Questa è la parte finale di una serie in cinque parti che approfondisce il modo in cui inizia l'esecuzione dei piani paralleli in modalità riga di SQL ServerSQL Server. La parte 1 ha inizializzato il contesto di esecuzione zero per l'attività padre e la parte 2 ha creato l'albero di scansione della query. La parte 3 ha avviato la scansione delle query, eseguito alcune fase iniziali elaborazione e ha avviato le prime attività parallele aggiuntive nella filiale C. La parte 4 ha descritto la sincronizzazione degli scambi e l'avvio delle filiali C e D del piano parallelo.
Inizio attività parallele ramo B
Un promemoria delle filiali in questo piano parallelo (clicca per ingrandire):
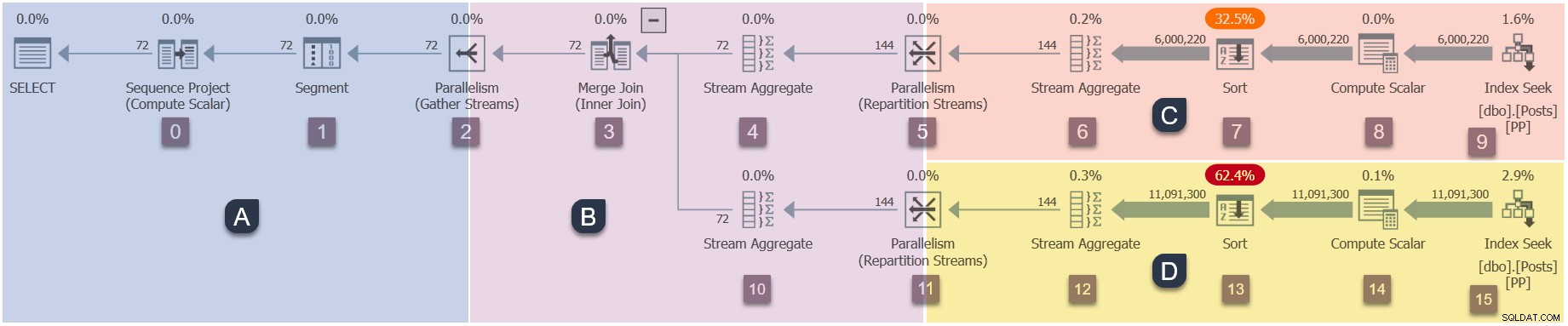
Questa è la quarta fase della sequenza di esecuzione:
- Ramo A (attività principale).
- Ramo C (attività parallele aggiuntive).
- Ramo D (attività parallele aggiuntive).
- Ramo B (attività parallele aggiuntive).
L'unico thread attivo in questo momento (non sospeso su CXPACKET ) è l'attività principale , che si trova sul lato consumer dello scambio di flussi di ripartizione al nodo 11 nella filiale B:
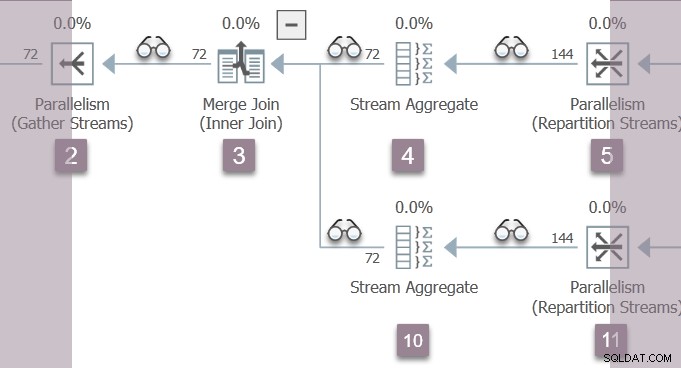
L'attività principale ora ritorna dalle fasi iniziali nidificate chiamate, impostazione dei tempi trascorsi e della CPU nei profiler man mano che procede. Il primo e l'ultimo orario attivo non aggiornato durante la prima fase di elaborazione. Ricorda che questi numeri vengono registrati rispetto al contesto di esecuzione zero:le attività parallele del ramo B non esistono ancora.
