Questo articolo fornisce una guida passo passo all'utilizzo delle funzionalità di Machine Learning con 2UDA. Nell'articolo utilizzeremo un esempio di Animali per prevedere se si tratta di mammiferi, uccelli, pesci o insetti.
Versioni software
Useremo 2UDA versione 11.6-1 per implementare il modello di Machine Learning. 2UDA versione 11.6-1 combina:
- PostgreSQL 11.6
- Arancione 3.23.0
Puoi trovare l'ultima versione di 2UDA qui.
Passaggio 1:carica il set di dati di addestramento in PostgreSQL
Il set di dati di esempio utilizzato per addestrare il nostro modello è disponibile nel repository GitHub ufficiale di Orange qui.
Segui questi passaggi per caricare i dati di addestramento nelle tabelle PostgreSQL:
- Connettiti a PostgreSQL tramite psql, OmniDB o qualsiasi altro strumento che conosci.
- Crea una tabella per memorizzare i nostri dati di allenamento . Qui è chiamato training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Inserisci i dati di addestramento nella tabella tramite query COPY. Prima di eseguire la query COPY, assicurati che PostgreSQL abbia richiesto i permessi di lettura sul file di dati, altrimenti l'operazione COPY fallirà.
NOTA: Assicurati di digitare una scheda spazio tra virgolette singole dopo il delimitatore parola chiave.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Di seguito lo screenshot del set di dati di addestramento
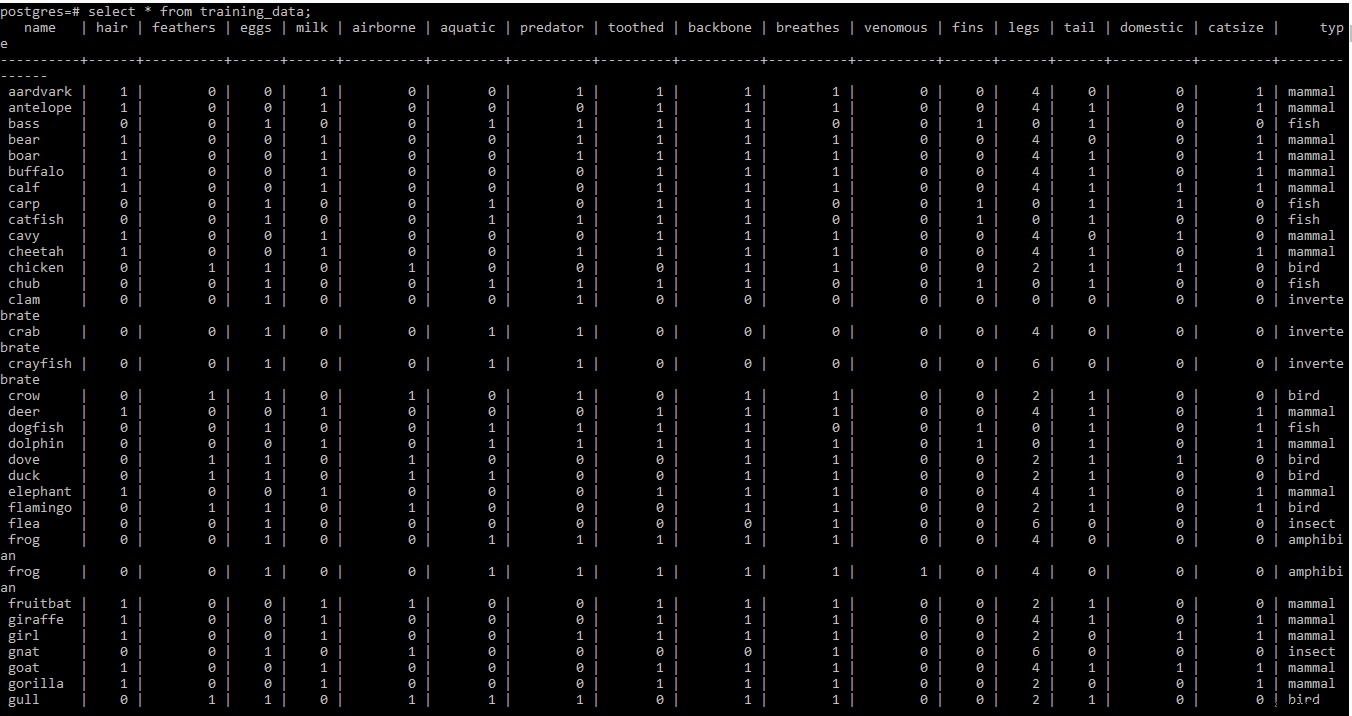
NOTA: Righe due e tre del set di dati di addestramento in .tab il file contiene alcune meta informazioni. Poiché a questo punto non è necessario, è stato rimosso dal file.
Fase 2:crea un flusso di lavoro con Orange
- Vai sul desktop e fai doppio clic sull'icona arancione.
