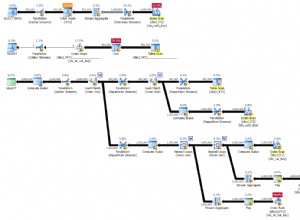
In precedenza avevo scritto un blog sull'unione a livello di partizione in PostgreSQL. In quel blog, avevo parlato di una tecnica avanzata di abbinamento delle partizioni che consentirà di utilizzare l'unione a livello di partizione in più casi. In questo blog parleremo in dettaglio di questa tecnica.
Per ricapitolare, la tecnica di base della corrispondenza delle partizioni consente di eseguire un'unione tra due tabelle partizionate utilizzando la tecnica di unione partizionata se le due tabelle partizionate hanno limiti di partizione esattamente corrispondenti, ad es. tabelle partizionate prt1 e prt2 descritte di seguito
psql> \d+ prt1
... [output clipped]
Partition key: RANGE (a)
Partitions: prt1_p1 FOR VALUES FROM (0) TO (5000),
prt1_p2 FOR VALUES FROM (5000) TO (15000),
prt1_p3 FOR VALUES FROM (15000) TO (30000)e
psql>\d+ prt2
... [ output clipped ]
Partition key: RANGE (b)
Partitions: prt2_p1 FOR VALUES FROM (0) TO (5000),
prt2_p2 FOR VALUES FROM (5000) TO (15000),
prt2_p3 FOR VALUES FROM (15000) TO (30000)Un join tra prt1 e prt2 sulla loro chiave di partizione (a) è suddiviso in join tra le partizioni corrispondenti, ad esempio prt1_p1 join prt2_p1, prt1_p2 join prt2_p2 e prt1_p3 join prt2_p3. I risultati di questi tre join insieme formano il risultato dell'unione tra prt1 e prt2. Questo ha molti vantaggi come discusso nel mio blog precedente. Tuttavia, la corrispondenza delle partizioni di base non può unire due tabelle partizionate con limiti di partizione diversi. Nell'esempio precedente, se prt1 ha una partizione aggiuntiva prt1_p4 PER VALORI DA (30000) A (50000), la corrispondenza della partizione di base non aiuterebbe a convertire un join tra prt1 e prt2 in un join a livello di partizione poiché non hanno una partizione esattamente corrispondente limiti.
Molte applicazioni utilizzano le partizioni per separare i dati utilizzati attivamente e i dati non aggiornati, una tecnica di cui ho discusso in un altro mio blog. I dati non aggiornati vengono infine rimossi eliminando le partizioni. Vengono create nuove partizioni per ospitare nuovi dati. Un join tra due di queste tabelle partizionate utilizzerà principalmente il join in termini di partizione poiché la maggior parte delle volte avranno partizioni corrispondenti. Ma quando una partizione attiva viene aggiunta a una di queste tabelle o una non aggiornata viene eliminata, i loro limiti di partizione non corrisponderanno fino a quando anche l'altra tabella non subirà un'operazione simile. Durante tale intervallo, un join tra queste due tabelle non utilizzerà il join in termini di partizione e potrebbe richiedere un tempo insolitamente più lungo per l'esecuzione. Non vogliamo che un join che colpisce il database durante questa breve durata abbia prestazioni scadenti poiché non può utilizzare il join a livello di partizione. L'algoritmo avanzato di corrispondenza delle partizioni aiuta in questo e in casi più complicati in cui i limiti delle partizioni non corrispondono esattamente.
