Questa è la seconda puntata di una serie in due parti su repmgr di 2ndQuadrant, uno strumento open source ad alta disponibilità per PostgreSQL.
Nella prima parte, abbiamo impostato un cluster PostgreSQL 12 a tre nodi insieme a un nodo "testimone". Il cluster era costituito da un nodo primario e due nodi standby. Il cluster e il nodo di controllo sono stati ospitati in un Amazon Web Service Virtual Private Cloud (VPC). I server EC2 che ospitano le istanze Postgres sono stati collocati in sottoreti in diverse zone di disponibilità (AZ), come mostrato di seguito:
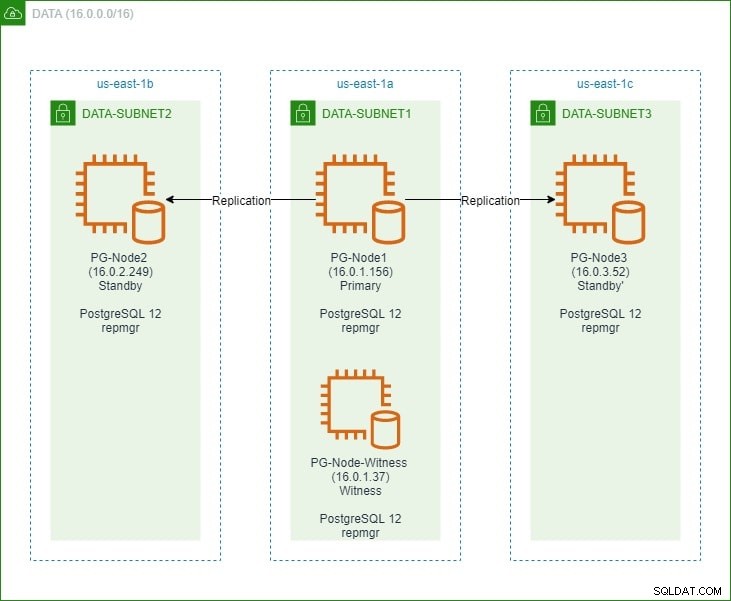
Faremo ampi riferimenti ai nomi dei nodi e ai loro indirizzi IP, quindi ecco di nuovo la tabella con i dettagli dei nodi:
| Nome nodo | Indirizzo IP | Ruolo | App in esecuzione |
| PG-Nodo1 | 16.0.1.156 | Principale | PostgreSQL 12 e repmgr |
| PG-Nodo2 | 16.0.2.249 | Standby 1 | PostgreSQL 12 e repmgr |
| PG-Nodo3 | 16.0.3.52 | Standby 2 | PostgreSQL 12 e repmgr |
| Testimone del nodo PG | 16.0.1.37 | Testimone | PostgreSQL 12 e repmgr |
Abbiamo installato repmgr nei nodi primario e standby e quindi registrato il nodo primario con repmgr. Abbiamo quindi clonato entrambi i nodi di standby dal primario e li abbiamo avviati. Entrambi i nodi standby sono stati registrati anche con repmgr. Il comando "repmgr cluster show" ci ha mostrato che tutto funzionava come previsto:

Problema attuale
Configurare la replica in streaming con repmgr è molto semplice. Quello che dobbiamo fare dopo è garantire che il cluster funzioni anche quando il primario non è disponibile. Questo è ciò di cui parleremo in questo articolo.
Nella replica PostgreSQL, un primario può diventare non disponibile per alcuni motivi. Ad esempio:
- Il sistema operativo del nodo primario può bloccarsi o non rispondere
- Il nodo primario può perdere la connettività di rete
- Il servizio PostgreSQL nel nodo primario può arrestarsi in modo anomalo, interrompersi o diventare non disponibile in modo imprevisto
- Il servizio PostgreSQL nel nodo primario può essere interrotto intenzionalmente o accidentalmente
Ogni volta che un primario diventa non disponibile, uno standby non si autopromuove automaticamente al ruolo di primo piano. Uno standby continua ancora a servire query di sola lettura, sebbene i dati saranno aggiornati fino all'ultimo LSN ricevuto dal primario. Qualsiasi tentativo di scrittura avrà esito negativo.
