Questo articolo è l'ottava parte di una serie sulle espressioni di tabella. Finora ho fornito uno sfondo per le espressioni di tabella, ho trattato sia gli aspetti logici che di ottimizzazione delle tabelle derivate, gli aspetti logici dei CTE e alcuni degli aspetti di ottimizzazione dei CTE. Questo mese continuo la copertura degli aspetti di ottimizzazione dei CTE, affrontando in particolare il modo in cui vengono gestiti più riferimenti CTE.
Questo articolo è l'ottava parte di una serie sulle espressioni di tabella. Finora ho fornito uno sfondo per le espressioni di tabella, ho trattato sia gli aspetti logici che di ottimizzazione delle tabelle derivate, gli aspetti logici dei CTE e alcuni degli aspetti di ottimizzazione dei CTE. Questo mese continuo la copertura degli aspetti di ottimizzazione dei CTE, affrontando in particolare il modo in cui vengono gestiti più riferimenti CTE.
Nei miei esempi continuerò a utilizzare il database di esempio TSQLV5. Puoi trovare lo script che crea e popola TSQLV5 qui e il suo diagramma ER qui.
Riferimenti multipli e non determinismo
Il mese scorso ho spiegato e dimostrato che i CTE non vengono nidificati, mentre le tabelle temporanee e le variabili di tabella persistono effettivamente i dati. Ho fornito consigli in termini di quando ha senso utilizzare CTE rispetto a quando ha senso utilizzare oggetti temporanei dal punto di vista delle prestazioni della query. Ma c'è un altro aspetto importante dell'ottimizzazione CTE, o elaborazione fisica, da considerare al di là delle prestazioni della soluzione:come vengono gestiti più riferimenti al CTE da una query esterna. È importante rendersi conto che se si dispone di una query esterna con più riferimenti allo stesso CTE, ciascuna viene annullata separatamente. Se hai calcoli non deterministici nella query interna del CTE, tali calcoli possono avere risultati diversi nei diversi riferimenti.
Supponiamo ad esempio di invocare la funzione SYSDATETIME nella query interna di un CTE, creando una colonna di risultati chiamata dt. In genere, supponendo che non ci siano modifiche negli input, una funzione incorporata viene valutata una volta per query e riferimento, indipendentemente dal numero di righe coinvolte. Se si fa riferimento al CTE solo una volta da una query esterna, ma si interagisce con la colonna dt più volte, tutti i riferimenti dovrebbero rappresentare la stessa valutazione della funzione e restituire gli stessi valori. Tuttavia, se si fa riferimento al CTE più volte nella query esterna, che si tratti di più subquery che si riferiscono al CTE o di un join tra più istanze dello stesso CTE (ad esempio alias C1 e C2), i riferimenti a C1.dt e C2.dt rappresentano valutazioni diverse dell'espressione sottostante e potrebbero risultare in valori diversi.
Per dimostrarlo, considera i seguenti tre batch:
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GO Sulla base di ciò che ho appena spiegato, puoi identificare quale dei lotti ha un ciclo infinito e quale si fermerà a un certo punto a causa dei due confronti del predicato che valutano valori diversi?
Ricorda che ho detto che una chiamata a una funzione non deterministica incorporata come SYSDATETIME viene valutata una volta per query e riferimento. Ciò significa che in Batch 1 hai due valutazioni diverse e dopo un numero sufficiente di iterazioni del ciclo risulteranno valori diversi. Provalo. Quante iterazioni ha riportato il codice?
Come per Batch 2, il codice ha due riferimenti alla colonna dt della stessa istanza CTE, il che significa che entrambi rappresentano la stessa valutazione della funzione e dovrebbero rappresentare lo stesso valore. Di conseguenza, il lotto 2 ha un ciclo infinito. Eseguilo per il tempo che desideri, ma alla fine dovrai interrompere l'esecuzione del codice.