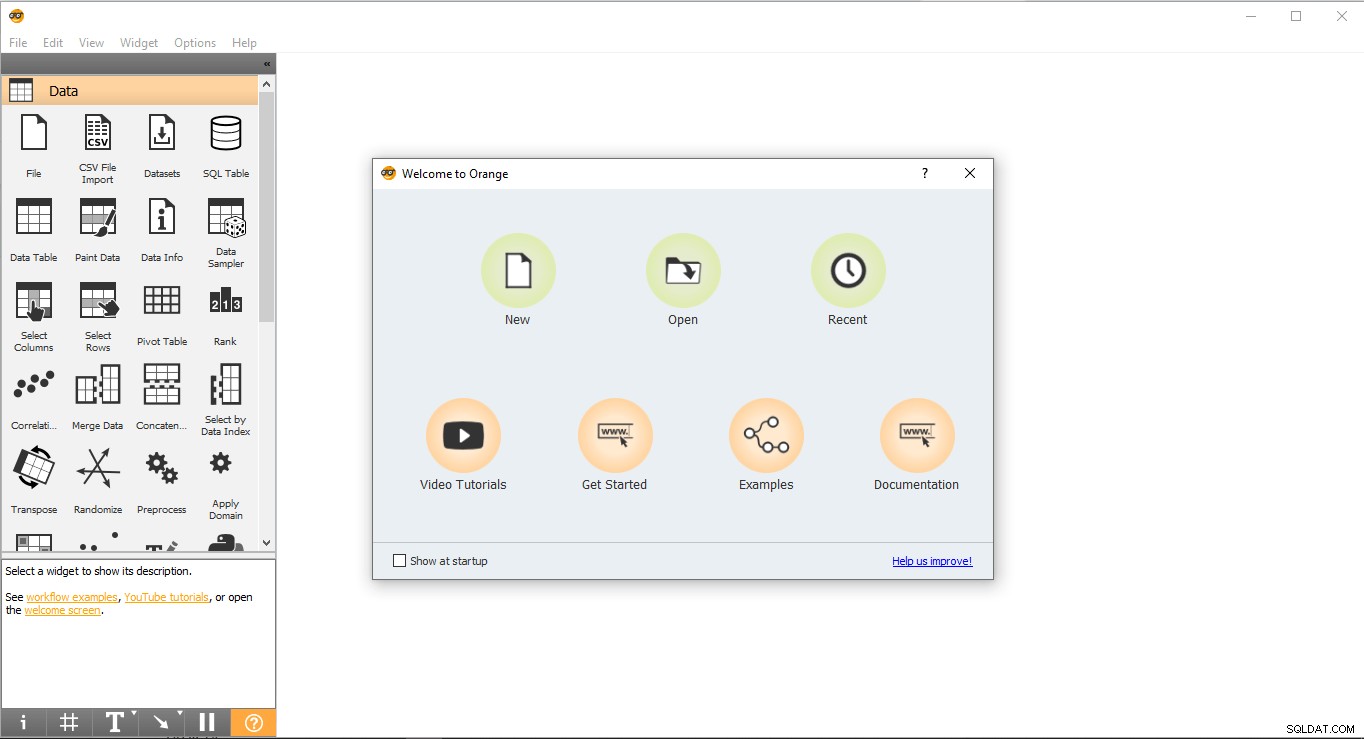
- Questo è l'aspetto della pagina iniziale. Seleziona Nuovo opzione e creerà un progetto vuoto.

Ora sei pronto per applicare il modello di Machine Learning sul set di dati.
Passaggio 3:seleziona il modello di Machine Learning per addestrare i dati
Per questo articolo, il più vicino vicini (KNN) Il modello di Machine Learning viene utilizzato per addestrare i dati. Una volta completato il processo di addestramento dei dati, nel passaggio successivo i dati del test vengono passati alla Previsione widget per verificare l'accuratezza delle previsioni.
Fase 4:importa i dati di addestramento da PostgreSQL in Orange
Questo set di dati di addestramento verrà utilizzato per addestrare il modello di Machine Learning.
- Trascina e rilascia Tabella SQL widget dai Dati menù.
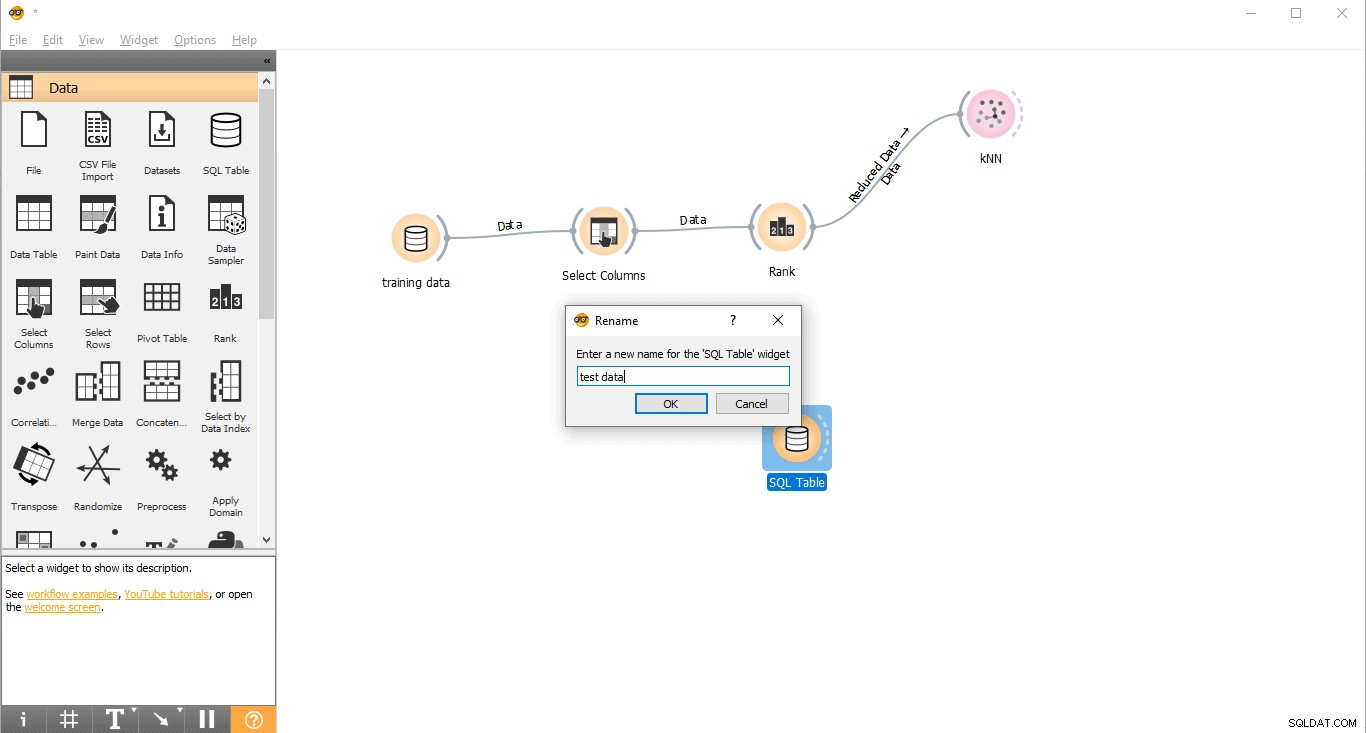
- Rinomina widget (opzionale)
- Fai clic con il pulsante destro del mouse sulla Tabella SQL widget.
