Sono stato a lungo un sostenitore della scelta del tipo di dati corretto. Ho parlato di alcuni esempi in un precedente post sul blog "Cattive abitudini", ma questo fine settimana a SQL Saturday #162 (Cambridge, Regno Unito), l'argomento dell'utilizzo di DATETIME per impostazione predefinita è venuto fuori. In una conversazione dopo la mia presentazione su T-SQL:Cattive abitudini e migliori pratiche, un utente ha dichiarato di usare semplicemente DATETIME anche se hanno bisogno della granularità solo al minuto o al giorno, in questo modo le colonne di data/ora all'interno dell'azienda sono sempre dello stesso tipo di dati. Ho suggerito che questo potrebbe essere uno spreco e che la coerenza potrebbe non valerne la pena, ma oggi ho deciso di provare a dimostrare la mia teoria.
TL;versione DR
I miei test di seguito rivelano che ci sono sicuramente scenari in cui potresti prendere in considerazione l'utilizzo di un tipo di dati più magro invece di attenersi a DATETIME ovunque. Ma è importante vedere dove i miei test per questo puntano dall'altra parte, ed è anche importante testare questi scenari rispetto al tuo schema, nel tuo ambiente, con hardware e dati che siano il più fedeli possibile alla produzione. I tuoi risultati possono variare, e quasi sicuramente varieranno.
Le tabelle di destinazione
Consideriamo il caso in cui la granularità è importante solo per la giornata (non ci interessano ore, minuti, secondi). Per questo potremmo scegliere DATETIME (come proposto dall'utente), o SMALLDATETIME o DATE su SQL Server 2008+. Ci sono anche due diversi tipi di dati che ho voluto prendere in considerazione:
- Dati che verrebbero inseriti approssimativamente in sequenza in tempo reale (es. eventi che stanno accadendo proprio ora);
- Dati che verrebbero inseriti casualmente (es. date di nascita dei nuovi membri).
Ho iniziato con 2 tabelle come la seguente, quindi ne ho create altre 4 (2 per SMALLDATETIME, 2 per DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime ( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL ); CREATE TABLE dbo.EventsSequential_Datetime ( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL ); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt); CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Then repeat for DATE and SMALLDATETIME.
E il mio obiettivo era testare le prestazioni dell'inserimento batch in questi due modi diversi, nonché l'impatto sulle dimensioni e sulla frammentazione dello spazio di archiviazione complessive e, infine, sulle prestazioni delle query di intervallo.
Dati di esempio
Per generare alcuni dati di esempio, ho usato una delle mie pratiche tecniche per generare qualcosa di significativo da qualcosa che non lo è:le viste del catalogo. Sul mio sistema questo ha restituito 971 valori di data/ora distinti (1.000.000 di righe in tutto) in circa 12 secondi:
;WITH y AS
(
SELECT TOP (1000000) d = DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101'))
FROM
(
SELECT s1.[object_id] % 1000
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x(x) ORDER BY NEWID()
)
SELECT DISTINCT d FROM y; Ho inserito questi milioni di righe in una tabella in modo da poter simulare inserimenti sequenziali/casuali utilizzando metodi di accesso diversi per gli stessi identici dati da tre diverse finestre di sessione:
CREATE TABLE dbo.Staging
(
ID INT IDENTITY(1,1) PRIMARY KEY,
source_date DATETIME NOT NULL
);
;WITH Staging_Data AS
(
SELECT TOP (1000000) dt = DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101'))
FROM
(
SELECT s1.[object_id] % 1000
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS sd(x) ORDER BY NEWID()
)
INSERT dbo.Staging(source_date)
SELECT dt
FROM y
ORDER BY dt; Il completamento di questo processo ha richiesto un po' più di tempo (20 secondi). Quindi ho creato una seconda tabella per memorizzare gli stessi dati ma distribuiti in modo casuale (in modo da poter ripetere la stessa distribuzione su tutti gli inserti).
CREATE TABLE dbo.Staging_Random ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL ); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Query per popolare le tabelle
Successivamente, ho scritto una serie di query per popolare le altre tabelle con questi dati, utilizzando tre finestre di query per simulare almeno un po' di concorrenza:
WAITFOR TIME '13:53';
GO
DECLARE @d DATETIME2 = SYSDATETIME();
INSERT dbo.{table_name}(dt) -- depending on method / data type
SELECT source_date
FROM dbo.Staging[_Random] -- depending on destination
WHERE ID % 3 = <0,1,2> -- depending on query window
ORDER BY ID;
SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Come nel mio ultimo post, ho pre-espanso il database per evitare che qualsiasi tipo di evento di crescita automatica dei file di dati interferisse con i risultati. Mi rendo conto che non è del tutto realistico eseguire inserimenti di milioni di righe in un passaggio, poiché non posso impedire l'interferenza dell'attività del registro per una transazione così grande, ma dovrebbe farlo in modo coerente in ogni metodo. Dato che l'hardware con cui sto testando è completamente diverso dall'hardware che stai utilizzando, i risultati assoluti non dovrebbero essere un elemento chiave, ma solo il confronto relativo.
