Questo articolo è il quarto di una serie sulle soglie di ottimizzazione. La serie tratta il raggruppamento e l'aggregazione dei dati, spiegando i diversi algoritmi che SQL Server può utilizzare e il modello di determinazione dei costi che consente di scegliere tra gli algoritmi. In questo articolo mi concentro sulle considerazioni sul parallelismo. Tratto le diverse strategie di parallelismo che SQL Server può utilizzare, le soglie per la scelta tra un piano seriale e uno parallelo e la logica dei costi applicata da SQL Server utilizzando un concetto chiamato grado di parallelismo per i costi (DOP per la determinazione dei costi).
Continuerò a utilizzare la tabella dbo.Orders nel database di esempio PerformanceV3 nei miei esempi. Prima di eseguire gli esempi in questo articolo, esegui il codice seguente per eliminare un paio di indici non necessari:
DROP INDEX IF EXISTS idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX IF EXISTS idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Gli unici due indici che dovrebbero essere lasciati in questa tabella sono idx_cl_od (raggruppato con orderdate come chiave) e PK_Orders (non raggruppato con orderid come chiave).
Strategie di parallelismo
Oltre a dover scegliere tra varie strategie di raggruppamento e aggregazione (Stream Aggregate, Sort + Stream Aggregate, Hash Aggregate preordinati), SQL Server deve anche scegliere se utilizzare un piano seriale o parallelo. Infatti, può scegliere tra più strategie di parallelismo differenti. SQL Server utilizza una logica di determinazione dei costi che determina soglie di ottimizzazione che in condizioni diverse rendono una strategia preferita alle altre. Abbiamo già discusso in modo approfondito la logica dei costi utilizzata da SQL Server nei piani seriali nelle parti precedenti della serie. In questa sezione introdurrò una serie di strategie di parallelismo che SQL Server può utilizzare per gestire il raggruppamento e l'aggregazione. Inizialmente, non entrerò nei dettagli della logica dei costi, ma descriverò semplicemente le opzioni disponibili. Più avanti nell'articolo spiegherò come funzionano le formule di determinazione dei costi e un fattore importante in quelle formule chiamate DOP per la determinazione dei costi.
Come imparerai in seguito, SQL Server tiene conto del numero di CPU logiche nella macchina nelle sue formule di costo per piani paralleli. Nei miei esempi, a meno che non dica diversamente, presumo che il sistema di destinazione abbia 8 CPU logiche. Se vuoi provare gli esempi che fornirò, per ottenere gli stessi piani e valori di costo come me, devi eseguire il codice anche su una macchina con 8 CPU logiche. Se la tua macchina ha un numero diverso di CPU, puoi emulare una macchina con 8 CPU, a fini di costo, in questo modo:
DBCC OPTIMIZER_WHATIF(CPUs, 8);
Anche se questo strumento non è ufficialmente documentato e supportato, è abbastanza conveniente per scopi di ricerca e apprendimento.
La tabella Ordini nel nostro database di esempio ha 1.000.000 di righe con ID ordine nell'intervallo da 1 a 1.000.000. Per dimostrare tre diverse strategie di parallelismo per il raggruppamento e l'aggregazione, filtrerò gli ordini in cui l'ID ordine è maggiore o uguale a 300001 (700.000 corrispondenze) e raggrupperò i dati in tre modi diversi (per custid [20.000 gruppi prima del filtraggio], per empid [500 gruppi] e per shipperid [5 gruppi]) e calcola il conteggio degli ordini per gruppo.
Utilizza il codice seguente per creare indici per supportare le query raggruppate:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid); CREATE INDEX idx_oid_i_sid ON dbo.Orders(orderid) INCLUDE(shipperid); CREATE INDEX idx_oid_i_cid ON dbo.Orders(orderid) INCLUDE(custid);
Le seguenti query implementano i suddetti filtri e raggruppamenti:
-- Query 1: Serial SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid OPTION(MAXDOP 1); -- Query 2: Parallel, not local/global SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid; -- Query 3: Local parallel global parallel SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; -- Query 4: Local parallel global serial SELECT shipperid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY shipperid;
Si noti che Query 1 e Query 2 sono le stesse (entrambe raggruppate per custid), solo la prima forza un piano seriale e la seconda ottiene un piano parallelo su una macchina con 8 CPU. Uso questi due esempi per confrontare le strategie seriali e parallele per la stessa query.