- Seleziona Rinomina .
- Connettiti con PostgreSQL per caricare il set di dati di addestramento:
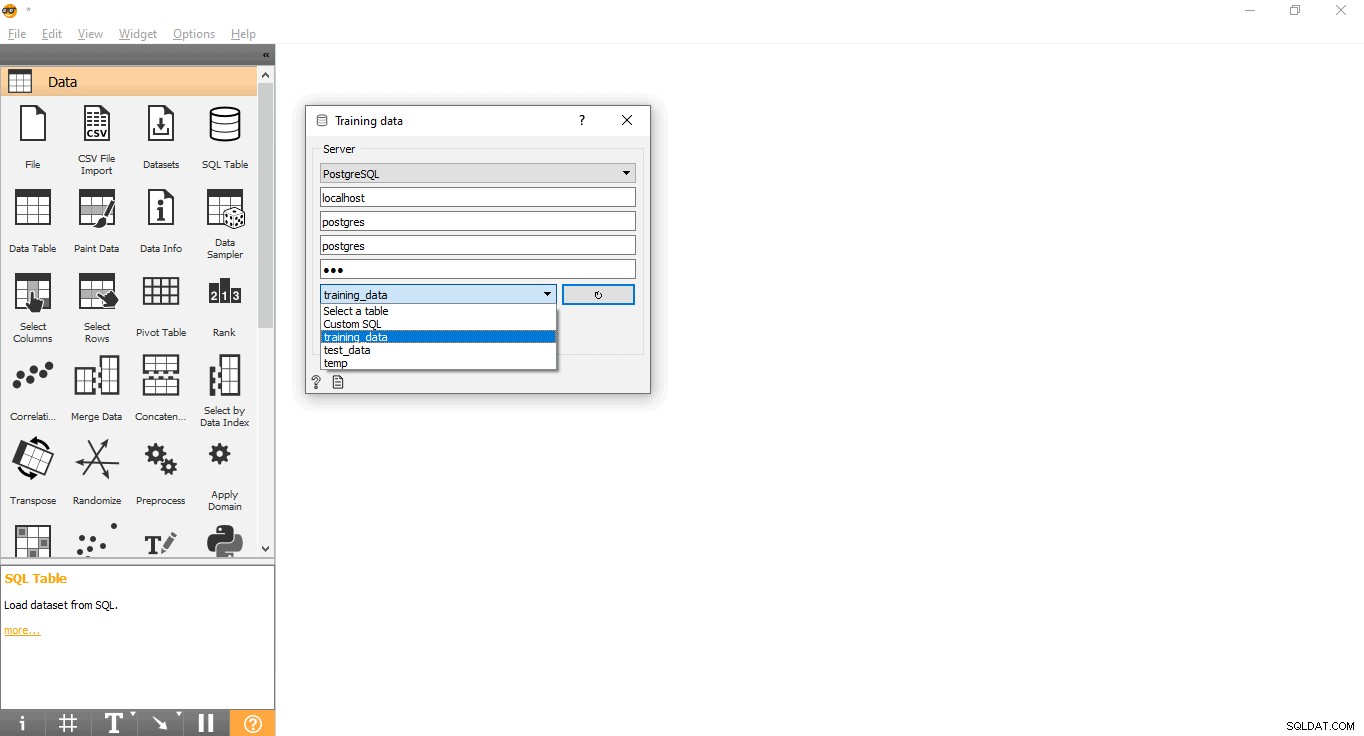
- Fai doppio clic sui Dati di allenamento widget.
- Inserisci le credenziali per connetterti al database PostgreSQL.
- Premi il pulsante di ricarica per caricare tutte le tabelle disponibili dal database specificato.
- Seleziona la tabella training_data dal menu a discesa e chiudi il pop-up.
Passaggio 5:aggiungi la colonna Target
Questo passaggio è importante perché il modello di Machine Learning proverà a prevedere i dati per questa variabile/colonna di destinazione:
- Trascina e rilascia Seleziona colonne widget dai dati menu.
- Fai doppio clic su Seleziona colonne widget.
