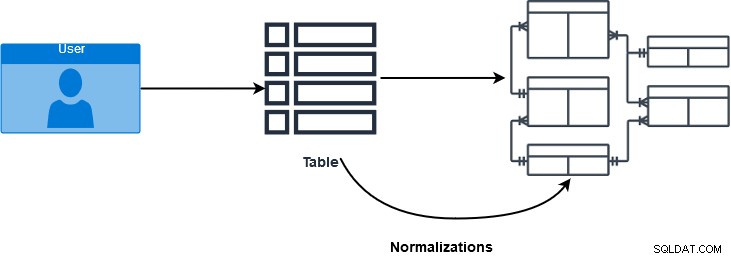
SQL JOIN è una clausola utilizzata per combinare più tabelle e recuperare dati in base a un campo comune nei database relazionali. I professionisti del database utilizzano le normalizzazioni per garantire e migliorare l'integrità dei dati. Nelle varie forme di normalizzazione, i dati sono distribuiti in più tabelle logiche. Queste tabelle usano vincoli referenziali, chiave primaria e chiavi esterne, per rafforzare l'integrità dei dati nelle tabelle di SQL Server. Nell'immagine sottostante, diamo uno sguardo al processo di normalizzazione del database.
Comprendere i diversi tipi di SQL JOIN
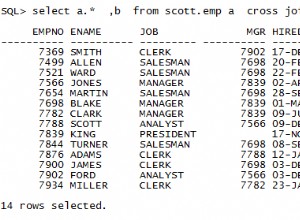
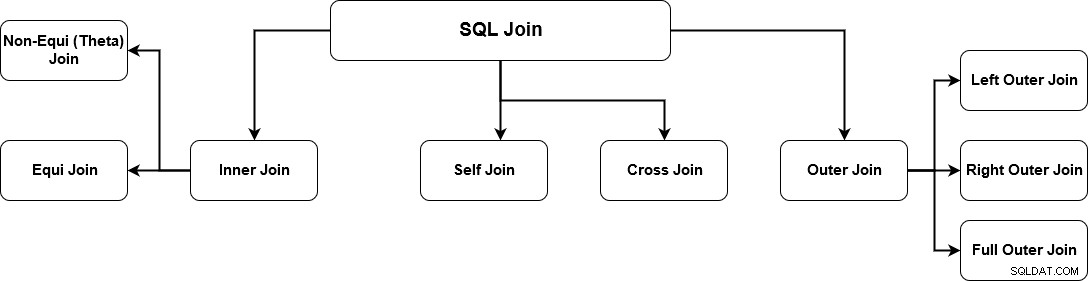
SQL JOIN genera dati significativi combinando più tabelle relazionali. Queste tabelle sono correlate tramite una chiave e hanno relazioni uno-a-uno o uno-a-molti. Per recuperare i dati corretti, è necessario conoscere i requisiti dei dati e i meccanismi di join corretti. SQL Server supporta più join e ogni metodo ha un modo specifico per recuperare i dati da più tabelle. L'immagine seguente specifica i join di SQL Server supportati.
Partecipazione interna a SQL
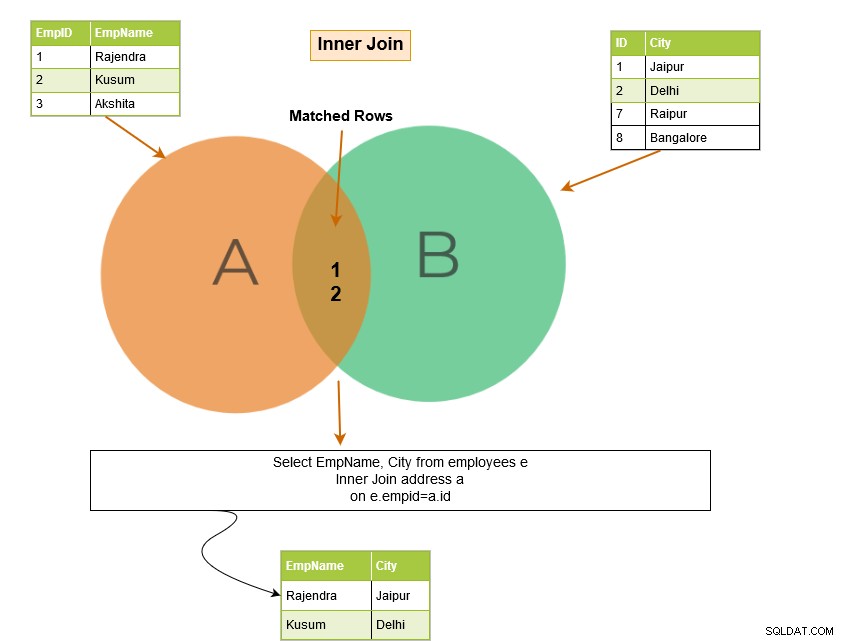
Il join interno SQL include le righe delle tabelle in cui sono soddisfatte le condizioni di join. Ad esempio, nel diagramma di Venn sottostante, inner join restituisce le righe corrispondenti dalla tabella A e dalla tabella B.