Ci sono due modi per mitigare questo:
- Lo standby è manualmente aggiornato a ruolo primario. Questo è solitamente il caso di un failover o "passaggio" pianificato
- Lo standby è automaticamente promosso a ruolo primario. Questo è il caso degli strumenti non nativi che monitorano continuamente la replica e intraprendono azioni di ripristino quando il primario non è disponibile. repmgr è uno di questi strumenti.
Considereremo qui il secondo scenario. Questa situazione presenta però alcune sfide extra:
- Se ci sono più di uno standby, in che modo lo strumento (o gli standby) decide quale deve essere promosso come principale? Come funzionano il quorum e il processo di promozione?
- Per più standby, se uno viene reso primario, in che modo gli altri nodi iniziano a "seguirlo" come nuovo primario?
- Cosa succede se il primario funziona, ma per qualche motivo si stacca temporaneamente dalla rete? Se uno degli standby viene promosso a primario e poi il primario originale torna online, come si può evitare una situazione di "cervello diviso"?
Risposta di remgr:il nodo testimone e il demone repmgr
Per rispondere a queste domande, repmgr usa qualcosa chiamato nodo testimone . Quando il primario non è disponibile, è compito del nodo di controllo aiutare gli standbys a raggiungere il quorum se uno di loro deve essere promosso a ruolo primario. Gli standby raggiungono questo quorum determinando se il nodo primario è effettivamente offline o solo temporaneamente non disponibile. Il nodo di controllo deve trovarsi nello stesso centro dati/segmento di rete/sottorete del nodo primario, ma non deve MAI essere eseguito sullo stesso host fisico del nodo primario.
Ricorda che nella prima parte di questa serie abbiamo implementato un nodo di controllo nella stessa zona di disponibilità e sottorete del nodo primario. L'abbiamo chiamato PG-Node-Witness e lì abbiamo installato un'istanza PostgreSQL 12. In questo post installeremo repmgr anche lì, ma ne parleremo più avanti.
Il secondo componente della soluzione è il demone repmgr (repmgrd) in esecuzione in tutti i nodi del cluster e del nodo di controllo. Ancora una volta, non abbiamo avviato questo demone nella prima parte di questa serie, ma lo faremo qui. Il daemon fa parte del pacchetto repmgr:quando abilitato, viene eseguito come un servizio regolare e monitora continuamente lo stato del cluster. Avvia un failover quando viene raggiunto un quorum relativo all'essere offline del principale. Non solo può promuovere automaticamente uno standby, ma può anche riavviare altri standby in un cluster multinodo per seguire il nuovo primario .
Il processo del quorum
Quando uno standby si rende conto che non può vedere il primario, si consulta con altri standby. Tutti gli standby in esecuzione nel cluster raggiungono il quorum per scegliere un nuovo primario utilizzando una serie di controlli:
- Ogni standby interroga gli altri standby sull'ultima volta che ha "visto" il primario. Se l'ultimo LSN replicato di uno standby o l'ora dell'ultima comunicazione con il primario è più recente dell'ultimo LSN replicato del nodo corrente o dell'ora dell'ultima comunicazione, il nodo non fa nulla e attende il ripristino della comunicazione con il primario
- Se nessuno degli standbys può vedere il primario, controlla se il nodo di controllo è disponibile. Se non è possibile raggiungere neanche il nodo di controllo, gli standbys presumono che si sia verificata un'interruzione della rete sul lato primario e non procedono alla scelta di un nuovo primario
- Se è possibile raggiungere il testimone, gli standbys presumono che il primario sia inattivo e procedono alla scelta di un primario
- Il nodo che è stato configurato come primario "preferito" verrà quindi promosso. Ogni standby avrà la sua replica reinizializzata per seguire il nuovo primario.
Configurazione del cluster per il failover automatico
Ora configureremo il cluster e il nodo di controllo per il failover automatico.
