Probabilmente hai commesso alcuni di questi errori quando stavi iniziando la tua carriera nella progettazione di database. Forse li stai ancora realizzando, o ne farai alcuni in futuro. Non possiamo tornare indietro nel tempo e aiutarti a cancellare i tuoi errori, ma possiamo salvarti da alcuni grattacapi futuri (o presenti).
Leggere questo articolo potrebbe farti risparmiare molte ore dedicate alla risoluzione di problemi di progettazione e codice, quindi tuffiamoci. Ho diviso l'elenco degli errori in due gruppi principali:quelli che sono non tecnici di natura e quelli strettamente tecnici . Entrambi questi gruppi sono una parte importante della progettazione del database.
Ovviamente, se non hai competenze tecniche, non saprai come fare qualcosa. Non sorprende vedere questi errori nell'elenco. Ma competenze non tecniche? Le persone potrebbero dimenticarsene, ma queste abilità sono anche una parte molto importante del processo di progettazione. Aggiungono valore al tuo codice e mettono in relazione la tecnologia con il problema del mondo reale che devi risolvere.
Quindi, iniziamo prima con i problemi non tecnici, quindi passiamo a quelli tecnici.
Errori non tecnici di progettazione del database
#1 Scarsa pianificazione
Questo è sicuramente un problema non tecnico, ma è un problema importante e comune. Siamo tutti entusiasti quando inizia un nuovo progetto e, entrandoci, tutto sembra fantastico. All'inizio, il progetto è ancora una pagina bianca e tu e il tuo cliente siete felici di iniziare a lavorare su qualcosa che creerà un futuro migliore per entrambi. Tutto ciò è grandioso e probabilmente il risultato finale sarà un grande futuro. Tuttavia, dobbiamo rimanere concentrati. Questa è la parte del progetto in cui possiamo commettere errori cruciali.
Prima di sederti per disegnare un modello di dati, devi essere sicuro che:
- Sei completamente consapevole di ciò che fa il tuo cliente (ovvero i suoi piani aziendali relativi a questo progetto e anche il suo quadro generale) e cosa vuole che questo progetto ottenga ora e in futuro.
- Comprendi il processo aziendale e, se o quando necessario, sei pronto a dare suggerimenti per semplificarlo e migliorarlo (ad es. per aumentare l'efficienza e le entrate, ridurre i costi e l'orario di lavoro, ecc.).
- Comprendi il flusso di dati nell'azienda del cliente. Idealmente, dovresti conoscere ogni dettaglio:chi lavora con i dati, chi apporta modifiche, quali rapporti sono necessari, quando e perché tutto ciò accade.
- Puoi usare la lingua/la terminologia utilizzata dal tuo cliente. Anche se potresti essere o meno un esperto nella loro area, il tuo cliente lo è sicuramente. Chiedi loro di spiegare ciò che non capisci. E quando spieghi i dettagli tecnici al cliente, usa un linguaggio e una terminologia che lui capisca.
- Sai quali tecnologie utilizzerai, dal motore di database e linguaggi di programmazione ad altri strumenti. Ciò che decidi di utilizzare è strettamente correlato al problema che risolverai, ma è importante includere le preferenze del cliente e la sua attuale infrastruttura IT.
Durante la fase di pianificazione, dovresti ottenere risposte a queste domande:
- Quali tavoli saranno i tavoli centrali nel tuo modello? Probabilmente ne avrai alcuni, mentre le altre tabelle saranno alcune delle solite (es. user_account, role). Non dimenticare i dizionari e le relazioni tra le tabelle.
- Quali nomi verranno utilizzati per le tabelle nel modello? Ricorda di mantenere la terminologia simile a quella attualmente utilizzata dal client.
- Quali regole verranno applicate durante la denominazione di tabelle e altri oggetti? (Vedi il punto 4 sulle convenzioni di denominazione.)
- Quanto durerà l'intero progetto? Questo è importante, sia per il tuo programma che per la sequenza temporale del cliente.
Solo quando hai tutte queste risposte sei pronto per condividere una prima soluzione al problema. Questa soluzione non deve necessariamente essere un'applicazione completa, magari un breve documento o anche alcune frasi nella lingua dell'attività del cliente.