L'attività principale sale l'albero dal nodo 11, attraverso lo stream aggregate al nodo 10 e il merge join al nodo 3, torna allo scambio dei flussi di raccolta al nodo 2.
L'elaborazione della fase iniziale è ora completa .
Con l'originale EarlyPhases chiamata al nodo 2 raccogliere flussi scambia finalmente completato, l'attività padre torna ad aprire quello scambio (potresti quasi ricordare quella chiamata dall'inizio di questa serie). Il metodo aperto al nodo 2 ora chiama CQScanExchangeNew::StartAllProducers per creare le attività parallele per la filiale B.
L'attività principale ora attende su CXPACKET presso il consumatore lato del nodo 2 raccogliere flussi scambio. Questa attesa continuerà fino a quando le attività del ramo B appena create non avranno completato il loro Open nidificato chiamate e restituito per completare l'apertura del lato produttore dello scambio di flussi di raccolta.
Attività parallele del ramo B aperte
Le due nuove attività parallele nella filiale B iniziano dal produttore lato del nodo 2 raccogliere flussi scambio. Seguendo il consueto modello di esecuzione iterativo in modalità riga, chiamano:
CQScanXProducerNew::Open(nodo 2 lato produttore aperto).CQScanProfileNew::Open(profiler per il nodo 3).CQScanMergeJoinNew::Open(unione unisci nodo 3).CQScanProfileNew::Open(profiler per il nodo 4).CQScanStreamAggregateNew::Open(aggregato flusso nodo 4).CQScanProfileNew::Open(profiler per il nodo 5).CQScanExchangeNew::Open(scambio di flussi di ripartizione).
Le attività parallele seguono entrambe l'input esterno (superiore) al join di unione, proprio come ha fatto l'elaborazione della fase iniziale.
Completamento dello scambio
Quando le attività del ramo B arrivano al consumatore lato dello scambio di flussi di ripartizione al nodo 5, ogni attività:
- Registrati con la porta di scambio (
CXPort). - Crea i tubi (
CXPipe) che collegano questa attività a una o più attività lato produttore (a seconda del tipo di scambio). Lo scambio corrente è una ripartizione dei flussi, quindi ogni attività del consumatore ha due pipe (a DOP 2). Ogni consumatore può ricevere righe da uno dei due produttori. - Aggiunge un
CXPipeMergeper unire righe da più pipe (poiché si tratta di uno scambio di conservazione degli ordini). - Crea pacchetti di righe (chiamato in modo confuso
CXPacket) utilizzato per il controllo del flusso e per tamponare le file attraverso i tubi di scambio. Questi sono allocati dalla memoria di query precedentemente concessa.
Una volta che entrambe le attività parallele lato consumatore hanno completato tale lavoro, lo scambio del nodo 5 è pronto per l'uso. I due consumer (in Branch B) ei due produttori (in Branch C) hanno tutti aperto la porta di scambio, quindi il nodo 5 CXPACKET aspetta la fine .
Punto di controllo
Allo stato attuale:
- L'attività principale nel Ramo A è in attesa su
CXPACKETsul lato consumer del nodo 2 raccogliere lo scambio di flussi. Questa attesa continuerà fino al ritorno di entrambi i produttori del nodo 2 e all'apertura dello scambio. - Le due attività parallele nel Ramo B sono eseguibili . Hanno appena aperto il lato consumer dello scambio di flussi di ripartizione al nodo 5.
- Le due attività parallele nel Ramo C sono appena stati rilasciati dal loro
CXPACKETattendi e ora sono eseguibili . I due flussi aggregati al nodo 6 (uno per attività parallela) possono iniziare ad aggregare righe dai due ordinamenti al nodo 7. Richiamare le ricerche di indice al nodo 9 chiuse qualche tempo fa, quando gli ordinamenti hanno completato la loro fase di input. - Le due attività parallele nel Ramo D sono in attesa su
CXPACKETsul lato produttore dello scambio di flussi di ripartizione al nodo 11. Stanno aspettando che il lato consumatore del nodo 11 venga aperto dalle due attività parallele nel ramo B. I cercatori di indice si sono chiusi e gli ordinamenti sono pronti per la transizione a la loro fase di uscita.