La figura 1 mostra i piani stimati per tutte e quattro le query:
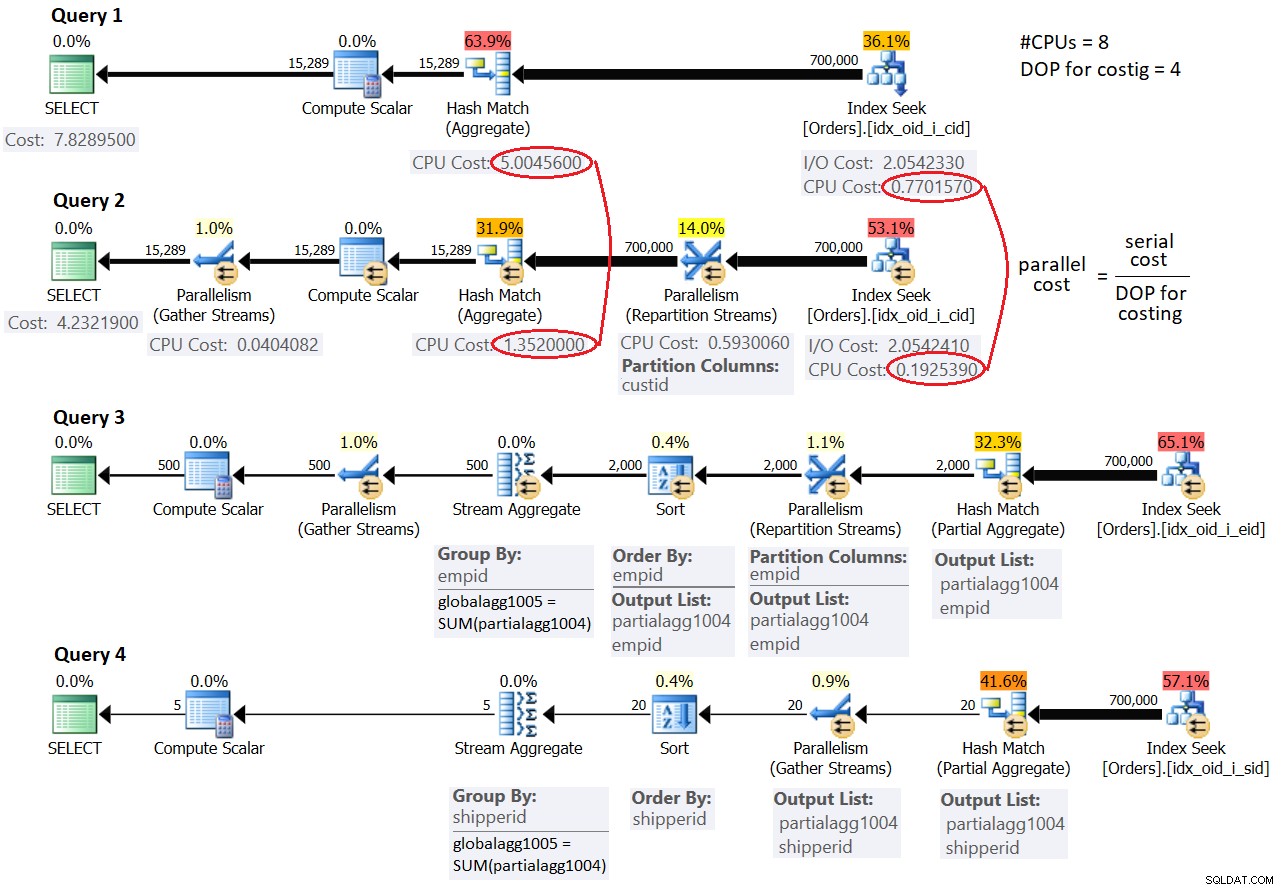 Figura 1:strategie di parallelismo
Figura 1:strategie di parallelismo
Per ora, non preoccuparti dei valori di costo mostrati in figura e della menzione del termine DOP per i costi. Parlerò di quelli più tardi. In primo luogo, concentrati sulla comprensione delle strategie e delle differenze tra di esse.
La strategia utilizzata nel piano seriale per la query 1 dovrebbe esserti familiare dalle parti precedenti della serie. Il piano filtra gli ordini pertinenti utilizzando una ricerca nell'indice di copertura creato in precedenza. Quindi, con il numero stimato di righe da raggruppare e aggregare, l'ottimizzatore preferisce la strategia Hash Aggregate alla strategia Sort + Stream Aggregate.
Il piano per Query 2 utilizza una semplice strategia di parallelismo che impiega un solo operatore aggregato. Un operatore Index Seek parallelo distribuisce pacchetti di righe ai diversi thread in modo round-robin. Ogni pacchetto di righe può contenere più ID cliente distinti. Affinché un singolo operatore di aggregazione possa calcolare i conteggi finali corretti dei gruppi, tutte le righe che appartengono allo stesso gruppo devono essere gestite dallo stesso thread. Per questo motivo, viene utilizzato un operatore di scambio Parallelism (Repartition Streams) per ripartizionare i flussi in base al gruppo di raggruppamento (custid). Infine, viene utilizzato un operatore di scambio Parallelism (Gather Streams) per raccogliere i flussi da più thread in un unico flusso di righe di risultati.
I piani per Query 3 e Query 4 utilizzano una strategia di parallelismo più complessa. I piani iniziano in modo simile al piano per la query 2 in cui un operatore Index Seek parallelo distribuisce pacchetti di righe a thread diversi. Quindi il lavoro di aggregazione viene eseguito in due passaggi:un operatore di aggregazione raggruppa e aggrega localmente le righe del thread corrente (notare il membro risultato partialagg1004) e un secondo operatore di aggregazione raggruppa e aggrega globalmente i risultati degli aggregati locali (notare il globalagg1005 membro del risultato). Ciascuno dei due passaggi aggregati, locale e globale, può utilizzare uno qualsiasi degli algoritmi aggregati descritti in precedenza nella serie. Entrambi i piani per Query 3 e Query 4 iniziano con un aggregato hash locale e procedono con un aggregato di ordinamento + flusso globale. La differenza tra i due è che il primo utilizza il parallelismo in entrambi i passaggi (quindi viene utilizzato uno scambio di Repartition Streams tra i due e uno scambio di Gather Streams dopo l'aggregato globale), e il secondo gestisce l'aggregato locale in una zona parallela e il globale aggregare in una zona seriale (quindi viene utilizzato uno scambio Gather Streams tra i due).