Passaggio 1:installa e configura repmgr in Witness
Abbiamo già visto come installare il pacchetto repmgr nel nostro ultimo articolo. Lo facciamo anche nel nodo di controllo:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
E poi:
# yum install repmgr12 -y
Successivamente, aggiungiamo le seguenti righe nel file postgresql.conf del nodo di controllo:
listen_addresses ='*'shared_preload_libraries ='repmgr'
Aggiungiamo anche le seguenti righe nel file pg_hba.conf nel nodo di controllo. Nota come stiamo utilizzando l'intervallo CIDR del cluster invece di specificare singoli indirizzi IP.
replica locale Repmgr TRUSTHOST Replication Repmgr 127.0.0.1/32 TRUSTHOST Replication Repmgr 16.0.0.0/16 Trustlocal Repmgr Repmgr Trusthost Repmgr 127.0.0.0.1/32 TRUSTHOST RepMgr 16.0.0.0.016 FiduciaNota
[I passaggi qui descritti sono solo a scopo dimostrativo. Il nostro esempio qui utilizza IP raggiungibili esternamente per i nodi. L'utilizzo di listen_address ='*' insieme al meccanismo di sicurezza "trust" di pg_hba rappresenta quindi un rischio per la sicurezza e NON dovrebbe essere utilizzato in scenari di produzione. In un sistema di produzione, i nodi saranno tutti all'interno di una o più sottoreti private, raggiungibili tramite IP privati da jumphost.]
Dopo aver apportato le modifiche a postgresql.conf e pg_hba.conf, creiamo l'utente repmgr e il database repmgr nel testimone e cambiamo il percorso di ricerca predefinito dell'utente repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$ createb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"Infine, aggiungiamo le seguenti righe al file repmgr.conf, che si trova in /etc/repmgr/12/
id_nodo =4nome_nodo ='Testimone del nodo PG'conninfo ='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'directory_dati ='/var/lib/pgsql/12/data'Una volta impostati i parametri di configurazione, riavviamo il servizio PostgreSQL nel nodo di controllo:
# systemctl riavvia postgresql-12.servicePer testare la connettività al nodo testimone repmgr, possiamo eseguire questo comando dal nodo primario:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'Successivamente, registriamo il nodo testimone con repmgr eseguendo il comando "repmgr testimone register" come utente postgres. Nota come stiamo usando l'indirizzo del primario node e NON il nodo di controllo nel comando seguente:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf registro dei testimoni -h 16.0.1.156Questo perché il comando "repmgr testimone register" aggiunge i metadati del nodo di controllo al database repmgr del nodo primario e, se necessario, inizializza il nodo di controllo installando l'estensione repmgr e copiando i metadati di repmgr nel nodo di controllo.
L'output sarà simile a questo:
INFO:connessione al nodo di controllo "PG-Node-Witness" (ID:4)INFO:connessione al nodo principaleAVVISO:tentativo di installazione dell'estensione "repmgr"AVVISO:estensione "repmgr" installata correttamenteINFO:registrazione del testimone completo AVVISO:nodo di controllo "PG-Node-Witness" (ID:4) riuscito registratoInfine, controlliamo lo stato della configurazione generale da qualsiasi nodo:
[esempio@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf mostra cluster --compactL'output è simile a questo:
Fase 2:modifica del file sudoers
Con il cluster e il testimone in esecuzione, aggiungiamo le seguenti righe nel file sudoers In ogni nodo del cluster e del nodo di controllo:
Default:postgres !requirettypostgres ALL =NOPASSWD:/usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl riavvia postgresql-12.service , /usr/bin/systemctl ricarica postgresql-12.service, /usr/bin/systemctl avvia repmgr12.service, /usr/bin/systemctl interrompe repmgr12.serviceFase 3:configurazione dei parametri repmgrd
Abbiamo già aggiunto quattro parametri nel file repmgr.conf in ogni nodo. I parametri aggiunti sono quelli di base necessari per il funzionamento di repmgr. Per abilitare il demone repmgr e il failover automatico, è necessario abilitare/aggiungere una serie di altri parametri. Nelle seguenti sottosezioni, descriveremo ciascun parametro e il valore su cui verranno impostati in ciascun nodo.