Più rami attivi
Questa è la prima volta che abbiamo più rami (B e C) attivi contemporaneamente, il che potrebbe essere difficile da discutere. Fortunatamente, la struttura della query demo è tale che gli aggregati di flusso nel ramo C producano solo poche righe. Il piccolo numero di righe di output strette si adatterà facilmente ai buffer del pacchetto di righe allo scambio dei flussi di ripartizione del nodo 5. Le attività del ramo C possono quindi continuare il loro lavoro (ed eventualmente chiudersi) senza attendere che il lato consumer dei flussi di ripartizione del nodo 5 recuperi le righe.
Convenientemente, questo significa che possiamo lasciare che le due attività parallele di Branch C vengano eseguite in background senza preoccuparcene. Dobbiamo solo preoccuparci di ciò che stanno facendo le due attività parallele del ramo B.
L'apertura del ramo B è completata
Un promemoria della filiale B:
I due lavoratori paralleli nel ramo B tornano dal loro Open chiamate allo scambio di flussi di ripartizione del nodo 5. Questo li riporta attraverso l'aggregazione del flusso al nodo 4, al join di unione al nodo 3.
Perché stiamo ascendendo l'albero in Open metodo, i profiler sopra il nodo 5 e il nodo 4 stanno registrando ultimo attivo tempo, nonché accumulare tempo trascorso e CPU (per attività). Al momento non stiamo eseguendo le prime fasi dell'attività padre, quindi i numeri registrati per il contesto di esecuzione zero non sono interessati.
Al merge join, le due attività parallele Branch B iniziano a decrescente l'input interno (inferiore), portandoli attraverso l'aggregato di flusso al nodo 10 (e un paio di profiler) al lato consumer dello scambio di flussi di ripartizione al nodo 11.
Il ramo D riprende l'esecuzione
Una ripetizione degli eventi Branch C al nodo 5 si verifica ora nei flussi di ripartizione del nodo 11. Il lato consumer dello scambio del nodo 11 viene completato e aperto. I due produttori del ramo D terminano il loro CXPACKET attende, diventando eseguibile ancora. Lasceremo che le attività del ramo D vengano eseguite in background, inserendo i loro risultati nei buffer di scambio.
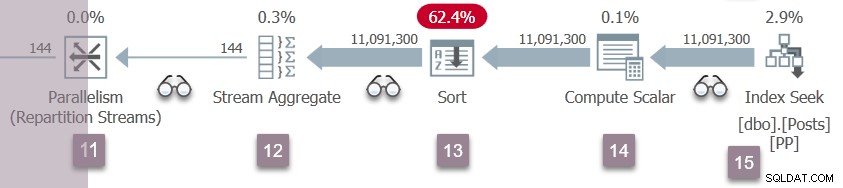
Ora ci sono sei attività parallele (due ciascuno nei rami B, C e D) condividono il tempo in modo cooperativo sui due pianificatori assegnati ad attività parallele aggiuntive in questa query.
L'apertura del ramo A è completata
Le due attività parallele nel ramo B ritornano dal loro Open chiamate allo scambio dei flussi di ripartizione del nodo 11, oltre l'aggregato del flusso del nodo 10, tramite l'unione di join al nodo 3 e di nuovo al lato produttore dei stream di raccolta al nodo 2. Profiler ultimo attivo e i tempi accumulati trascorsi e CPU vengono aggiornati mentre saliamo sull'albero in Open nidificato metodi.
Presso il produttore lato dello scambio dei flussi di raccolta, le due attività parallele del ramo B si sincronizzano aprendo la porta di scambio, quindi attendono CXPACKET per l'apertura da parte dei consumatori.
L'attività principale l'attesa sul lato consumer dei flussi di raccolta è ora rilasciata dal suo CXPACKET wait, che gli consente di completare l'apertura della porta di scambio sul lato consumatore. Questo a sua volta libera i produttori dal loro (breve) CXPACKET aspettare. I flussi di raccolta del nodo 2 sono stati ora aperti da tutti i proprietari.