Una buona pianificazione non è specifica per la modellazione dei dati; è applicabile a quasi tutti i progetti IT (e non). Saltare è solo un'opzione se 1) hai un progetto davvero piccolo; 2) i compiti e gli obiettivi sono chiari e 3) hai molta fretta. Un esempio storico sono gli ingegneri di lancio dello Sputnik 1 che danno istruzioni verbali ai tecnici che lo stavano assemblando. Il progetto andava di fretta a causa della notizia che gli Stati Uniti stavano pianificando di lanciare presto il proprio satellite, ma immagino che non avrai tanta fretta.
#2 Comunicazione insufficiente con clienti e sviluppatori
Quando inizi il processo di progettazione del database, probabilmente capirai la maggior parte dei requisiti principali. Alcuni sono molto comuni indipendentemente dall'attività, ad es. ruoli e stati degli utenti. D'altra parte, alcune tabelle nel tuo modello saranno piuttosto specifiche. Ad esempio, se stai costruendo un modello per una compagnia di taxi, avrai tabelle per veicoli, conducenti, clienti ecc.
Tuttavia, non tutto sarà ovvio all'inizio di un progetto. Potresti fraintendere alcuni requisiti, il client potrebbe aggiungere alcune nuove funzionalità, vedrai qualcosa che potrebbe essere fatto diversamente, il processo potrebbe cambiare, ecc. Tutto ciò causa cambiamenti nel modello. La maggior parte delle modifiche richiede l'aggiunta di nuove tabelle, ma a volte rimuoverai o modificherai le tabelle. Se hai già iniziato a scrivere codice che utilizza queste tabelle, dovrai riscrivere anche quel codice.
Per ridurre il tempo dedicato a modifiche impreviste, dovresti:
- Parla con sviluppatori e clienti e non aver paura di porre domande aziendali vitali. Quando pensi di essere pronto per iniziare, chiediti La situazione X è inclusa nel nostro database? Il client sta attualmente facendo Y in questo modo; ci aspettiamo un cambiamento nel prossimo futuro? Una volta che siamo sicuri che il nostro modello è in grado di memorizzare tutto ciò di cui abbiamo bisogno nel modo giusto, possiamo iniziare a codificare.
- Se devi affrontare un cambiamento importante nel tuo design e hai già molto codice scritto, non dovresti provare a risolverlo rapidamente. Fallo come avrebbe dovuto essere fatto, indipendentemente dalla situazione attuale. Una soluzione rapida potrebbe far risparmiare tempo e probabilmente funzionerebbe bene per un po', ma in seguito può trasformarsi in un vero incubo.
- Se pensi che qualcosa vada bene ora ma potrebbe diventare un problema in seguito, non ignorarlo. Analizza quell'area e implementa le modifiche se miglioreranno la qualità e le prestazioni del sistema. Ci vorrà del tempo, ma fornirai un prodotto migliore e dormirai molto meglio.
Se cerchi di evitare di apportare modifiche al tuo modello di dati quando vedi un potenziale problema, o se opti per una soluzione rapida invece di farlo correttamente, prima o poi pagherai per questo.
Inoltre, rimani in contatto con il tuo cliente e gli sviluppatori durante tutto il progetto. Controlla sempre e verifica se sono state apportate modifiche rispetto all'ultima discussione.
#3 Documentazione scarsa o mancante
Per la maggior parte di noi, la documentazione arriva alla fine del progetto. Se siamo ben organizzati, probabilmente abbiamo documentato le cose lungo il percorso e dovremo solo concludere tutto. Ma onestamente, di solito non è così. La scrittura della documentazione avviene appena prima della chiusura del progetto e subito dopo che abbiamo mentalmente finito con quel modello di dati!
Il prezzo pagato per un progetto scarsamente documentato può essere piuttosto alto, alcune volte superiore al prezzo che paghiamo per documentare tutto correttamente. Immagina di trovare un bug pochi mesi dopo aver chiuso il progetto. Poiché non hai documentato correttamente, non sai da dove cominciare.
Mentre lavori, non dimenticare di scrivere commenti. Spiega tutto ciò che necessita di ulteriori spiegazioni e in pratica scrivi tutto ciò che ritieni possa essere utile un giorno. Non sai mai se o quando avrai bisogno di queste informazioni extra.
Errori di progettazione del database tecnico
#4 Non utilizzare una convenzione di denominazione
Non sai mai con certezza quanto durerà un progetto e se avrai più di una persona che lavora sul modello di dati. C'è un punto in cui sei davvero vicino al modello di dati, ma non hai ancora iniziato a disegnarlo. Questo è il momento in cui è opportuno decidere come assegnare un nome agli oggetti nel modello, nel database e nell'applicazione generale. Prima di modellare, dovresti sapere:
- I nomi delle tabelle sono singolari o plurali?