Algoritmo avanzato di corrispondenza delle partizioni
La tecnica avanzata di corrispondenza delle partizioni trova le partizioni corrispondenti da due tabelle partizionate anche quando i loro limiti di partizione non corrispondono esattamente. Trova le partizioni corrispondenti confrontando i limiti di entrambe le tabelle nel loro ordine simile all'algoritmo di merge join. Due partizioni qualsiasi, una per ciascuna tabella partizionata, i cui limiti corrispondono esattamente o si sovrappongono sono considerate partner di unione poiché possono contenere righe di unione. Continuando con l'esempio sopra, supponiamo che una nuova partizione attiva prt2_p4 venga aggiunta a prt4. Le tabelle partizionate ora assomigliano a:
psql>\d+ prt1
... [output clipped]
Partition key: RANGE (a)
Partitions: prt1_p1 FOR VALUES FROM (0) TO (5000),
prt1_p2 FOR VALUES FROM (5000) TO (15000),
prt1_p3 FOR VALUES FROM (15000) TO (30000)e
psql>\d+ prt2
... [ output clipped ]
Partition key: RANGE (b)
Partitions: prt2_p1 FOR VALUES FROM (0) TO (5000),
prt2_p2 FOR VALUES FROM (5000) TO (15000),
prt2_p3 FOR VALUES FROM (15000) TO (30000),
prt2_p4 FOR VALUES FROM (30000) TO (50000)È facile vedere che i limiti di partizione di prt1_p1 e prt2_p1, prt1_p2 e prt2_p2 e prt1_p3 e prt2_p3 corrispondono rispettivamente. Ma a differenza della corrispondenza delle partizioni di base, la corrispondenza delle partizioni avanzate saprà che prt2_p4 non ha alcuna partizione corrispondente in prt1. Se il join tra prt1 e prt2 è un join INNER o quando prt2 è una relazione INNER nel join, il risultato del join non avrà alcuna riga da prt2_p4. Abilitato con informazioni dettagliate sulle partizioni corrispondenti e sulle partizioni che non corrispondono, rispetto al semplice fatto che i limiti della partizione corrispondono o meno, Query Optimizer può decidere se utilizzare o meno il join a livello di partizione. In questo caso, sceglierà di eseguire il join come join tra le partizioni corrispondenti lasciando da parte prt2_p4. Ma non è molto simile a una corrispondenza di partizione "avanzata". Vediamo un caso un po' più complicato usando questa volta le tabelle partizionate dell'elenco:
psql>\d+ plt1
Partition key: LIST (c)
Partitions: plt1_p1 FOR VALUES IN ('0001', '0003'),
plt1_p2 FOR VALUES IN ('0004', '0006'),
plt1_p3 FOR VALUES IN ('0008', '0009')e
psql>\d+ plt2
Partition key: LIST (c)
Partitions: plt2_p1 FOR VALUES IN ('0002', '0003'),
plt2_p2 FOR VALUES IN ('0004', '0006'),
plt2_p3 FOR VALUES IN ('0007', '0009')Osservare che ci sono esattamente tre partizioni in entrambe le relazioni, ma gli elenchi di valori di partizione differiscono. L'elenco corrispondente alla partizione plt1_p2 corrisponde esattamente a quello di plt2_p2. A parte questo, nessuna delle due partizioni, una per lato, ha elenchi esattamente corrispondenti. L'algoritmo avanzato di corrispondenza delle partizioni deduce che plt1_p1 e plt2_p1 hanno elenchi sovrapposti e che i loro elenchi non si sovrappongono a nessun'altra partizione dall'altra relazione. Allo stesso modo per plt1_p3 e plt2_p3. Query Optimizer vede quindi che il join tra plt1 e plt2 può essere eseguito come join a livello di partizione unendo le partizioni corrispondenti, ad esempio plt1_p1 e plt2_p1, plt1_p2 e plt2_p2 e plt1_p3 e plt2_p3 rispettivamente. L'algoritmo può trovare partizioni corrispondenti in insiemi di elenchi legati a partizioni ancora più complessi, nonché in tabelle con partizioni di intervalli. Ma non li tratteremo per brevità. I lettori interessati e più audaci possono dare un'occhiata al commit. Ha anche molti test case, che mostrano vari scenari in cui viene utilizzato l'algoritmo avanzato di corrispondenza delle partizioni.