Quando si effettuano ricerche sull'ottimizzazione delle query in generale e sul parallelismo in particolare, è bene avere familiarità con gli strumenti che consentono di controllare vari aspetti dell'ottimizzazione per vederne gli effetti. Sai già come forzare un piano seriale (con un suggerimento MAXDOP 1) e come emulare un ambiente che, ai fini dei costi, ha un certo numero di CPU logiche (DBCC OPTIMIZER_WHATIF, con l'opzione CPU). Un altro strumento utile è l'hint di query ENABLE_PARALLEL_PLAN_PREFERENCE (introdotto in SQL Server 2016 SP1 CU2), che massimizza il parallelismo. Ciò che intendo dire con questo è che se un piano parallelo è supportato per la query, il parallelismo sarà preferito in tutte le parti del piano che possono essere gestite in parallelo, come se fosse gratuito. Ad esempio, osserva nella Figura 1 che per impostazione predefinita il piano per la query 4 gestisce l'aggregato locale in una zona seriale e l'aggregato globale in una zona parallela. Ecco la stessa query, solo che questa volta con l'hint per la query ENABLE_PARALLEL_PLAN_PREFERENCE applicato (lo chiameremo Query 5):
SELECT shipperid, COUNT(*) AS numorders
FROM dbo.Orders
WHERE orderid >= 300001
GROUP BY shipperid
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); Il piano per la query 5 è mostrato nella Figura 2:
 Figura 2:massimizzazione del parallelismo
Figura 2:massimizzazione del parallelismo
Osserva che questa volta sia gli aggregati locali che globali vengono gestiti in zone parallele.
Scelta del piano seriale/parallelo
Ricordiamo che durante l'ottimizzazione delle query, SQL Server crea più piani candidati e seleziona quello con il costo più basso tra quelli prodotti. Il termine costo è un termine improprio poiché il piano candidato con il costo più basso dovrebbe essere, secondo le stime, quello con il minor tempo di esecuzione, non quello con la minor quantità di risorse utilizzate complessivamente. Ad esempio, tra un piano candidato seriale e uno parallelo prodotto per la stessa query, il piano parallelo utilizzerà probabilmente più risorse, poiché deve utilizzare operatori di scambio che sincronizzano i thread (distribuire, ripartizionare e raccogliere flussi). Tuttavia, affinché il piano parallelo richieda meno tempo per completare l'esecuzione rispetto al piano seriale, i risparmi ottenuti eseguendo il lavoro con più thread devono superare il lavoro aggiuntivo svolto dagli operatori di scambio. E questo deve riflettersi nelle formule di costo utilizzate da SQL Server quando è coinvolto il parallelismo. Non è un compito semplice da svolgere con precisione!
Oltre al costo del piano parallelo che deve essere inferiore al costo del piano seriale per essere preferito, il costo dell'alternativa del piano seriale deve essere maggiore o uguale alla soglia di costo per il parallelismo . Questa è un'opzione di configurazione del server impostata su 5 per impostazione predefinita che impedisce che le query con un costo piuttosto basso vengano gestite con parallelismo. L'idea qui è che un sistema con un gran numero di piccole query trarrebbe nel complesso maggiori benefici dall'utilizzo di piani seriali, invece di sprecare molte risorse per sincronizzare i thread. Puoi comunque avere più query con piani seriali in esecuzione contemporaneamente, utilizzando in modo efficiente le risorse multi-CPU della macchina. In effetti, a molti professionisti di SQL Server piace aumentare la soglia di costo per il parallelismo dal valore predefinito di 5 a un valore superiore. Un sistema che esegue un numero abbastanza ridotto di query di grandi dimensioni contemporaneamente trarrebbe molto vantaggio dall'utilizzo di piani paralleli.
Per ricapitolare, affinché SQL Server preferisca un piano parallelo all'alternativa seriale, il costo del piano seriale deve essere almeno la soglia di costo per il parallelismo e il costo del piano parallelo deve essere inferiore al costo del piano seriale (implicando potenzialmente minor tempo di esecuzione).
Prima di arrivare ai dettagli delle formule di costo effettive, illustrerò con esempi diversi scenari in cui viene effettuata una scelta tra piani seriali e paralleli. Assicurati che il tuo sistema presuppone 8 CPU logiche per ottenere costi di query simili ai miei se vuoi provare gli esempi.