failover
Il parametro di failover è uno dei parametri obbligatori per il demone repmgr. Questo parametro indica al demone se deve avviare un failover automatico quando viene rilevata una situazione di failover. Può avere uno dei due valori:“manuale” o “automatico”. Lo imposteremo su automatico in ogni nodo:
failover ='automatico'promo_comando
Questo è un altro parametro obbligatorio per il demone repmgr. Questo parametro dice al demone repmgr quale comando dovrebbe eseguire per promuovere uno standby. Il valore di questo parametro sarà in genere il comando "repmgr standby promuovere" o il percorso di uno script di shell che chiama il comando. Per il nostro caso d'uso, lo impostiamo come segue in ogni nodo:
promozione_comando ='/usr/pgsql-12/bin/repmgr standby promuovere -f /etc/repmgr/12/repmgr.conf --log-to-file'segui_comando
Questo è il terzo parametro obbligatorio per il demone repmgr. Questo parametro indica a un nodo di standby di seguire il nuovo primario. Il demone repmgr sostituisce il segnaposto %n con l'ID nodo della nuova primaria in fase di esecuzione:
follow_command ='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'priorità
Il parametro priority aggiunge peso all'idoneità di un nodo a diventare primario. L'impostazione di questo parametro su un valore più alto conferisce a un nodo una maggiore idoneità a diventare il nodo principale. Inoltre, l'impostazione di questo valore su zero per un nodo garantirà che il nodo non venga mai promosso come primario.
Nel nostro caso d'uso, abbiamo due standby:PG-Node2 e PG-Node3. Vogliamo promuovere PG-Node2 come nuovo primario quando PG-Node1 va offline e PG-Node3 per seguire PG-Node2 come nuovo primario. Impostiamo il parametro sui seguenti valori nei due nodi standby:

| Nome nodo | Impostazione parametri |
| PG-Nodo2 | priorità =60 |
| PG-Nodo3 | priorità =40 |
monitor_interval_secs
Questo parametro dice al demone repmgr con quale frequenza (in numero di secondi) dovrebbe controllare la disponibilità del nodo upstream. Nel nostro caso, esiste un solo nodo a monte:il nodo primario. Il valore predefinito è 2 secondi, ma lo imposteremo comunque in modo esplicito in ogni nodo:
monitor_interval_secs =2
tipo_controllo_connessione
Il parametro connection_check_type determina il protocollo che il demone repmgr utilizzerà per raggiungere il nodo upstream. Questo parametro può assumere tre valori:
- ping :repmgr usa il metodo PQPing()
- connessione :repmgr tenta di creare una nuova connessione al nodo upstream
- interroga :repmgr tenta di eseguire una query SQL sul nodo upstream utilizzando la connessione esistente
Ancora una volta, imposteremo questo parametro sul valore predefinito di ping in ciascun nodo:
tipo_controllo_connessione ='ping'
reconnect_attempts e reconnect_interval
Quando il primario diventa non disponibile, il daemon repmgr nei nodi di standby tenterà di riconnettersi al primario per i tempi di reconnect_attempts. Il valore predefinito per questo parametro è 6. Tra ogni tentativo di riconnessione, attenderà reconnect_interval secondi, che ha un valore predefinito di 10. A scopo dimostrativo, utilizzeremo un breve intervallo e un minor numero di tentativi di riconnessione. Impostiamo questo parametro in ogni nodo:
reconnect_attempts =4intervallo_riconnessione =8
primary_visibility_consensus
Quando il primario diventa non disponibile in un cluster a più nodi, gli standby possono consultarsi per creare un quorum su un failover. Questo viene fatto chiedendo a ogni standby l'ultima volta che ha visto il primario. Se l'ultima comunicazione di un nodo è stata molto recente e successiva al momento in cui il nodo locale ha visto il primario, il nodo locale presume che il primario sia ancora disponibile e non prende una decisione di failover.