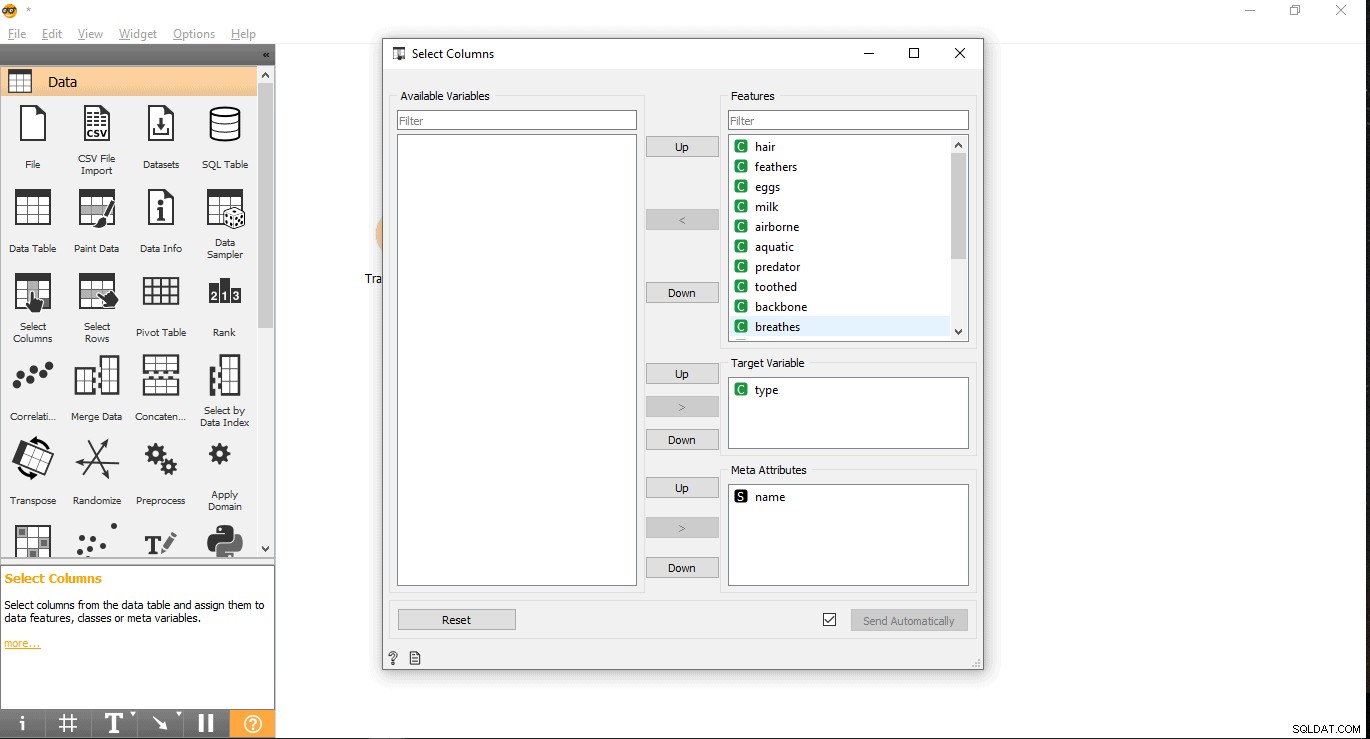
- Cerca la colonna di destinazione sotto l'etichetta Funzioni. Qui viene utilizzato tipo come variabile target perché dobbiamo vedere di che tipo è un determinato animale.
- Trascinalo e rilascialo sotto Variabile di destinazione casella e chiudi il pop-up.
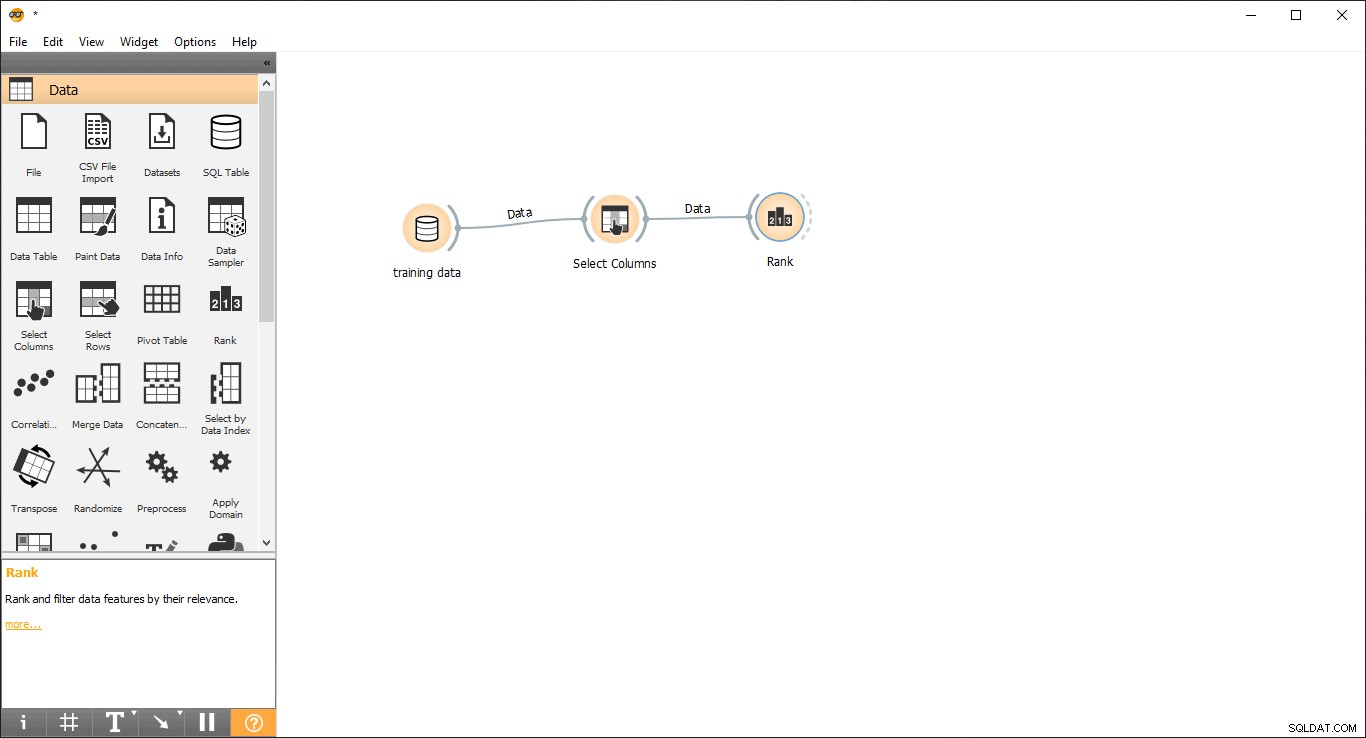
Fase 6:classifica delle colonne
Puoi classificare o valutare la variabile/colonne di allenamento in base alla loro correlazione con la colonna obiettivo.
