Questo post fa parte di una serie sugli obiettivi di fila. Puoi trovare le altre parti qui:
- Parte 1:Impostazione e identificazione degli obiettivi di fila
- Parte 2:Semi join
- Parte 3:Anti join
Applica Anti Join con un operatore Top
Vedrai spesso un operatore Top (1) interno in applica anti join piani di esecuzione. Ad esempio, utilizzando il database AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Il piano mostra un operatore Top (1) sul lato interno dell'anti join (riferimenti esterni):
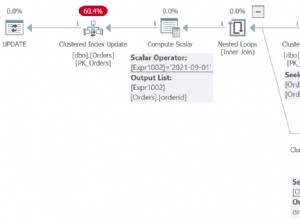
Questo operatore Top è completamente ridondante . Non è richiesto per correttezza, efficienza o per garantire che sia impostato un obiettivo di fila.
L'operatore di applicazione anti join smetterà di controllare le righe sul lato interno (per l'iterazione corrente) non appena viene visualizzata una riga al join. È perfettamente possibile generare un piano di applicazione anti join senza il Top. Allora perché c'è un operatore Top in questo piano?
Fonte dell'operatore Top
Per capire da dove viene questo inutile operatore Top, dobbiamo seguire i passaggi principali effettuati durante la compilazione e l'ottimizzazione della nostra query di esempio.
Come al solito, la query viene prima analizzata in un albero. Questo presenta un operatore logico "non esiste" con una sottoquery, che in questo caso corrisponde molto alla forma scritta della query:

La sottoquery non esiste viene srotolata in un'applicazione anti join:

Questo viene poi ulteriormente trasformato in un anti semi join logico sinistro. L'albero risultante passato all'ottimizzazione basata sui costi ha il seguente aspetto:

La prima esplorazione eseguita dall'ottimizzatore basato sui costi consiste nell'introdurre un distinto logico operazione sull'ingresso anti join inferiore, per produrre valori univoci per la chiave anti join. L'idea generale è che invece di testare i valori duplicati al join, il piano potrebbe trarre vantaggio dal raggruppare quei valori in anticipo.
La regola di esplorazione responsabile si chiama LASJNtoLASJNonDist (anti semi join sinistro a anti semi join sinistro su distinti). Non è stata ancora eseguita alcuna implementazione fisica o determinazione dei costi, quindi questo è solo l'ottimizzatore che esplora un'equivalenza logica, basata sulla presenza di ProductID duplicati valori. Di seguito viene mostrato il nuovo albero con l'operazione di raggruppamento aggiunta:

La successiva trasformazione logica considerata consiste nel riscrivere il join come applica . Questo viene esplorato utilizzando la regola LASJNtoApply (anti semi join sinistro da applicare con selezione relazionale). Come accennato in precedenza nella serie, la precedente trasformazione da apply a join consisteva nell'abilitare trasformazioni che funzionano specificamente sui join. È sempre possibile riscrivere un join come richiesta, in modo da ampliare la gamma di ottimizzazioni disponibili.
Ora, l'ottimizzatore non sempre considerare una riscrittura dell'applicazione come parte dell'ottimizzazione basata sui costi. Ci deve essere qualcosa nell'albero logico per rendere utile spingere il predicato join verso il basso. In genere, questa sarà l'esistenza di un indice di corrispondenza, ma ci sono altri obiettivi promettenti. In questo caso, è la chiave logica su ProductID creato dall'operazione di aggregazione.
Il risultato di questa regola è un anti join correlato con selezione sul lato interno:

Successivamente, l'ottimizzatore considera di spostare la selezione relazionale (il predicato di join correlato) più in basso nella parte interna, oltre il distinto (gruppo per aggregato) introdotto in precedenza dall'ottimizzatore. Questo viene fatto dalla regola SelOnGbAgg , che sposta quanto più possibile una selezione (predicato) oltre un gruppo adatto per aggregato (parte della selezione potrebbe essere lasciata indietro). Questa attività aiuta a selezione push il più vicino possibile agli operatori di accesso ai dati a livello di foglia, per eliminare le righe prima e rendere più facile la successiva corrispondenza degli indici.
