IRI offre ora anche funzioni di ricerca fuzzy, sia nel suo database gratuito che negli strumenti di profilatura di file flat, e come librerie di funzioni sul campo disponibili in IRI CoSort, FieldShield e Voracity per aumentare la qualità dei dati, la sicurezza e le capacità MDM. Questo è il primo di una serie di articoli sulle soluzioni di ricerca fuzzy IRI che coprono la loro applicazione al miglioramento della qualità dei dati.
Introduzione
La veridicità o l'affidabilità dei dati di una delle grandi parole a "V" (insieme a volume, varietà, velocità e valore) di cui parlano IRI e altri nel contesto della gestione dei dati e delle informazioni aziendali. In generale, IRI definisce i dati in dubbio come aventi uno o più di questi attributi:
- Bassa qualità, perché incoerente, imprecisa o incompleta
- Ambiguo (pensa all'MDM), impreciso (non strutturato) o ingannevole (social media)
- Prevenuto (domanda del sondaggio), rumoroso (superfluo o contaminato) o anormale (valori anomali)
- Non valido per qualsiasi altro motivo (i dati sono corretti e accurati per l'uso previsto?)
- Non sicuro:contiene informazioni personali o segreti ed è adeguatamente mascherato, reversibile, ecc.?
Questo articolo si concentra solo sulle nuove soluzioni di ricerca fuzzy al primo problema, la qualità dei dati. Altri articoli in questo blog discutono di come il software IRI risolve gli altri quattro problemi di veridicità; chiedi aiuto per trovarli se non puoi.
Informazioni sulla ricerca fuzzy
Le ricerche fuzzy trovano parole o frasi (valori) simili, ma non necessariamente identiche, ad altre parole o frasi (valori). Questo tipo di ricerca ha molti usi, come trovare errori di sequenza, errori di ortografia, caratteri trasposti e altri che tratteremo in seguito.
L'esecuzione di una ricerca sfocata di parole o frasi approssimative può aiutare a trovare dati che potrebbero essere duplicati di dati memorizzati in precedenza. Tuttavia, l'input dell'utente o la correzione automatica potrebbero aver alterato i dati in qualche modo per far sembrare i record indipendenti.
Il resto dell'articolo tratterà quattro funzioni di ricerca fuzzy ora supportate da IRI, come utilizzarle per setacciare i dati e restituire quei record che si avvicinano al valore di ricerca.
1. Levenshtein
L'algoritmo di Levenshtein funziona prendendo due parole o frasi e contando quanti passaggi di modifica saranno necessari per trasformare una parola o una frase nell'altra. Meno passaggi saranno necessari, più è probabile che la parola o la frase corrisponda. I passaggi che la funzione di Levenshtein può eseguire sono:
- Inserimento di un carattere nella parola o frase
- Cancellazione di un carattere dalla parola o frase
- Sostituzione di un carattere in una parola o frase con un altro
Quello che segue è un programma CoSort SortCL (script di lavoro) che mostra come utilizzare la funzione di ricerca fuzzy di Levenshtein:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Ci sono due parti che devono essere utilizzate per produrre l'output desiderato.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Questa riga chiama la funzione fs_levenshtein e memorizza il risultato nel campo FS_RESULT. La funzione accetta due parametri di input:
- Il campo su cui eseguire la ricerca fuzzy (NOME nel nostro esempio)
- La stringa con cui verrà confrontato il campo di input ("Barney Oakley" nel nostro esempio).
/INCLUDE WHERE FS_RESULT GT 50
Questa riga confronta il campo FS_RESULT e controlla se è maggiore di 50, quindi vengono emessi solo i record con un FS_RESULT superiore a 50. Quanto segue mostra l'output del nostro esempio.

Come mostra l'output, questo tipo di ricerca è utile per trovare:
- Nomi concatenati
- Rumore
- Errori di ortografia
- Caratteri trasposti
- Errori di trascrizione
- Errori di digitazione
La funzione di Levenshtein è quindi utile anche per identificare gli errori comuni di immissione dei dati. Tuttavia, l'esecuzione dei quattro algoritmi richiede più tempo, poiché confronta ogni carattere di una stringa con ogni carattere dell'altra.
Il coefficiente dei dadi, o algoritmo dei dadi, suddivide parole o frasi in coppie di caratteri, confronta quelle coppie e conta le corrispondenze. Più corrispondenze hanno le parole, più è probabile che la parola stessa sia una corrispondenza.