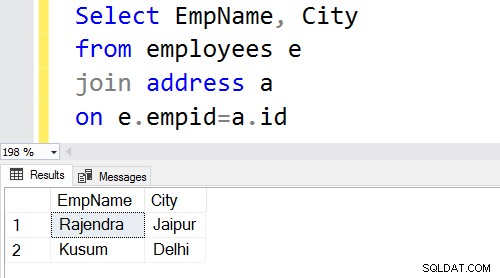
Nell'esempio seguente, nota le seguenti cose:
- Abbiamo due tabelle:[Dipendenti] e [Indirizzo].
- La query SQL viene unita nella colonna [Employees].[EmpID] e [Address].[ID].
L'output della query restituisce i record dei dipendenti per EmpID che esiste in entrambe le tabelle.
Il join interno restituisce le righe corrispondenti da entrambe le tabelle; pertanto, è anche noto come Equi join. Se non specifichiamo la parola chiave inner, SQL Server esegue l'operazione di inner join.
In un altro tipo di inner join, un theta join, non utilizziamo l'operatore di uguaglianza (=) nella clausola ON. Al contrario, utilizziamo operatori di non uguaglianza come
SELEZIONA * DA Tabella1 T1, Tabella2 T2 DOVE T1.Prezzo
In un self-join, SQL Server si unisce alla tabella con se stesso. Ciò significa che il nome della tabella viene visualizzato due volte nella clausola from.
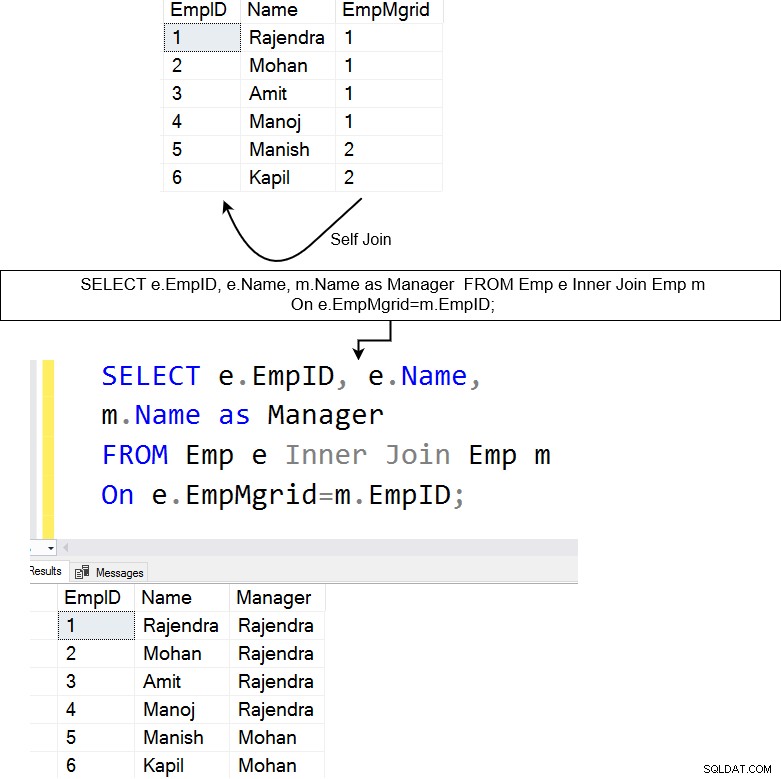
Di seguito, abbiamo una tabella [Emp] che contiene i dati dei dipendenti e dei loro manager. Il self-join è utile per interrogare i dati gerarchici. Ad esempio, nella tabella dei dipendenti, possiamo utilizzare l'adesione automatica per conoscere il nome di ciascun dipendente e del relativo responsabile dei rapporti.