Per abilitare questo modello di consenso, il parametro primary_visibility_consensus deve essere impostato su "true" in ogni nodo, incluso il testimone:
primary_visibility_consensus =vero
standby_disconnect_on_failover
Quando il parametro standby_disconnect_on_failover è impostato su "true" in un nodo standby, il daemon repmgr assicurerà che il suo ricevitore WAL sia disconnesso dal primario e non riceva alcun segmento WAL. Attenderà inoltre che i ricevitori WAL di altri nodi standby si fermino prima di prendere una decisione di failover. Questo parametro deve essere impostato sullo stesso valore in ogni nodo. Lo stiamo impostando su "true".
standby_disconnect_on_failover =vero
L'impostazione di questo parametro su true significa che ogni nodo di standby ha smesso di ricevere dati dal primario quando si verifica il failover. Il processo avrà un ritardo di 5 secondi più il tempo impiegato dal ricevitore WAL per arrestarsi prima che venga presa una decisione di failover. Per impostazione predefinita, il demone repmgr attenderà 30 secondi per confermare che tutti i nodi di pari livello abbiano smesso di ricevere segmenti WAL prima che si verifichi il failover.
repmgrd_service_start_command e repmgrd_service_stop_command
Questi due parametri specificano come avviare e arrestare il demone repmgr utilizzando i comandi “repmgr daemon start” e “repmgr daemon stop”.
Fondamentalmente, questi due comandi sono wrapper attorno ai comandi del sistema operativo per avviare/arrestare il servizio. I due valori di parametro associano questi comandi alle loro versioni specifiche del sistema operativo. Impostiamo questi parametri sui seguenti valori in ogni nodo:
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
Comandi di avvio/arresto/riavvio del servizio PostgreSQL
Come parte del suo funzionamento, il demone repmgr dovrà spesso arrestare, avviare o riavviare il servizio PostgreSQL. Per garantire che ciò avvenga senza problemi, è meglio specificare i comandi del sistema operativo corrispondenti come valori di parametro nel file repmgr.conf. A questo scopo imposteremo quattro parametri in ciascun nodo:
comando_avvio_servizio ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl riavvia postgresql-12.service'service_reload_command ='sudo /usr/bin/systemctl ricarica postgresql-12.service'
cronologia_monitoraggio
L'impostazione del parametro monitoring_history su "yes" garantirà che repmgr salvi i dati di monitoraggio del cluster. Lo impostiamo su "yes" in ogni nodo:
Cronologia_di_monitoraggio =sì
log_status_interval
Impostiamo il parametro in ogni nodo per specificare la frequenza con cui il demone repmgr registrerà un messaggio di stato. In questo caso, lo impostiamo ogni 60 secondi:
log_status_interval =60
Fase 4:avvio del demone repmgr
Con i parametri ora impostati nel cluster e nel nodo di controllo, eseguiamo un dry run del comando per avviare il demone repmgr. Lo testiamo prima nel nodo primario, quindi nei due nodi standby, seguiti dal nodo testimone. Il comando deve essere eseguito come utente postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
L'output dovrebbe essere simile a questo:
INFO:soddisfatti i prerequisiti per l'avvio di repmgrd DETTAGLIO:verrebbe eseguito il seguente comando: sudo /usr/bin/systemctl start repmgr12.service
Successivamente, avviamo il demone in tutti e quattro i nodi:
[esempio@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf inizio del demone
L'output in ogni nodo dovrebbe mostrare che il demone è stato avviato:
AVVISO:esecuzione:"sudo /usr/bin/systemctl start repmgr12.service"AVVISO:repmgrd è stato avviato correttamente
Possiamo anche controllare l'evento di avvio del servizio dai nodi primari o di standby:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf evento cluster --event=repmgrd_start
L'output dovrebbe mostrare che il demone sta monitorando le connessioni:
ID nodo | Nome | Evento | OK | Timestamp | Dettagli--------+---+---------------+----+- --------------------+---------------- -------------------------------------4 | Testimone del nodo PG | repmgrd_start | t | 2020-02-05 11:37:31 | monitoraggio della connessione al nodo primario "PG-Node1" (ID:1) 3 | PG-Nodo3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoraggio della connessione al nodo upstream "PG-Node1" (ID:1) 2 | PG-Nodo2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoraggio della connessione al nodo upstream "PG-Node1" (ID:1) 1 | PG-Nodo1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoraggio del cluster primario "PG-Node1" (ID:1)
Infine, possiamo controllare l'output del demone dal syslog in qualsiasi standby:
# cat /var/log/messages | grep repmgr | meno
Ecco l'output da PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [AVVISO] utilizzando il file di configurazione fornito "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [AVVISO] repmgrd (repmgrd 5.0.0) avvio Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] connessione al database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"Feb 5 11:37:24 PG-Node3 systemd[1]:repmgr12.service:impossibile aprire il file PID /run/repmgr/repmgrd-12.pid (ancora?) dopo l'avvio:nessun file o directory di questo tipoFeb 5 11:37 :24 PG-Node3 repmgrd[2014]:INFO: set_repmgrd_pid():il file pid fornito è /run/repmgr/repmgrd-12.pid 5 feb 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [AVVISO] avvio del monitoraggio del nodo "PG-Node3" (ID:3) 5 feb 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] "connection_check_type" impostato su "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] monitoraggio della connessione al nodo upstream "PG-Node1" (ID:1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [INFO] nodo "PG-Node3" (ID:3) monitoraggio del nodo a monte "PG- Nodo1" (ID:1) in stato normale Feb 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [DETAIL] l'ultimo aggiornamento delle statistiche di monitoraggio risale a 2 secondi fa Feb 5 11:39:26 PG-Node3 repmgrd[2014]:[2020-02-05 11:39:26] [INFO] nodo "PG-Node3" (ID:3) monitoraggio del nodo a monte "PG- Nodo1" (ID:1) in stato normale ... ...
Il controllo del syslog nel nodo primario mostra un diverso tipo di output:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [AVVISO] utilizzando il file di configurazione fornito "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [AVVISO] repmgrd (repmgrd 5.0.0) avvio Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] connessione al database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [AVVISO] avvio del monitoraggio del nodo "PG-Node1" (ID:1) 5 feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] "connection_check_type" impostato su "ping" 5 feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [AVVISO] cluster di monitoraggio primario "PG-Node1" (ID:1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] il nodo figlio "PG-Node-Witness" (ID:4) non è ancora allegatoFeb 5 11 :37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] il nodo figlio "PG-Node3" (ID:3) è allegato 5 feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] il nodo figlio "PG-Node2" (ID:2) è allegato 5 febbraio 11:37:32 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:32] [AVVISO] il nuovo testimone "PG-Node-Witness" (ID:4) si è connesso Feb 5 11:38:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:38:14] [INFO] monitoraggio del nodo primario "PG-Node1" (ID:1) in stato normale Feb 5 11:39:15 PG-Node1 repmgrd[2017]:[2020-02-05 11:39:15] [INFO] monitoraggio del nodo primario "PG-Node1" (ID:1) in stato normale ... ...
Fase 5:simulazione di una primaria fallita
Ora simuleremo un primario guasto arrestando il nodo primario (PG-Node1). Dal prompt della shell del nodo, eseguiamo il seguente comando:
# systemctl interrompe postgresql-12.service
Il processo di failover
Una volta interrotto il processo, attendiamo circa un minuto o due, quindi controlliamo il file syslog di PG-Node2. Vengono visualizzati i seguenti messaggi. Per chiarezza e semplicità, abbiamo gruppi di messaggi codificati per colore e aggiunti spazi bianchi tra le righe:
... 5 febbraio 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [AVVISO] impossibile eseguire il ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"Feb 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [ DETTAGLIO] PQping() ha restituito "PQPING_NO_RESPONSE" 5 feb 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [INFO] dorme 8 secondi fino al prossimo tentativo di riconnessione 5 feb 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] verifica dello stato del nodo 1, 2 di 4 tentativi Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [AVVISO] impossibile eseguire il ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [ DETTAGLIO] PQping() ha restituito "PQPING_NO_RESPONSE" 5 feb 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] dorme 8 secondi fino al prossimo tentativo di riconnessione 5 feb 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] verifica dello stato del nodo 1, 3 di 4 tentativi 5 feb 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [AVVISO] impossibile eseguire il ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"Feb 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [ DETTAGLIO] PQping() ha restituito "PQPING_NO_RESPONSE" 5 feb 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] dorme 8 secondi fino al prossimo tentativo di