- Trascina e rilascia Classifica widget dai dati menu.
- Disegna una linea di collegamento da Seleziona colonne widget per Classifica widget .
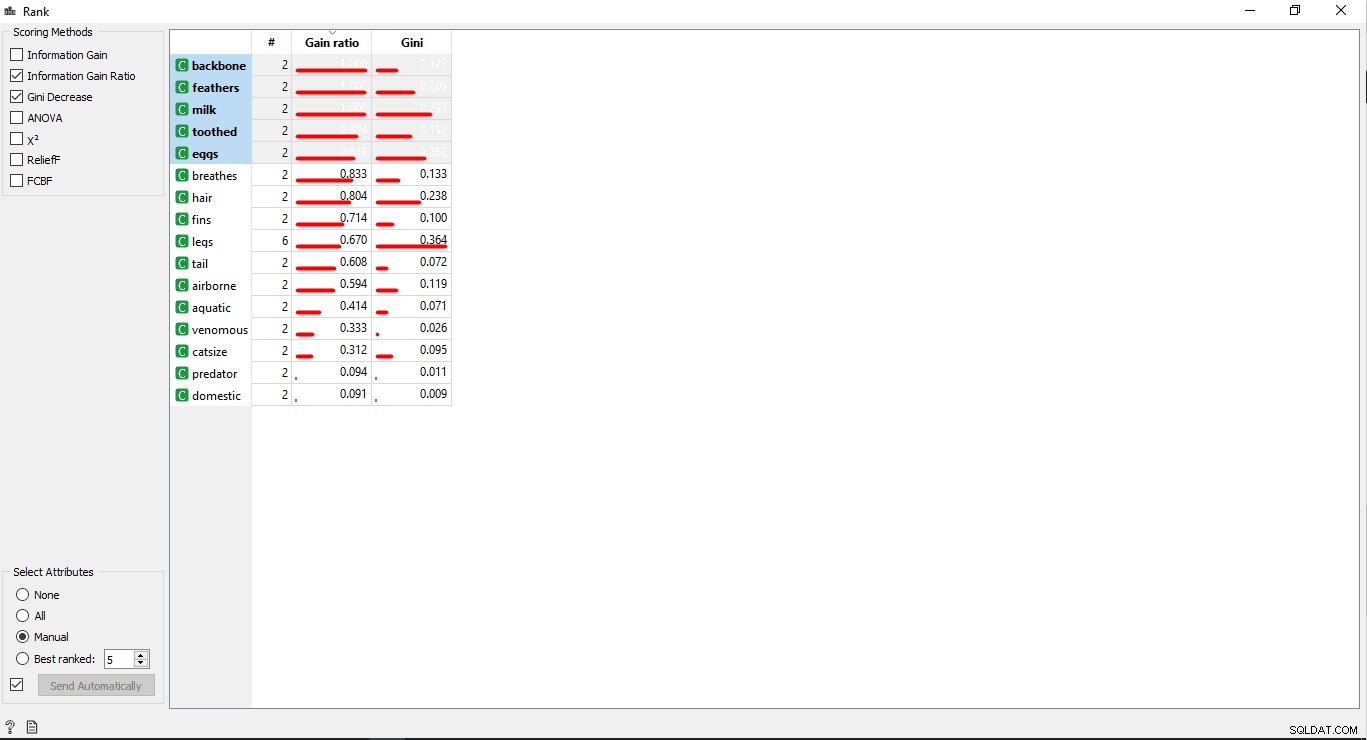
- Fai doppio clic su Classifica widget per visualizzare le colonne più correlate nella tabella dei dati di addestramento. Per impostazione predefinita, selezionerà le prime 5 colonne.