In questo caso, il filtro si trova sulla stessa colonna dell'operazione di raggruppamento, quindi la trasformazione è valida. Il risultato è che l'intera selezione viene spinta sotto l'aggregato:

L'operazione finale di interesse viene eseguita dalla regola GbAggToConstScanOrTop . Questa trasformazione cerca di sostituire un gruppo per aggregato con una Scansione costante o Inizio operazione logica. Questa regola corrisponde al nostro albero perché la colonna di raggruppamento è costante per ogni riga che passa attraverso la selezione spostata verso il basso. È garantito che tutte le righe abbiano lo stesso ProductID . Il raggruppamento su quel singolo valore produrrà sempre una riga. Quindi, è valido trasformare l'aggregato in un Top (1). Quindi è da qui che viene il top.
Attuazione e determinazione dei costi
L'ottimizzatore ora esegue una serie di regole di implementazione per trovare operatori fisici per ciascuna delle alternative logiche promettenti che ha considerato finora (memorizzate in modo efficiente in una struttura memo). Le opzioni fisiche di hash e merge anti join provengono dall'albero iniziale con l'aggregazione introdotta (per gentile concessione della regola LASJNtoLASJNonDist ricordare). L'applicazione richiede un po' più di lavoro per creare un top fisico e abbinare la selezione a una ricerca dell'indice.
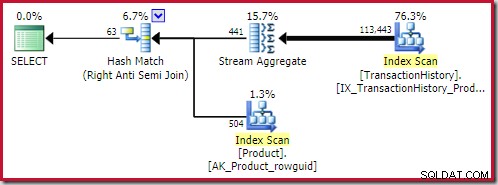
Il miglior anti join hash la soluzione trovata ha un costo di 0,362143 unità:
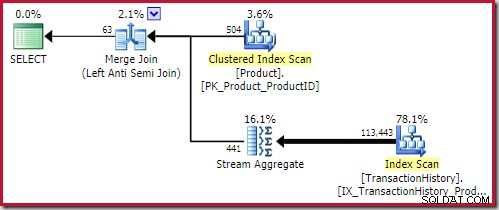
Il miglior unione anti-unione la soluzione arriva a 0,353479 unità (leggermente più economiche):
Il applica anti join costa 0,091823 unità (più economico con un ampio margine):
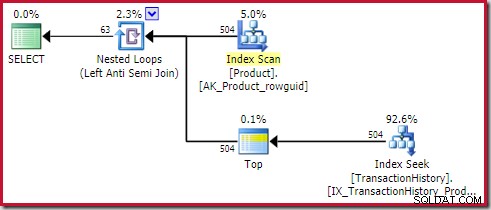
Il lettore accorto potrebbe notare che il conteggio delle righe sul lato interno dell'applicazione anti join (504) differisce dallo screenshot precedente dello stesso piano. Questo perché si tratta di un piano stimato, mentre il piano precedente era successivo all'esecuzione. Quando questo piano viene eseguito, solo un totale di 441 righe si trovano sul lato interno su tutte le iterazioni. Ciò evidenzia una delle difficoltà di visualizzazione con l'applicazione di piani semi/anti join:la stima minima dell'ottimizzatore è una riga, ma un semi o anti join individuerà sempre una riga o nessuna riga su ogni iterazione. Le 504 righe mostrate sopra rappresentano 1 riga su ciascuna delle 504 iterazioni. Per far corrispondere i numeri, la stima dovrebbe essere 441/504 =0,875 righe ogni volta, il che probabilmente confonderebbe le persone altrettanto.
Ad ogni modo, il piano di cui sopra è abbastanza "fortunato" da qualificarsi per un goal di fila sul lato interno dell'applicazione anti join per due motivi:
- L'anti join viene trasformato da join in applicazione nell'ottimizzatore basato sui costi. Questo stabilisce un obiettivo di fila (come stabilito nella parte tre).
- L'operatore Top(1) imposta anche un obiettivo di riga nel suo sottoalbero.
