Cosa fa l'indicizzazione?
L'indicizzazione è il modo per inserire una tabella non ordinata in un ordine che massimizzerà l'efficienza della query durante la ricerca.
Quando una tabella non è indicizzata, l'ordine delle righe probabilmente non sarà distinguibile dalla query in quanto ottimizzato in alcun modo e la query dovrà quindi cercare tra le righe in modo lineare. In altre parole, le query dovranno cercare in ogni riga per trovare le righe che soddisfano le condizioni. Come puoi immaginare, questo può richiedere molto tempo. Guardare attraverso ogni singola riga non è molto efficiente.
Ad esempio, la tabella seguente rappresenta una tabella in un'origine dati fittizia, che è completamente non ordinata.
| company_id | unità | costo_unità |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1.95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Se dovessimo eseguire la seguente query:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
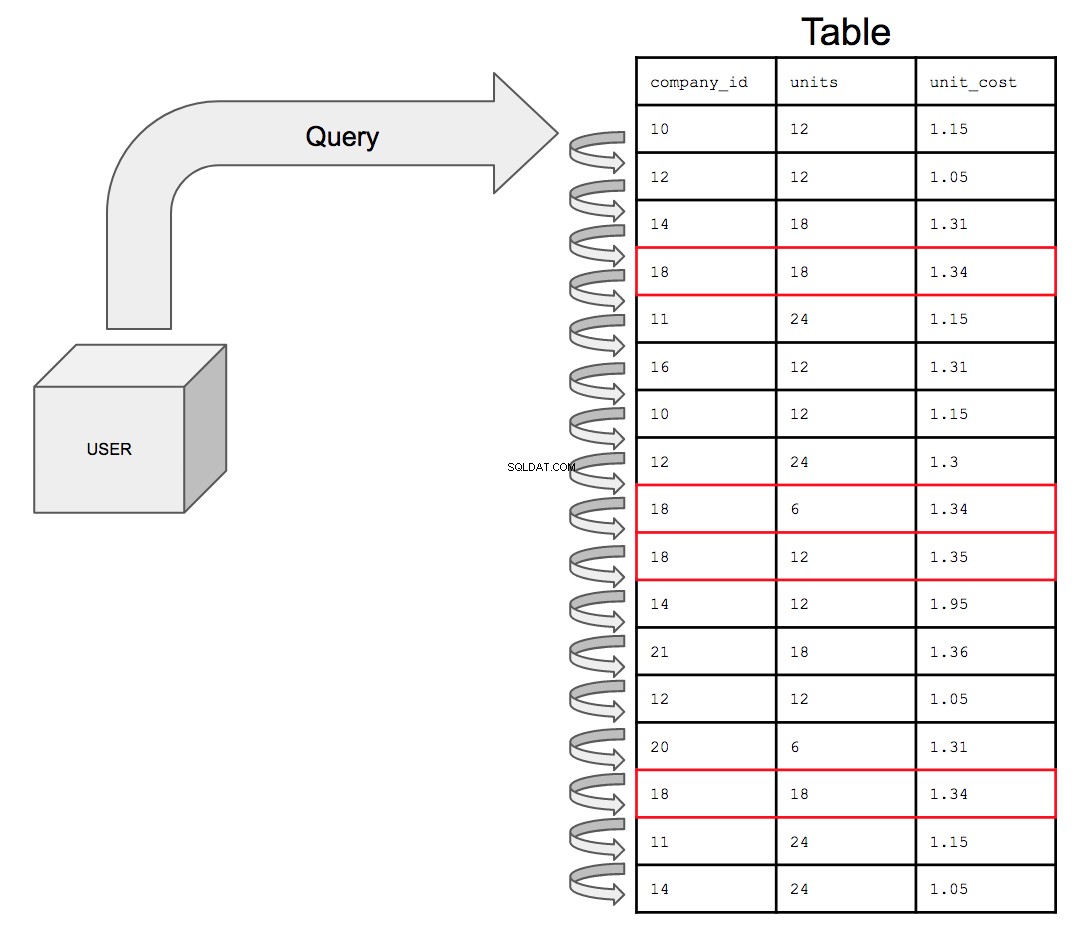
Il database dovrebbe cercare in tutte le 17 righe nell'ordine in cui appaiono nella tabella, dall'alto verso il basso, una alla volta. Quindi per cercare tutte le potenziali istanze di company_id numero 18, il database deve esaminare l'intera tabella per tutte le apparenze di 18 nel company_id colonna.
