Una delle tante nuove funzionalità introdotte in SQL Server 2008 è stata la compressione dei dati. La compressione a livello di riga o di pagina offre l'opportunità di risparmiare spazio su disco, con il compromesso di richiedere un po' più di CPU per comprimere e decomprimere i dati. Si sostiene spesso che la maggior parte dei sistemi sono legati all'IO, non alla CPU, quindi ne vale la pena. La presa? Dovevi essere su Enterprise Edition per usare la compressione dei dati. Con il rilascio di SQL Server 2016 SP1, le cose sono cambiate! Se esegui l'edizione standard di SQL Server 2016 SP1 e versioni successive, ora puoi usare la compressione dei dati. C'è anche una nuova funzione integrata per la compressione, COMPRESS (e la sua controparte DECOMPRESS). La compressione dei dati non funziona su dati fuori riga, quindi se nella tabella è presente una colonna come NVARCHAR(MAX) con valori di dimensioni generalmente superiori a 8000 byte, i dati non verranno compressi (grazie Adam Machanic per quel promemoria) . La funzione COMPRESS risolve questo problema e comprime i dati fino a 2 GB di dimensione. Inoltre, anche se direi che la funzione dovrebbe essere utilizzata solo per dati fuori riga di grandi dimensioni, ho pensato che confrontarla direttamente con la compressione di righe e pagine fosse un esperimento utile.
CONFIGURAZIONE
Per i dati di test, sto lavorando da uno script che Aaron Bertrand ha utilizzato in precedenza, ma ho apportato alcune modifiche. Ho creato un database separato per il test, ma è possibile utilizzare tempdb o un altro database di esempio, quindi ho iniziato con una tabella Customers con tre colonne NVARCHAR. Ho pensato di creare colonne più grandi e di popolarle con stringhe di lettere ripetute, ma l'utilizzo di testo leggibile fornisce un esempio più realistico e quindi fornisce una maggiore precisione.
Nota: Se sei interessato a implementare la compressione e vuoi sapere in che modo influirà sull'archiviazione e sulle prestazioni nel tuo ambiente, CONSIGLIO VIVAMENTE DI PROVARLA. Ti sto dando la metodologia con dati di esempio; implementarlo nel tuo ambiente non dovrebbe comportare lavoro aggiuntivo.
Noterai di seguito che dopo aver creato il database stiamo abilitando Query Store. Perché creare una tabella separata per provare a tenere traccia delle nostre metriche delle prestazioni quando possiamo semplicemente utilizzare le funzionalità integrate in SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Ora imposteremo alcune cose all'interno del database:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Con la tabella creata, aggiungeremo alcuni dati, ma stiamo aggiungendo 5 milioni di righe invece di 1 milione. L'esecuzione sul mio laptop richiede circa otto minuti.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Ora creeremo altre tre tabelle:una per la compressione delle righe, una per la compressione delle pagine e una per la funzione COMPRESS. Si noti che con la funzione COMPRESS, è necessario creare le colonne come tipi di dati VARBINARY. Di conseguenza, nella tabella non sono presenti indici non cluster (poiché non è possibile creare una chiave di indice su una colonna varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Quindi copieremo i dati da [dbo].