Fase 7:formazione sui dati
In questo passaggio, il modello di apprendimento automatico (KNN) verrà addestrato con il set di dati di addestramento. Si prega di seguire i seguenti passaggi:
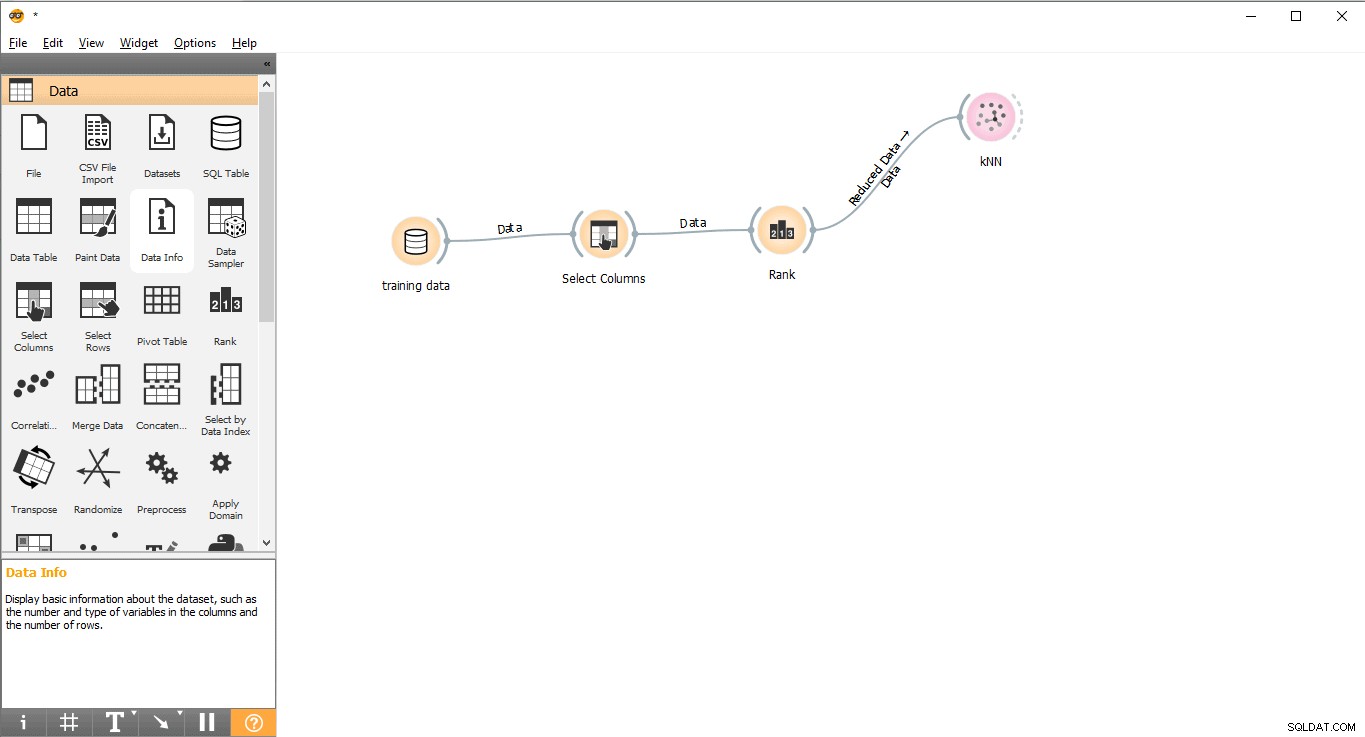
- Trascina e rilascia KNN widget dal Modello menu.
- Traccia una linea di collegamento da Rank widget su KNN widget.
Fase 8:carica il set di dati di test in PostgreSQL
Viene creato un set di dati di test separato per eseguire le previsioni. Segui i passaggi per caricare il set di dati di test nella tabella PostgreSQL.
- Crea una tabella per memorizzare i nostri dati di prova . Qui è chiamato test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Inserisci i dati del test nella tabella del test tramite COPIA interrogazione. Prima di eseguire COPIA query assicurati che PostgreSQL abbia richiesto i permessi di lettura sul file di dati, altrimenti l'operazione di COPIA fallirà.
NOTA: Assicurati di digitare una scheda spazio tra virgolette singole dopo il delimitatore parola chiave. Un punto interrogativo è inserito intenzionalmente nel tipo colonna del set di dati di test perché abbiamo bisogno di capire il tipo di un determinato animale con il nostro modello di Machine Learning.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Di seguito trovi lo screenshot del set di dati di test

Fase 9:importa i dati di test da PostgreSQL in Orange
Segui i seguenti passaggi per applicare le previsioni.
- Trascina e rilascia Tabella SQL widget dai dati menù.
- Rinomina widget (facoltativo)
- Fai clic con il pulsante destro del mouse sulla Tabella SQL widget.
- Seleziona Rinomina .
