SQL Server ha tradizionalmente evitato di fornire soluzioni native ad alcune delle domande statistiche più comuni, come il calcolo di una mediana. Secondo WikiPedia, "la mediana è descritta come il valore numerico che separa la metà superiore di un campione, una popolazione o una distribuzione di probabilità, dalla metà inferiore. La mediana di un elenco finito di numeri può essere trovata disponendo tutte le osservazioni da dal valore più basso al valore più alto e selezionando quello intermedio. Se c'è un numero pari di osservazioni, allora non c'è un unico valore medio; la mediana è quindi solitamente definita come la media dei due valori medi."
In termini di una query di SQL Server, la cosa fondamentale che ne trarrai è che devi "organizzare" (ordinare) tutti i valori. L'ordinamento in SQL Server è in genere un'operazione piuttosto costosa se non è presente un indice di supporto e l'aggiunta di un indice per supportare un'operazione che probabilmente non è richiesta spesso potrebbe non essere utile.
Esaminiamo come in genere abbiamo risolto questo problema nelle versioni precedenti di SQL Server. Per prima cosa creiamo una tabella molto semplice in modo da poter vedere che la nostra logica è corretta e deriva una mediana accurata. Possiamo testare le seguenti due tabelle, una con un numero pari di righe e l'altra con un numero dispari di righe:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Solo per osservanza casuale, possiamo vedere che la mediana per la tabella con righe dispari dovrebbe essere 6 e per la tabella pari dovrebbe essere 7,5 ((6+9)/2). Quindi ora vediamo alcune soluzioni che sono state utilizzate negli anni:
SQL Server 2000
In SQL Server 2000 eravamo vincolati a un dialetto T-SQL molto limitato. Sto esaminando queste opzioni per il confronto perché alcune persone stanno ancora eseguendo SQL Server 2000 e altre potrebbero aver eseguito l'aggiornamento ma, poiché i loro calcoli mediani sono stati scritti "all'epoca", il codice potrebbe ancora apparire così oggi.
2000_A – max di una metà, min dell'altra
Questo approccio prende il valore più alto dal primo 50 percento, il valore più basso dall'ultimo 50 percento, quindi li divide per due. Funziona per righe pari o dispari perché, nel caso pari, i due valori sono le due righe centrali e, nel caso dispari, i due valori provengono effettivamente dalla stessa riga.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #tabella temporanea
Questo esempio crea prima una tabella #temp e, utilizzando lo stesso tipo di matematica di cui sopra, determina le due righe "intermedie" con l'assistenza di un IDENTITY contiguo colonna ordinata dalla colonna val. (L'ordine di assegnazione di IDENTITY i valori possono essere considerati affidabili solo a causa del MAXDOP impostazione.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 ha introdotto alcune nuove interessanti funzioni della finestra, come ROW_NUMBER() , che può aiutare a risolvere problemi statistici come la mediana un po' più facilmente di quanto potremmo fare in SQL Server 2000. Questi approcci funzionano tutti in SQL Server 2005 e versioni successive:
2005_A – i numeri delle file dei duelli
Questo esempio utilizza ROW_NUMBER() per camminare su e giù per i valori una volta in ciascuna direzione, quindi trova le righe "medie" una o due in base a quel calcolo. Questo è abbastanza simile al primo esempio sopra, con una sintassi più semplice:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – numero riga + conteggio
Questo è abbastanza simile al precedente, utilizzando un singolo calcolo di ROW_NUMBER() e quindi utilizzando il totale COUNT() per trovare la "metà" una o due righe:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – variazione numero riga + conteggio
Il collega MVP Itzik Ben-Gan mi ha mostrato questo metodo, che ottiene la stessa risposta dei due metodi precedenti, ma in un modo leggermente diverso:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
In SQL Server 2012 sono disponibili nuove funzionalità di windowing in T-SQL che consentono di esprimere più direttamente calcoli statistici come la mediana. Per calcolare la mediana per un insieme di valori, possiamo usare PERCENTILE_CONT() . Possiamo anche utilizzare la nuova estensione "paging" per ORDER BY clausola (OFFSET / FETCH ).
2012_A – nuova funzionalità di distribuzione
Questa soluzione utilizza un calcolo molto semplice utilizzando la distribuzione (se non si desidera la media tra i due valori intermedi nel caso di un numero pari di righe).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – trucco di paging
Questo esempio implementa un uso intelligente di OFFSET / FETCH (e non esattamente quello per cui era previsto) – ci spostiamo semplicemente sulla riga che è una prima della metà del conteggio, quindi prendiamo la o le due righe successive a seconda che il conteggio sia pari o dispari. Grazie a Itzik Ben-Gan per aver sottolineato questo approccio.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Ma quale funziona meglio?
