Nella parte 5 della mia serie sulle espressioni di tabella ho fornito la seguente soluzione per generare una serie di numeri utilizzando CTE, un costruttore di valori di tabella e incroci incrociati:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Esistono molti casi d'uso pratici per uno strumento di questo tipo, inclusa la generazione di una serie di valori di data e ora, la creazione di dati di esempio e altro ancora. Riconoscendo la necessità comune, alcune piattaforme forniscono uno strumento integrato, come la funzione generate_series di PostgreSQL. Al momento in cui scrivo, T-SQL non fornisce uno strumento così integrato, ma si può sempre sperare e votare che tale strumento venga aggiunto in futuro.
In un commento al mio articolo, Marcos Kirchner ha affermato di aver testato la mia soluzione con diverse cardinalità del costruttore di valori di tabella e ottenuto tempi di esecuzione diversi per le diverse cardinalità.
 Ho sempre usato la mia soluzione con una cardinalità del costruttore del valore della tabella di base di 2, ma il commento di Marcos mi ha fatto pensare. Questo strumento è così utile che noi come comunità dovremmo unire le forze per provare a creare la versione più veloce possibile. Testare diverse cardinalità della tabella di base è solo una dimensione da provare. Potrebbero essercene molti altri. Presenterò i test delle prestazioni che ho eseguito con la mia soluzione. Ho principalmente sperimentato diverse cardinalità del costruttore di valori di tabella, con l'elaborazione seriale rispetto a quella parallela e con l'elaborazione in modalità riga rispetto alla modalità batch. Tuttavia, potrebbe essere che una soluzione completamente diversa sia persino più veloce della mia versione migliore. Quindi, la sfida è aperta! Chiamo tutti i jedi, padawan, maghi e apprendisti allo stesso modo. Qual è la soluzione più performante che puoi evocare? Hai dentro di te per battere la soluzione più veloce pubblicata finora? In tal caso, condividi il tuo come commento a questo articolo e sentiti libero di migliorare qualsiasi soluzione pubblicata da altri.
Ho sempre usato la mia soluzione con una cardinalità del costruttore del valore della tabella di base di 2, ma il commento di Marcos mi ha fatto pensare. Questo strumento è così utile che noi come comunità dovremmo unire le forze per provare a creare la versione più veloce possibile. Testare diverse cardinalità della tabella di base è solo una dimensione da provare. Potrebbero essercene molti altri. Presenterò i test delle prestazioni che ho eseguito con la mia soluzione. Ho principalmente sperimentato diverse cardinalità del costruttore di valori di tabella, con l'elaborazione seriale rispetto a quella parallela e con l'elaborazione in modalità riga rispetto alla modalità batch. Tuttavia, potrebbe essere che una soluzione completamente diversa sia persino più veloce della mia versione migliore. Quindi, la sfida è aperta! Chiamo tutti i jedi, padawan, maghi e apprendisti allo stesso modo. Qual è la soluzione più performante che puoi evocare? Hai dentro di te per battere la soluzione più veloce pubblicata finora? In tal caso, condividi il tuo come commento a questo articolo e sentiti libero di migliorare qualsiasi soluzione pubblicata da altri.
Requisiti:
- Implementa la tua soluzione come una funzione inline con valori di tabella (iTVF) denominata dbo.GetNumsYourName con i parametri @low AS BIGINT e @high AS BIGINT. Ad esempio, vedi quelli che invierò alla fine di questo articolo.
- Se necessario, puoi creare tabelle di supporto nel database degli utenti.
- Puoi aggiungere suggerimenti secondo necessità.
- Come accennato, la soluzione dovrebbe supportare i delimitatori di tipo BIGINT, ma si può ipotizzare una cardinalità massima della serie di 4.294.967.296.
- Per valutare le prestazioni della tua soluzione e confrontarla con altre, la testerò con l'intervallo da 1 a 100.000.000, con Elimina risultati dopo l'esecuzione abilitato in SSMS.
Buona fortuna a tutti noi! Che vinca la community migliore.;)
Diverse cardinalità per il costruttore del valore della tabella di base
Ho sperimentato diverse cardinalità del CTE di base, partendo da 2 e avanzando in scala logaritmica, quadrando la cardinalità precedente in ogni passaggio:2, 4, 16 e 256.