Considera le seguenti query (le chiameremo Query 6 e Query 7):
-- Query 6: Serial
SELECT empid, COUNT(*) AS numorders
FROM dbo.Orders
WHERE orderid >= 400001
GROUP BY empid;
-- Query 7: Forced parallel
SELECT empid, COUNT(*) AS numorders
FROM dbo.Orders
WHERE orderid >= 400001
GROUP BY empid
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); I piani per queste query sono mostrati nella Figura 3.
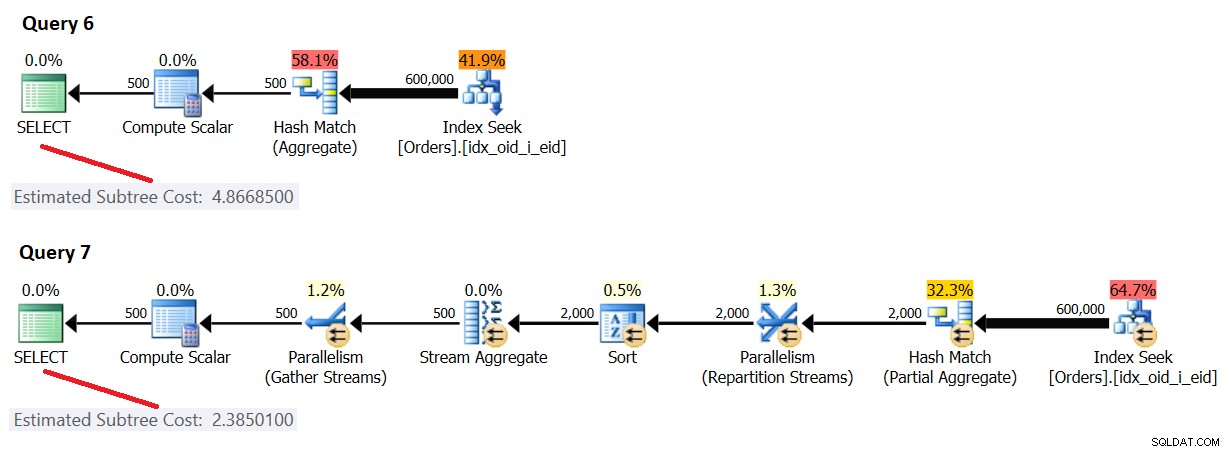 Figura 3:costo seriale
Figura 3:costo seriale
Qui, il costo del piano parallelo [forzato] è inferiore al costo del piano seriale; tuttavia, il costo del piano seriale è inferiore alla soglia di costo predefinita per il parallelismo di 5, quindi SQL Server ha scelto il piano seriale per impostazione predefinita.
Considera le seguenti query (le chiameremo Query 8 e Query 9):
-- Query 8: Parallel SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; -- Query 9: Forced serial SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid OPTION(MAXDOP 1);
I piani per queste query sono mostrati nella Figura 4.
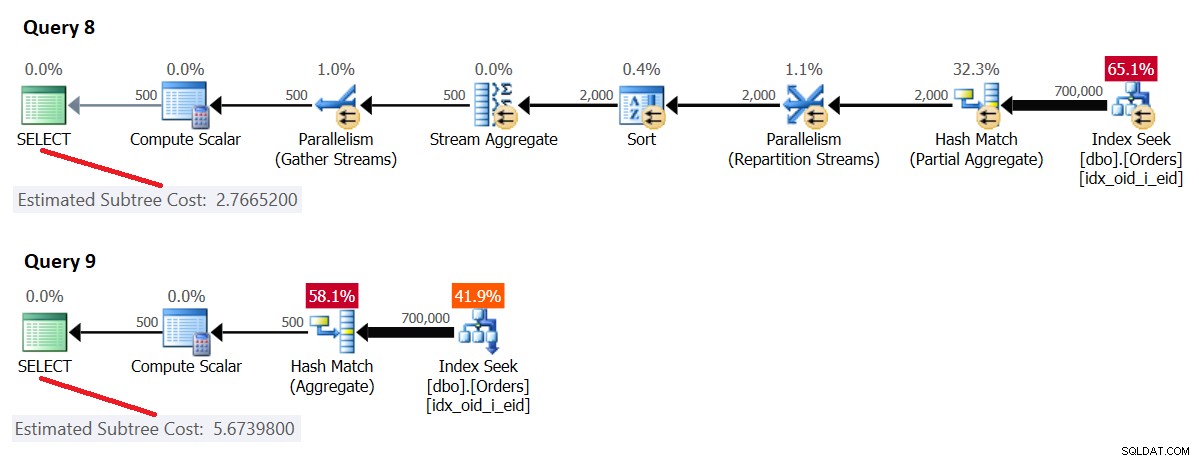 Figura 4:costo seriale>=soglia di costo per parallelismo, costo parallelo
Figura 4:costo seriale>=soglia di costo per parallelismo, costo parallelo
Qui, il costo del piano seriale [forzato] è maggiore o uguale alla soglia di costo per il parallelismo e il costo del piano parallelo è inferiore al costo del piano seriale, quindi SQL Server ha scelto il piano parallelo per impostazione predefinita.
Considera le seguenti query (le chiameremo Query 10 e Query 11):
-- Query 10: Serial
SELECT *
FROM dbo.Orders
WHERE orderid >= 100000;
-- Query 11: Forced parallel
SELECT *
FROM dbo.Orders
WHERE orderid >= 100000
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); I piani per queste query sono mostrati nella Figura 5.