- Raggrupperemo le tabelle usando i nomi? (Ad es. tutte le tabelle relative ai client contengono "client_", tutte le tabelle relative alle attività contengono "task_", ecc.)
- Utilizzeremo lettere maiuscole e minuscole o solo minuscole?
- Che nome utilizzeremo per le colonne ID? (Molto probabilmente sarà "id".)
- Come nomineremo le chiavi esterne? (Molto probabilmente "id_" e il nome della tabella di riferimento.)
Confronta parte di un modello che non utilizza le convenzioni di denominazione con la stessa parte che utilizza le convenzioni di denominazione, come mostrato di seguito:
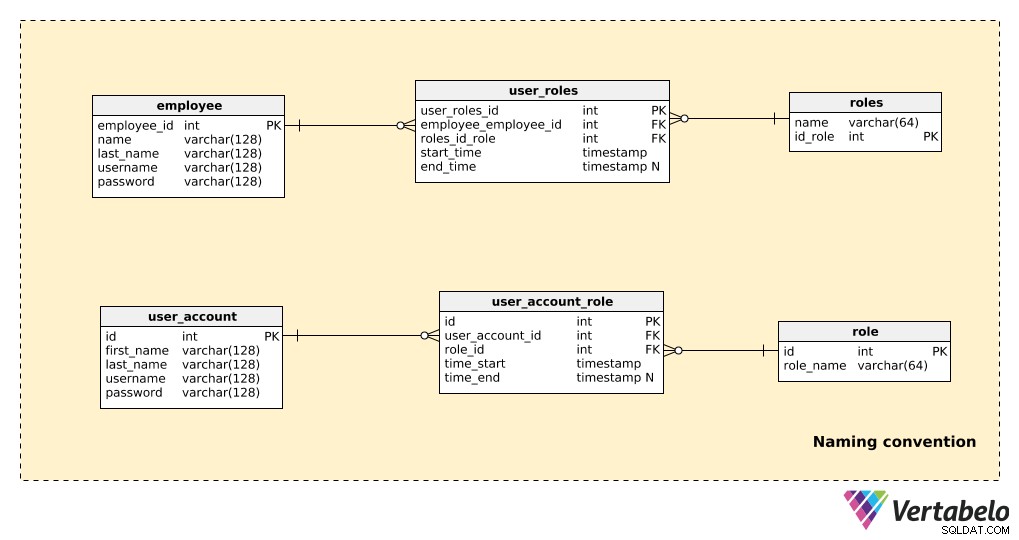
Ci sono solo poche tabelle qui, ma è ancora abbastanza ovvio quale modello è più facile da leggere. Si noti che:
- Entrambi i modelli “funzionano”, quindi non ci sono problemi dal punto di vista tecnico.
- Nell'esempio della convenzione di non denominazione (le tre tabelle superiori), ci sono alcune cose che incidono in modo significativo sulla leggibilità:usare sia la forma singolare che quella plurale nei nomi delle tabelle; nomi di chiavi primarie non standardizzate (
employees_id,id_role); e gli attributi in tabelle diverse condividono lo stesso nome (ad es. il nome appare in entrambi i "employee" e i "roles” tabelle).
Ora immagina il pasticcio che creeremmo se il nostro modello contenesse centinaia di tabelle. Forse potremmo lavorare con un modello del genere (se lo creassimo noi stessi), ma saremmo molto sfortunati a qualcuno se dovessero lavorarci dopo di noi.
Per evitare problemi futuri con i nomi, non utilizzare parole riservate SQL, caratteri speciali o spazi al loro interno.
Quindi, prima di iniziare a creare qualsiasi nome, crea un semplice documento (magari lungo solo poche pagine) che descriva la convenzione di denominazione che hai utilizzato. Ciò aumenterà la leggibilità dell'intero modello e semplificherà il lavoro futuro.
Puoi leggere ulteriori informazioni sulle convenzioni di denominazione in questi due articoli:
- Convenzioni di denominazione nella modellazione di database
- Uno sguardo logico senza emozioni alle convenzioni di denominazione di SQL Server
Problemi di normalizzazione n. 5
La normalizzazione è una parte essenziale della progettazione del database. Ogni database deve essere normalizzato ad almeno 3NF (le chiavi primarie sono definite, le colonne sono atomiche e non ci sono gruppi ripetuti, dipendenze parziali o dipendenze transitive). Ciò riduce la duplicazione dei dati e garantisce l'integrità referenziale.
