All'inizio di questo mese, ho pubblicato un suggerimento su qualcosa che probabilmente tutti vorremmo non dover fare:ordinare o rimuovere i duplicati da stringhe delimitate, che in genere coinvolgono funzioni definite dall'utente (UDF). A volte è necessario riassemblare l'elenco (senza i duplicati) in ordine alfabetico e talvolta può essere necessario mantenere l'ordine originale (potrebbe essere l'elenco delle colonne chiave in un indice errato, ad esempio).
Per la mia soluzione, che affronta entrambi gli scenari, ho utilizzato una tabella di numeri, insieme a una coppia di funzioni definite dall'utente (UDF):una per dividere la stringa, l'altra per riassemblarla. Puoi vedere quel suggerimento qui:
- Rimozione dei duplicati dalle stringhe in SQL Server
Naturalmente, ci sono diversi modi per risolvere questo problema; Stavo semplicemente fornendo un metodo per provare se sei bloccato con quei dati della struttura. @Phil_Factor di Red-Gate ha proseguito con un rapido post che mostra il suo approccio, che evita le funzioni e la tabella dei numeri, optando invece per la manipolazione XML inline. Dice che preferisce avere query a istruzione singola ed evitare sia le funzioni che l'elaborazione riga per riga:
- Deduplicazione degli elenchi delimitati in SQL Server
Quindi un lettore, Steve Mangiameli, ha pubblicato una soluzione di loop come commento sul suggerimento. Il suo ragionamento era che l'uso di una tabella numerica gli sembrava esagerato.
Tutti e tre non siamo riusciti ad affrontare un aspetto di questo che di solito sarà piuttosto importante se esegui l'attività abbastanza spesso oa qualsiasi livello di scala:prestazioni .
Test
Curioso di vedere come si sarebbero comportati bene l'XML in linea e gli approcci di looping rispetto alla mia soluzione basata su tabelle di numeri, ho costruito una tabella fittizia per eseguire alcuni test; il mio obiettivo era 5.000 righe, con una lunghezza media della stringa maggiore di 250 caratteri e almeno 10 elementi in ogni stringa. Con un ciclo molto breve di esperimenti, sono stato in grado di ottenere qualcosa di molto simile a questo con il seguente codice:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Ciò ha prodotto una tabella con righe di esempio simili a questa (valori troncati):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
I dati nel loro insieme avevano il profilo seguente, che dovrebbe essere sufficientemente buono da scoprire eventuali problemi di prestazioni potenziali:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Nota che sono passato a varchar qui da nvarchar nell'articolo originale, perché i campioni forniti da Phil e Steve presumevano varchar , stringhe che terminano solo a 255 o 8000 caratteri, delimitatori di un solo carattere, ecc. Ho imparato la mia lezione nel modo più duro, che se hai intenzione di prendere la funzione di qualcuno e includerla nei confronti delle prestazioni, cambi anche solo possibile – idealmente niente. In realtà userei sempre nvarchar e non presumere nulla sulla stringa più lunga possibile. In questo caso sapevo che non stavo perdendo alcun dato perché la stringa più lunga è di soli 2.905 caratteri e in questo database non ho tabelle o colonne che utilizzano caratteri Unicode.
Successivamente, ho creato le mie funzioni (che richiedono una tabella di numeri). Un lettore ha individuato un problema nella funzione nel mio suggerimento, in cui ho ipotizzato che il delimitatore sarebbe sempre stato un singolo carattere e l'ho corretto qui. Ho anche convertito quasi tutto in varchar(8000) per livellare il campo di gioco in termini di tipi di corde e lunghezze.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Successivamente, ho creato una singola funzione inline con valori di tabella che combinava le due funzioni precedenti, cosa che ora vorrei aver fatto nell'articolo originale, al fine di evitare del tutto la funzione scalare. (Anche se è vero che non tutti le funzioni scalari sono terribili su larga scala, ci sono pochissime eccezioni.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Ho anche creato versioni separate dell'inline TVF dedicate a ciascuna delle due scelte di ordinamento, al fine di evitare la volatilità del CASE espressione, ma si è rivelato non avere affatto un impatto drammatico.
Poi ho creato le due funzioni di Steve:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Quindi ho inserito le query dirette di Phil nel mio banco di prova (nota che le sue query codificano < come < per proteggerli da errori di analisi XML, ma non codificano > o & – Ho aggiunto dei segnaposto nel caso in cui sia necessario proteggersi dalle stringhe che possono potenzialmente contenere quei caratteri problematici):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Il banco di prova consisteva sostanzialmente in queste due query e anche nelle seguenti chiamate di funzione. Dopo aver verificato che tutti restituivano gli stessi dati, ho intervallato lo script con DATEDIFF output e registrato in una tabella:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Quindi ho eseguito i test delle prestazioni su due sistemi diversi (un quad core con 8 GB e una VM a 8 core con 32 GB) e, in ogni caso, su SQL Server 2012 e SQL Server 2016 CTP 3.2 (13.0.900.73).