Il seguente script SortCL mostra la funzione di ricerca fuzzy del coefficiente dei dadi.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Ci sono due parti che devono essere utilizzate per fornirci l'output desiderato.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Questa riga chiama la funzione fs_dice e memorizza il risultato nel campo FS_RESULT. La funzione accetta due parametri di input:
- Il campo su cui eseguire la ricerca fuzzy (NOME nel nostro esempio).
- La stringa con cui verrà confrontato il campo di input ("Robert Thomas Smith" nel nostro esempio).
/INCLUDE WHERE FS_RESULT GT 50
Questa riga confronta il campo FS_RESULT e controlla se è maggiore di 50, quindi vengono emessi solo i record con un FS_RESULT superiore a 50. Quanto segue mostra l'output del nostro esempio.
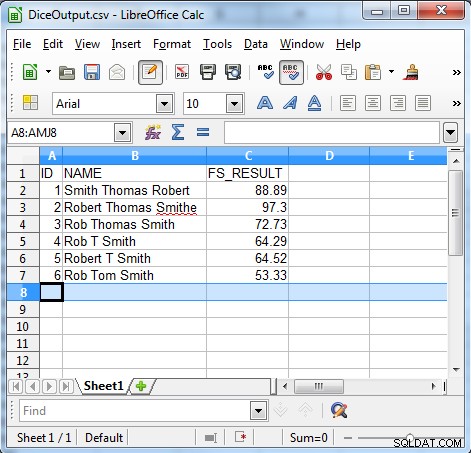
Poiché l'output mostra l'algoritmo del coefficiente dei dadi è utile per trovare dati incoerenti come:
- Errori di sequenza
- Correzioni involontarie
- Nomi
- Iniziali e soprannomi
- Uso imprevedibile delle iniziali
- Localizzazione
L'algoritmo dei dadi è più veloce del Levenshtein, ma può diventare meno accurato quando sono presenti molti semplici errori come errori di battitura.
3. Metafono e 4. Soundex
gli algoritmi Metaphone e Soundex confrontano parole o frasi in base ai loro suoni fonetici. Soundex lo fa leggendo la parola o la frase e guardando i singoli caratteri, mentre Metaphone esamina sia i singoli caratteri che i gruppi di caratteri. Quindi entrambi forniscono codici in base all'ortografia e alla pronuncia della parola.
Il seguente script SortCL mostra le funzioni di ricerca di Soundex e Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
In ogni caso, ci sono tre parti che devono essere utilizzate per darci l'output desiderato.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
La linea chiama la funzione e memorizza il risultato nel campo RISULTATO. Entrambe le funzioni accettano due parametri di input:
- Il campo su cui eseguire la ricerca fuzzy (NOME nel nostro esempio)
- La stringa x con cui verrà confrontato il campo di input ("John" nel nostro esempio)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Questa riga confronta i campi SE_RESULT e MP_RESULT e controlla e restituisce la riga se uno dei due è maggiore di 0.
Soundex restituisce 100 per una corrispondenza o 0 se non è una corrispondenza. Metaphone ha risultati più specifici e restituisce 100 per una corrispondenza forte, 66 per una corrispondenza normale e 33 per una corrispondenza minore.
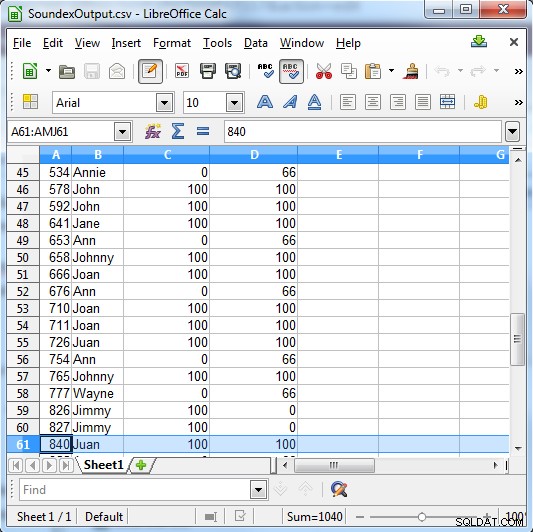
Colonna C mostra i risultati di Soundex. Ccolonna D mostra i risultati di Metaphone
Come mostra l'output, questo tipo di ricerca è utile per trovare:
- Errori fonetici
Invia un feedback su questo articolo di seguito e, se sei interessato a utilizzare queste funzioni, contatta il tuo rappresentante IRI. Consulta il nostro prossimo articolo sull'utilizzo di questi algoritmi nella procedura guidata di consolidamento (qualità) dei dati di IRI Workbench.