Limiti
Collegamenti esterni con partizioni corrispondenti mancanti sul lato interno
I join esterni pongono un problema particolare nel mondo PostgreSQL. Si consideri prt2 LEFT JOIN prt1, nell'esempio precedente, dove prt2 è una relazione OUTER. prt2_p4 non ha un partner di join in prt1 e tuttavia le righe in quella partizione dovrebbero far parte del risultato del join poiché appartengono alla relazione esterna. In PostgreSQL, quando il lato INNER di un join è vuoto, è rappresentato da una relazione "fittizia" che non emette righe ma conosce ancora lo schema di quella relazione. Di solito una relazione "fittizia" emerge da una relazione non fittizia che non emetterà alcuna riga a causa di alcune ottimizzazioni di query come l'esclusione di vincoli. L'ottimizzatore di query di PostgreSQL contrassegna una relazione non fittizia come fittizia e l'esecutore procede normalmente durante l'esecuzione di tale join. Ma quando non esiste una partizione interna corrispondente per una partizione esterna, non esiste "entità esistente" che può essere contrassegnata come "fittizia". Ad esempio, in questo caso non esiste prt1_p4 che possa rappresentare una partizione interna fittizia che unisce prt2_p4 esterno. In questo momento, PostgreSQL non ha un modo per "creare" tali relazioni "fittizie" durante la pianificazione. Pertanto, in questo caso Query Optimizer non utilizza il join a livello di partizione.
Idealmente un tale join con interno vuoto richiede solo lo schema della relazione interna e non un'intera relazione. Questo schema può essere derivato dalla tabella partizionata stessa. Tutto ciò di cui ha bisogno è la capacità di produrre la riga di join utilizzando le colonne di una riga nel lato esterno unite da valori NULL per le colonne dal lato interno. Una volta che avremo questa capacità in PostgreSQL, Query Optimizer sarà in grado di utilizzare l'unione partizionata anche in questi casi.
Consentitemi di sottolineare che i join esterni in cui non ci sono partizioni mancanti sul join interno utilizzano il join in termini di partizione.
Più partizioni corrispondenti
Quando le tabelle sono partizionate in modo tale che più partizioni da un lato corrispondano a una o più partizioni dall'altro lato, non è possibile utilizzare il join per partizione poiché non c'è modo di indurre una relazione "Aggiungi" durante il tempo di pianificazione che rappresenti due o più partizioni insieme. Speriamo di rimuovere anche questa limitazione a volte e consentire l'utilizzo del join in base alla partizione anche in questi casi.
Tabelle partizionate hash
I limiti di partizione di due tabelle partizionate hash che utilizzano lo stesso modulo corrispondono sempre. Quando il modulo è diverso, una riga di una determinata partizione di una tabella può avere i suoi partner di unione in molte partizioni dell'altra, quindi una determinata partizione da un lato corrisponde a più partizioni dell'altra tabella, rendendo inefficace il join a livello di partizione.
Quando l'algoritmo avanzato di corrispondenza delle partizioni non riesce a trovare partizioni corrispondenti o non è possibile utilizzare il join in base alle partizioni a causa delle limitazioni di cui sopra, PostgreSQL ricorre per unire le tabelle partizionate come tabelle normali.
Tempo di corrispondenza delle partizioni avanzato
Simon ha sollevato un punto interessante quando ha commentato la funzione. Le partizioni di una tabella partizionata non cambiano spesso, quindi il risultato della corrispondenza avanzata delle partizioni dovrebbe rimanere lo stesso per una durata maggiore. Non è necessario calcolarlo ogni volta che viene eseguita una query che coinvolge queste tabelle. Invece potremmo salvare l'insieme delle partizioni corrispondenti in qualche catalogo e aggiornarlo ogni volta che le partizioni cambiano. Questo è un po' di lavoro, ma vale la pena spendere il tempo speso per abbinare la partizione per ogni query.
Nonostante tutte queste limitazioni, quella che abbiamo oggi è una soluzione molto utile che serve la maggior parte dei casi pratici. Inutile dire che questa funzione funziona perfettamente con FDW join push down migliorando le capacità di sharding che PostgreSQL ha già!