Risultati
I risultati che ho osservato sono riassunti nel grafico seguente, che mostra la durata in millisecondi di ciascun tipo di query, la media dell'ordine alfabetico e originale, le quattro combinazioni server/versione e una serie di 15 esecuzioni per ciascuna permutazione. Clicca per ingrandire:
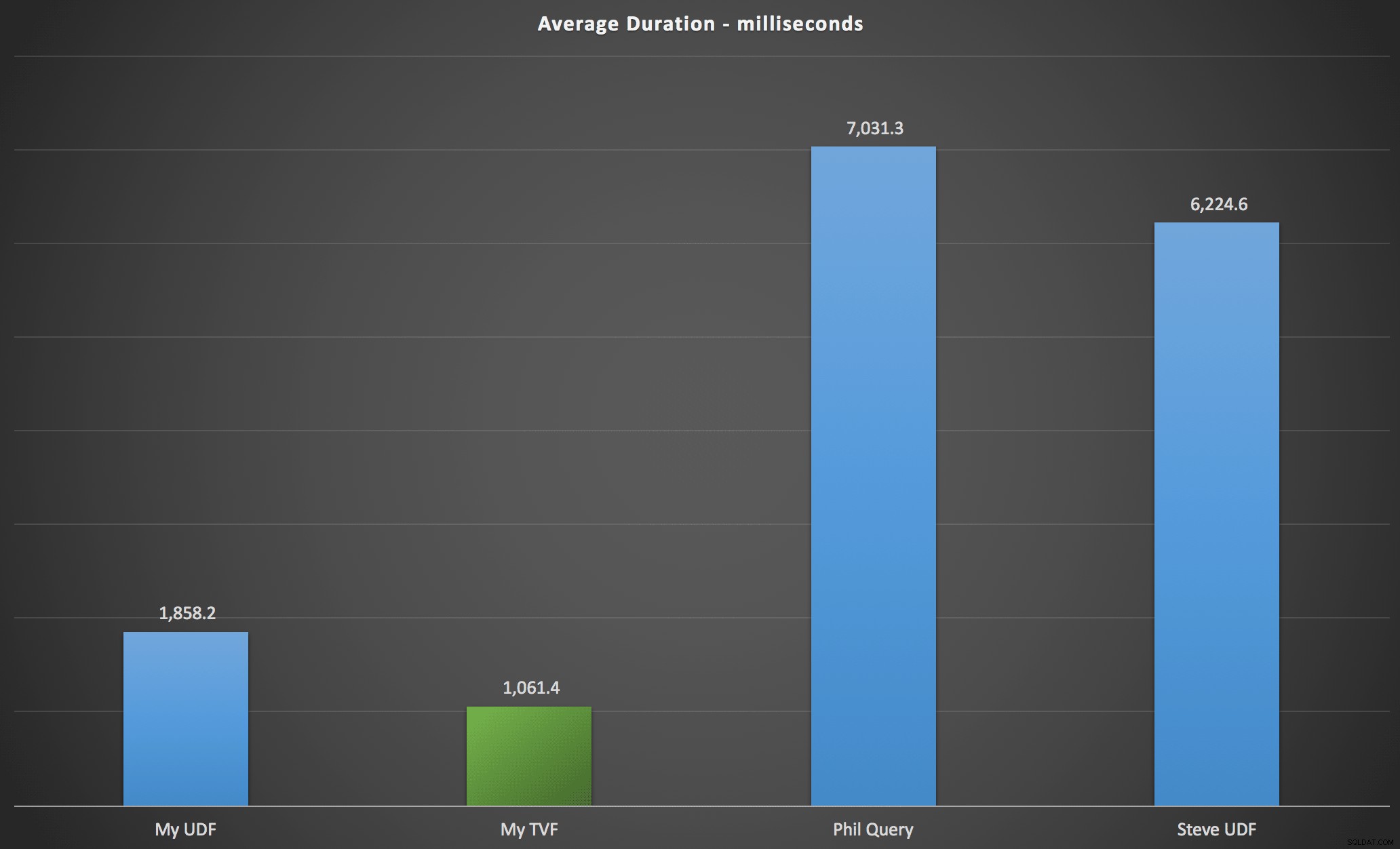
Ciò mostra che la tabella dei numeri, sebbene ritenuta eccessivamente ingegnerizzata, ha effettivamente prodotto la soluzione più efficiente (almeno in termini di durata). Questo era meglio, ovviamente, con il singolo TVF che ho implementato più di recente rispetto alle funzioni nidificate dell'articolo originale, ma entrambe le soluzioni girano attorno alle due alternative.