Come per il Batch 3, la query esterna ha due diverse sottoquery che interagiscono con il CTE C, ognuna delle quali rappresenta un'istanza diversa che passa attraverso un processo di unnesting separatamente. Il codice non assegna in modo esplicito alias diversi alle diverse istanze del CTE perché le due sottoquery appaiono in ambiti indipendenti, ma per semplificare la comprensione, potresti pensare che i due utilizzino alias diversi come C1 in una sottoquery e C2 nell'altro. Quindi è come se una sottoquery interagisse con C1.dt e l'altra con C2.dt. I diversi riferimenti rappresentano valutazioni diverse dell'espressione sottostante e quindi possono risultare in valori diversi. Prova a eseguire il codice e vedi che si interrompe a un certo punto. Quante iterazioni ci sono volute prima che si fermasse?
È interessante provare a identificare i casi in cui hai una valutazione singola rispetto a più valutazioni dell'espressione sottostante nel piano di esecuzione della query. La figura 1 presenta i piani di esecuzione grafici per i tre lotti (fare clic per ingrandire).
 Figura 1:piani di esecuzione grafici per Batch 1, Batch 2 e Batch 3
Figura 1:piani di esecuzione grafici per Batch 1, Batch 2 e Batch 3
Sfortunatamente, nessuna gioia dai piani di esecuzione grafica; sembrano tutti identici anche se, semanticamente, i tre batch non hanno significati identici. Grazie a @CodeRecce e Forrest (@tsqladdict), come community siamo riusciti ad andare fino in fondo con altri mezzi.
Come ha scoperto @CodeRecce, i piani XML contengono la risposta. Ecco le parti rilevanti dell'XML per i tre batch:
−− Lotto 1
…
…
−− Lotto 2
…
…
−− Lotto 3
…
…
Puoi vedere chiaramente nel piano XML per Batch 1 che il predicato del filtro confronta i risultati di due chiamate dirette separate della funzione intrinseca SYSDATETIME.
Nel piano XML per Batch 2, il predicato del filtro confronta l'espressione costante ConstExpr1002 che rappresenta una chiamata della funzione SYSDATETIME con se stessa.
Nel piano XML per Batch 3, il predicato del filtro confronta due diverse espressioni costanti denominate ConstExpr1005 e ConstExpr1006, ciascuna delle quali rappresenta un'invocazione separata della funzione SYSDATETIME.
Come un'altra opzione, Forrest (@tsqladdict) ha suggerito di utilizzare il flag di traccia 8605, che mostra la rappresentazione iniziale dell'albero delle query creata da SQL Server, dopo aver abilitato il flag di traccia 3604 che fa sì che l'output di TF 8605 venga indirizzato al client SSMS. Utilizzare il codice seguente per abilitare entrambi i flag di traccia:
DBCC TRACEON(3604); -- direct output to client GO DBCC TRACEON(8605); -- show initial query tree GO
Quindi esegui il codice per il quale vuoi ottenere l'albero delle query. Ecco le parti rilevanti dell'output che ho ottenuto da TF 8605 per i tre lotti:
−− Lotto 1
*** Albero convertito:***
LogOp_Project COL:Espr1000
LogOp_Select
LogOp_ConstTableGet (1) [vuoto]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Espr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Non di proprietà,Valore=1)
−− Lotto 2
*** Albero convertito:***
LogOp_Project COL:Espr1001
LogOp_Select
LogOp_ViewAncora
LogOp_Progetto
LogOp_ConstTableGet (1) [vuoto]
AncOp_PrjList
AncOp_PrjEl COL:Espr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Espr1000
ScaOp_Identifier COL:Espr1000
AncOp_PrjList
AncOp_PrjEl COL:Espr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Non di proprietà,Valore=1)
−− Lotto 3
*** Albero convertito:***
LogOp_Project COL:Espr1004
LogOp_Select
LogOp_ConstTableGet (1) [vuoto]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Espr1001
LogOp_Progetto
LogOp_ViewAncora
LogOp_Progetto
LogOp_ConstTableGet (1) [vuoto]
AncOp_PrjList
AncOp_PrjEl COL:Espr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Espr1001
ScaOp_Identifier COL:Espr1000
ScaOp_Subquery COL:Espr1003
LogOp_Progetto
LogOp_ViewAncora
LogOp_Progetto
LogOp_ConstTableGet (1) [vuoto]
AncOp_PrjList
AncOp_PrjEl COL:Espr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Espr1003
ScaOp_Identifier COL:Espr1002
AncOp_PrjList
AncOp_PrjEl COL:Espr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Non di proprietà,Valore=1)
In Batch 1, puoi vedere un confronto tra i risultati di due valutazioni separate della funzione intrinseca SYSDATETIME.
