I professionisti dei dati non sempre riescono a utilizzare database con un design ottimale. A volte le cose che ti fanno piangere sono cose che abbiamo fatto a noi stessi, perché all'epoca sembravano buone idee. A volte sono a causa di applicazioni di terze parti. A volte semplicemente ti precedono.
Quello a cui sto pensando in questo post è quando la tua colonna datetime (o datetime2, o meglio ancora datetimeoffset) è in realtà due colonne:una per la data e una per l'ora. (Se hai di nuovo una colonna separata per l'offset, ti abbraccerò la prossima volta che ti vedrò, perché probabilmente hai dovuto affrontare tutti i tipi di ferite.)
Ho fatto un sondaggio su Twitter e ho scoperto che questo è un problema molto reale che circa la metà di voi ha a che fare con data e ora di tanto in tanto.
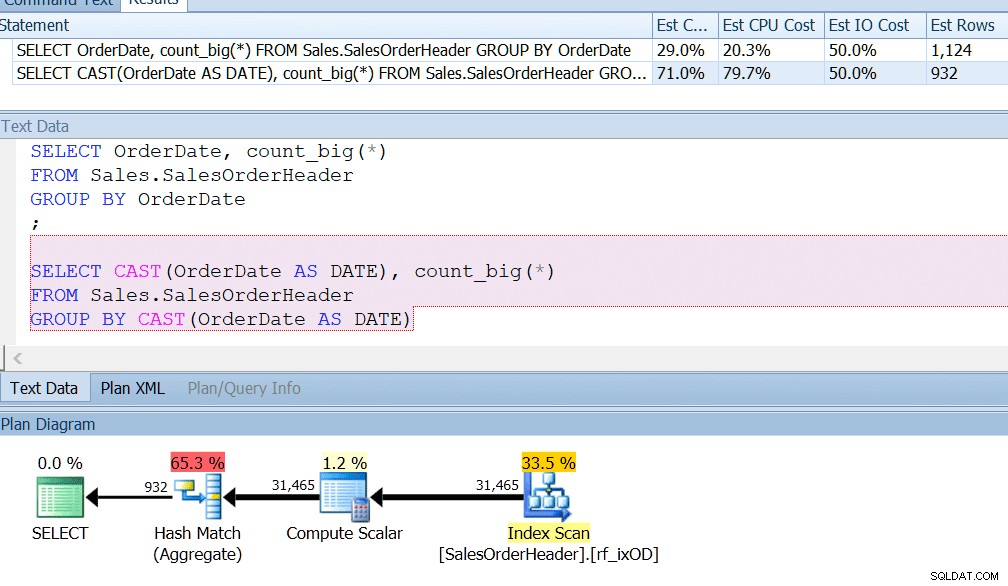
AdventureWorks lo fa quasi:se guardi nella tabella Sales.SalesOrderHeader, vedrai una colonna datetime chiamata OrderDate, che contiene sempre date esatte. Scommetto che se sei uno sviluppatore di report presso AdventureWorks, probabilmente hai scritto query che cercano il numero di ordini in un determinato giorno, utilizzando GROUP BY OrderDate o qualcosa del genere. Anche se sapessi che si tratta di una colonna datetime e che potrebbe memorizzare anche un'ora non di mezzanotte, diresti comunque GROUP BY OrderDate solo per il gusto di utilizzare correttamente un indice. GROUP BY CAST(OrderDate AS DATE) semplicemente non lo taglia.
Ho un indice su OrderDate, come faresti se eseguissi regolarmente query su quella colonna, e posso vedere che il raggruppamento per CAST (OrderDate AS DATE) è circa quattro volte peggiore dal punto di vista della CPU.
Quindi capisco perché saresti felice di interrogare la tua colonna come se fosse una data, semplicemente sapendo che avrai un mondo di dolore se l'uso di quella colonna cambia. Forse lo risolvi avendo un vincolo sul tavolo. Forse hai appena messo la testa sotto la sabbia.
E quando qualcuno arriva e dice "Sai, dovremmo memorizzare anche il tempo in cui accadono gli ordini", beh, pensi a tutto il codice che presuppone che OrderDate sia semplicemente una data e immagini che avere una colonna separata chiamata OrderTime (tipo di dati di tempo, per favore) sarà l'opzione più sensata. Capisco. Non è l'ideale, ma funziona senza rompere troppe cose.
A questo punto, ti consiglio di creare anche OrderDateTime, che sarebbe una colonna calcolata che unisce i due (cosa che dovresti fare aggiungendo il numero di giorni dal giorno 0 a CAST(OrderDate as datetime2), piuttosto che provare ad aggiungere l'ora a data, che generalmente è molto più disordinata). E poi indicizzare OrderDateTime, perché sarebbe sensato.
Ma abbastanza spesso, ti ritroverai con data e ora come colonne separate, praticamente senza nulla che tu possa fare al riguardo. Non puoi aggiungere una colonna calcolata, perché è un'applicazione di terze parti e non sai cosa potrebbe rompersi. Sei sicuro che non facciano mai SELECT *? Un giorno spero che ci permettano di aggiungere colonne e nasconderle, ma per il momento rischi sicuramente di rompere le cose.
E, sai, anche msdb lo fa. Sono entrambi numeri interi. Ed è a causa della compatibilità con le versioni precedenti, suppongo. Ma dubito che tu stia considerando di aggiungere una colonna calcolata a una tabella in msdb.