La query precedente inserisce un self-join sulla tabella [Emp]. Unisce la colonna EmpMgrID con la colonna EmpID e restituisce le righe corrispondenti.
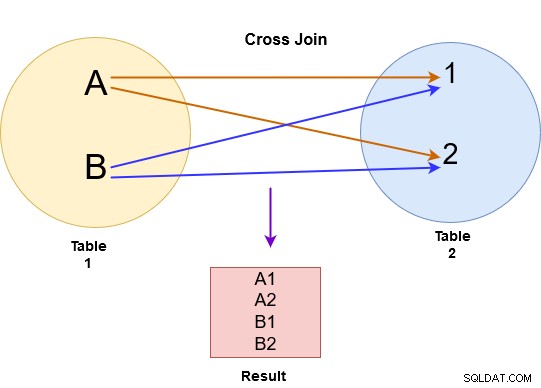
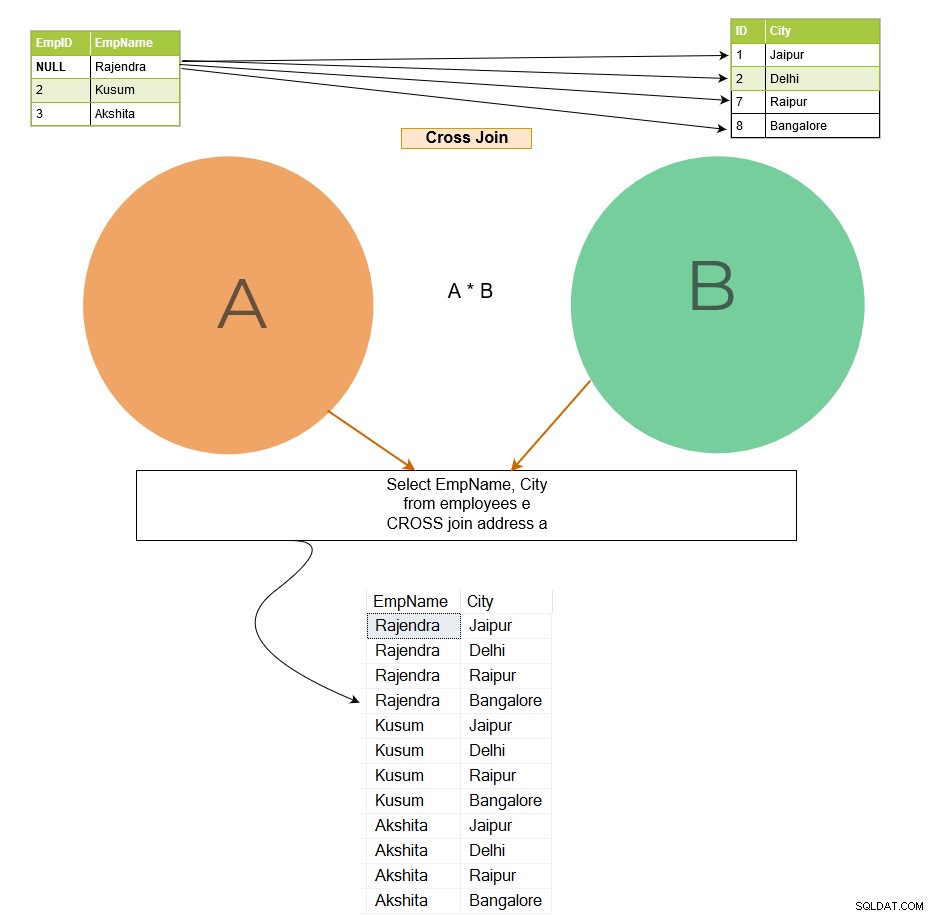
Nel cross join, SQL Server restituisce un prodotto cartesiano da entrambe le tabelle. Ad esempio, nell'immagine sottostante, abbiamo eseguito un cross-join per le tabelle A e B.