Completamento della scansione della query
L'attività principale ora ascende l'albero di scansione della query dallo scambio di flussi di raccolta, tornando da Open chiamate alla centrale, segmento e progetto sequenza operatori della Filiale A.
Questo completa l'apertura l'albero di scansione della query, avviato tutto questo tempo fa dalla chiamata a CQueryScan::StartupQuery . È stata avviata l'esecuzione di tutti i rami del piano parallelo.
Righe di ritorno
Il piano di esecuzione è pronto per iniziare a restituire le righe in risposta a GetRow chiamate alla radice dell'albero di scansione della query, avviato da una chiamata a CQueryScan::GetRow . Non entrerò nei dettagli, poiché va rigorosamente oltre lo scopo di un articolo su come avviare i piani paralleli .
Tuttavia, la breve sequenza è:
- L'attività principale chiama
GetRownel progetto della sequenza, che chiamaGetRowsul segmento, che chiamaGetRowsul consumatore lato dello scambio di flussi di raccolta. - Se non ci sono ancora righe disponibili nello scambio, l'attività principale attende su
CXCONSUMER. - Nel frattempo, le attività parallele Branch B indipendenti hanno chiamato in modo ricorsivo
GetRowa partire dal produttore lato dello scambio di flussi di raccolta. - Le righe vengono fornite al ramo B dai lati consumer degli scambi di flussi di ripartizione ai nodi 5 e 12.
- I rami C e D stanno ancora elaborando le righe dai loro ordinamenti attraverso i rispettivi aggregati di flusso. Le attività del ramo B potrebbero dover attendere su
CXCONSUMERalla ripartizione, i flussi 5 e 12 diventano disponibili per un pacchetto completo di righe. - Righe che emergono dal
GetRowannidato le chiamate nella filiale B vengono assemblate in pacchetti di righe presso il produttore lato dello scambio di flussi di raccolta. - Il
CXCONSUMERdell'attività principale wait sul lato consumer dei flussi di raccolta termina quando un pacchetto diventa disponibile. - Una riga alla volta viene quindi elaborata tramite gli operatori principali nella filiale A e infine al cliente.
- Alla fine, le righe si esauriscono e un
Closenidificato la chiamata scorre lungo l'albero, attraverso gli scambi e l'esecuzione parallela giunge al termine.
Riepilogo e note finali
Innanzitutto, un riepilogo della sequenza di esecuzione di questo particolare piano di esecuzione parallela:
- L'attività principale apre il ramo A . Fase iniziale l'elaborazione inizia allo scambio dei flussi di raccolta.
- Le chiamate della fase iniziale dell'attività padre scendono dall'albero di scansione alla ricerca dell'indice al nodo 9, quindi risalgono allo scambio di ripartizionamento al nodo 5.
- L'attività principale avvia attività parallele per Ramo C , quindi attende mentre leggono tutte le righe disponibili negli operatori di ordinamento di blocco al nodo 7.
- Le chiamate della fase iniziale salgono al merge join, quindi scendono dall'input interno allo scambio al nodo 11.
- Attività per Ramo D vengono avviati proprio come per il ramo C, mentre l'attività padre attende al nodo 11.
- Le chiamate della fase iniziale ritornano dal nodo 11 fino ai flussi di raccolta. La fase iniziale termina qui.
- L'attività principale crea attività parallele per il Ramo B , e attende il completamento dell'apertura del ramo B.
- Le attività del ramo B raggiungono i flussi di ripartizione del nodo 5, sincronizzano, completano lo scambio e rilasciano le attività del ramo C per iniziare ad aggregare le righe degli ordinamenti.
- Quando le attività del ramo B raggiungono i flussi di ripartizione del nodo 12, sincronizzano, completano lo scambio e rilasciano le attività del ramo D per iniziare ad aggregare le righe dall'ordinamento.
- Le attività del ramo B tornano allo scambio di flussi di raccolta e si sincronizzano, liberando l'attività padre dalla sua attesa. L'attività principale è ora pronta per avviare il processo di restituzione delle righe al client.