Per entrare più nel dettaglio, ecco i dettagli per ogni macchina, versione e tipo di query, per mantenere l'ordine originale:
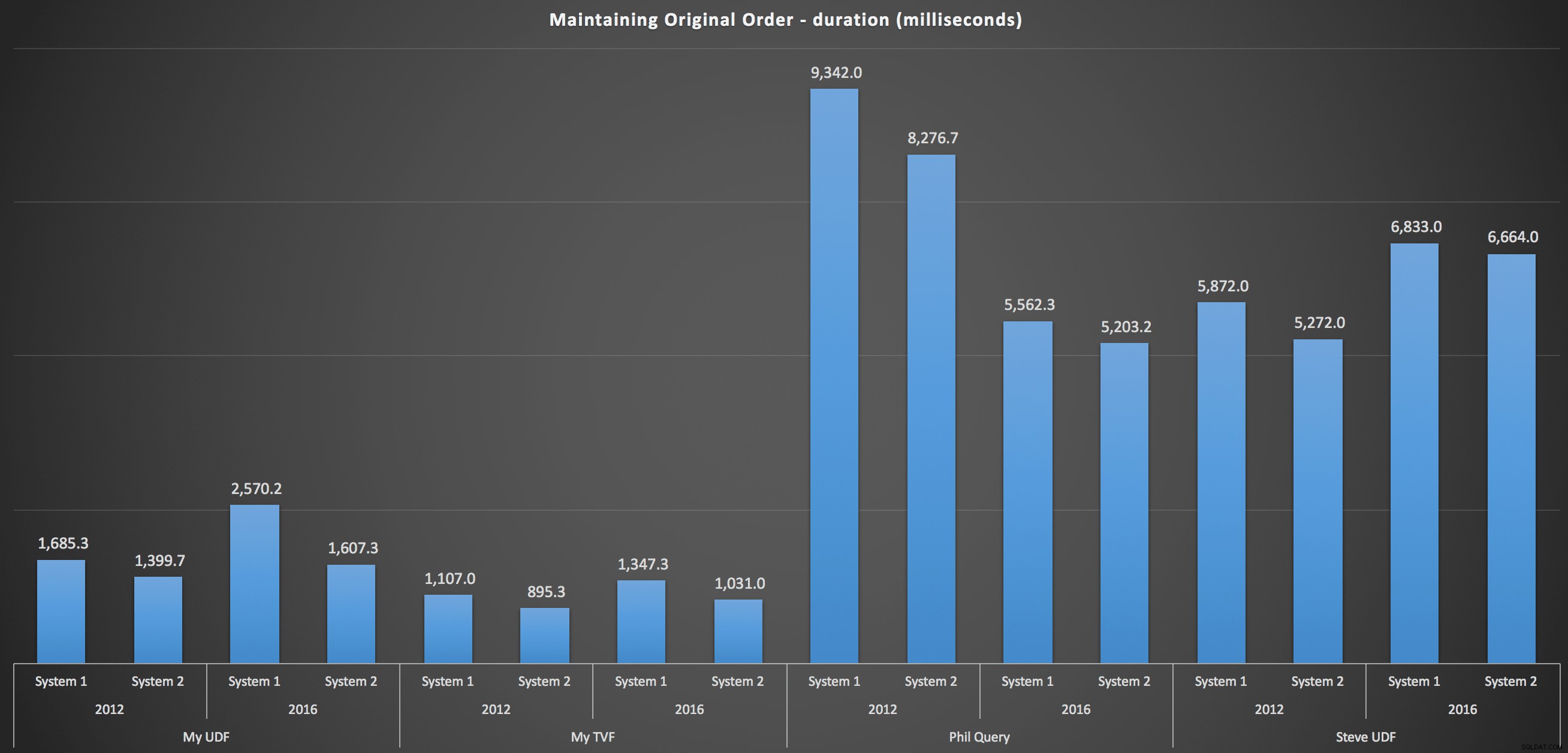
…e per ricomporre l'elenco in ordine alfabetico:
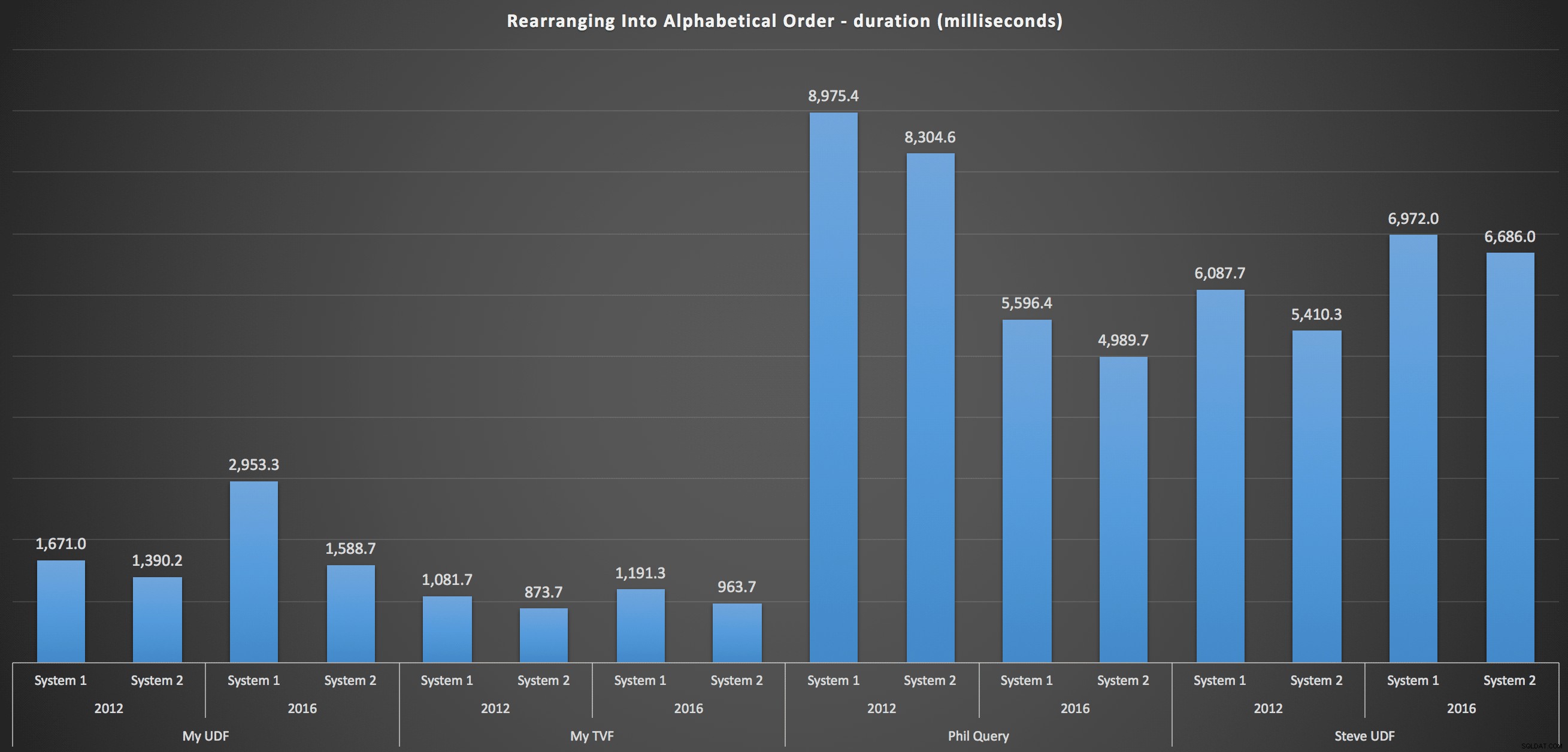
Questi mostrano che la scelta di ordinamento ha avuto scarso impatto sul risultato:entrambi i grafici sono praticamente identici. E questo ha senso perché, data la forma dei dati di input, non c'è alcun indice che posso immaginare che renderebbe l'ordinamento più efficiente:è un approccio iterativo, indipendentemente da come lo si taglia o come si restituiscono i dati. Ma è chiaro che alcuni approcci iterativi possono essere generalmente peggiori di altri e non è necessariamente l'uso di una UDF (o di una tabella di numeri) che li rende tali.
Conclusione
Fino a quando non avremo la funzionalità di divisione e concatenazione nativa in SQL Server, utilizzeremo tutti i tipi di metodi non intuitivi per portare a termine il lavoro, comprese le funzioni definite dall'utente. Se stai gestendo una singola stringa alla volta, non vedrai molta differenza. Ma man mano che i tuoi dati aumentano, varrà la pena testare vari approcci (e non sto affatto suggerendo che i metodi sopra siano i migliori che troverai – non ho nemmeno guardato CLR, ad esempio, o altri approcci T-SQL di questa serie).