Ciò richiederà sempre più tempo all'aumentare delle dimensioni del tavolo. Con l'aumentare della sofisticazione dei dati, ciò che potrebbe eventualmente accadere è che una tabella con un miliardo di righe venga unita a un'altra tabella con un miliardo di righe; la query ora deve cercare il doppio della quantità di righe che costano il doppio del tempo.
Puoi vedere come questo diventa problematico nel nostro mondo sempre saturo di dati. Le tabelle aumentano di dimensioni e la ricerca aumenta nel tempo di esecuzione.
La query su una tabella non indicizzata, se presentata visivamente, sarebbe simile a questa:
Ciò che fa l'indicizzazione è impostare la colonna in cui si trovano le condizioni di ricerca in un ordine ordinato per ottimizzare le prestazioni della query.
Con un indice su company_id colonna, la tabella, essenzialmente, "sembrerebbe" così:
| company_id | unità | costo_unità |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1.95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Ora, il database può cercare company_id numero 18 e restituisci tutte le colonne richieste per quella riga, quindi passa alla riga successiva. Se la riga successiva è comapny_id anche il numero è 18, quindi restituirà tutte le colonne richieste nella query. Se la riga successiva è company_id è 20, la query sa di interrompere la ricerca e la query verrà completata.
Come funziona l'indicizzazione?
In realtà la tabella del database non si riordina ogni volta che cambiano le condizioni della query per ottimizzare le prestazioni della query:ciò non sarebbe realistico. In realtà, ciò che accade è che l'indice fa sì che il database crei una struttura di dati. Il tipo di struttura dati è molto probabilmente un B-Tree. Mentre i vantaggi del B-Tree sono numerosi, il vantaggio principale per i nostri scopi è che è ordinabile. Quando la struttura dei dati è ordinata, rende la nostra ricerca più efficiente per gli ovvi motivi che abbiamo indicato sopra.
Quando l'indice crea una struttura dati su una colonna specifica, è importante notare che nessun'altra colonna è memorizzata nella struttura dati. La nostra struttura dati per la tabella sopra conterrà solo il company_id numeri. Unità e unit_cost non saranno conservati nella struttura dati.
Come fa il database a sapere quali altri campi della tabella devono restituire?
Gli indici del database memorizzeranno anche i puntatori che sono semplicemente informazioni di riferimento per la posizione delle informazioni aggiuntive in memoria. Fondamentalmente l'indice contiene il company_id e l'indirizzo di casa di quella particolare riga sul disco di memoria. L'indice sarà effettivamente così:
| company_id | puntatore |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
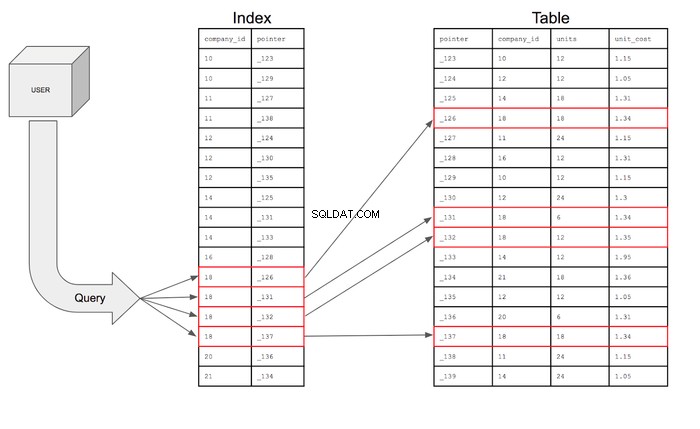
Con tale indice, la query può cercare solo le righe in company_id la colonna che ha 18 e quindi utilizzando il puntatore può andare nella tabella per trovare la riga specifica in cui si trova quel puntatore. La query può quindi entrare nella tabella per recuperare i campi per le colonne richieste per le righe che soddisfano le condizioni.
Se la ricerca fosse presentata visivamente, sarebbe simile a questa:
Riepilogo
- L'indicizzazione aggiunge una struttura dati con colonne per le condizioni di ricerca e un puntatore
- Il puntatore è l'indirizzo sul disco di memoria della riga con il resto delle informazioni
- La struttura dei dati dell'indice è ordinata per ottimizzare l'efficienza delle query
- La query cerca la riga specifica nell'indice; l'indice si riferisce al puntatore che troverà il resto delle informazioni.
- L'indice riduce il numero di righe in cui la query deve eseguire la ricerca da 17 a 4.