Ti potrebbe piacere guardare l'esecuzione di questo piano in Sentry One Plan Explorer. Assicurati di abilitare l'opzione "Con profilo query live" della raccolta del piano effettivo. La cosa bella dell'esecuzione della query direttamente in Plan Explorer è che sarai in grado di scorrere più acquisizioni al tuo ritmo e persino riavvolgere. Mostrerà anche un riepilogo grafico di I/O, CPU e attese sincronizzati con i dati di profilatura delle query in tempo reale.
Note aggiuntive
L'aumento dell'albero di scansione della query durante l'elaborazione della fase iniziale imposta il primo e l'ultimo tempo attivo in ogni iteratore di profilatura per l'attività padre, ma non accumula tempo trascorso o CPU. Ascensione all'albero durante Open e GetRow le chiamate su un'attività parallela imposta l'ultimo tempo attivo e accumula il tempo trascorso e CPU a ogni iteratore di profilatura per attività.
L'elaborazione della fase iniziale è specifica per i piani paralleli in modalità riga. È necessario assicurarsi che gli scambi siano inizializzati nell'ordine corretto e che tutte le macchine parallele funzionino correttamente.
L'attività padre non esegue sempre l'intera elaborazione della fase iniziale. Le prime fasi iniziano con uno scambio di root, ma il modo in cui queste chiamate navigano nell'albero dipende dagli iteratori incontrati. Ho scelto un merge join per questa demo perché richiede l'elaborazione in fase iniziale per entrambi gli input.
Le prime fasi (ad esempio) di un join hash parallelo si propagano solo nell'input di compilazione. Quando l'hash join passa alla sua fase di indagine, si apre iteratori su quell'input, inclusi eventuali scambi. Viene avviato un altro ciclo di elaborazione della fase iniziale, gestito da (esattamente) una delle attività parallele, che svolge il ruolo dell'attività principale.
Quando l'elaborazione della fase iniziale incontra un ramo parallelo contenente un iteratore di blocco, avvia le attività parallele aggiuntive per quel ramo e attende che i produttori completino la fase di apertura. Quel ramo può anche avere rami figlio, che vengono gestiti allo stesso modo, in modo ricorsivo.
Alcuni rami in un piano parallelo in modalità riga potrebbero dover essere eseguiti su un singolo thread (ad esempio a causa di un aggregato globale o superiore). Queste "zone seriali" vengono eseguite anche su un'attività "parallela" aggiuntiva, l'unica differenza è che c'è solo un'attività, un contesto di esecuzione e un lavoratore per quel ramo. L'elaborazione della fase iniziale funziona allo stesso modo indipendentemente dal numero di attività assegnate a una filiale. Ad esempio, una "zona seriale" riporta i tempi per l'attività principale (o un'attività parallela che svolge quel ruolo) nonché per la singola attività aggiuntiva. Questo si manifesta in showplan come dati per "thread 0" (fasi iniziali) e "thread 1" (l'attività aggiuntiva).
Pensieri conclusivi
Tutto ciò rappresenta sicuramente un ulteriore livello di complessità. Il ritorno su tale investimento è nell'utilizzo delle risorse di runtime (principalmente thread e memoria), attese di sincronizzazione ridotte, maggiore velocità effettiva, metriche delle prestazioni potenzialmente accurate e una possibilità ridotta al minimo di deadlock paralleli all'interno delle query.
Sebbene il parallelismo della modalità riga sia stato in gran parte eclissato dal più moderno motore di esecuzione parallela in modalità batch, il design della modalità riga ha ancora una certa bellezza. La maggior parte degli iteratori finge di essere ancora in esecuzione in un piano seriale, con quasi tutta la sincronizzazione, il controllo del flusso e la pianificazione gestiti dagli scambi. La cura e l'attenzione evidenti nei dettagli di implementazione, come l'elaborazione della fase iniziale, consentono anche ai più grandi piani paralleli di essere eseguiti con successo senza che il progettista di query presti troppa attenzione alle difficoltà pratiche.