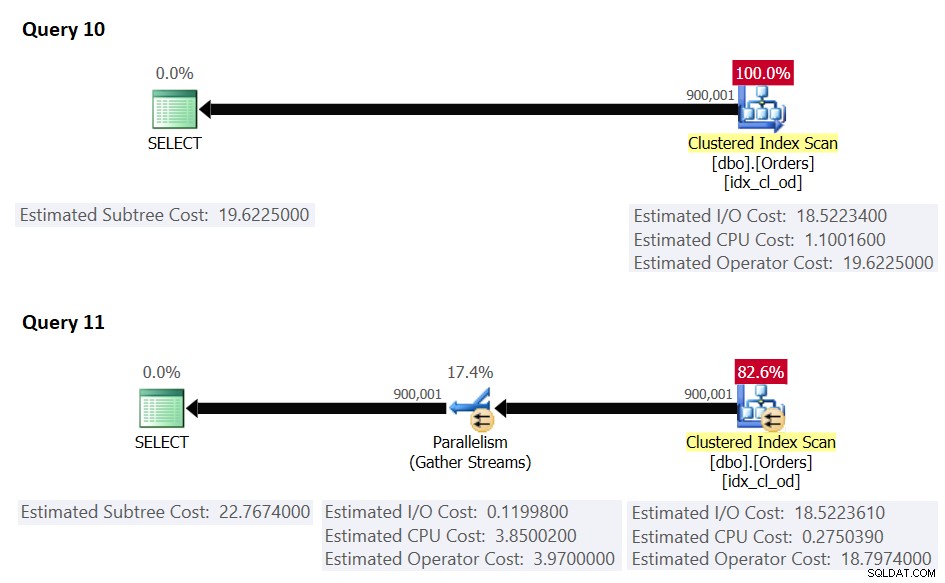 Figura 5:costo seriale>=soglia di costo per parallelismo, costo parallelo>=costo seriale
Figura 5:costo seriale>=soglia di costo per parallelismo, costo parallelo>=costo seriale
In questo caso, il costo del piano seriale è maggiore o uguale alla soglia di costo per il parallelismo; tuttavia, il costo del piano seriale è inferiore al costo del piano parallelo [forzato], quindi SQL Server ha scelto il piano seriale per impostazione predefinita.
C'è un'altra cosa che devi sapere sul tentativo di massimizzare il parallelismo con il suggerimento ENABLE_PARALLEL_PLAN_PREFERENCE. Affinché SQL Server possa persino utilizzare un piano parallelo, è necessario che sia presente un abilitatore di parallelismo come un predicato residuo, un ordinamento, un aggregato e così via. Un piano che applica solo una scansione dell'indice o una ricerca dell'indice senza un predicato residuo e senza alcun altro abilitatore di parallelismo verrà elaborato con un piano seriale. Considera le seguenti query come esempio (le chiameremo Query 12 e Query 13):
-- Query 12
SELECT *
FROM dbo.Orders
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));
-- Query 13
SELECT *
FROM dbo.Orders
WHERE orderid >= 100000
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); I piani per queste query sono mostrati nella Figura 6.
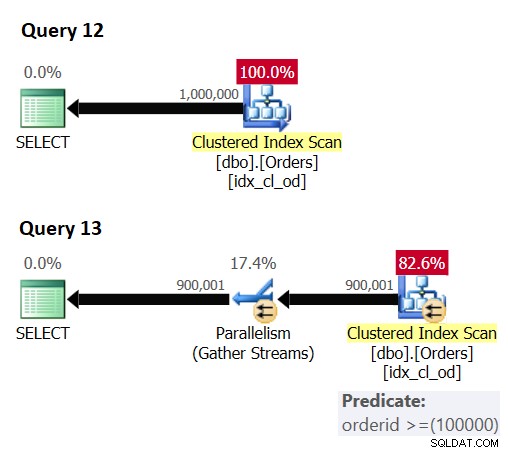 Figura 6:Parallelism enabler
Figura 6:Parallelism enabler
La query 12 ottiene un piano seriale nonostante il suggerimento poiché non esiste un abilitatore di parallelismo. La query 13 ottiene un piano parallelo poiché è coinvolto un predicato residuo.
Calcolo e test DOP per la determinazione dei costi
Microsoft ha dovuto calibrare le formule di determinazione dei costi nel tentativo di avere un costo del piano parallelo inferiore rispetto al costo del piano seriale che riflettesse un tempo di esecuzione inferiore e viceversa. Un'idea potenziale era quella di prendere il costo della CPU dell'operatore seriale e dividerlo semplicemente per il numero di CPU logiche nella macchina per produrre il costo della CPU dell'operatore parallelo. Il numero logico di CPU nella macchina è il fattore principale che determina il grado di parallelismo della query, o DOP in breve (il numero di thread che possono essere utilizzati in una zona parallela nel piano). Il pensiero semplicistico qui è che se un operatore richiede T unità di tempo per il completamento quando si utilizza un thread e il grado di parallelismo della query è D, ci vorrebbe del tempo T/D dell'operatore per il completamento quando si utilizzano D thread. In pratica, le cose non sono così semplici. Ad esempio, di solito hai più query in esecuzione contemporaneamente e non solo una, nel qual caso una singola query non otterrà tutte le risorse della CPU della macchina. Quindi, Microsoft ha avuto l'idea di un grado di parallelismo per i costi (DOP per i costi, in breve). Questa misura è in genere inferiore al numero di CPU logiche nella macchina ed è il fattore per cui viene diviso il costo della CPU dell'operatore seriale per calcolare il costo della CPU dell'operatore parallelo.