Abbiamo verificato che i metodi precedenti producono tutti i risultati attesi sul nostro tavolino e sappiamo che la versione di SQL Server 2012 ha la sintassi più pulita e logica. Ma quale dovresti usare nel tuo frenetico ambiente di produzione? Possiamo creare una tabella molto più grande dai metadati di sistema, assicurandoci di avere molti valori duplicati. Questo script produrrà una tabella con 10.000.000 di numeri interi non univoci:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
Sul mio sistema la mediana per questa tabella dovrebbe essere 146.099.561. Posso calcolarlo abbastanza rapidamente senza un controllo a campione manuale di 10.000.000 di righe utilizzando la seguente query:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Risultati:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Quindi ora possiamo creare una stored procedure per ogni metodo, verificare che ognuno produca l'output corretto e quindi misurare le metriche delle prestazioni come durata, CPU e letture. Eseguiremo tutti questi passaggi con la tabella esistente e anche con una copia della tabella che non beneficia dell'indice cluster (lo elimineremo e ricreeremo la tabella come heap).
Ho creato sette procedure che implementano i metodi di query sopra. Per brevità non li elencherò qui, ma ognuno si chiama dbo.Median_<version> , per esempio. dbo.Median_2000_A , dbo.Median_2000_B , ecc. corrispondenti agli approcci sopra descritti. Se eseguiamo queste sette procedure utilizzando SQL Sentry Plan Explorer gratuito, ecco cosa osserviamo in termini di durata, CPU e letture (notare che eseguiamo DBCC FREEPROCCACHE e DBCC DROPCLEANBUFFERS tra le esecuzioni):
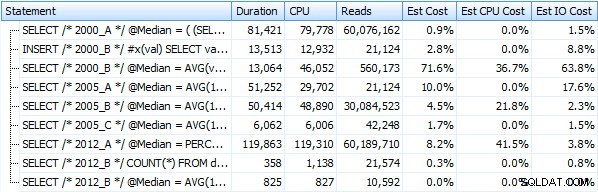
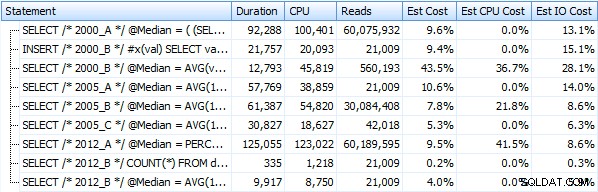
E queste metriche non cambiano affatto se operiamo invece contro un heap. La più grande variazione percentuale è stata il metodo che ha comunque finito per essere il più veloce:il trucco di paging usando OFFSET / FETCH:
Ecco una rappresentazione grafica dei risultati. Per chiarire meglio, ho evidenziato in rosso l'esecutore più lento e in verde l'approccio più veloce.
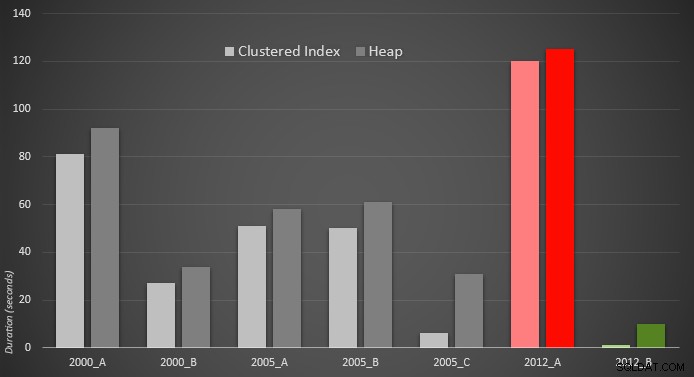
Sono stato sorpreso di vedere che, in entrambi i casi, PERCENTILE_CONT() – che è stato progettato per questo tipo di calcolo – è in realtà peggiore di tutte le altre soluzioni precedenti. Immagino che dimostri che mentre a volte una sintassi più recente potrebbe semplificare la nostra codifica, non sempre garantisce che le prestazioni miglioreranno. Sono stato anche sorpreso di vedere OFFSET / FETCH rivelarsi così utile in scenari che di solito non sembrerebbero adatti al suo scopo:l'impaginazione.
In ogni caso, spero di aver dimostrato quale approccio dovresti usare, a seconda della tua versione di SQL Server (e che la scelta dovrebbe essere la stessa indipendentemente dal fatto che tu abbia o meno un indice di supporto per il calcolo).