[Customers] alle altre tre tabelle. Questo è un INSERT diretto per le nostre tabelle di pagine e righe e impiega circa due o tre minuti per ogni INSERT, ma c'è un problema di scalabilità con la funzione COMPRESS:provare a inserire 5 milioni di righe in un colpo solo non è ragionevole. Lo script seguente inserisce le righe in batch di 50.000 e inserisce solo 1 milione di righe anziché 5 milioni. Lo so, questo significa che non siamo veramente mele per mele qui per il confronto, ma sono d'accordo con quello. L'inserimento di 1 milione di righe richiede 10 minuti sulla mia macchina; sentiti libero di modificare lo script e inserire 5 milioni di righe per i tuoi test.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Con tutte le nostre tabelle popolate, possiamo fare un controllo delle dimensioni. A questo punto non abbiamo implementato la compressione ROW o PAGE, ma è stata utilizzata la funzione COMPRESS:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
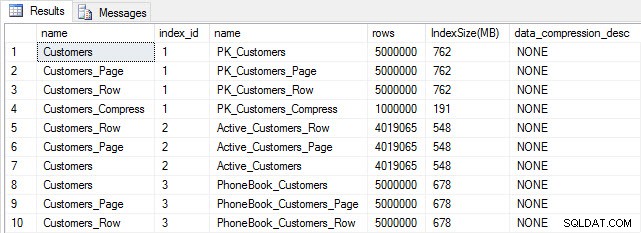 Dimensioni tabella e indice dopo l'inserimento
Dimensioni tabella e indice dopo l'inserimento
Come previsto, tutte le tabelle tranne Customers_Compress hanno all'incirca le stesse dimensioni. Ora ricostruiremo gli indici su tutte le tabelle, implementando la compressione di riga e pagina rispettivamente su Customers_Row e Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Se controlliamo le dimensioni della tabella dopo la compressione, ora possiamo vedere i nostri risparmi di spazio su disco:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
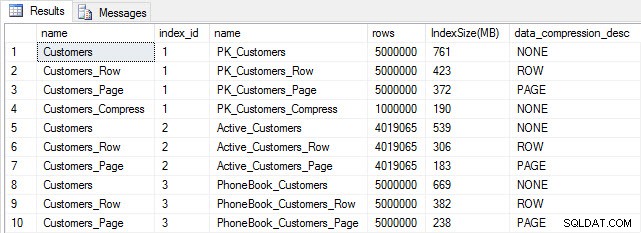
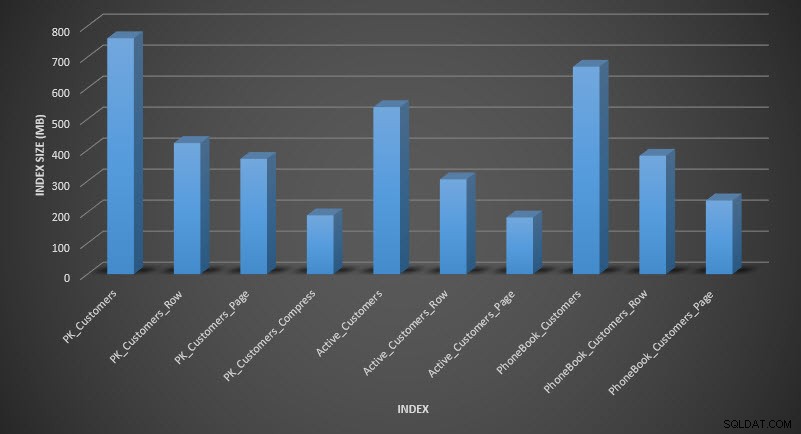 Dimensione dell'indice dopo la compressione
Dimensione dell'indice dopo la compressione
Come previsto, la compressione di righe e pagine riduce notevolmente le dimensioni della tabella e dei relativi indici. La funzione COMPRESS ci ha fatto risparmiare più spazio:l'indice cluster è un quarto delle dimensioni della tabella originale.
ESAME DELLE PRESTAZIONI DELLA QUERY
Prima di testare le prestazioni delle query, tieni presente che possiamo utilizzare Query Store per esaminare le prestazioni di INSERT e REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
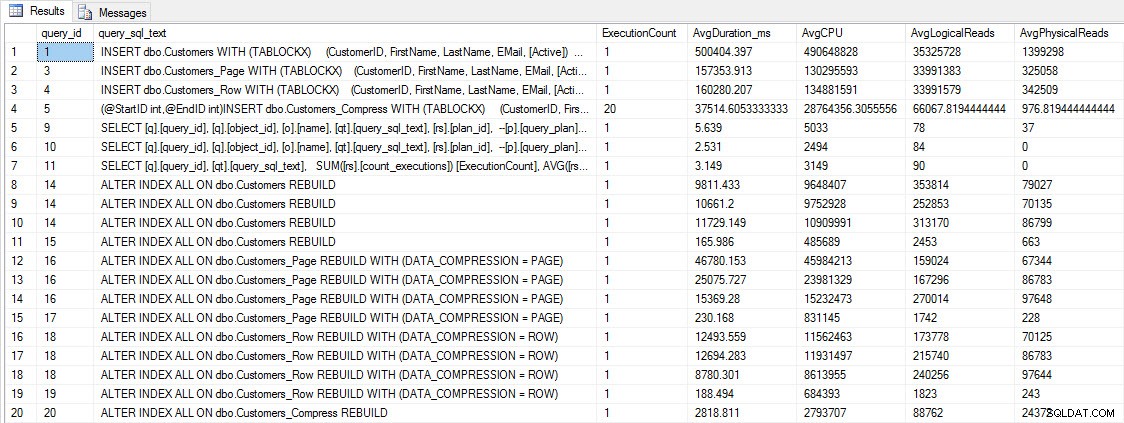 INSERIRE e RICOSTRUIRE le metriche delle prestazioni
INSERIRE e RICOSTRUIRE le metriche delle prestazioni
Sebbene questi dati siano interessanti, sono più curioso di sapere come la compressione influisce sulle mie query SELECT quotidiane. Ho un set di tre stored procedure ciascuna con una query SELECT, in modo che venga utilizzato ogni indice. Ho creato queste procedure per ogni tabella e quindi ho scritto uno script per estrarre i valori per il nome e il cognome da utilizzare per il test. Ecco lo script per creare le procedure.
