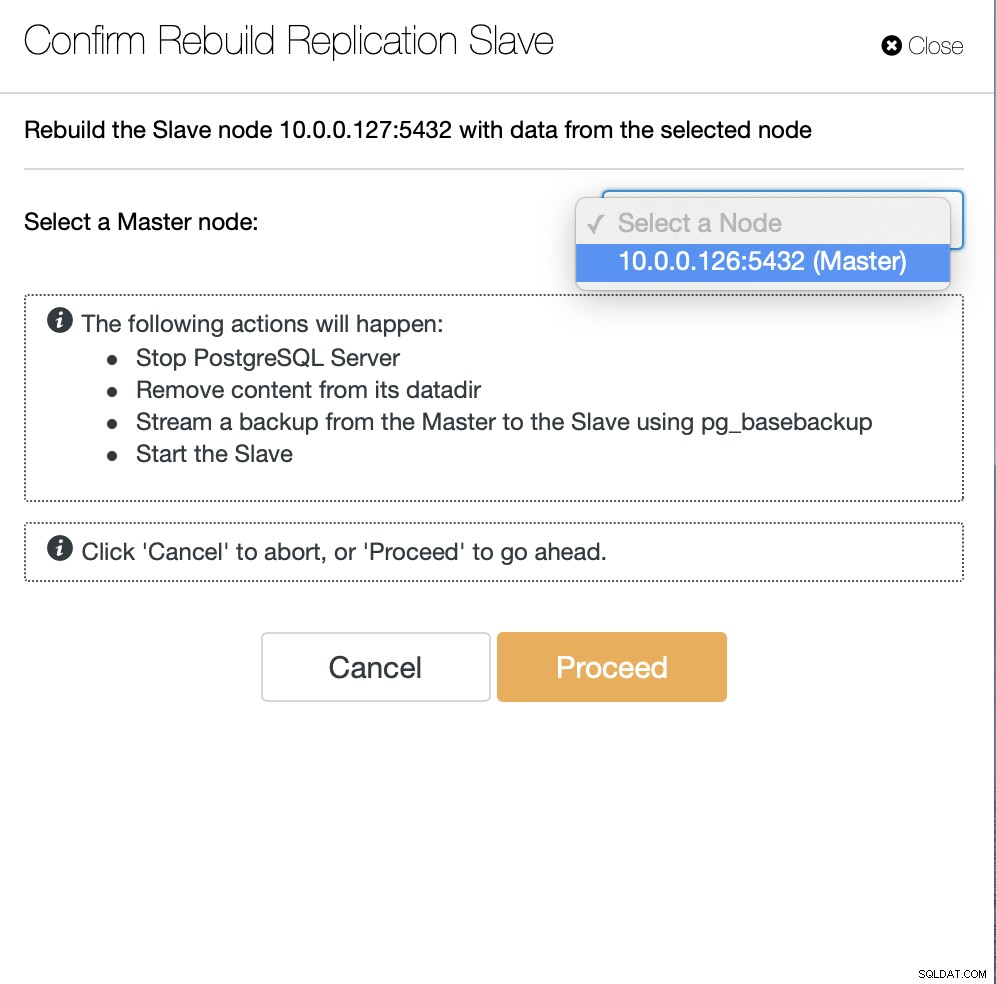
Successivamente, dobbiamo scegliere il nodo da cui ricostruire lo slave e questo è Tutto. ClusterControl utilizzerà pg_basebackup per configurare lo slave di replica e configurare la replica non appena i dati vengono trasferiti.