In Batch 2, viene visualizzata una valutazione della funzione risultante in una colonna denominata Espr1000, quindi un confronto tra questa colonna e se stessa.
In Batch 3 vengono visualizzate due valutazioni separate della funzione. Uno nella colonna denominata Expr1000 (successivamente proiettato dalla colonna della sottoquery denominata Expr1001). Un altro nella colonna denominata Expr1002 (successivamente proiettato dalla colonna della sottoquery denominata Expr1003). Quindi hai un confronto tra Espr1001 ed Espr1003.
Quindi, scavando un po' di più oltre ciò che espone il piano di esecuzione grafico, puoi effettivamente capire quando un'espressione sottostante viene valutata solo una volta rispetto a più volte. Ora che hai compreso i diversi casi, puoi sviluppare le tue soluzioni in base al comportamento desiderato che stai cercando.
Funzioni di finestra con ordine non deterministico
Esiste un'altra classe di calcoli che possono metterti nei guai se utilizzati in soluzioni con più riferimenti allo stesso CTE. Queste sono funzioni della finestra che si basano su un ordinamento non deterministico. Prendi come esempio la funzione della finestra ROW_NUMBER. Se utilizzato con ordini parziali (ordinando per elementi che non identificano in modo univoco la riga), ogni valutazione della query sottostante potrebbe comportare una diversa assegnazione dei numeri di riga anche se i dati sottostanti non sono cambiati. Con più riferimenti CTE, ricorda che ciascuno viene annullato separatamente e potresti ottenere set di risultati diversi. A seconda di cosa fa la query esterna con ciascun riferimento, ad es. con quali colonne di ciascun riferimento interagisce e come, l'ottimizzatore può decidere di accedere ai dati per ciascuna delle istanze utilizzando indici diversi con requisiti di ordinamento diversi.
Considera il codice seguente come esempio:
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Questa query può mai restituire un set di risultati non vuoto? Forse la tua reazione iniziale è che non può. Ma pensa a ciò che ho appena spiegato un po' più attentamente e ti renderai conto che, almeno in teoria, a causa dei due processi di disannidamento CTE separati che avranno luogo qui, uno di C1 e un altro di C2, è possibile. Tuttavia, una cosa è teorizzare che qualcosa può succedere e un'altra è dimostrarlo. Ad esempio, quando ho eseguito questo codice senza creare nuovi indici, continuavo a ottenere un set di risultati vuoto:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Ho ottenuto il piano mostrato nella Figura 23 per questa query.