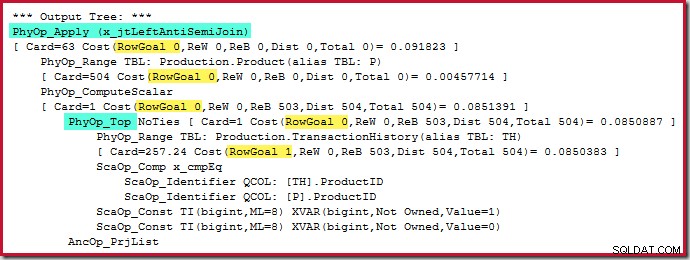
L'operatore Top stesso non ha un obiettivo di riga (da applicare) poiché l'obiettivo di riga di 1 non sarebbe inferiore rispetto alla stima normale, che è anche 1 riga (Card=1 per PhyOp_Top sotto):
Il modello Anti Join Anti
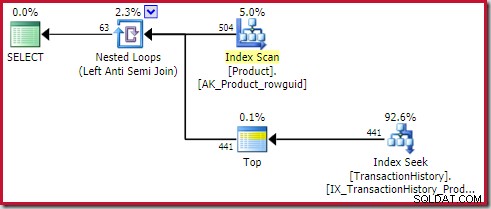
La seguente forma del piano generale è quella che considero un anti pattern:
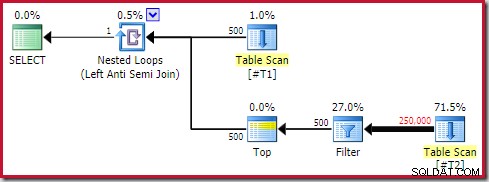
Non tutti i piani di esecuzione contenenti un'applicazione anti join con un operatore Top (1) sul lato interno saranno problematici. Tuttavia, è uno schema da riconoscere e che richiede quasi sempre ulteriori indagini.
I quattro elementi principali a cui prestare attenzione sono:
- Un ciclo nidificato correlato (applica ) anti join
- Un Top (1) operatore immediatamente sul lato interno
- Un numero significativo di righe sull'input esterno (quindi il lato interno verrà eseguito molte volte)
- Un potenzialmente costoso sottoalbero sotto il Top
Il sottoalbero "$$$" è potenzialmente costoso in fase di esecuzione . Questo può essere difficile da riconoscere. Se siamo fortunati, ci sarà qualcosa di ovvio come una tabella completa o una scansione dell'indice. Nei casi più difficili, il sottoalbero sembrerà perfettamente innocente a prima vista, ma conterrà qualcosa di costoso se osservato più da vicino. Per fare un esempio abbastanza comune, potresti vedere un Index Seek che dovrebbe restituire un numero ridotto di righe, ma che contiene un costoso predicato residuo che verifica un numero molto elevato di righe per trovare le poche che si qualificano.
L'esempio di codice AdventureWorks precedente non disponeva di una sottostruttura "potenzialmente costosa". L'Index Seek (senza predicato residuo) sarebbe un metodo di accesso ottimale indipendentemente dalle considerazioni sull'obiettivo della riga. Questo è un punto importante:fornire all'ottimizzatore un sempre efficiente il percorso di accesso ai dati sul lato interno di un join correlato è sempre una buona idea. Ciò è ancora più vero quando l'applicazione è in esecuzione in modalità anti join con un operatore Top (1) sul lato interno.
Diamo un'occhiata ora a un esempio che ha prestazioni di runtime piuttosto scarse a causa di questo anti pattern.
Esempio
Lo script seguente crea due tabelle temporanee dell'heap. Il primo ha 500 righe contenenti gli interi da 1 a 500 inclusi. La seconda tabella ha 500 copie di ogni riga della prima tabella, per un totale di 250.000 righe. Entrambe le tabelle usano sql_variant tipo di dati.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Prestazioni
Ora eseguiamo una query alla ricerca di righe nella tabella più piccola che non sono presenti nella tabella più grande (ovviamente non ce ne sono):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Questa query viene eseguita per circa 20 secondi , che è un tempo terribilmente lungo per confrontare 500 righe con 250.000. Il piano stimato di SSMS rende difficile capire perché le prestazioni potrebbero essere così scarse:
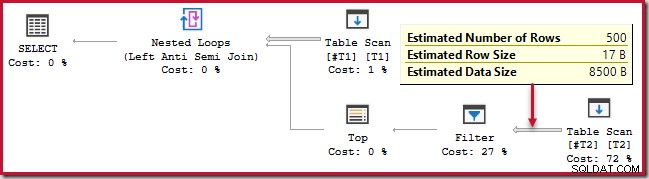
L'osservatore deve essere consapevole del fatto che i piani stimati dell'SSMS mostrano stime interne per iterazione del join di ciclo nidificato. In modo confuso, i piani effettivi di SSMS mostrano il numero di righe su tutte le iterazioni . Plan Explorer esegue automaticamente i semplici calcoli necessari ai piani stimati per mostrare anche il numero totale di righe previste:
Anche così, le prestazioni di runtime sono molto peggiori di quanto stimato. Il piano di esecuzione (effettivo) post-esecuzione è:
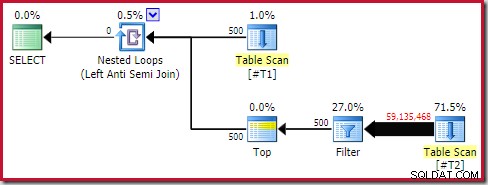
Notare il filtro separato, che normalmente verrebbe inserito nella scansione come predicato residuo. Questo è il motivo per cui si usa sql_variant tipo di dati; impedisce il push del predicato, il che rende più facile vedere l'enorme numero di righe della scansione.
