La scorsa settimana, ho presentato la mia sessione T-SQL :Bad Habits and Best Practices durante la conferenza GroupBy. Un video replay e altro materiale sono disponibili qui:
- T-SQL:cattive abitudini e best practice
Uno degli elementi che menziono sempre in quella sessione è che generalmente preferisco GROUP BY su DISTINCT quando elimino i duplicati. Sebbene DISTINCT spieghi meglio l'intento e GROUP BY sia richiesto solo quando sono presenti aggregazioni, in molti casi sono intercambiabili.
Iniziamo con qualcosa di semplice utilizzando Wide World Importers. Queste due query producono lo stesso risultato:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
E in effetti derivano i loro risultati utilizzando lo stesso identico piano di esecuzione:

Stessi operatori, stesso numero di letture, differenze trascurabili di CPU e durata totale (si alternano "vincenti").
Allora perché dovrei raccomandare di usare la sintassi GROUP BY più verbosa e meno intuitiva su DISTINCT? Bene, in questo caso semplice, è un lancio di una moneta. Tuttavia, nei casi più complessi, DISTINCT può finire per fare più lavoro. In sostanza, DISTINCT raccoglie tutte le righe, comprese le espressioni che devono essere valutate, e quindi elimina i duplicati. GROUP BY può (di nuovo, in alcuni casi) filtrare le righe duplicate prima eseguire qualsiasi di quel lavoro.