Puoi leggere di più sulla normalizzazione in questo articolo. In breve, ogni volta che si parla di modello di database relazionale, si parla di database normalizzato. Se un database non viene normalizzato, ci imbatteremo in una serie di problemi relativi all'integrità dei dati.
In alcuni casi, potremmo voler denormalizzare il nostro database. Se lo fai, hai davvero una buona ragione. Puoi leggere ulteriori informazioni sulla denormalizzazione del database qui.
#6 Utilizzo del modello Entity-Attribute-Value (EAV)
EAV sta per entità-attributo-valore. Questa struttura può essere utilizzata per memorizzare dati aggiuntivi su qualsiasi cosa nel nostro modello. Diamo un'occhiata a un esempio.
Supponiamo di voler memorizzare alcuni attributi aggiuntivi del cliente. Il “customer ” è la nostra entità, l'“attribute ” è ovviamente il nostro attributo e il “attribute_value ” contiene il valore di tale attributo per quel cliente.
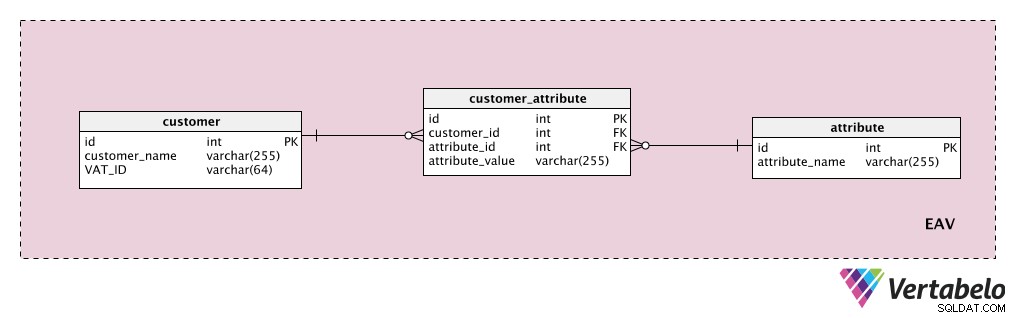
Innanzitutto, aggiungeremo un dizionario con un elenco di tutte le possibili proprietà che potremmo assegnare a un cliente. Questo è l'“attribute " tavolo. Potrebbe contenere proprietà come "valore del cliente", "dettagli di contatto", "informazioni aggiuntive" ecc. Il "customer_attribute La tabella contiene un elenco di tutti gli attributi, con valori, per ciascun cliente. Per ogni cliente, avremo record solo per gli attributi che ha e memorizzeremo il "attribute_value ” per quell'attributo.
Questo potrebbe sembrare davvero fantastico. Ci consentirebbe di aggiungere facilmente nuove proprietà (perché le aggiungiamo come valori in “customer_attribute " tavolo). Pertanto, eviteremo di apportare modifiche al database. Quasi troppo bello per essere vero.
Ed è troppo buono. Sebbene il modello memorizzerà i dati di cui abbiamo bisogno, lavorare con tali dati è molto più complicato. E questo include quasi tutto, dalla scrittura di semplici query SELECT all'ottenimento di tutti i valori relativi ai clienti all'inserimento, all'aggiornamento o all'eliminazione di valori.
In breve, dovremmo evitare la struttura EAV. Se devi usarlo, usalo solo quando sei sicuro al 100% che sia davvero necessario.
#7 Utilizzo di un GUID/UUID come chiave primaria
Un GUID (Globally Unique Identifier) è un numero a 128 bit generato secondo le regole definite in RFC 4122. A volte sono anche conosciuti come UUID (Universaly Unique Identifiers). Il vantaggio principale di un GUID è che è unico; la possibilità che tu colpisca lo stesso GUID due volte è davvero improbabile. Pertanto, i GUID sembrano un ottimo candidato per la colonna della chiave primaria. Ma non è così.
