In un mondo perfetto, non importa quale particolare sintassi T-SQL abbiamo scelto per esprimere una query. Qualsiasi costruzione semanticamente identica porterebbe esattamente allo stesso piano di esecuzione fisico, con esattamente le stesse caratteristiche prestazionali.
Per ottenere ciò, Query Optimizer di SQL Server dovrebbe conoscere ogni possibile equivalenza logica (supponendo che potremmo mai conoscerle tutte) e avere il tempo e le risorse per esplorare tutte le opzioni. Dato l'enorme numero di modi possibili in cui possiamo esprimere lo stesso requisito in T-SQL e l'enorme numero di possibili trasformazioni, le combinazioni diventano rapidamente ingestibili per tutti i casi tranne che per i più semplici.
Un "mondo perfetto" con una completa indipendenza dalla sintassi potrebbe non sembrare così perfetto per gli utenti che devono aspettare giorni, settimane o addirittura anni per la compilazione di una query di modesta complessità. Quindi Query Optimizer compromette:esplora alcune equivalenze comuni e si sforza di evitare di dedicare più tempo alla compilazione e all'ottimizzazione di quanto non risparmi in tempo di esecuzione. Il suo obiettivo può essere riassunto come cercare di trovare un piano di esecuzione ragionevole in un tempo ragionevole, consumando risorse ragionevoli.
Un risultato di tutto ciò è che i piani di esecuzione sono spesso sensibili alla forma scritta della query. L'ottimizzatore ha una logica per trasformare rapidamente alcune costruzioni equivalenti ampiamente utilizzate in una forma comune, ma queste capacità non sono né ben documentate né (per nulla vicino) complete.
Possiamo certamente massimizzare le nostre possibilità di ottenere un buon piano di esecuzione scrivendo query più semplici, fornendo utili indici, mantenendo buone statistiche e limitandoci a concetti più relazionali (ad esempio evitando cursori, loop espliciti e funzioni non inline), ma questo è non una soluzione completa. Né è possibile dire che una costruzione T-SQL sarà sempre produrre un piano di esecuzione migliore che un'alternativa semanticamente identica.
Il mio solito consiglio è di iniziare con il modulo di query relazionale più semplice che soddisfi le tue esigenze, utilizzando qualsiasi sintassi T-SQL tu trovi preferibile. Se la query non soddisfa i requisiti dopo l'ottimizzazione fisica (ad es. Indicizzazione), può valere la pena provare a esprimere la query in un modo leggermente diverso, pur mantenendo la semantica originale. Questa è la parte difficile. Quale parte della query dovresti provare a riscrivere? Quale riscrittura dovresti provare? Non esiste una risposta semplice e valida per tutti a queste domande. In parte dipende dall'esperienza, anche se conoscere un po' l'ottimizzazione delle query e gli interni del motore di esecuzione può essere una guida utile.
Esempio
Questo esempio usa la tabella AdventureWorks TransactionHistory. Lo script seguente crea una copia della tabella e crea un indice cluster e non cluster. Non modificheremo affatto i dati; questo passaggio serve solo a rendere chiara l'indicizzazione (e a dare alla tabella un nome più breve):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
L'attività consiste nel produrre un elenco di ID prodotto e cronologia per sei prodotti particolari. Un modo per esprimere la query è:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Questa query restituisce 764 righe utilizzando il seguente piano di esecuzione (mostrato in SentryOne Plan Explorer):

Questa semplice query si qualifica per la compilazione del piano TRIVIAL. Il piano di esecuzione prevede sei operazioni di ricerca dell'indice separate in una:
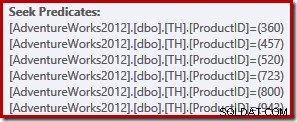
I lettori più attenti avranno notato che le sei ricerche sono elencate in crescente ordine ID prodotto, non nell'ordine (arbitrario) specificato nell'elenco IN della query originale. In effetti, se esegui tu stesso la query, è molto probabile che i risultati vengano restituiti in ordine crescente di ID prodotto. La query non è garantita per restituire i risultati in quell'ordine ovviamente, perché non abbiamo specificato una clausola ORDER BY di primo livello. Possiamo tuttavia aggiungere tale clausola ORDER BY, senza modificare il piano di esecuzione prodotto in questo caso:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Non ripeterò il grafico del piano di esecuzione, perché è esattamente lo stesso:la query si qualifica ancora per un piano banale, le operazioni di ricerca sono esattamente le stesse e i due piani hanno esattamente lo stesso costo stimato. L'aggiunta della clausola ORDER BY non ci è costata proprio nulla, ma ci ha guadagnato una garanzia di ordinazione del set di risultati.