Analisi
Il motivo della discrepanza dipende dal modo in cui l'ottimizzatore stima il numero di righe che dovrà leggere dalla scansione tabella per raggiungere l'obiettivo di una riga impostato sul filtro. Il semplice presupposto è che i valori siano distribuiti uniformemente nella tabella, quindi per trovare 1 dei 500 valori univoci presenti, SQL Server dovrà leggere 250.000/500 =500 righe. Oltre 500 iterazioni, che arrivano a 250.000 righe.
Il presupposto dell'uniformità dell'ottimizzatore è generale, ma qui non funziona bene. Puoi leggere di più su questo in A Row Goal Request di Joe Obbish e votare per il suo suggerimento sul forum di feedback sulla sostituzione di Connect in Use More Than Density to Cost a Scan on the Inner Side of a Nested Loop with TOP.
La mia opinione su questo aspetto specifico è che l'ottimizzatore dovrebbe ritirarsi rapidamente da un semplice presupposto di uniformità quando l'operatore si trova sul lato interno di un join di loop nidificato (ad es. riavvolgimento più ribind stimati è maggiore di uno). Una cosa è presumere che dobbiamo leggere 500 righe per trovare una corrispondenza nella prima iterazione del ciclo. Assumere questo su ogni iterazione sembra terribilmente improbabile che sia accurato; significa che le prime 500 righe incontrate dovrebbero contenere uno di ogni valore distinto. È altamente improbabile che ciò avvenga nella pratica.
Una serie di sfortunati eventi
Indipendentemente dal modo in cui vengono valutati i costi dei Top operator ripetuti, mi sembra che l'intera situazione dovrebbe essere evitata in primo luogo . Ricorda come è stato creato il Top in questo piano:
- L'ottimizzatore ha introdotto un aggregato distinto del lato interno come ottimizzazione delle prestazioni .
- Questo aggregato fornisce una chiave sulla colonna di join per definizione (produce unicità).
- Questa chiave costruita fornisce una destinazione per la conversione da un join a un apply.
- Il predicato (selezione) associato all'applicazione viene spostato verso il basso oltre l'aggregato.
- Ora è garantito che l'aggregato operi su un unico valore distinto per iterazione (poiché è un valore di correlazione).
- L'aggregato viene sostituito da un Top (1).
Tutte queste trasformazioni sono valide individualmente. Fanno parte delle normali operazioni di ottimizzazione in quanto ricerca un piano di esecuzione ragionevole. Sfortunatamente, il risultato qui è che l'aggregato speculativo introdotto dall'ottimizzatore finisce per essere trasformato in un Top (1) con un obiettivo di riga associato . L'obiettivo di fila porta alla determinazione dei costi imprecisa basata sull'ipotesi di uniformità e quindi alla selezione di un piano che è altamente improbabile che funzioni bene.
Ora, si potrebbe obiettare che l'applicazione anti join avrebbe comunque un obiettivo di riga, senza la sequenza di trasformazione sopra. La controargomentazione è che l'ottimizzatore non prenderebbe in considerazione trasformazione da anti join a applica anti join (impostazione dell'obiettivo della riga) senza che l'aggregato introdotto dall'ottimizzatore fornisca LASJNtoApply governare qualcosa a cui legarsi. Inoltre, abbiamo visto (nella terza parte) che se l'anti join fosse entrato nell'ottimizzazione basata sui costi come applicazione (anziché come join), non ci sarebbe ancora nessun obiettivo di riga .