Il cross join unisce ogni riga della tabella A a ogni riga disponibile nella tabella B. Pertanto, l'output è anche noto come prodotto cartesiano di entrambe le tabelle. Nell'immagine sottostante, nota quanto segue:
Nell'output di unione incrociata, la riga 1 della tabella [Dipendente] si unisce a tutte le righe della tabella [Indirizzo] e segue lo stesso schema per le righe rimanenti.
Se la prima tabella ha x numero di righe e la seconda tabella ha n numero di righe, il cross join fornisce x*n numero di righe nell'output. Dovresti evitare il cross join su tabelle più grandi perché potrebbe restituire un numero elevato di record e SQL Server richiede molta potenza di calcolo (CPU, memoria e IO) per gestire dati così estesi.
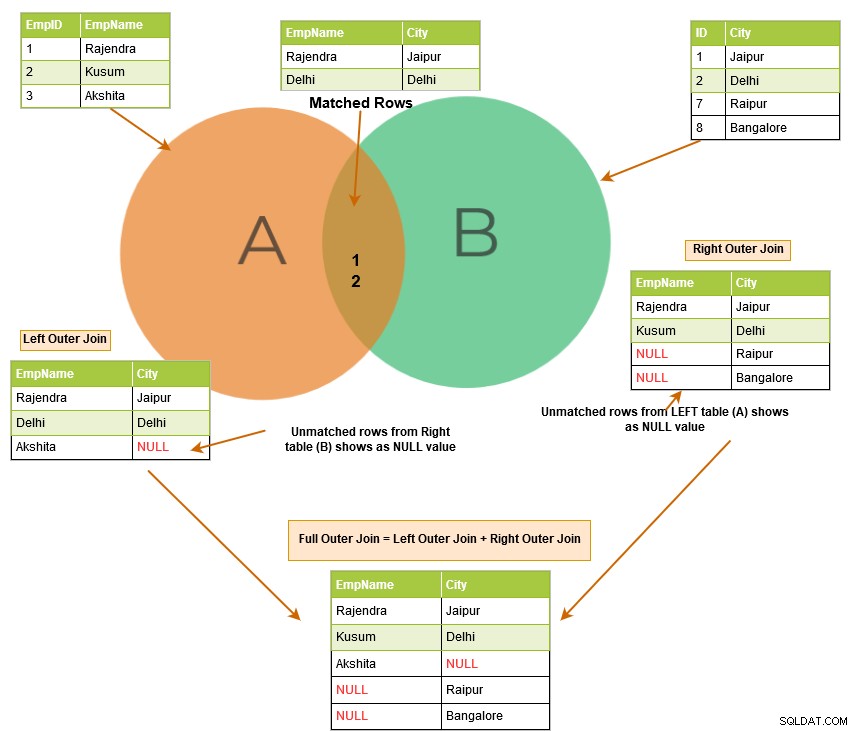
Come spiegato in precedenza, il join interno restituisce le righe corrispondenti da entrambe le tabelle. Quando si utilizza un outer join SQL, non solo elenca le righe corrispondenti, ma restituisce anche le righe non corrispondenti dalle altre tabelle. La riga senza corrispondenza dipende dalle parole chiave sinistra, destra o completa.
L'immagine seguente descrive ad alto livello il join esterno sinistro, destro e completo.