Ora abbiamo la garanzia che i risultati verranno restituiti nell'ordine dell'ID prodotto, ma la nostra query al momento non specifica come righe con stesso l'ID prodotto verrà ordinato. Osservando i risultati, potresti notare che le righe per lo stesso ID prodotto sembrano essere ordinate per ID transazione, crescente.
Senza un ORDER BY esplicito, questa è solo un'altra osservazione (cioè non possiamo fare affidamento su questo ordinamento), ma possiamo modificare la query per garantire che le righe siano ordinate in base all'ID transazione all'interno di ciascun ID prodotto:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Anche in questo caso, il piano di esecuzione per questa query è esattamente lo stesso di prima; viene prodotto lo stesso banale progetto con lo stesso costo stimato. La differenza è che i risultati ora sono garantiti da ordinare prima per ID prodotto e poi per ID transazione.
Alcune persone potrebbero essere tentate di concludere che anche le due query precedenti restituiranno sempre righe in questo ordine, poiché i piani di esecuzione sono gli stessi. Questa non è un'implicazione sicura, perché non tutti i dettagli del motore di esecuzione sono esposti nei piani di esecuzione (anche nel formato XML). Senza una clausola order by esplicita, SQL Server è libero di restituire le righe in qualsiasi ordine, anche se il piano ci sembra lo stesso (potrebbe, ad esempio, eseguire le ricerche nell'ordine specificato nel testo della query). Il punto è che Query Optimizer conosce e può imporre determinati comportamenti all'interno del motore che non sono visibili agli utenti.
Nel caso ti stia chiedendo come il nostro indice non univoco non cluster su Product ID può restituire righe in Product e Ordine dell'ID transazione, la risposta è che la chiave dell'indice non cluster incorpora l'ID transazione (la chiave dell'indice cluster univoca). In effetti, il fisico la struttura del nostro indice non cluster è esattamente lo stesso, a tutti i livelli, come se avessimo creato l'indice con la seguente definizione:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Possiamo anche scrivere la query con un DISTINCT o GROUP BY esplicito e ottenere comunque esattamente lo stesso piano di esecuzione:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Per essere chiari, ciò non richiede in alcun modo la modifica dell'indice non cluster originale. Come ultimo esempio, tieni presente che possiamo anche richiedere i risultati in ordine decrescente:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Le proprietà del piano di esecuzione ora mostrano che l'indice viene scansionato all'indietro:

A parte questo, il piano è lo stesso:è stato prodotto nella fase di ottimizzazione del piano banale e ha ancora lo stesso costo stimato.
Riscrittura della query
Non c'è niente di sbagliato nella query o nel piano di esecuzione precedente, ma potremmo aver scelto di esprimere la query in modo diverso:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Chiaramente questo modulo specifica esattamente gli stessi risultati dell'originale, e infatti la nuova query produce lo stesso piano di esecuzione (piano banale, ricerca multipla in uno, stesso costo stimato). Il modulo OR forse rende leggermente più chiaro che il risultato è una combinazione dei risultati per i sei singoli ID prodotto, il che potrebbe portarci a provare un'altra variante che rende questa idea ancora più esplicita:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Il piano di esecuzione per la query UNION ALL è abbastanza diverso:
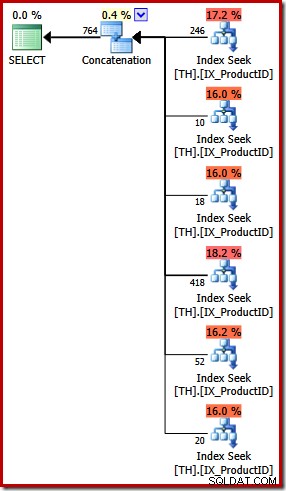
A parte le ovvie differenze visive, questo piano richiedeva un'ottimizzazione basata sui costi (COMPLETA) (non si qualificava per un piano banale) e il costo stimato è (relativamente parlando) un po' più alto, circa 0,02> unità rispetto a circa 0,005 unità prima.
Questo risale alle mie osservazioni di apertura:Query Optimizer non conosce ogni equivalenza logica e non può sempre riconoscere query alternative come specifiche per gli stessi risultati. Il punto che sto sottolineando in questa fase è che l'espressione di questa particolare query utilizzando UNION ALL anziché IN ha comportato un piano di esecuzione meno ottimale.