In breve, l'obiettivo della riga nel piano finale è del tutto artificiale e non ha alcuna base nella specifica della query originale. Il problema con il gol in alto e in fila è un effetto collaterale di questo aspetto più fondamentale.
Soluzioni alternative
Ci sono molte potenziali soluzioni a questo problema. La rimozione di uno qualsiasi dei passaggi nella sequenza di ottimizzazione di cui sopra garantirà che l'ottimizzatore non produca un'implementazione di applicazione anti join con costi notevolmente (e artificialmente) ridotti. Si spera che questo problema venga risolto in SQL Server prima piuttosto che dopo.
Nel frattempo, il mio consiglio è di fare attenzione al pattern anti join anti. Assicurati che il lato interno di un'applicazione anti join abbia sempre un percorso di accesso efficiente per tutte le condizioni di runtime. Se ciò non è possibile, potrebbe essere necessario utilizzare suggerimenti, disabilitare gli obiettivi di riga, utilizzare una guida al piano o forzare un piano di archivio query per ottenere prestazioni stabili dalle query anti join.
Riepilogo serie
Abbiamo coperto molto terreno nelle quattro rate, quindi ecco un riepilogo di alto livello:
- Parte 1 – Impostazione e identificazione degli obiettivi di fila
- La sintassi della query non determina la presenza o l'assenza di un obiettivo di riga.
- Un obiettivo di fila viene impostato solo quando l'obiettivo è inferiore alla stima normale.
- Gli operatori fisici Top (inclusi quelli introdotti dall'ottimizzatore) aggiungono un obiettivo di riga al loro sottoalbero.
- Un
FASToSET ROWCOUNTistruzione imposta un obiettivo di fila alla base del piano. - Semi join e anti join maggio aggiungi un obiettivo di fila.
- SQL Server 2017 CU3 aggiunge l'attributo showplan EstimateRowsWithoutRowGoal per gli operatori interessati da un obiettivo di riga
- Le informazioni sugli obiettivi di riga possono essere rivelate da flag di traccia non documentati 8607 e 8612.
- Parte 2 – Semi join
- Non è possibile esprimere un semi join direttamente in T-SQL, quindi utilizziamo la sintassi indiretta, ad es.
IN,EXISTS, oINTERSECT. - Queste sintassi vengono analizzate in un albero contenente un'applicazione (join correlato).
- L'ottimizzatore tenta di trasformare l'applicazione in un join regolare (non sempre possibile).
- Hash, merge e semi join di loop nidificati regolari non impostano un obiettivo di riga.
- Applica semi join imposta sempre un obiettivo di fila.
- Applica semi join può essere riconosciuto avendo i riferimenti esterni sull'operatore di join dei loop nidificati.
- Applica semi join non utilizza un operatore Top (1) sul lato interno.
- Parte 3 – Anti join
- Anche analizzato in un'applicazione, con un tentativo di riscriverlo come un'unione (non sempre possibile).
- Hash, merge e loop nidificati regolari anti join non impostano un obiettivo di riga.
- Applica l'anti join non sempre imposta un obiettivo di fila.
- Solo le regole di ottimizzazione basata sui costi (CBO) che trasformano l'anti join in applicazione stabiliscono un obiettivo di riga.
- L'anti join deve entrare in CBO come join (non applicabile). In caso contrario, non è possibile eseguire il join per applicare la trasformazione.
- Per inserire CBO come adesione, è necessario che la riscrittura pre-CBO da applicare per partecipare sia riuscita.
- CBO esplora la riscrittura di un anti join in un'applicazione solo nei casi promettenti.
- Le semplificazioni precedenti alla CBO possono essere visualizzate con il flag di traccia non documentato 8621.
- Parte 4 – Anti Join Anti Pattern
- L'ottimizzatore imposta un obiettivo di riga per l'applicazione dell'anti join solo se esiste una ragione promettente per farlo.
- Purtroppo, più trasformazioni interagenti dell'ottimizzatore aggiungono un operatore Top (1) al lato interno di un'applicazione anti join.
- L'operatore Top è ridondante; non è richiesta per correttezza o efficienza.
- Il Top fissa sempre un obiettivo di fila (a differenza dell'applica, che ha bisogno di una buona ragione).
- L'obiettivo di fila ingiustificato può portare a prestazioni estremamente scarse.
- Attenzione a un sottoalbero potenzialmente costoso sotto il Top artificiale (1).