La gestione della memoria in PostgreSQL è importante per migliorare le prestazioni del server di database. Il file di configurazione di PostgreSQL (postgres.conf) gestisce la configurazione del server di database. Utilizza i valori predefiniti dei parametri, ma possiamo modificare questi valori per riflettere meglio il carico di lavoro e l'ambiente operativo.
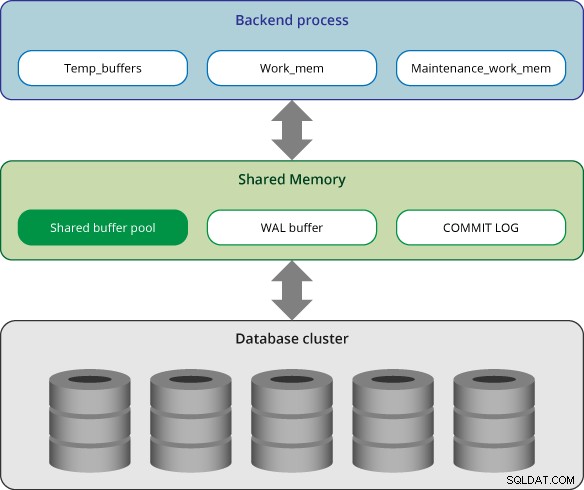
In questo blog tratteremo questi parametri relativi alla memoria. Ma prima di iniziare, diamo un'occhiata all'architettura della memoria in PostgreSQL.
Architettura della memoria
La memoria in PostgreSQL può essere classificata in due categorie:
- Area di memoria locale:è allocata da ciascun processo di back-end per il proprio uso.
- Area di memoria condivisa:è utilizzata da tutti i processi di un server PostgreSQL.
Area di memoria locale
In PostgreSQL, ogni processo di back-end alloca memoria locale per l'elaborazione delle query; ogni area è suddivisa in sottoaree le cui dimensioni sono fisse o variabili.
Le sottoaree sono le seguenti.
Mem_lavoro
L'esecutore usa quest'area per ordinare le tuple in base alle operazioni ORDER BY e DISTINCT. Lo usa anche per unire tabelle tramite operazioni di merge-join e hash-join.
Mem_lavoro_manutenzione
Questo parametro viene utilizzato per alcuni tipi di operazioni di manutenzione (VACUUM, REINDEX).
Temp_buffer
L'esecutore utilizza quest'area per memorizzare le tabelle temporanee.
Area di memoria condivisa
L'area di memoria condivisa viene allocata dal server PostgreSQL all'avvio. Queste aree sono suddivise in diverse sottoaree di dimensioni fisse.
Pool buffer condiviso
PostgreSQL carica le pagine all'interno di tabelle e indici dalla memoria persistente a un pool di buffer condiviso, quindi opera su di esse direttamente.
Buffer WAL
PostgreSQL supporta il meccanismo WAL (Write ahead log) per garantire che nessun dato venga perso dopo un errore del server. I dati WAL sono in realtà un registro delle transazioni in PostgreSQL e il buffer WAL è un'area di buffering dei dati WAL prima di scriverli in una memoria permanente.
Registro commit
Il log di commit (CLOG) mantiene gli stati di tutte le transazioni e fa parte del meccanismo di controllo della concorrenza. Il log di commit viene allocato alla memoria condivisa e utilizzato durante l'elaborazione della transazione.
PostgreSQL definisce i seguenti quattro stati di transazione.
- IN_PROGRESS
- IMPEGNATO
- INTERROTTO
- SUB-COMMITTED
Ottimizzazione dei parametri di memoria di PostgreSQL
Ci sono alcuni parametri importanti che sono consigliati per la gestione della memoria in PostgreSQL. Dovresti tenere in considerazione quanto segue.
Buffer_condivisi
Questo parametro indica la quantità di memoria utilizzata per i buffer di memoria condivisa. Il parametro shared_buffers determina la quantità di memoria dedicata al server per la memorizzazione nella cache dei dati. Il valore predefinito di shared_buffers è in genere 128 megabyte (128 MB).
Il valore predefinito di questo parametro è molto basso perché su alcune piattaforme come le versioni precedenti di Solaris e SGI, avere valori elevati richiede un'azione invasiva come la ricompilazione del kernel. Anche sui moderni sistemi Linux, il kernel probabilmente non consentirà di impostare shared_buffers su oltre 32 MB senza prima modificare le impostazioni del kernel.
Il meccanismo è cambiato in PostgreSQL 9.4 e versioni successive, quindi le impostazioni del kernel non dovranno essere modificate lì.
Se è presente un carico elevato sul server del database, l'impostazione di un valore elevato migliorerà le prestazioni.
Se hai un server DB dedicato con 1 GB o più di RAM, un valore iniziale ragionevole per il parametro di configurazione shared_buffer è il 25% della memoria nel tuo sistema.
Valore predefinito di shared_buffers =128 MB. La modifica richiede il riavvio del server PostgreSQL.
La raccomandazione generale per impostare shared_buffers è la seguente.
- Al di sotto di 2 GB di memoria, imposta il valore di shared_buffers al 20% della memoria totale del sistema.
- Al di sotto di 32 GB di memoria, imposta il valore di shared_buffers al 25% della memoria totale del sistema.