riconnessione 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] verifica dello stato del nodo 1, 4 di 4 tentativi 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] impossibile eseguire il ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [ DETTAGLIO] PQping() ha restituito "PQPING_NO_RESPONSE" 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] impossibile riconnettersi al nodo 1 dopo 4 tentativi 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] impostando "wal_retrieve_retry_interval" su 86405000 millisecondi 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] ricevitore wal non in esecuzione 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] Ricevitore WAL disconnesso su tutti i nodi di pari livello 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] Ricevitore WAL disconnesso su tutti e 2 i nodi di pari livello 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] lsn di ricezione dell'ultimo nodo locale:0/2214A000 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] verifica dello stato del nodo di pari livello "PG-Node3" (ID:3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] il nodo "PG-Node3" (ID:3) segnala che il suo upstream è il nodo 1 , visto l'ultima volta 26 secondi fa 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] nodo 3 ultimo nodo primario visto 26 secondo(i) fa Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] l'ultima ricezione LSN per il nodo di pari livello "PG-Node3" (ID:3) è :0/2214A000 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] il nodo "PG-Node3" (ID:3) ha lo stesso LSN del candidato attuale "PG-Nodo2" (ID:2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] il nodo "PG-Node3" (ID:3) ha una priorità inferiore (40) rispetto all'attuale candidato "PG-Node2" (ID:2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] verifica dello stato del nodo di pari livello "PG-Node-Witness" (ID:4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] il nodo "PG-Node-Witness" (ID:4) segnala che il suo upstream è nodo 1, visto l'ultima volta 26 secondi fa 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] nodo 4 ultimo nodo primario visto 26 secondo(i) fa 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] nodi visibili:3; nodi totali:3; nessun nodo ha visto il primario negli ultimi 4 secondi ……Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] il candidato alla promozione è "PG-Node2" (ID:2) 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] impostando "wal_retrieve_retry_interval" su 5000 ms 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] questo nodo è il vincitore, ora si promuoverà e informerà gli altri nodi …… 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] promozione dello standby a primario 5 feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [DETAIL] promozione del server "PG-Node2" (ID:2) using pg_promote() 5 febbraio 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVVISO] in attesa fino a 60 secondi (parametro "promote_check_timeout") per il completamento della promozione 5 feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [AVVISO] PROMOZIONE STANDBY riuscita Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] Il server [DETAIL] "PG-Node2" (ID:2) è stato promosso correttamente a primario 5 febbraio 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] 2 follower da notificare 5 feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [AVVISO] notifica al nodo "PG-Node3" (ID:3) di seguire il nodo 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [AVVISO] notifica al nodo "PG-Node-Witness" (ID:4) di seguire il nodo 2 5 febbraio 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] passaggio alla modalità di monitoraggio principale 5 feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [AVVISO] cluster di monitoraggio primario "PG-Node2" (ID:2) 5 febbraio 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [AVVISO] il nuovo testimone "PG-Node-Witness" (ID:4) si è connesso Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [AVVISO] nuovo standby "PG-Node3" (ID:3) si è connesso Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [AVVISO] nuovo standby "PG-Node3" (ID:3) connessoFeb 5 11:55:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:55:02] [INFO] monitoraggio del nodo primario "PG-Node2" (ID:2) in stato normale Feb 5 11:56:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:56:02] [INFO] monitoraggio del nodo primario "PG-Node2" (ID:2) in stato normale … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
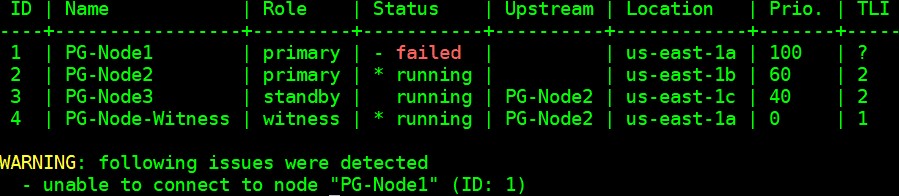
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
Conclusione
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1