Una regola generale per le chiavi primarie è che utilizziamo una colonna intera con la proprietà autoincrement impostata su "yes". Ciò aggiungerà i dati in ordine sequenziale alla chiave primaria e fornirà prestazioni ottimali. Senza una chiave sequenziale o un timestamp, non c'è modo di sapere quali dati sono stati inseriti per primi. Questo problema sorge anche quando utilizziamo valori UNICI del mondo reale (ad es. Partita IVA). Sebbene contengano valori UNIQUE, non costituiscono buone chiavi primarie. Usali invece come chiavi alternative.
Una nota aggiuntiva: Preferisco utilizzare attributi interi generati automaticamente a colonna singola come chiave primaria. È sicuramente la migliore pratica. Ti consiglio di evitare di utilizzare chiavi primarie composte.
#8 Indicizzazione insufficiente
Gli indici sono una parte molto importante dell'utilizzo dei database, ma una discussione approfondita su di essi esula dallo scopo di questo articolo. Fortunatamente, abbiamo già alcuni articoli relativi agli indici che puoi consultare per saperne di più:- Che cos'è un indice di database?
- All About Indexes:The Very Basics
- Tutto sugli indici, parte 2:struttura e prestazioni degli indici MySQL
La versione breve è che ti consiglio di aggiungere un indice ovunque ti aspetti che sia necessario. Puoi anche aggiungerli dopo che il database è in produzione se vedi che l'aggiunta di un indice in un determinato punto migliorerà le prestazioni.
Dati ridondanti n. 9
I dati ridondanti dovrebbero generalmente essere evitati in qualsiasi modello. Non solo occupa spazio su disco aggiuntivo, ma aumenta anche notevolmente le possibilità di problemi di integrità dei dati. Se qualcosa deve essere ridondante, dovremmo fare attenzione che i dati originali e la "copia" siano sempre in stati coerenti. In effetti, ci sono alcune situazioni in cui i dati ridondanti sono desiderabili:
- In alcuni casi, dobbiamo assegnare la priorità a una determinata azione e, per fare in modo che ciò avvenga, dobbiamo eseguire calcoli complessi. Questi calcoli potrebbero utilizzare molte tabelle e consumare molte risorse. In questi casi, sarebbe saggio eseguire questi calcoli durante le ore di riposo (evitando così problemi di prestazioni durante l'orario di lavoro). Se lo facciamo in questo modo, potremmo memorizzare quel valore calcolato e usarlo in seguito senza doverlo ricalcolare. Naturalmente, il valore è ridondante; tuttavia, ciò che guadagniamo in termini di prestazioni è molto più di ciò che perdiamo (un po' di spazio sul disco rigido).
- Potremmo anche archiviare una piccola serie di dati di reporting all'interno del database. Ad esempio, alla fine della giornata, memorizzeremo il numero di chiamate effettuate quel giorno, il numero di vendite riuscite, ecc. I dati dei rapporti dovrebbero essere archiviati in questo modo solo se è necessario utilizzarli spesso. Ancora una volta, perderemo un po' di spazio sul disco rigido, ma eviteremo di ricalcolare i dati o di collegarci al database dei rapporti (se ne abbiamo uno).
Nella maggior parte dei casi, non dovremmo utilizzare dati ridondanti perché:
- L'archiviazione degli stessi dati più di una volta nel database potrebbe influire sull'integrità dei dati. Se memorizzi il nome di un cliente in due posti diversi, dovresti apportare le modifiche (inserisci/aggiorna/elimina) in entrambi i posti contemporaneamente. Questo complica anche il codice di cui avrai bisogno, anche per le operazioni più semplici.
- Anche se potremmo memorizzare alcuni numeri aggregati nel nostro database operativo, dovremmo farlo solo quando è veramente necessario. Un database operativo non ha lo scopo di archiviare i dati di reporting e la combinazione di questi due è generalmente una cattiva pratica. Chiunque produca report dovrà utilizzare le stesse risorse degli utenti che lavorano su attività operative; le query di reporting sono in genere più complesse e possono influire sulle prestazioni. Pertanto, dovresti separare il tuo database operativo e il tuo database di reporting.
Ora tocca a te pesare
Spero che la lettura di questo articolo ti abbia fornito alcune nuove informazioni e ti incoraggi a seguire le migliori pratiche di modellazione dei dati. Ti faranno risparmiare tempo!
Hai riscontrato uno dei problemi menzionati in questo articolo? Pensi che ci siamo persi qualcosa di importante? O pensi che dovremmo rimuovere qualcosa dalla nostra lista? Per favore, dicci nei commenti qui sotto.