Una volta create le stored procedure, possiamo eseguire lo script seguente per chiamarle. Inizia e poi aspetta un paio di minuti...
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Dopo qualche minuto, dai un'occhiata a cosa c'è in Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Vedrai che la maggior parte delle stored procedure è stata eseguita solo 20 volte perché due procedure contro [dbo].[Customers_Compress] sono veramente Lento. Questa non è una sorpresa; né [FirstName] né [LastName] sono indicizzati, quindi qualsiasi query dovrà eseguire la scansione della tabella. Non voglio che queste due query rallentino i miei test, quindi modificherò il carico di lavoro e commenterò EXEC [dbo].[usp_FindActiveCustomer_CS] ed EXEC [dbo].[usp_FindAnyCustomer_CS] e quindi riavviarlo. Questa volta, lo lascerò funzionare per circa 10 minuti e quando guardo di nuovo l'output di Query Store, ora ho dei buoni dati. I numeri grezzi sono sotto, con i grafici preferiti dal manager sotto.
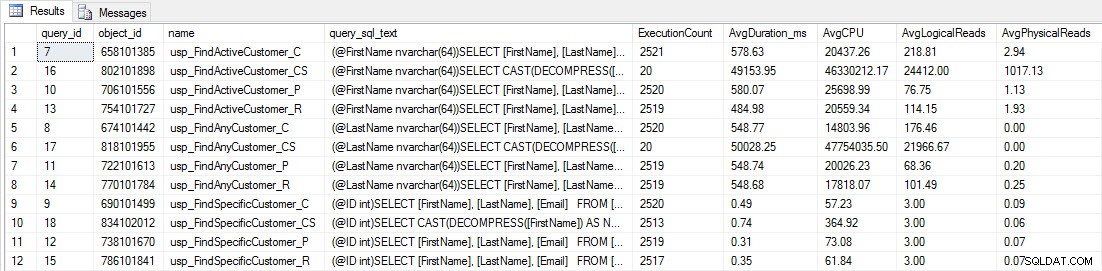 Dati sulle prestazioni da Query Store
Dati sulle prestazioni da Query Store
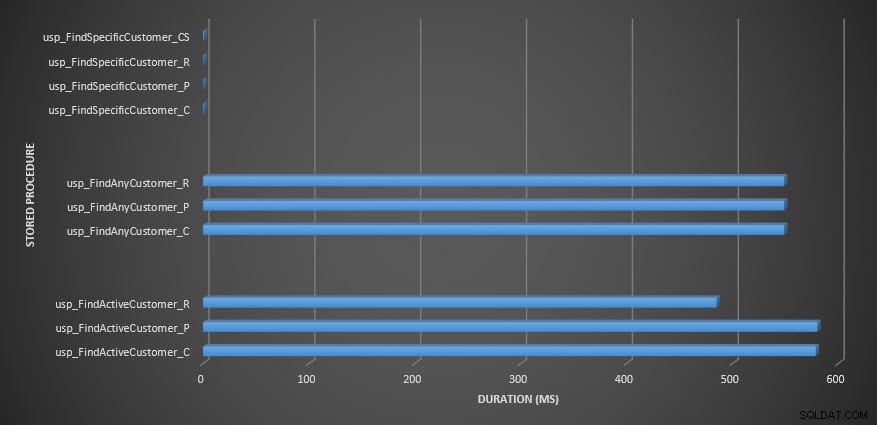 Durata della stored procedure
Durata della stored procedure
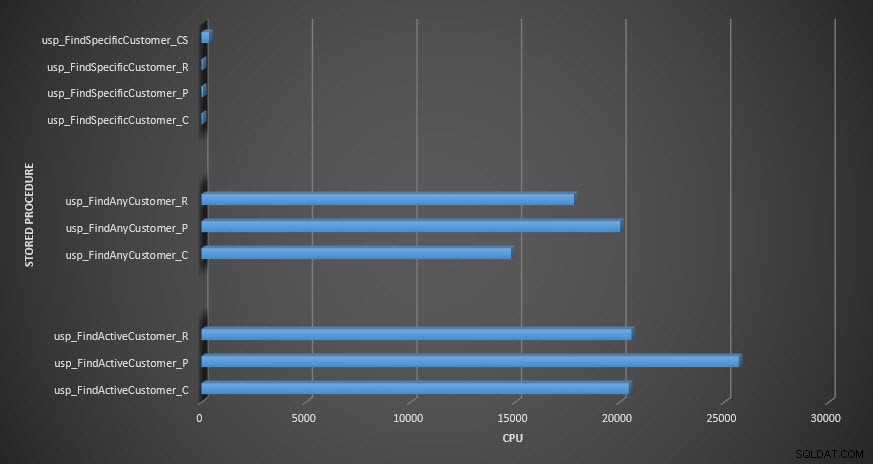 CPU con procedura memorizzata
CPU con procedura memorizzata
Promemoria:tutte le stored procedure che terminano con _C provengono dalla tabella non compressa. Le procedure che terminano con _R sono la tabella compressa di riga, quelle che terminano con _P sono compresse di pagina e quella con _CS utilizza la funzione COMPRESS (ho rimosso i risultati per detta tabella per usp_FindAnyCustomer_CS e usp_FindActiveCustomer_CS poiché hanno distorto il grafico così tanto che abbiamo perso il differenze nel resto dei dati). Le procedure usp_FindAnyCustomer_* e usp_FindActiveCustomer_* utilizzavano indici non cluster e restituivano migliaia di righe per ogni esecuzione.