Prima di iniziare a sperimentare con diverse cardinalità di base, potrebbe essere utile disporre di una formula che, data la cardinalità di base e la cardinalità dell'intervallo massimo, ti dica quanti livelli di CTE sono necessari. Come passaggio preliminare, è più facile trovare prima una formula che, data la cardinalità di base e il numero di livelli di CTE, calcola qual è la cardinalità massima dell'intervallo risultante. Ecco una tale formula espressa in T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Con i valori di input di esempio sopra, questa espressione produce una cardinalità massima dell'intervallo di 4.294.967.296.
Quindi, la formula inversa per calcolare il numero di livelli CTE necessari prevede l'annidamento di due funzioni di registro, in questo modo:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Con i valori di input di esempio precedenti questa espressione produce 5. Nota che questo numero è in aggiunta al CTE di base che ha il costruttore del valore della tabella, che ho chiamato L0 (per il livello 0) nella mia soluzione.
Non chiedermi come sono arrivato a queste formule. La storia a cui mi sto attenendo è che Gandalf me le ha pronunciate in elfico nei miei sogni.
Procediamo con i test delle prestazioni. Assicurati di abilitare Elimina risultati dopo l'esecuzione nella finestra di dialogo Opzioni query SSMS in Griglia, Risultati. Utilizza il codice seguente per eseguire un test con cardinalità CTE di base di 2 (richiede 5 livelli aggiuntivi di CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ho ottenuto il piano mostrato nella Figura 1 per questa esecuzione.
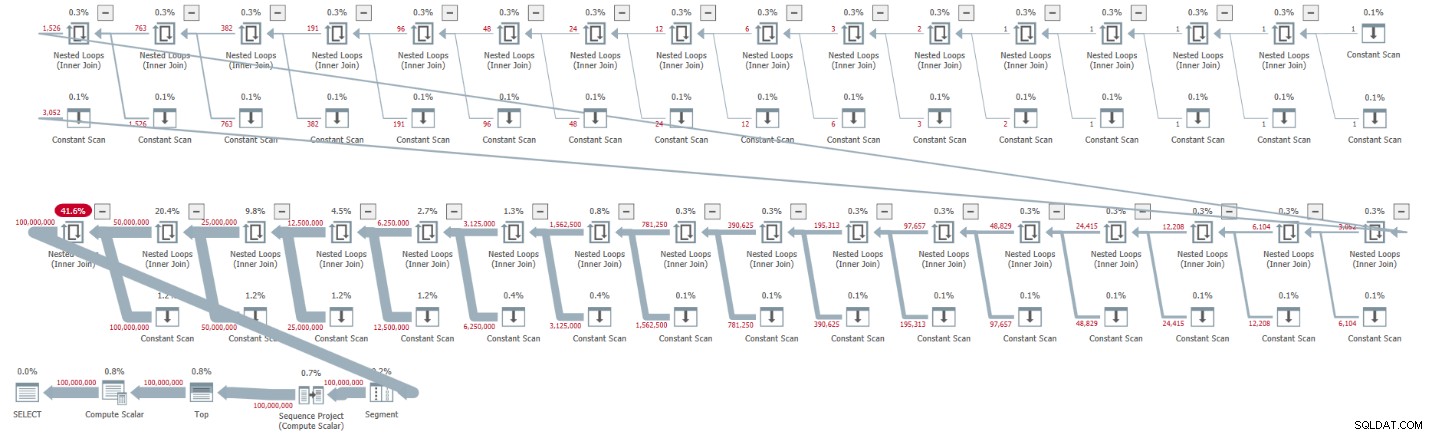 Figura 1:piano per cardinalità CTE di base di 2
Figura 1:piano per cardinalità CTE di base di 2
Il piano è seriale e tutti gli operatori del piano utilizzano l'elaborazione in modalità riga per impostazione predefinita. Se stai ricevendo un piano parallelo per impostazione predefinita, ad esempio, quando incapsula la soluzione in un iTVF e utilizzi un intervallo ampio, per ora forza un piano seriale con un suggerimento MAXDOP 1.
Osserva come la decompressione dei CTE ha prodotto 32 istanze dell'operatore Constant Scan, ciascuna delle quali rappresenta una tabella con due righe.
Ho ottenuto le seguenti statistiche sulle prestazioni per questa esecuzione:
CPU time = 30188 ms, elapsed time = 32844 ms.
Usa il codice seguente per testare la soluzione con una cardinalità CTE di base di 4, che secondo la nostra formula richiede quattro livelli di CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ho ottenuto il piano mostrato nella Figura 2 per questa esecuzione.