Normalmente, il DOP per la determinazione dei costi viene calcolato come il numero di CPU logiche diviso per 2, utilizzando la divisione intera. Ci sono eccezioni, però. Quando il numero di CPU è 2 o 3, DOP per la determinazione dei costi è impostato su 2. Con 4 o più CPU, DOP per la determinazione dei costi è impostato su #CPUs / 2, ancora, usando la divisione intera. Questo è fino a un certo massimo, che dipende dalla quantità di memoria disponibile per la macchina. In una macchina con un massimo di 4.096 MB di memoria il DOP massimo per la determinazione dei costi è 8; con più di 4.096 MB, il DOP massimo per i costi è 32.
Per testare questa logica, sai già come emulare un numero desiderato di CPU logiche utilizzando DBCC OPTIMIZER_WHATIF, con l'opzione CPU, in questo modo:
DBCC OPTIMIZER_WHATIF(CPUs, 8);
Utilizzando lo stesso comando con l'opzione MemoryMBs, puoi emulare la quantità di memoria desiderata in MB, in questo modo:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);
Utilizzare il codice seguente per verificare lo stato esistente delle opzioni emulate:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(Status); DBCC TRACEOFF(3604);
Utilizzare il codice seguente per reimpostare tutte le opzioni:
DBCC OPTIMIZER_WHATIF(ResetAll);
Ecco una query T-SQL che puoi utilizzare per calcolare DOP per i costi in base al numero di input di CPU logiche e alla quantità di memoria:
DECLARE @NumCPUs AS INT = 8, @MemoryMBs AS INT = 16384;
SELECT
CASE
WHEN @NumCPUs = 1 THEN 1
WHEN @NumCPUs <= 3 THEN 2
WHEN @NumCPUs >= 4 THEN
(SELECT MIN(n)
FROM ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) AS D2(n))
END AS DOP4C
FROM ( VALUES( CASE WHEN @MemoryMBs <= 4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C); Con i valori di input specificati, questa query restituisce 4.
La tabella 1 descrive in dettaglio il DOP per i costi che ottieni in base al numero logico di CPU e alla quantità di memoria nella tua macchina.
| #CPU | DOP per i costi quando MemoryMBs <=4096 | DOP per i costi quando MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tabella 1:DOP per i costi
Ad esempio, rivisitiamo Query 1 e Query 2 mostrate in precedenza:
-- Query 1: Forced serial SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid OPTION(MAXDOP 1); -- Query 2: Naturally parallel SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid;
I piani per queste query sono mostrati nella Figura 7.
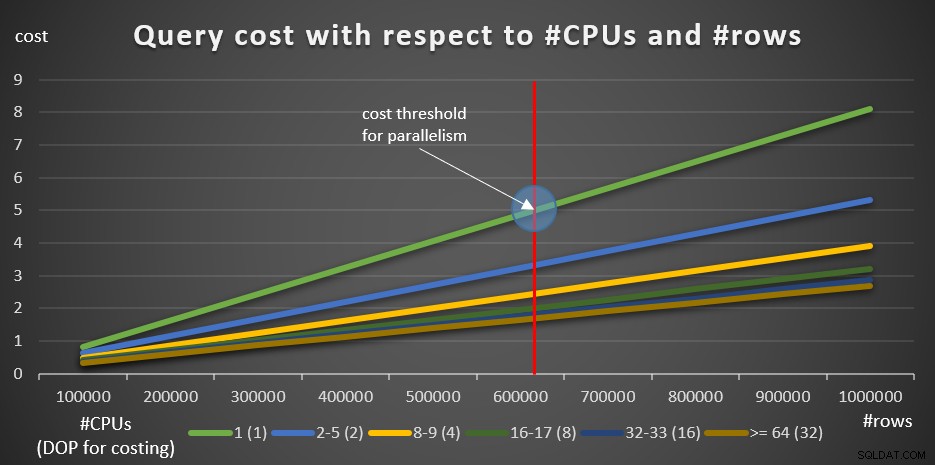 Figura 7:DOP per costare
Figura 7:DOP per costare
La query 1 forza un piano seriale, mentre la query 2 ottiene un piano parallelo nel mio ambiente (emulazione di 8 CPU logiche e 16.384 MB di memoria). Ciò significa che il DOP per la determinazione dei costi nel mio ambiente è 4. Come accennato, il costo della CPU di un operatore parallelo viene calcolato come il costo della CPU dell'operatore seriale diviso per la DOP per la determinazione dei costi. Puoi vedere che è proprio così nel nostro piano parallelo con gli operatori Index Seek e Hash Aggregate che vengono eseguiti in parallelo.