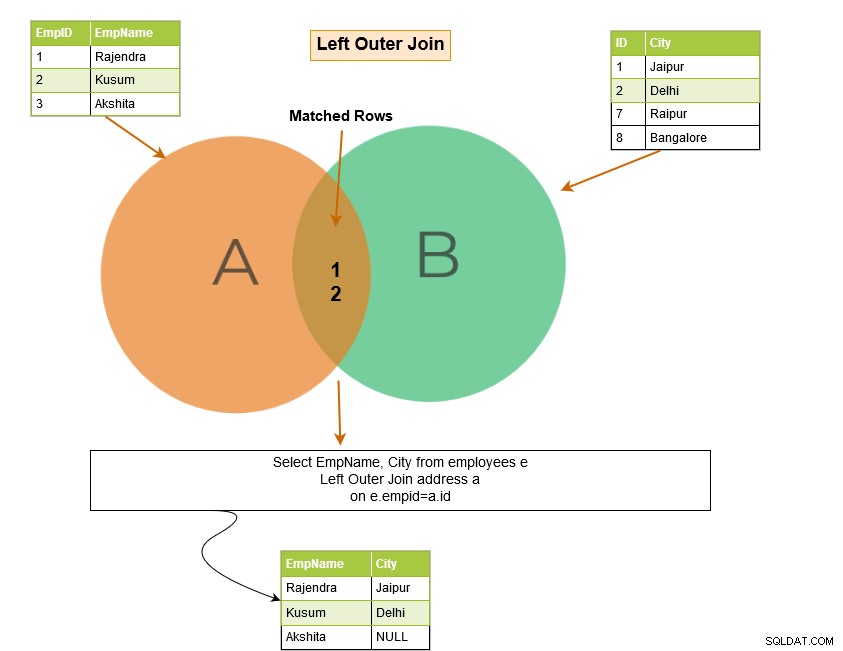
Il join esterno sinistro SQL restituisce le righe corrispondenti di entrambe le tabelle insieme alle righe non corrispondenti della tabella di sinistra. Se un record della tabella di sinistra non ha righe corrispondenti nella tabella di destra, visualizza il record con valori NULL.
Nell'esempio seguente, il join esterno sinistro restituisce le seguenti righe:
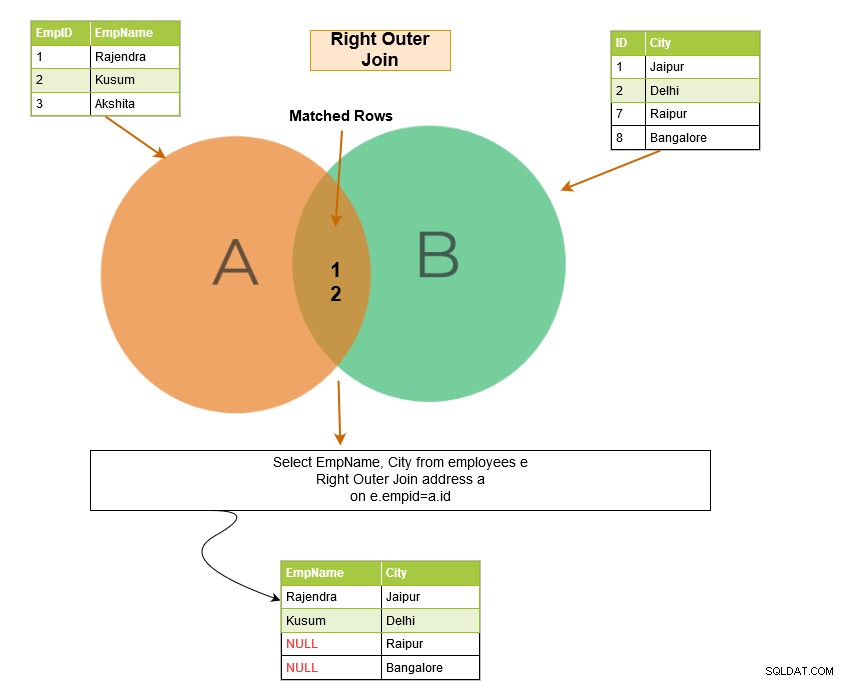
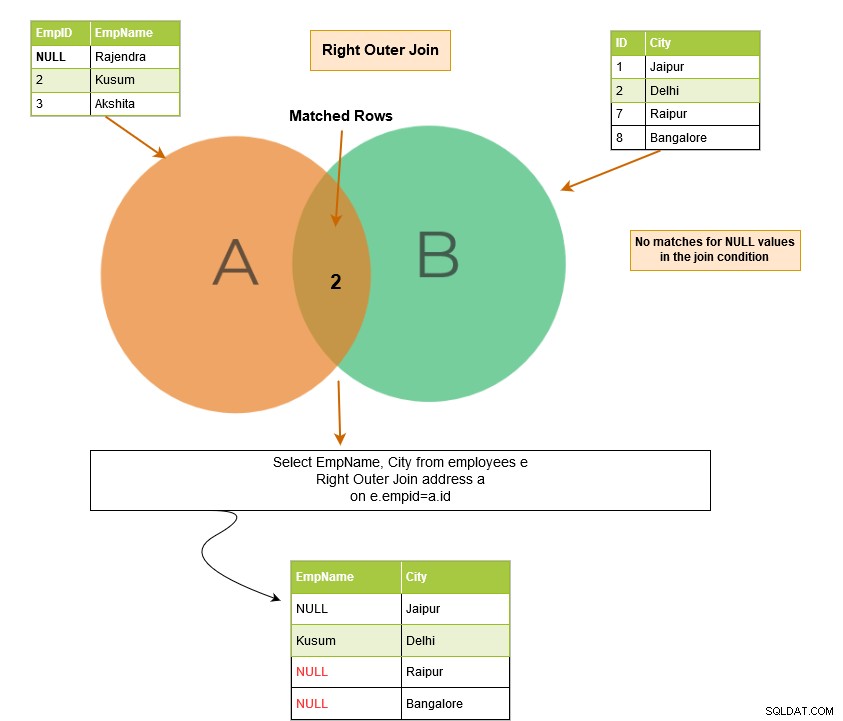