 Figura 2:piano per cardinalità CTE di base di 4
Figura 2:piano per cardinalità CTE di base di 4
Il disimballaggio dei CTE ha portato a 16 operatori di Constant Scan, ciascuno dei quali rappresenta una tabella di 4 righe.
Ho ottenuto le seguenti statistiche sulle prestazioni per questa esecuzione:
CPU time = 23781 ms, elapsed time = 25435 ms.
Si tratta di un discreto miglioramento del 22,5% rispetto alla soluzione precedente.
Esaminando le statistiche di attesa riportate per la query, il tipo di attesa dominante è SOS_SCHEDULER_YIELD. In effetti, il conteggio delle attese è curiosamente diminuito del 22,8 percento rispetto alla prima soluzione (conteggio delle attese 15.280 contro 19.800).
Utilizza il codice seguente per testare la soluzione con una cardinalità CTE di base di 16, che secondo la nostra formula richiede tre livelli di CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ho ottenuto il piano mostrato nella Figura 3 per questa esecuzione.
 Figura 3:piano per cardinalità CTE di base di 16
Figura 3:piano per cardinalità CTE di base di 16
Questa volta il disimballaggio dei CTE ha portato a 8 operatori Constant Scan, ciascuno dei quali rappresenta una tabella con 16 righe.
Ho ottenuto le seguenti statistiche sulle prestazioni per questa esecuzione:
CPU time = 22968 ms, elapsed time = 24409 ms.
Questa soluzione riduce ulteriormente il tempo trascorso, seppur di pochi punti percentuali in più, pari a una riduzione del 25,7 per cento rispetto alla prima soluzione. Anche in questo caso, il conteggio delle attese del tipo di attesa SOS_SCHEDULER_YIELD continua a diminuire (12.938).
Avanzando nella nostra scala logaritmica, il test successivo prevede una cardinalità CTE di base di 256. È lungo e brutto, ma provalo:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ho ottenuto il piano mostrato nella Figura 4 per questa esecuzione.
 Figura 4:piano per cardinalità CTE di base di 256
Figura 4:piano per cardinalità CTE di base di 256
Questa volta il disimballaggio dei CTE ha comportato solo quattro operatori Constant Scan, ciascuno con 256 righe.
Ho ottenuto i seguenti numeri di prestazioni per questa esecuzione:
CPU time = 23516 ms, elapsed time = 25529 ms.
Questa volta sembra che le prestazioni siano leggermente peggiorate rispetto alla soluzione precedente con una cardinalità CTE di base di 16. In effetti, il conteggio delle attese del tipo di attesa SOS_SCHEDULER_YIELD è leggermente aumentato a 13.176. Quindi, sembrerebbe che abbiamo trovato il nostro numero d'oro:16!
Piani paralleli e seriali
Ho provato a forzare un piano parallelo usando il suggerimento ENABLE_PARALLEL_PLAN_PREFERENCE, ma ha finito per danneggiare le prestazioni. In effetti, quando ho implementato la soluzione come iTVF, ho ricevuto un piano parallelo sulla mia macchina per impostazione predefinita per ampi intervalli e ho dovuto forzare un piano seriale con un suggerimento MAXDOP 1 per ottenere prestazioni ottimali.
Elaborazione in batch
La risorsa principale utilizzata nei piani per le mie soluzioni è la CPU. Dato che l'elaborazione batch riguarda il miglioramento dell'efficienza della CPU, specialmente quando si tratta di un numero elevato di righe, vale la pena provare questa opzione. L'attività principale qui che può trarre vantaggio dall'elaborazione batch è il calcolo del numero di riga. Ho testato le mie soluzioni in SQL Server 2019 Enterprise Edition. Per impostazione predefinita, SQL Server ha scelto l'elaborazione in modalità riga per tutte le soluzioni mostrate in precedenza. Apparentemente, questa soluzione non ha superato l'euristica richiesta per abilitare la modalità batch su rowstore. Ci sono un paio di modi per far sì che SQL Server utilizzi l'elaborazione batch qui.
L'opzione 1 consiste nel coinvolgere una tabella con un indice columnstore nella soluzione. Puoi ottenere ciò creando una tabella fittizia con un indice columnstore e introducendo un join sinistro fittizio nella query più esterna tra il nostro Nums CTE e quella tabella. Ecco la definizione della tabella fittizia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Quindi rivedere la query esterna rispetto a Nums per utilizzare FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Ecco un esempio con una cardinalità CTE di base di 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ho ottenuto il piano mostrato nella Figura 5 per questa esecuzione.