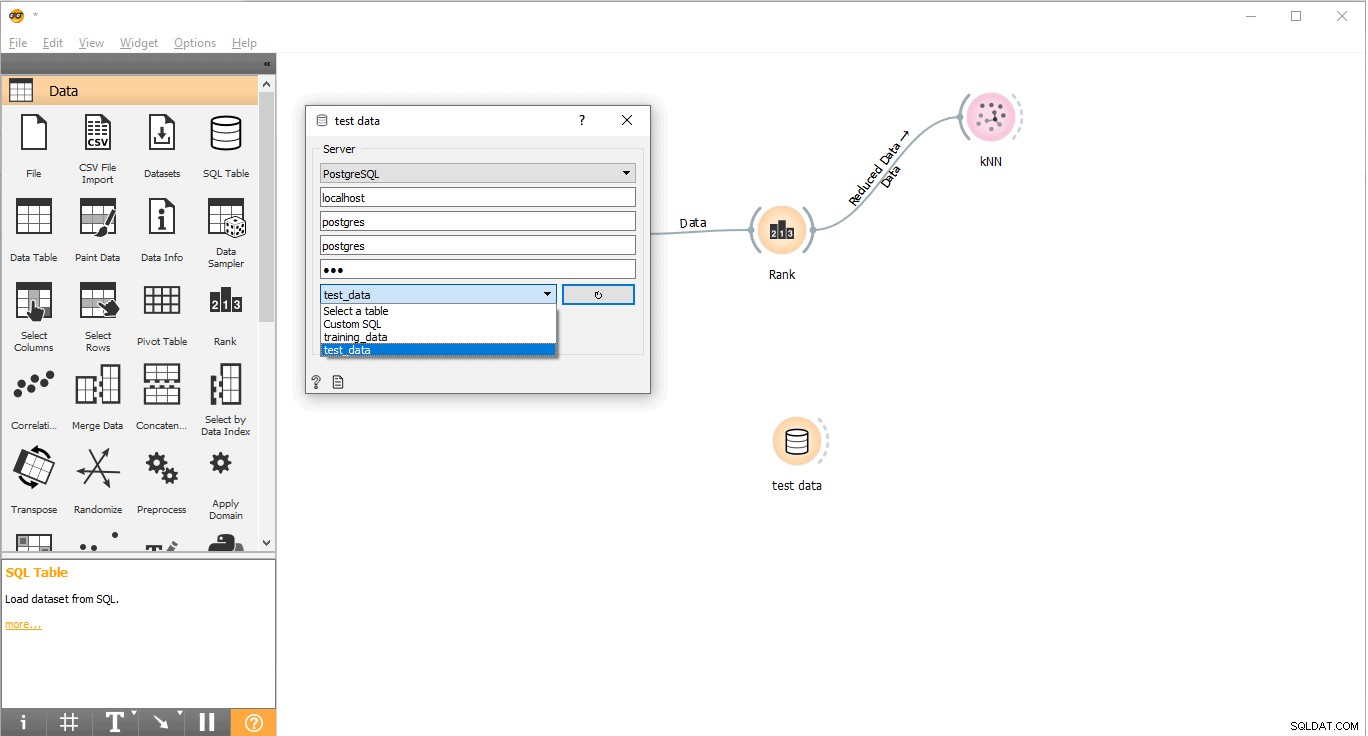
- Connettiti con PostgreSQL per caricare i dati di test.
- Fai doppio clic su Dati di prova widget.
- Collegalo a Dati di prova tabella da PostgreSQL.
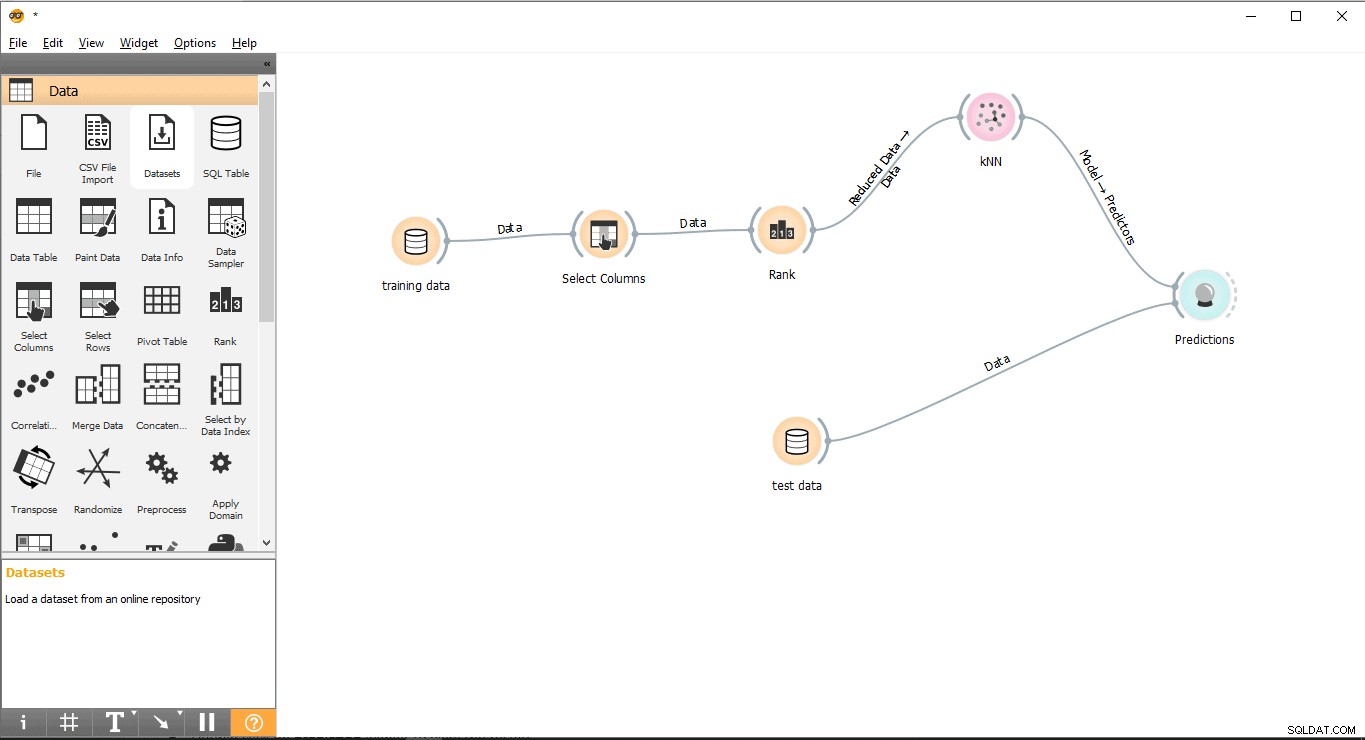
Ora siamo pronti per eseguire le previsioni.