Parliamo di aggregazione di stringhe, per esempio. Mentre in SQL Server v.Next sarai in grado di usare STRING_AGG (vedi i post qui e qui), il resto di noi deve continuare con FOR XML PATH (e prima che tu mi dica quanto sono sorprendenti i CTE ricorsivi per questo, per favore leggi anche questo post). Potremmo avere una query come questa, che tenta di restituire tutti gli ordini dalla tabella Sales.OrderLines, insieme alle descrizioni degli articoli come un elenco delimitato da pipe:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Questa è una query tipica per risolvere questo tipo di problema, con il seguente piano di esecuzione (l'avviso in tutti i piani è solo per la conversione implicita che esce dal filtro XPath):
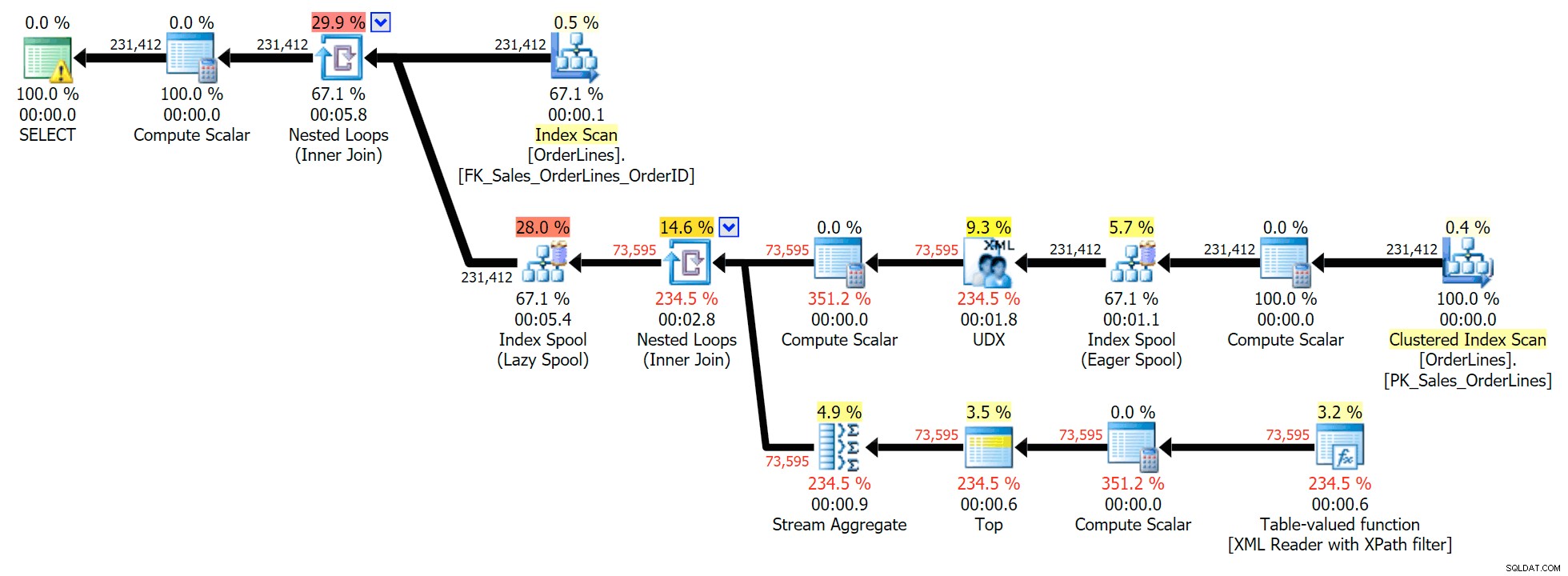
Tuttavia, ha un problema che potresti notare nel numero di righe di output. Puoi sicuramente individuarlo durante la scansione casuale dell'output:

Per ogni ordine, vediamo l'elenco delimitato da barre verticali, ma vediamo una riga per ogni articolo in ogni ordine. La reazione istintiva è di lanciare un DISTINCT nell'elenco delle colonne:
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Ciò elimina i duplicati (e modifica le proprietà di ordinamento sulle scansioni, quindi i risultati non appariranno necessariamente in un ordine prevedibile) e produce il seguente piano di esecuzione:
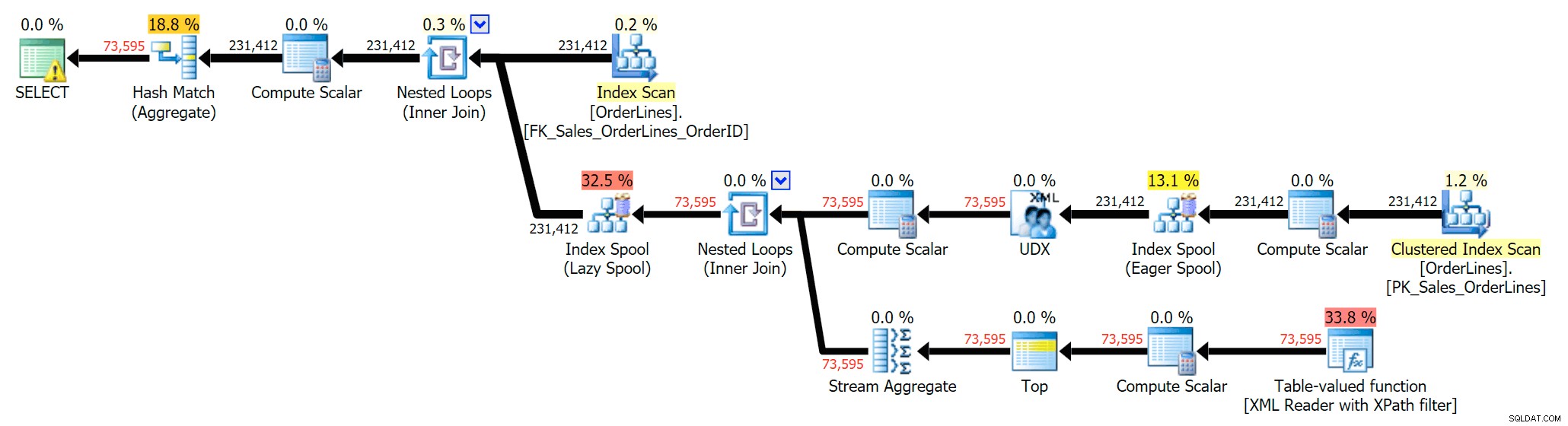
Un altro modo per farlo è aggiungere un GROUP BY per OrderID (poiché la sottoquery non ne ha esplicitamente necessità da referenziare nuovamente nel GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Questo produce gli stessi risultati (sebbene l'ordine sia tornato) e un piano leggermente diverso:
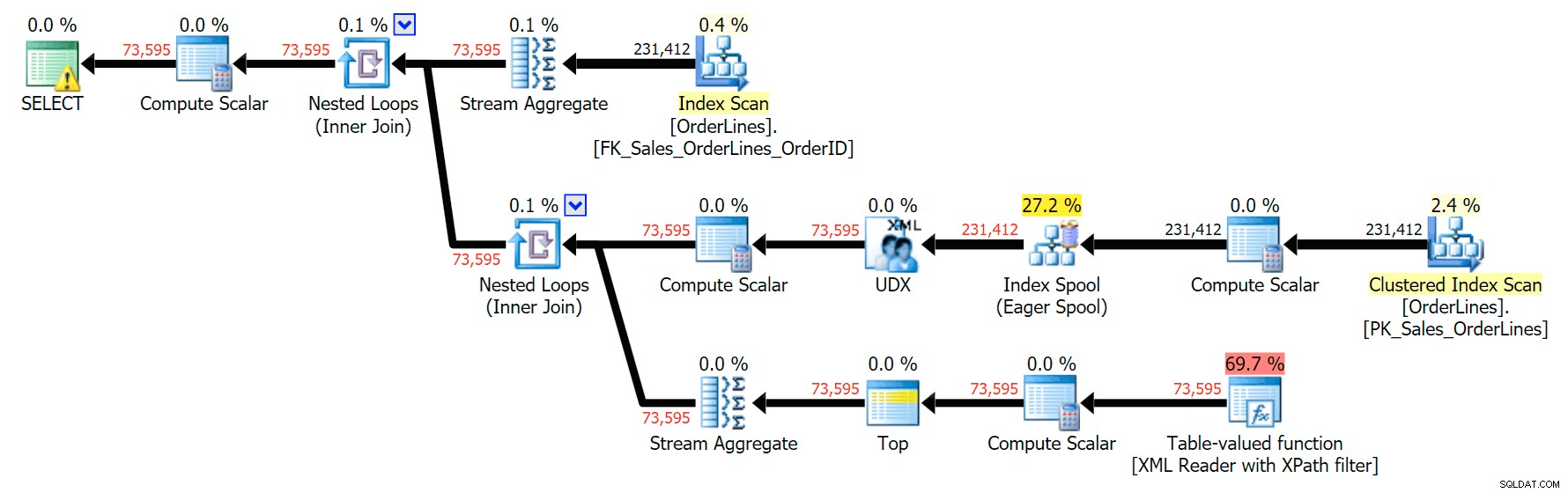
Le metriche delle prestazioni, tuttavia, sono interessanti da confrontare.