- Al di sopra di 32 GB di memoria, imposta il valore di shared_buffers su 8 GB
Mem_lavoro
Questo parametro specifica la quantità di memoria da utilizzare per le operazioni di ordinamento interno e le tabelle hash prima di scrivere su file su disco temporanei. Se si verificano molti ordinamenti complessi e hai memoria sufficiente, l'aumento del parametro work_mem consente a PostgreSQL di eseguire ordinamenti in memoria più grandi che saranno più veloci degli equivalenti basati su disco.
Si noti che per una query complessa, molte operazioni di ordinamento o hash potrebbero essere eseguite in parallelo. Ciascuna operazione potrà utilizzare tutta la memoria specificata da questo valore prima di iniziare a scrivere i dati nei file temporanei. Esiste una possibilità che diverse sessioni possano eseguire tali operazioni contemporaneamente. Pertanto, la memoria totale utilizzata potrebbe essere molte volte il valore del parametro work_mem.
Si prega di ricordarlo quando si sceglie il valore giusto. Le operazioni di ordinamento vengono utilizzate per ORDER BY, DISTINCT e merge join. Le tabelle hash vengono utilizzate negli hash join, nell'elaborazione basata su hash delle sottoquery IN e nell'aggregazione basata su hash.
Il parametro log_temp_files può essere utilizzato per registrare ordinamenti, hash e file temporanei che possono essere utili per capire se gli ordinamenti vengono riversati su disco invece di adattarsi alla memoria. Puoi controllare gli ordinamenti che si riversano su disco usando i piani EXPLAIN ANALYZE. Ad esempio, nell'output di EXPLAIN ANALYZE, se vedi la riga come:"Metodo di ordinamento:unione esterna Disco:7528kB ”, un work_mem di almeno 8 MB manterrebbe in memoria i dati intermedi e migliorerebbe il tempo di risposta alle query.
Il valore predefinito di work_mem =4 MB.
La raccomandazione generale per impostare work_mem è la seguente.
- Inizia con un valore basso:32-64 MB
- Quindi cerca le righe di "file temporaneo" nei log
- Imposta 2-3 volte il file temporaneo più grande
manutenzione _work_mem
Questo parametro specifica la quantità massima di memoria utilizzata dalle operazioni di manutenzione come VACUUM, CREATE INDEX e ALTER TABLE ADD FOREIGN KEY. Poiché solo una di queste operazioni alla volta può essere eseguita da una sessione di database e un'installazione di PostgreSQL non ne ha molte in esecuzione contemporaneamente, è sicuro impostare il valore di Maintenance_work_mem significativamente più grande di work_mem.
L'impostazione di un valore maggiore potrebbe migliorare le prestazioni per l'aspirazione e il ripristino dei dump del database.
È necessario ricordare che durante l'esecuzione di autovacuum, è possibile che questa memoria venga allocata fino a tempi di autovacuum_max_workers, quindi fare attenzione a non impostare un valore predefinito troppo alto.
Il valore predefinito di Maintenance_work_mem =64 MB.
La raccomandazione generale per impostare Maintenance_work_mem è la seguente.
- Imposta il valore 10% della memoria di sistema, fino a 1 GB
- Forse puoi impostarlo ancora più alto se hai problemi di VUOTO
Dimensione_cache_effettiva
La dimensione_cache_effettiva deve essere impostata su una stima della quantità di memoria disponibile per la memorizzazione nella cache del disco dal sistema operativo e all'interno del database stesso. Questa è una linea guida per la quantità di memoria che prevedi di essere disponibile nel sistema operativo e nelle cache del buffer PostgreSQL, non un'allocazione.
Il pianificatore di query PostgreSQL utilizza questo valore per capire se i piani che sta considerando dovrebbero adattarsi alla RAM o meno. Se è impostato su un valore troppo basso, gli indici potrebbero non essere utilizzati per eseguire le query nel modo previsto. Poiché la maggior parte dei sistemi Unix è piuttosto aggressiva durante la memorizzazione nella cache, almeno il 50% della RAM disponibile su un server di database dedicato sarà piena di dati memorizzati nella cache.
La raccomandazione generale per la dimensione_cache_effettiva è la seguente.
- Imposta il valore sulla quantità di cache del file system disponibile
- Se non lo sai, imposta il valore sul 50% della memoria di sistema totale
Il valore predefinito di dimensione_cache_effettiva =4 GB.
Temp_buffer
Questo parametro imposta il numero massimo di buffer temporanei utilizzati da ciascuna sessione del database. I buffer locali di sessione vengono utilizzati solo per l'accesso alle tabelle temporanee. L'impostazione di questo parametro può essere modificata all'interno delle singole sessioni ma solo prima del primo utilizzo delle tabelle temporanee all'interno della sessione.
Il database PostgreSQL utilizza quest'area di memoria per contenere le tabelle temporanee di ogni sessione, queste verranno cancellate alla chiusura della connessione.
Il valore predefinito di temp_buffer =8 MB.
Conclusione
Comprendere l'architettura della memoria e regolare i parametri appropriati è importante per migliorare le prestazioni. Ciò è particolarmente necessario per i sistemi con carichi di lavoro elevati. Per suggerimenti più generici sull'ottimizzazione delle prestazioni, consulta questo cheat sheet sulle prestazioni per PostgreSQL.