 Figura 5:piano con elaborazione batch
Figura 5:piano con elaborazione batch
Osservare l'uso dell'operatore Window Aggregate in modalità batch per calcolare i numeri di riga. Osserva inoltre che il piano non coinvolge il tavolo fittizio. L'ottimizzatore l'ha ottimizzato.
Il vantaggio dell'opzione 1 è che funziona in tutte le edizioni di SQL Server ed è rilevante in SQL Server 2016 o versioni successive, poiché l'operatore Window Aggregate in modalità batch è stato introdotto in SQL Server 2016. Lo svantaggio è la necessità di creare la tabella fittizia e includere nella soluzione.
L'opzione 2 per ottenere l'elaborazione batch per la nostra soluzione, a condizione che tu stia utilizzando SQL Server 2019 Enterprise Edition, consiste nell'usare il suggerimento autoesplicativo non documentato OVERRIDE_BATCH_MODE_HEURISTICS (dettagli nell'articolo di Dmitry Pilugin), in questo modo:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Il vantaggio dell'opzione 2 è che non è necessario creare una tabella fittizia e coinvolgerla nella soluzione. Gli svantaggi sono che è necessario utilizzare l'edizione Enterprise, utilizzare almeno SQL Server 2019 in cui è stata introdotta la modalità batch su rowstore e la soluzione prevede l'utilizzo di un suggerimento non documentato. Per questi motivi, preferisco l'opzione 1.
Ecco i numeri delle prestazioni che ho ottenuto per le varie cardinalità CTE di base:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
La figura 6 mostra un confronto delle prestazioni tra le diverse soluzioni:
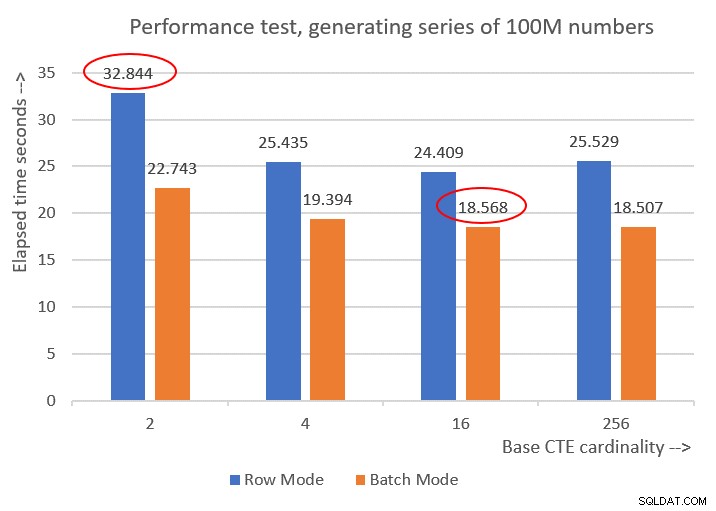 Figura 6:confronto delle prestazioni
Figura 6:confronto delle prestazioni
Puoi osservare un discreto miglioramento delle prestazioni del 20-30 percento rispetto alle controparti in modalità riga.
Curiosamente, con l'elaborazione in modalità batch, la soluzione con cardinalità CTE di base di 256 ha funzionato meglio. Tuttavia, è solo un po' più veloce della soluzione con cardinalità CTE di base di 16. La differenza è così minima e quest'ultima ha un chiaro vantaggio in termini di brevità del codice, che mi atterrei a 16.
Quindi, i miei sforzi di ottimizzazione hanno portato a un miglioramento del 43,5 percento rispetto alla soluzione originale con la cardinalità di base di 2 utilizzando l'elaborazione in modalità riga.
La sfida è iniziata!
Presento due soluzioni come contributo della mia comunità a questa sfida. Se stai utilizzando SQL Server 2016 o versioni successive e sei in grado di creare una tabella nel database utente, crea la seguente tabella fittizia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
E usa la seguente definizione iTVF:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Usa il codice seguente per testarlo (assicurati di aver selezionato Elimina risultati dopo l'esecuzione):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Questo codice termina in 18 secondi sulla mia macchina.
Se per qualsiasi motivo non riesci a soddisfare i requisiti della soluzione di elaborazione batch, invio la seguente definizione di funzione come seconda soluzione:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Usa il codice seguente per testarlo:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Questo codice termina in 24 secondi sulla mia macchina.
Il tuo turno!