Mi aspettavo che la durata fosse maggiore per le procedure usp_FindAnyCustomer_* e usp_FindActiveCustomer_* rispetto alle tabelle compresse di righe e pagine, rispetto alla tabella non compressa, a causa del sovraccarico della decompressione dei dati. I dati di Query Store non supportano le mie aspettative:la durata di queste due stored procedure è più o meno la stessa (o meno in un caso!) in queste tre tabelle. L'IO logico per le query era quasi lo stesso per le tabelle non compresse e per pagine e righe compresse.
In termini di CPU, nelle stored procedure usp_FindActiveCustomer e usp_FindAnyCustomer era sempre maggiore per le tabelle compresse. La CPU era comparabile per la procedura usp_FindSpecificCustomer, che era sempre una ricerca singleton rispetto all'indice cluster. Notare l'elevata CPU (ma una durata relativamente bassa) per la procedura usp_FindSpecificCustomer rispetto alla tabella [dbo].[Customer_Compress], che richiedeva la funzione DECOMPRESS per visualizzare i dati in un formato leggibile.
RIEPILOGO
La CPU aggiuntiva richiesta per recuperare i dati compressi esiste e può essere misurata utilizzando Query Store o metodi di baseline tradizionali. Sulla base di questo test iniziale, la CPU è comparabile per le ricerche singleton, ma aumenta con più dati. Volevo forzare SQL Server a decomprimere più di 10 pagine, ne volevo almeno 100. Ho eseguito variazioni di questo script, in cui sono state restituite decine di migliaia di righe e i risultati erano coerenti con ciò che vedi qui. La mia aspettativa è che per vedere differenze significative nella durata dovute al tempo necessario per decomprimere i dati, le query debbano restituire centinaia di migliaia o milioni di righe. Se sei in un sistema OLTP, non vuoi restituire così tante righe, quindi i test qui dovrebbero darti un'idea di come la compressione può influire sulle prestazioni. Se ti trovi in un data warehouse, probabilmente vedrai una durata maggiore insieme a una CPU più alta quando restituisci set di dati di grandi dimensioni. Sebbene la funzione COMPRESS offra un notevole risparmio di spazio rispetto alla compressione di pagine e righe, il calo delle prestazioni in termini di CPU e l'impossibilità di indicizzare le colonne compresse a causa del loro tipo di dati, la rendono praticabile solo per grandi volumi di dati che non saranno cercato.