(In un test futuro lo proverò anche con batch reali provenienti da file di registro con dati relativamente misti e utilizzando blocchi della tabella di origine in loop:penso che anche quelli sarebbero esperimenti interessanti. E ovviamente aggiungendo compressione nel mix.)
I risultati:
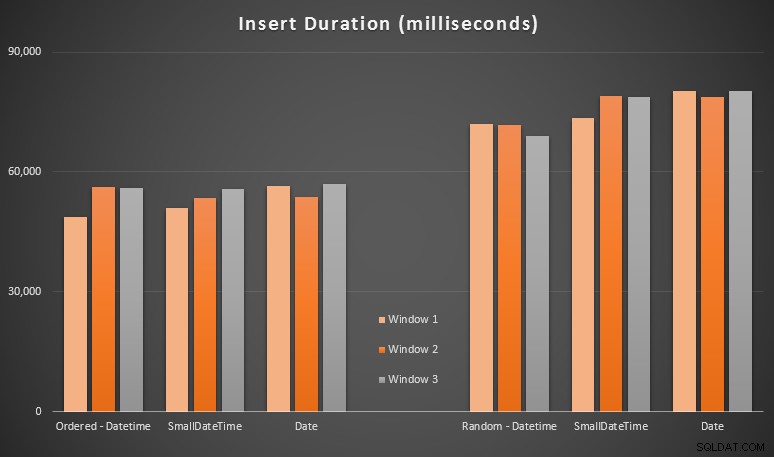
Questi risultati non sono stati poi così sorprendenti per me:l'inserimento in ordine casuale ha portato a tempi di esecuzione più lunghi rispetto all'inserimento sequenziale, qualcosa che tutti possiamo riportare alle nostre radici nella comprensione di come funzionano gli indici in SQL Server e di come possono verificarsi più divisioni di pagina "cattive" in questo scenario (non ho monitorato specificamente le divisioni di pagina in questo esercizio, ma è qualcosa che prenderò in considerazione nei test futuri).
Ho notato che, sul lato casuale, le conversioni implicite sui dati in entrata potrebbero aver avuto un impatto sui tempi, dal momento che sembravano un po' più alte rispetto al nativo DATETIME -> DATETIME inserti. Quindi ho deciso di creare due nuove tabelle contenenti dati di origine:una che utilizza DATE e uno che utilizza SMALLDATETIME . Ciò simulerebbe, in una certa misura, la corretta conversione del tipo di dati prima di passarlo all'istruzione di inserimento, in modo tale che non sia richiesta una conversione implicita durante l'inserimento. Ecco le nuove tabelle e come sono state popolate:
CREATE TABLE dbo.Staging_Random_SmallDatetime ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL ); CREATE TABLE dbo.Staging_Random_Date ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL ); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Questo non ha avuto l'effetto che speravo:i tempi erano simili in tutti i casi. Quindi è stato un inseguimento selvaggio.
Spazio utilizzato e frammentazione
Ho eseguito la seguente query per determinare quante pagine erano riservate per ciascuna tabella:
SELECT name = 'dbo.' + OBJECT_NAME([object_id]), pages = SUM(reserved_page_count) FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id]) ORDER BY pages;
I risultati:
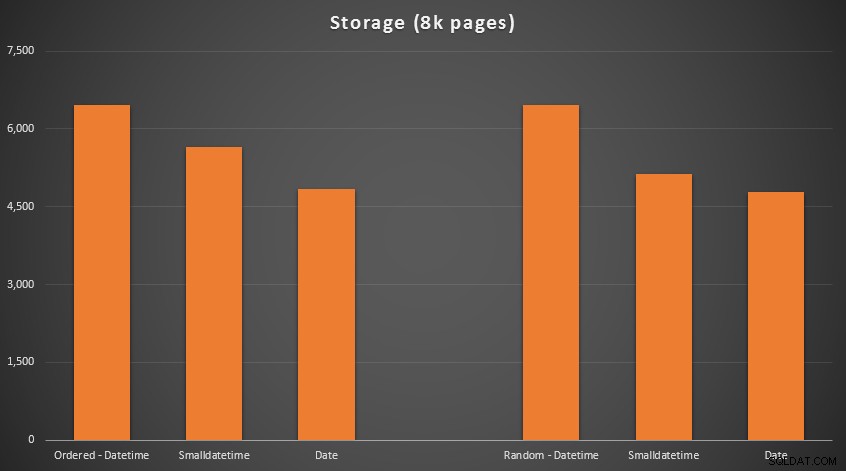
Nessuna scienza missilistica qui; usa un tipo di dati più piccolo, dovresti usare meno pagine. Passaggio da DATETIME a DATE ha prodotto costantemente una riduzione del 25% del numero di pagine utilizzate, mentre SMALLDATETIME ha ridotto il requisito del 13-20%.