Secondo esempio
Questo esempio sceglie un diverso insieme di sei ID prodotto e richiede i risultati nell'ordine ID transazione:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Il nostro indice non cluster non è in grado di fornire righe nell'ordine richiesto, quindi Query Optimizer può scegliere tra la ricerca nell'indice non cluster e l'ordinamento o la scansione dell'indice cluster (che è digitato solo sull'ID transazione) e l'applicazione dei predicati dell'ID prodotto come un residuo. Gli ID prodotto elencati hanno una selettività inferiore rispetto al set precedente, quindi l'ottimizzatore sceglie una scansione dell'indice cluster in questo caso:
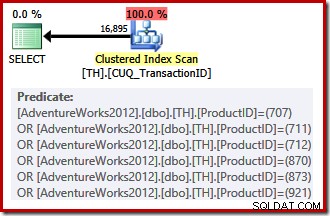
Poiché c'è una scelta basata sui costi da fare, questo piano di esecuzione non si qualificava per un piano banale. Il costo stimato del piano finale è di circa 0,714 unità. La scansione dell'indice cluster richiede 797 letture logiche al momento dell'esecuzione.
Forse essendo sorpresi dal fatto che la query non utilizzasse l'indice del prodotto, potremmo provare a forzare una ricerca dell'indice non cluster utilizzando un suggerimento sull'indice o specificando FORCESESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
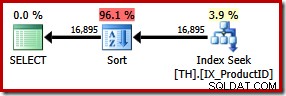
Ciò si traduce in un ordinamento esplicito per ID transazione. Si stima che il nuovo ordinamento rappresenti il 96% della 1.15 del nuovo piano costo unitario. Questo costo stimato più elevato spiega perché l'ottimizzatore ha scelto la scansione dell'indice in cluster apparentemente più economica quando è stata lasciata ai propri dispositivi. Tuttavia, il costo di I/O della nuova query è inferiore:quando viene eseguita, la ricerca dell'indice consuma solo 49 letture logiche (prima erano 797).
Potremmo anche aver scelto di esprimere questa query utilizzando (l'idea precedentemente non riuscita) UNION ALL:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Il produce il seguente piano di esecuzione (clicca sull'immagine per ingrandirla in una nuova finestra):

Questo piano può sembrare più complesso, ma ha un costo stimato di soli 0,099 unità, che è molto inferiore alla scansione dell'indice cluster (0,714 unità) o cercare più ordinamento (1,15 unità). Inoltre, il nuovo piano consuma solo 49 letture logiche al momento dell'esecuzione:le stesse del piano di ricerca + ordinamento e molto inferiori alle 797 necessarie per la scansione dell'indice cluster.
Questa volta, l'espressione della query utilizzando UNION ALL ha prodotto un piano molto migliore, sia in termini di costi stimati che di letture logiche. Il set di dati di origine è un po' troppo piccolo per fare un confronto veramente significativo tra la durata delle query o l'utilizzo della CPU, ma la scansione dell'indice cluster impiega il doppio (26 ms) delle altre due sul mio sistema.
L'ordinamento extra nel piano suggerito è probabilmente innocuo in questo semplice esempio perché è improbabile che si riversi su disco, ma molte persone preferiranno comunque il piano UNION ALL perché non è bloccante, evita una concessione di memoria e non richiede un suggerimento per la query.
Conclusione
Abbiamo visto che la sintassi delle query può influenzare il piano di esecuzione scelto dall'ottimizzatore, anche se le query specificano logicamente esattamente lo stesso set di risultati. La stessa riscrittura (ad es. UNION ALL) a volte comporterà un miglioramento e talvolta la selezione di un piano peggiore.
Riscrivere le query e provare una sintassi alternativa è una tecnica di ottimizzazione valida, ma è necessaria una certa attenzione. Un rischio è che modifiche future al prodotto possano far sì che il diverso modulo di query smetta improvvisamente di produrre il piano migliore, ma si potrebbe obiettare che è sempre un rischio e mitigato da test pre-aggiornamento o dall'uso di guide del piano.
C'è anche il rischio di lasciarsi trasportare da questa tecnica: l'utilizzo di costruzioni di query "strane" o "insolite" per ottenere un piano dalle prestazioni migliori è spesso un segno che è stata superata una linea di demarcazione. Il punto esatto in cui si trova la distinzione tra sintassi alternativa valida e "insolito/strano" è probabilmente piuttosto soggettivo; la mia guida personale è lavorare con moduli di query relazionali equivalenti e mantenere le cose il più semplici possibile.