Per quanto riguarda i costi degli operatori di scambio, sono costituiti da un costo di avvio e da un costo costante per riga, che puoi facilmente decodificare.
Si noti che nella strategia di raggruppamento e aggregazione parallela semplice, che è quella utilizzata qui, le stime di cardinalità nei piani seriali e paralleli sono le stesse. Questo perché viene impiegato un solo operatore aggregato. In seguito vedrai che le cose sono diverse quando usi la strategia locale/globale.
Le seguenti query aiutano a illustrare l'effetto del numero di CPU logiche e del numero di righe coinvolte sul costo della query (10 query, con incrementi di 100.000 righe):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 900001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 800001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 700001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 600001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 500001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 400001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 200001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 100001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 000001 GROUP BY empid;
La figura 8 mostra i risultati.
Figura 8:costo della query rispetto a #CPU e #righe
La linea verde rappresenta i costi delle diverse query (con il diverso numero di righe) utilizzando un piano seriale. Le altre righe rappresentano i costi dei piani paralleli con diversi numeri di CPU logiche e i rispettivi DOP per la determinazione dei costi. La linea rossa rappresenta il punto in cui il costo della query seriale è 5, ovvero la soglia di costo predefinita per l'impostazione del parallelismo. A sinistra di questo punto (meno righe da raggruppare e aggregare), normalmente l'ottimizzatore non considererà un piano parallelo. Per poter ricercare i costi dei piani paralleli al di sotto della soglia dei costi per il parallelismo, puoi fare una delle due cose. Un'opzione consiste nell'usare l'hint per la query ENABLE_PARALLEL_PLAN_PREFERENCE, ma come promemoria, questa opzione massimizza il parallelismo invece di forzarlo semplicemente. Se questo non è l'effetto desiderato, puoi semplicemente disabilitare la soglia di costo per il parallelismo, in questo modo:
EXEC sp_configure 'show advanced options', 1; RECONFIGURE; EXEC sp_configure 'cost threshold for parallelism', 0; EXEC sp_configure 'show advanced options', 0; RECONFIGURE;
Ovviamente, non è una mossa intelligente in un sistema produttivo, ma perfettamente utile per scopi di ricerca. Questo è ciò che ho fatto per produrre le informazioni per il grafico nella Figura 8.
A partire da 100.000 righe e aggiungendo 100.000 incrementi, tutti i grafici sembrano implicare che se la soglia di costo per il parallelismo non fosse un fattore, un piano parallelo sarebbe sempre stato preferito. Questo è effettivamente il caso delle nostre query e del numero di righe coinvolte. Tuttavia, prova un numero inferiore di righe, iniziando con 10.000 e aumentando di 10.000 incrementi utilizzando le cinque query seguenti (ancora una volta, mantieni la soglia di costo per il parallelismo disabilitata per ora):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 990001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 980001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 970001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 960001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 950001 GROUP BY empid;
La Figura 9 mostra i costi delle query con piani sia seriali che paralleli (emulazione di 4 CPU, DOP per il costo di 2).
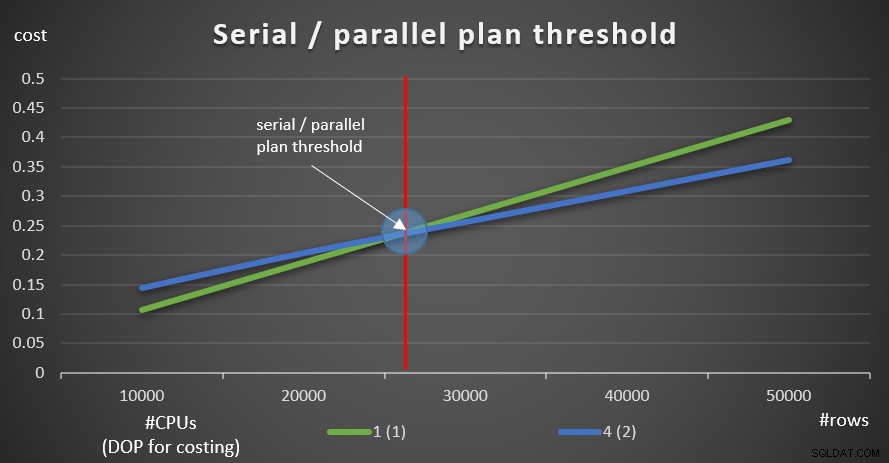 Figura 9:Seriale / soglia del piano parallelo
Figura 9:Seriale / soglia del piano parallelo
Come puoi vedere, esiste una soglia di ottimizzazione fino alla quale si preferisce il piano seriale e al di sopra della quale si preferisce il piano parallelo. Come accennato, in un sistema normale in cui o si mantiene la soglia di costo per il parallelismo impostando il valore predefinito di 5, o superiore, la soglia effettiva è comunque superiore a quella di questo grafico.
In precedenza ho menzionato che quando SQL Server sceglie la strategia di parallelismo di raggruppamento e aggregazione semplice, le stime di cardinalità dei piani seriali e paralleli sono le stesse. La domanda è:in che modo SQL Server gestisce le stime di cardinalità per la strategia di parallelismo locale/globale.