Il join esterno destro SQL restituisce le righe corrispondenti di entrambe le tabelle insieme alle righe non corrispondenti della tabella di destra. Se un record della tabella di destra non ha righe corrispondenti nella tabella di sinistra, visualizza il record con valori NULL.
Nell'esempio seguente, abbiamo le seguenti righe di output:
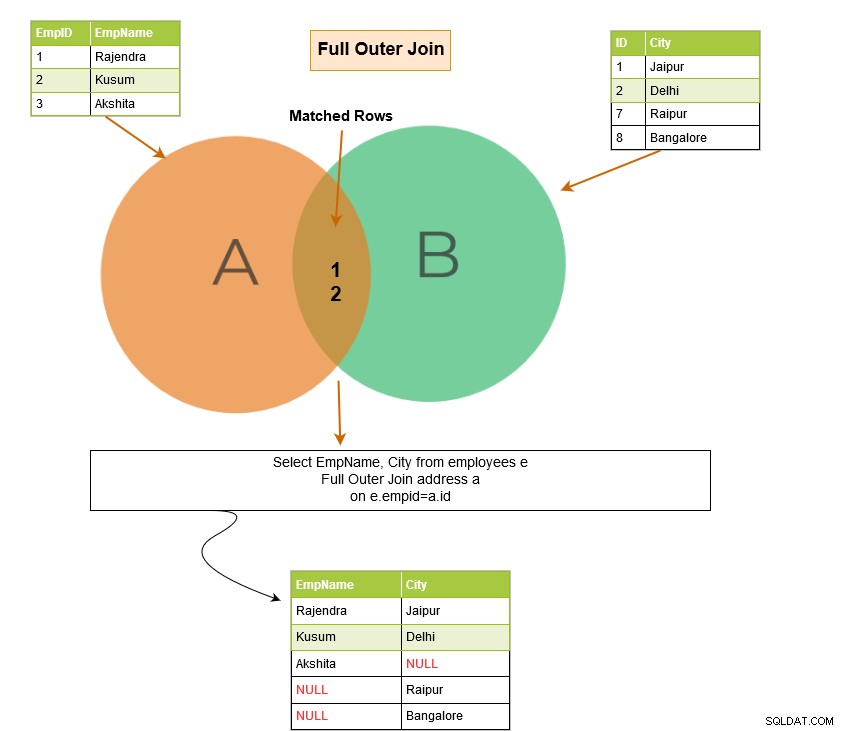
Un join esterno completo restituisce le seguenti righe nell'output:
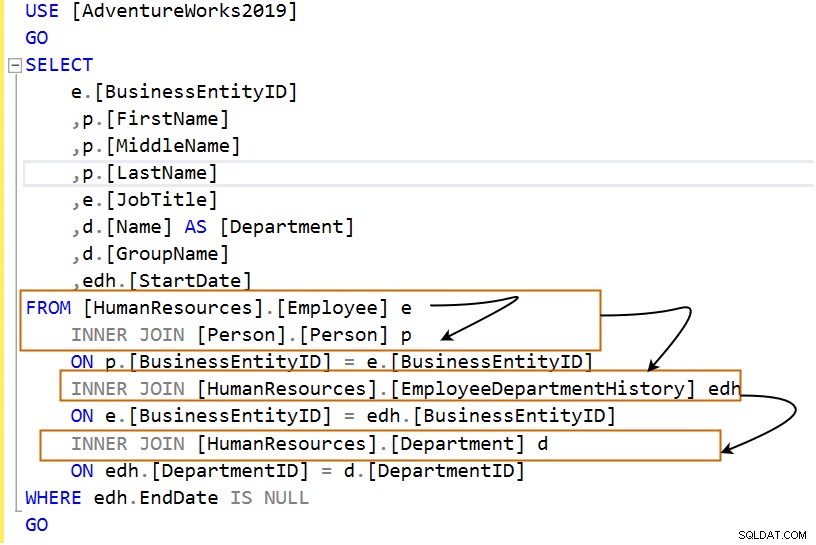
Negli esempi precedenti, utilizziamo due tabelle in una query SQL per eseguire operazioni di join. Per lo più, uniamo più tabelle insieme e restituisce i dati rilevanti.