Fase 10:Previsioni
Previsione il widget proverà a prevedere i dati del test in base ai dati di addestramento di KNN .
- Trascina e rilascia Previsione widget da Valuta menu.
- Disegna una linea di collegamento dal modulo Dati di prova widget per Previsione widget.
- Disegna una linea di collegamento da KNN widget per Previsione widget.
Fase 11:Risultati
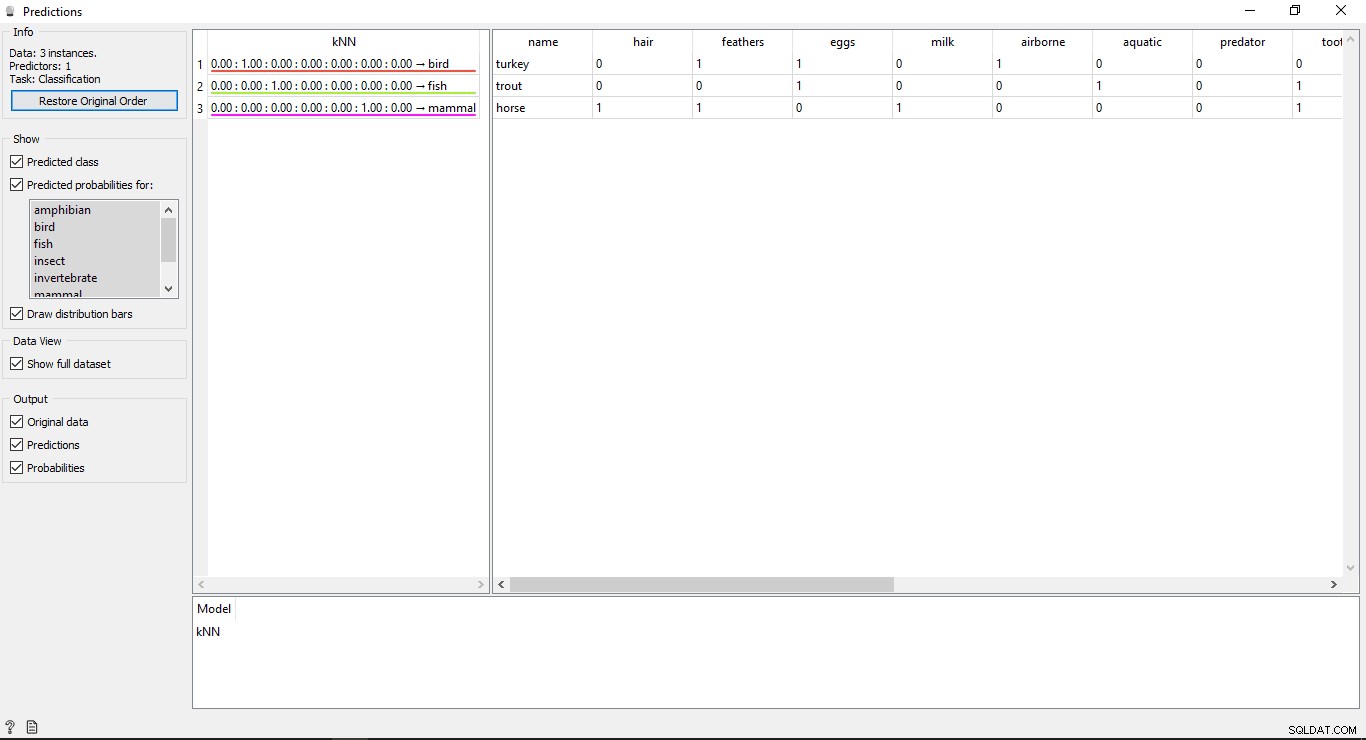
Fai doppio clic su Previsione widget per visualizzare i risultati.
Capire i risultati
Vedrai 2 tabelle principali nella finestra di previsione. La tabella a sinistra mostra i risultati previsti, mentre la tabella a destra mostra i dati del test originale, che sono stati forniti per le previsioni.
Dal KNN model è stato utilizzato per addestrare i dati in modo da visualizzare una colonna denominata KNN che elenca i risultati.
Come sappiamo:
- Cavallo è un mammifero
- Trota è un Pesce
- Turchia è un Uccello
Quindi KNN è in grado di determinare correttamente tutti i tipi.
Precisione delle previsioni
Se vedi la tabella sul lato sinistro nell'output del widget di previsione, ha alcuni numeri prima del tipo previsto, ad esempio 1,00. 0.00 Questi numeri mostrano l'accuratezza del tipo previsto.
Abbiamo utilizzato 7 tipi di animali nel set di dati di addestramento, quindi mostra un numero totale di 7 colonne con valori di precisione, ciascuna colonna rappresenterà 1 tipo di animale. Puoi controllare quale colonna rappresenta il tipo di animale osservando l'elenco disponibile sul lato sinistro dello schermo in Probabilità previste per etichetta. Se guardi la prima riga che dice Turchia è un Uccello . Possiamo vedere che la sua precisione è 1.00 (100% dalla 2a colonna). Lo stesso vale per altri esempi Trota è un Pesce e la sua precisione è 1,00 (100% dalla 3a colonna).
In questo articolo, abbiamo utilizzato l'algoritmo dei vicini più vicini (KNN) per implementare il modello di Machine Learning. Nel prossimo blog utilizzeremo la Support Vector Machine modello (SVM).
Per qualsiasi domanda o commento, ti preghiamo di contattarci utilizzando il modulo di contatto qui.