Per capirlo, userò Query 3 e Query 4 dai nostri esempi precedenti:
-- Query 3: Local parallel global parallel SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; -- Query 4: Local parallel global serial SELECT shipperid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY shipperid;
In un sistema con 8 CPU logiche e un DOP effettivo per un valore di costo di 4, ho ottenuto i piani mostrati nella Figura 10.
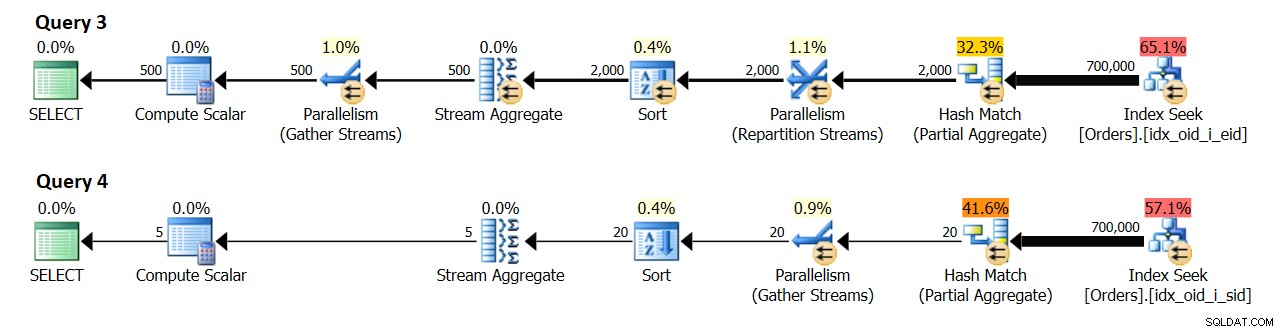 Figura 10:stima della cardinalità
Figura 10:stima della cardinalità
La query 3 raggruppa gli ordini per empid. Alla fine sono previsti 500 gruppi di dipendenti distinti.
La query 4 raggruppa gli ordini per shipperid. Alla fine sono previsti 5 distinti gruppi di spedizionieri.
Curiosamente, sembra che la stima della cardinalità per il numero di gruppi prodotti dall'aggregato locale sia {numero di gruppi distinti attesi da ciascun thread} * {DOP for costing}. In pratica, ti rendi conto che il numero di solito sarà il doppio poiché ciò che conta è il DOP per l'esecuzione (ovvero, solo DOP), che si basa principalmente sul numero di CPU logiche. Questa parte è un po' complicata da emulare per scopi di ricerca poiché il comando DBCC OPTIMIZER_WHATIF con l'opzione CPU influisce sul calcolo del DOP per i costi, ma il DOP per l'esecuzione non sarà maggiore del numero effettivo di CPU logiche visualizzate dall'istanza di SQL Server. Questo numero si basa essenzialmente sul numero di utilità di pianificazione con cui SQL Server inizia. puoi controllare il numero di pianificatori SQL Server inizia con l'utilizzo del parametro di avvio -P{ #schedulers }, ma è uno strumento di ricerca un po' più aggressivo rispetto a un'opzione di sessione.
In ogni caso, senza emulare alcuna risorsa, la mia macchina di test ha 4 CPU logiche, risultando in DOP per il costo 2 e DOP per l'esecuzione 4. Nel mio ambiente, l'aggregato locale nel piano per Query 3 mostra una stima di 1.000 gruppi di risultati (500 x 2) e un effettivo di 2.000 (500 x 4). Allo stesso modo, l'aggregato locale nel piano per la query 4 mostra una stima di 10 gruppi di risultati (5 x 2) e un effettivo di 20 (5 x 4).
Al termine della sperimentazione, esegui il codice seguente per la pulizia:
-- Set cost threshold for parallelism to default EXEC sp_configure 'show advanced options', 1; RECONFIGURE; EXEC sp_configure 'cost threshold for parallelism', 5; EXEC sp_configure 'show advanced options', 0; RECONFIGURE; GO -- Reset OPTIMIZER_WHATIF options DBCC OPTIMIZER_WHATIF(ResetAll); -- Drop indexes DROP INDEX idx_oid_i_sid ON dbo.Orders; DROP INDEX idx_oid_i_eid ON dbo.Orders; DROP INDEX idx_oid_i_cid ON dbo.Orders;
Conclusione
In questo articolo ho descritto una serie di strategie di parallelismo utilizzate da SQL Server per gestire il raggruppamento e l'aggregazione. Un concetto importante da comprendere nell'ottimizzazione delle query con piani paralleli è il grado di parallelismo (DOP) per la determinazione dei costi. Ho mostrato una serie di soglie di ottimizzazione, inclusa una soglia tra piani seriali e paralleli e l'impostazione della soglia di costo per il parallelismo. La maggior parte dei concetti che ho descritto qui non sono univoci per il raggruppamento e l'aggregazione, ma sono altrettanto applicabili per le considerazioni sul piano parallelo in SQL Server in generale. Il mese prossimo continuerò la serie discutendo dell'ottimizzazione con la riscrittura delle query.