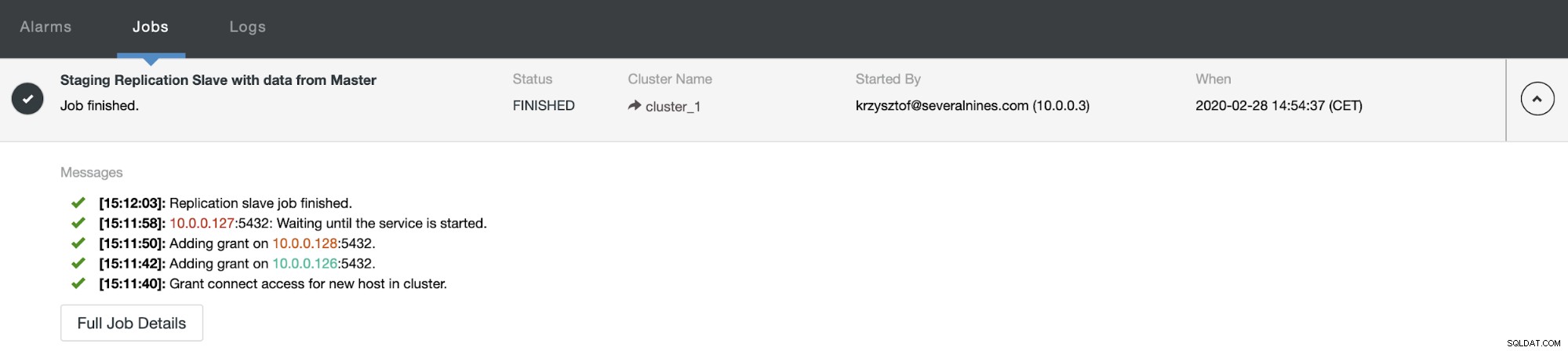
Dopo un po' di tempo il lavoro viene completato e lo slave torna nella catena di replica:
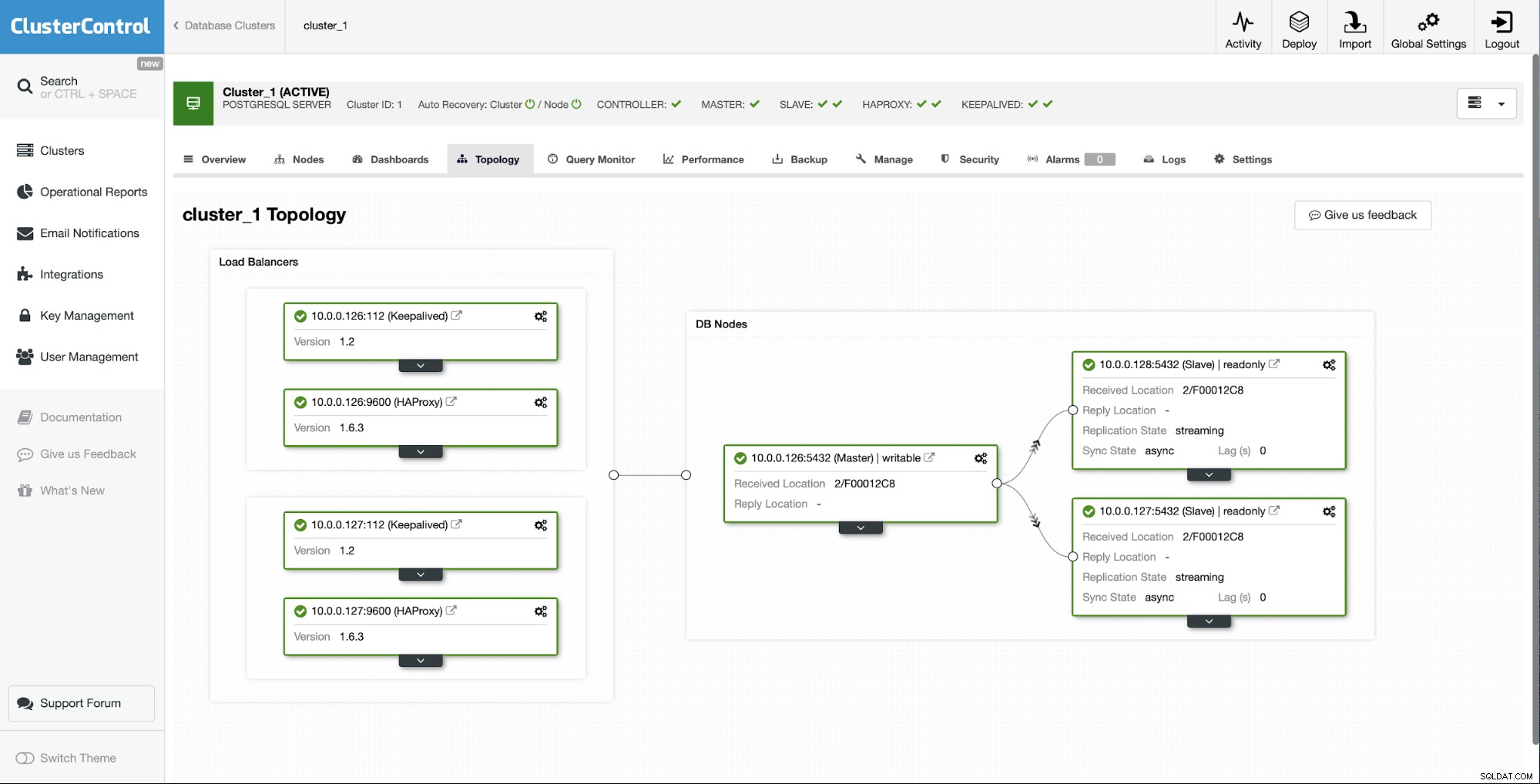
Come puoi vedere, con solo un paio di clic, grazie a ClusterControl, siamo riusciti a ricostruire il nostro slave guasto e riportarlo nel cluster.