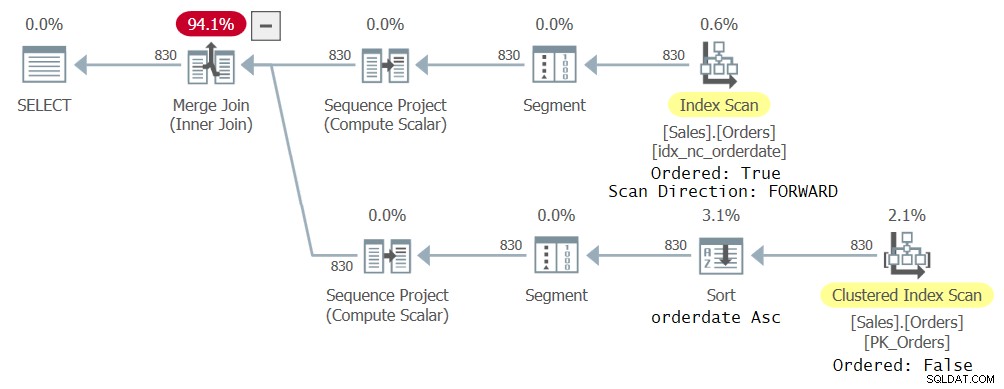 Figura 2:primo piano per la query con due riferimenti CTE
Figura 2:primo piano per la query con due riferimenti CTE
Ciò che è interessante notare qui è che l'ottimizzatore ha scelto di utilizzare indici diversi per gestire i diversi riferimenti CTE perché è quello che ha ritenuto ottimale. Dopotutto, ogni riferimento nella query esterna riguarda un diverso sottoinsieme delle colonne CTE. Un riferimento ha prodotto una scansione in avanti ordinata dell'indice idx_nc_orderedate e l'altro in una scansione non ordinata dell'indice cluster seguito da un'operazione di ordinamento per data dell'ordine crescente. Anche se l'indice idx_nc_orderedate è definito esplicitamente solo nella colonna orderdate come chiave, in pratica è definito su (orderdate, orderid) come chiavi poiché orderid è la chiave dell'indice cluster ed è inclusa come ultima chiave in tutti gli indici non cluster. Quindi una scansione ordinata dell'indice emette effettivamente le righe ordinate per orderdate, orderid. Per quanto riguarda la scansione non ordinata dell'indice cluster, a livello di motore di archiviazione, i dati vengono scansionati in base all'ordine delle chiavi di indice (basato su orderid) per soddisfare le aspettative di coerenza minima del livello di isolamento predefinito read commit. L'operatore Sort quindi ingerisce i dati ordinati per orderid, ordina le righe per orderdate e in pratica finisce per emettere le righe ordinate per orderdate, orderid.
Ancora una volta, in teoria non vi è alcuna garanzia che i due riferimenti rappresentino sempre lo stesso set di risultati anche se i dati sottostanti non cambiano. Un modo semplice per dimostrarlo consiste nell'organizzare due diversi indici ottimali per i due riferimenti, ma in uno si ordinano i dati per data dell'ordine ASC, ID dell'ordine ASC e l'altro ordinano i dati per data dell'ordine DESC, ID dell'ordine ASC (o esattamente il contrario). Abbiamo già il precedente indice in atto. Ecco il codice per creare quest'ultimo:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
Esegui il codice una seconda volta dopo aver creato l'indice:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Ho ottenuto il seguente output durante l'esecuzione di questo codice dopo aver creato il nuovo indice:
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
Ops.
Esaminare il piano di query per questa esecuzione come mostrato nella Figura 3:
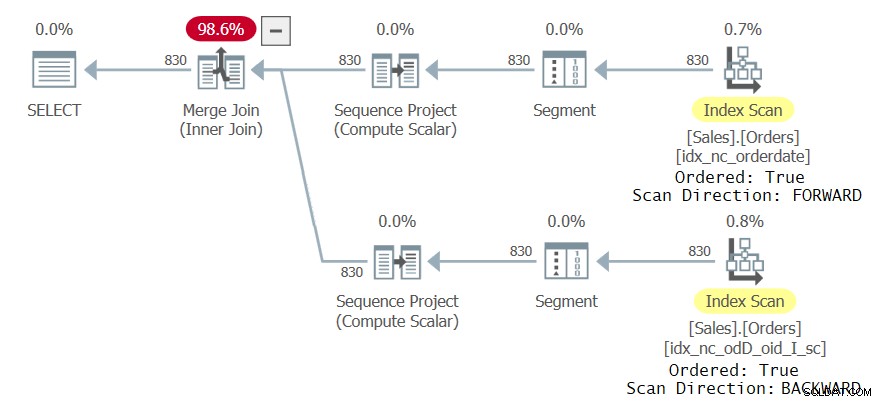 Figura 3:Secondo piano per query con due riferimenti CTE
Figura 3:Secondo piano per query con due riferimenti CTE
Si noti che il ramo superiore del piano esegue la scansione dell'indice idx_nc_orderdate in modo ordinato, facendo in modo che l'operatore Sequence Project che calcola i numeri di riga ingerisca i dati in pratica ordinati per orderdate ASC, orderid ASC. Il ramo inferiore del piano esegue la scansione del nuovo indice idx_nc_odD_oid_I_sc in modo ordinato all'indietro, facendo in modo che l'operatore Sequence Project acquisisca i dati in pratica ordinati per data dell'ordine ASC, ID dell'ordine DESC. Ciò si traduce in una diversa disposizione dei numeri di riga per i due riferimenti CTE ogni volta che è presente più di un'occorrenza dello stesso valore orderdate. Di conseguenza, la query genera un set di risultati non vuoto.