Ora per la frammentazione e la densità di pagina sugli indici non in cluster (c'era pochissima differenza per gli indici in cluster):
SELECT '{table_name}',
index_id
avg_page_space_used_in_percent,
avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID(), OBJECT_ID('{table_name}'),
NULL, NULL, 'DETAILED'
)
WHERE index_level = 0 AND index_id = 2; Risultati:
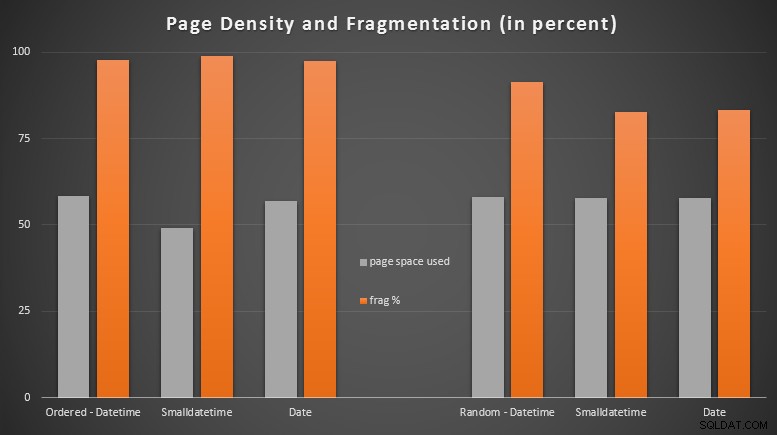
Sono rimasto abbastanza sorpreso di vedere che i dati ordinati sono diventati quasi completamente frammentati, mentre i dati inseriti casualmente hanno effettivamente finito con un utilizzo della pagina leggermente migliore. Ho preso nota del fatto che ciò giustifica ulteriori indagini al di fuori dell'ambito di questi test specifici, ma potrebbe essere qualcosa che vorrai controllare se hai indici non cluster che si basano su inserti in gran parte sequenziali.
[Una ricostruzione online degli indici non cluster su tutte e 6 le tabelle è stata eseguita in 7 secondi, riportando la densità delle pagine all'intervallo del 99,5% e riducendo la frammentazione a meno dell'1%. Ma non l'ho eseguito fino a quando non ho eseguito i test di query di seguito...]
Test della query sull'intervallo
Infine, volevo vedere l'impatto sui tempi di esecuzione per semplici query di intervallo di date rispetto ai diversi indici, sia con la frammentazione intrinseca causata dall'attività di scrittura di tipo OLTP, sia su un indice pulito che viene ricostruito. La query stessa è piuttosto semplice:
SELECT TOP (200000) dt
FROM dbo.{table_name}
WHERE dt >= '20110101'
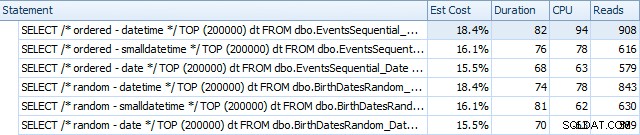
ORDER BY dt; Di seguito sono riportati i risultati prima della ricostruzione degli indici, utilizzando SQL Sentry Plan Explorer:
E differiscono leggermente dopo le ricostruzioni:
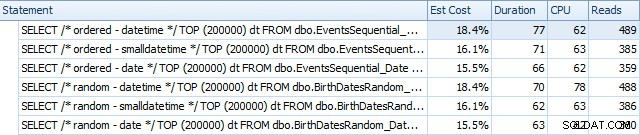
In sostanza vediamo una durata e letture leggermente superiori per le versioni DATETIME, ma pochissima differenza nella CPU. E le differenze tra SMALLDATETIME e DATE sono trascurabili in confronto. Tutte le query avevano piani di query semplicistici come questo:

(La ricerca è, ovviamente, una scansione di intervallo ordinata.)
Conclusione
Mentre è vero che questi test sono piuttosto fabbricati e avrebbero potuto beneficiare di più permutazioni, mostrano più o meno ciò che mi aspettavo di vedere:gli impatti maggiori su questa scelta specifica sono sullo spazio occupato dall'indice non cluster (dove la scelta di un tipo di dati più magro certamente vantaggio) e sul tempo necessario per eseguire inserimenti in ordine arbitrario, anziché sequenziale (dove DATETIME ha solo un margine marginale).
Mi piacerebbe sentire le tue idee su come sottoporre scelte di tipo di dati come queste a test più approfonditi e punitivi. Ho intenzione di entrare più nel dettaglio nei post futuri.