La query seguente utilizza più inner join.
Analizziamo la query nei seguenti passaggi:
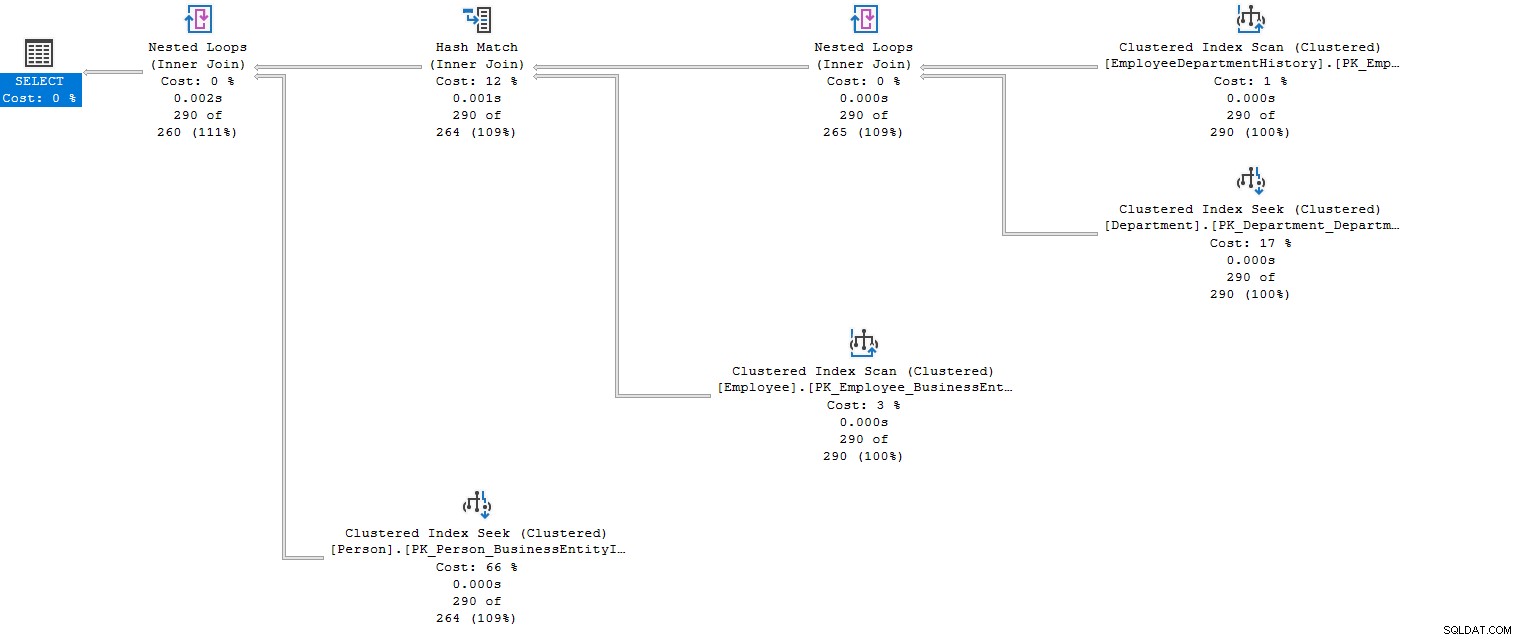
Dopo aver eseguito la query con più join, Query Optimizer prepara il piano di esecuzione. Prepara un piano di esecuzione ottimizzato in termini di costi che soddisfa le condizioni di join con l'utilizzo delle risorse, ad esempio, nel piano di esecuzione effettivo di seguito, possiamo guardare più loop nidificati (inner join) e corrispondenze hash (inner join) che combinano i dati da più tabelle di join .