La variazione DISTINCT ha impiegato 4 volte più tempo, ha utilizzato 4 volte la CPU e quasi 6 volte le letture rispetto alla variazione GROUP BY. (Ricorda, queste query restituiscono esattamente gli stessi risultati.)
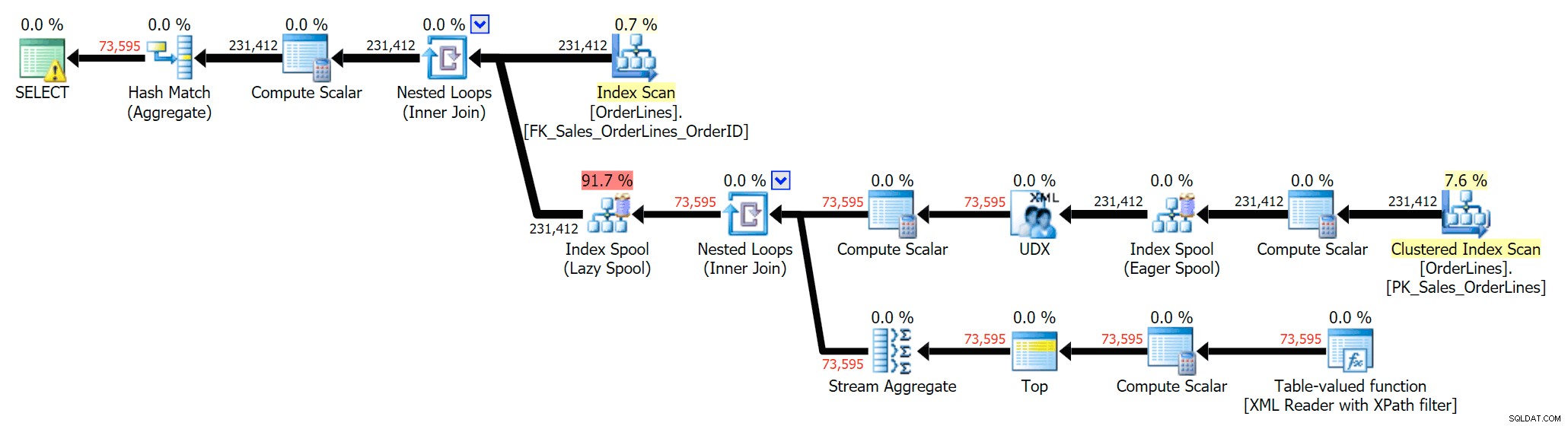
Possiamo anche confrontare i piani di esecuzione quando cambiamo i costi da CPU + I/O combinati a solo I/O, una funzionalità esclusiva di Plan Explorer. Mostriamo anche i valori ricalcolati (che si basano su effettivi costi osservati durante l'esecuzione della query, una funzionalità presente anche solo in Plan Explorer). Ecco il piano DISTINCT:
Ed ecco il piano GROUP BY:
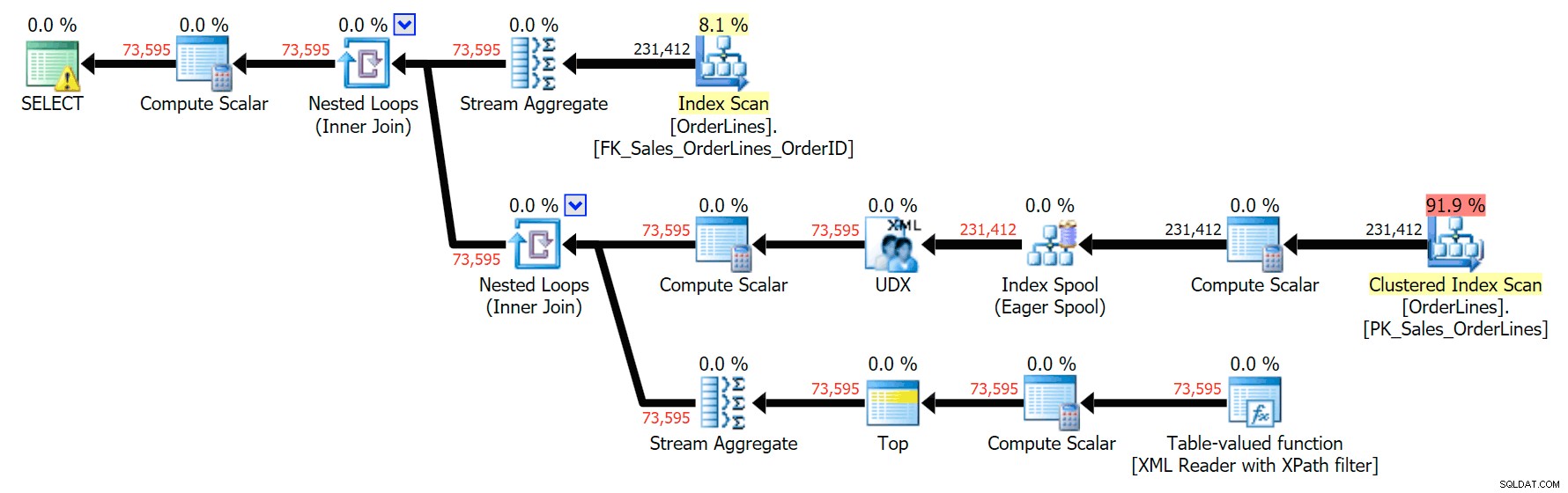
Puoi vedere che, nel piano GROUP BY, quasi tutto il costo di I/O è nelle scansioni (ecco il suggerimento per la scansione CI, che mostra un costo di I/O di ~3,4 "query bucks"). Tuttavia, nel piano DISTINCT, la maggior parte del costo di I/O è nello spool dell'indice (ed ecco il suggerimento; il costo di I/O qui è di circa 41,4 "query bucks"). Nota che anche la CPU è molto più alta con lo spool dell'indice. Parleremo di "query bucks" un'altra volta, ma il punto è che lo spool dell'indice è più di 10 volte più costoso della scansione, eppure la scansione è sempre la stessa 3.4 in entrambi i piani. Questo è uno dei motivi per cui mi infastidisce sempre quando le persone dicono di dover "aggiustare" l'operatore nel piano con il costo più alto. Alcuni operatori del piano sempre essere il più costoso; ciò non significa che debba essere riparato.