Se vuoi evitare tali bug, un'opzione ovvia è quella di rendere persistente il risultato della query interna in un oggetto temporaneo come una tabella temporanea o una variabile di tabella. Tuttavia, se hai una situazione in cui preferisci continuare a utilizzare i CTE, una soluzione semplice è utilizzare l'ordine totale nella funzione finestra aggiungendo un tiebreaker. In altre parole, assicurati di ordinare in base a una combinazione di espressioni che identifichi in modo univoco una riga. Nel nostro caso, puoi semplicemente aggiungere orderid in modo esplicito come tiebreaker, in questo modo:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Ottieni un set di risultati vuoto come previsto:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Senza aggiungere altri indici, ottieni il piano mostrato nella Figura 4:
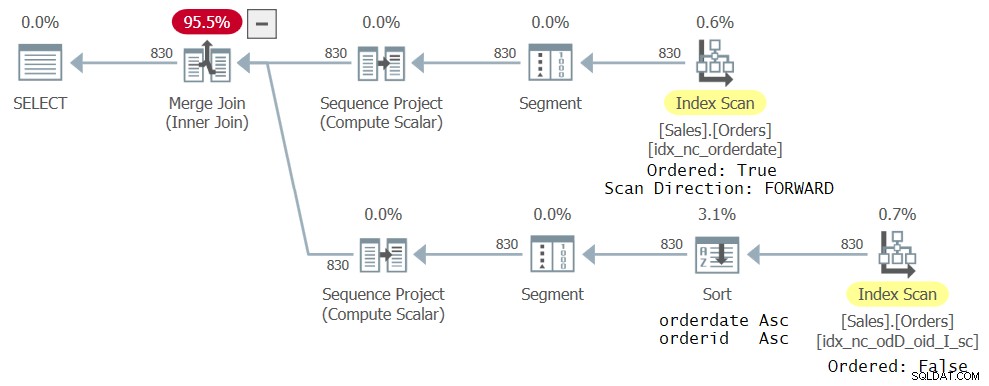 Figura 4:terzo piano per query con due riferimenti CTE
Figura 4:terzo piano per query con due riferimenti CTE
Il ramo superiore del piano è lo stesso del piano precedente mostrato nella Figura 3. Il ramo inferiore è però leggermente diverso. Il nuovo indice creato in precedenza non è proprio l'ideale per la nuova query, nel senso che non ha i dati ordinati come necessita la funzione ROW_NUMBER (orderdate, orderid). È ancora l'indice di copertura più stretto che l'ottimizzatore potrebbe trovare per il rispettivo riferimento CTE, quindi è selezionato; tuttavia, viene scansionato in modo ordinato:falso. Un operatore di ordinamento esplicito quindi ordina i dati per data dell'ordine, ID dell'ordine come richiesto dal calcolo ROW_NUMBER. Naturalmente, è possibile modificare la definizione dell'indice per fare in modo che sia orderdate che orderid utilizzino la stessa direzione e in questo modo l'ordinamento esplicito verrà eliminato dal piano. Il punto principale, tuttavia, è che utilizzando l'ordine totale eviti di avere problemi a causa di questo bug specifico.
Al termine, esegui il codice seguente per la pulizia:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;
Conclusione
È importante comprendere che più riferimenti allo stesso CTE da una query esterna determinano valutazioni separate della query interna del CTE. Prestare particolare attenzione con i calcoli non deterministici, poiché le diverse valutazioni potrebbero comportare valori diversi.
Quando utilizzi funzioni di finestra come ROW_NUMBER e aggregati con una cornice, assicurati di utilizzare l'ordine totale per evitare di ottenere risultati diversi per la stessa riga nei diversi riferimenti CTE.