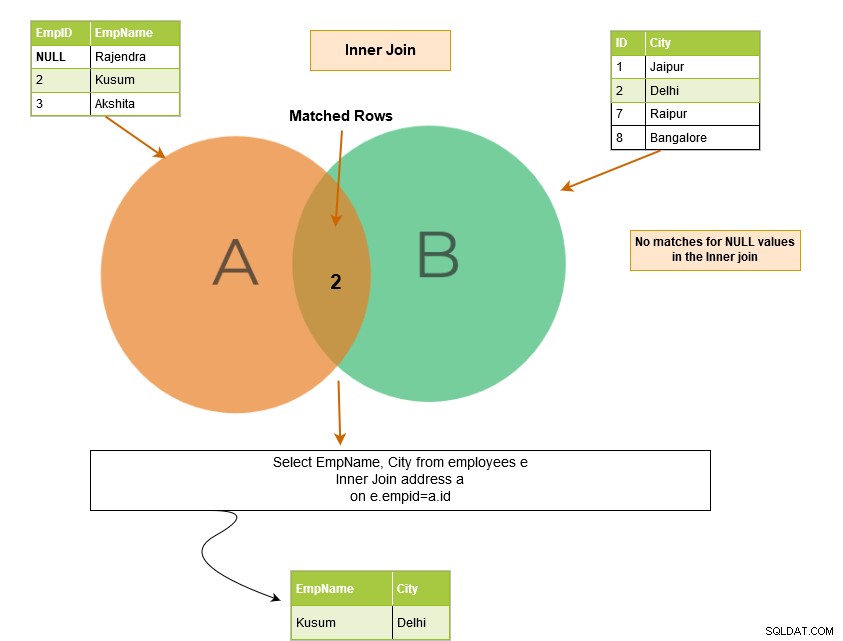
Supponiamo di avere valori NULL nelle colonne della tabella e uniamo le tabelle su quelle colonne. SQL Server corrisponde ai valori NULL?
I valori NULL non corrispondono tra loro. Pertanto, SQL Server non è stato in grado di restituire la riga corrispondente. Nell'esempio seguente, abbiamo NULL nella colonna EmpID della tabella [Employees]. Pertanto, nell'output, restituisce la riga corrispondente solo per [EmpID] 2.
Possiamo ottenere questa riga NULL nell'output in caso di un outer join SQL perché restituisce anche le righe non corrispondenti.
In questo articolo, abbiamo esplorato i diversi tipi di join SQL. Di seguito sono riportate alcune best practice importanti da ricordare e applicare quando si utilizzano i join SQL.Accesso automatico a SQL
unione incrociata SQL
Join esterno SQL
Unisci esterno sinistro
Unione esterna destra
Full outer join
Unisce a SQL con più tabelle
USE [AdventureWorks2019]
GO
SELECT
e.[BusinessEntityID]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
GO
Valori NULL e join SQL
Best practice per l'adesione a SQL