@AaronBertrand quelle query non sono realmente equivalenti logicamente — DISTINCT è su entrambe le colonne, mentre il tuo GROUP BY è solo su una
— Adam Machanic (@AdamMachanic) 20 gennaio 2017
Sebbene Adam Machanic abbia ragione quando afferma che queste query sono semanticamente diverse, il risultato è lo stesso:otteniamo lo stesso numero di righe, contenenti esattamente gli stessi risultati, e lo abbiamo fatto con molte meno letture e CPU.
Quindi, mentre DISTINCT e GROUP BY sono identici in molti scenari, qui c'è un caso in cui l'approccio GROUP BY porta sicuramente a prestazioni migliori (a costo di un intento dichiarativo meno chiaro nella query stessa). Sarei interessato a sapere se pensi che ci siano scenari in cui DISTINCT è meglio di GROUP BY, almeno in termini di prestazioni, che è molto meno soggettivo dello stile o se un'affermazione deve essere autodocumentante.
Questo post rientra nella mia serie "sorprese e ipotesi" perché molte cose che consideriamo verità basate su osservazioni limitate o casi d'uso particolari possono essere testate se utilizzate in altri scenari. Dobbiamo solo ricordarci di prenderci il tempo per farlo come parte dell'ottimizzazione delle query SQL...
Riferimenti
- Concatenazione di gruppi in SQL Server
- Concatenazione raggruppata:ordinazione e rimozione dei duplicati
- Quattro casi d'uso pratici per la concatenazione di gruppi
- SQL Server v.Next:prestazioni STRING_AGG()
- SQL Server v.Next:prestazioni STRING_AGG, parte 2