Quindi come lo interroghiamo? Supponiamo di voler trovare le voci che erano all'interno di un particolare intervallo datetime?
Facciamo un po' di esperimenti.
Per prima cosa, creiamo una tabella con 3 milioni di righe e indicizziamo le colonne che ci interessano.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Avrei potuto renderlo un indice cluster, ma immagino che un indice non cluster sia più tipico per il tuo ambiente.)
I nostri dati sono simili a questo e voglio trovare righe tra, diciamo, il 2 agosto 2011 alle 8:30 e il 5 agosto 2011 alle 21:30.
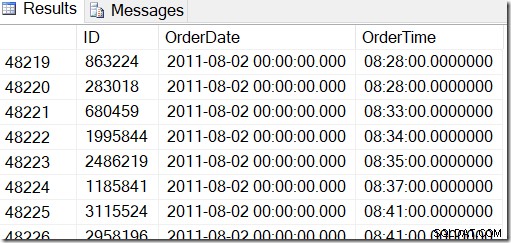
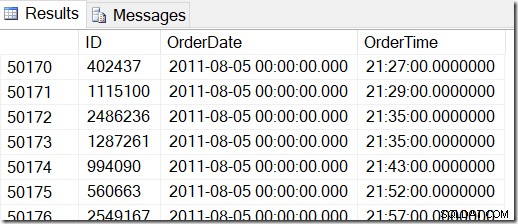
Esaminando i dati, posso vedere che voglio tutte le righe comprese tra 48221 e 50171. Sono 50171-48221 + 1 =1951 righe (il +1 è perché è un intervallo inclusivo). Questo mi aiuta a essere sicuro che i miei risultati siano corretti. Probabilmente avresti qualcosa di simile sulla tua macchina, ma non esatto, perché ho usato valori casuali durante la generazione della mia tabella.
So che non posso semplicemente fare qualcosa del genere:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
...perché questo non includerebbe qualcosa che è successo durante la notte il 4. Questo mi dà 1268 righe – chiaramente non giuste.
Un'opzione è combinare le colonne:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Questo dà i risultati corretti. Lo fa. È solo che questo è completamente non sargable e ci dà una scansione su tutte le righe della nostra tabella. Sulle nostre 3 milioni di righe potrebbero essere necessari secondi per eseguirlo.
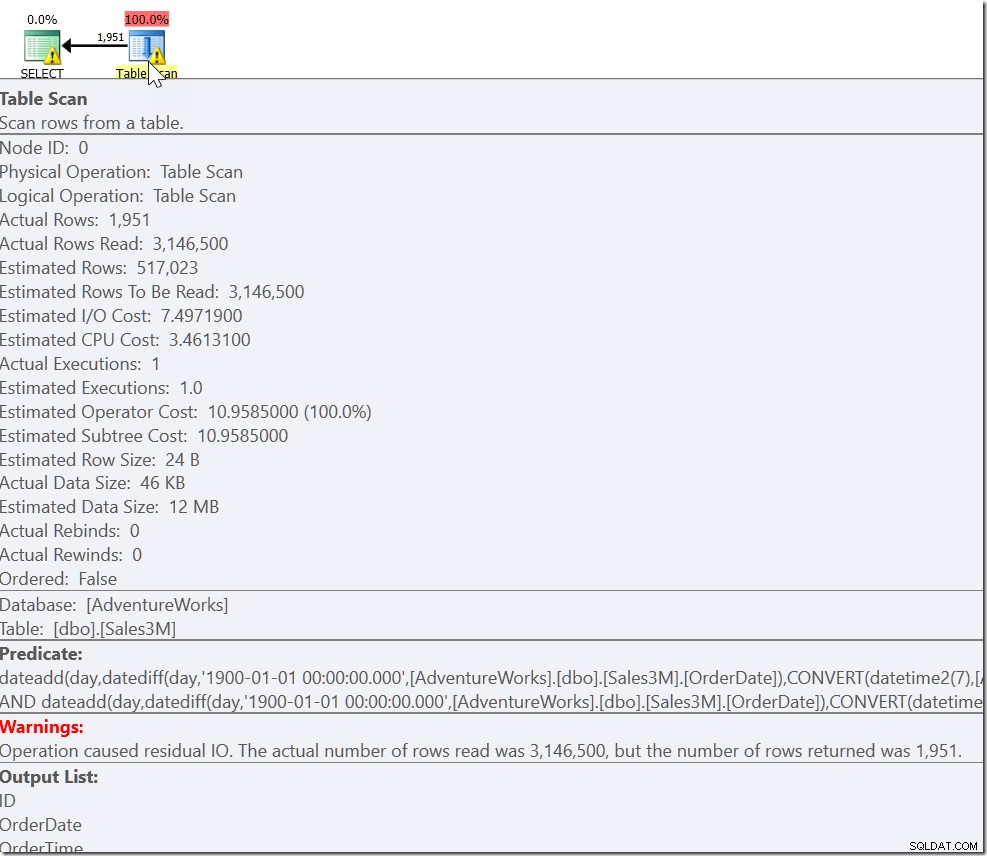
Il nostro problema è che abbiamo un caso ordinario e due casi speciali. Sappiamo che ogni riga che soddisfa OrderDate> '20110802' AND OrderDate <'20110805' è quella che vogliamo. Ma abbiamo anche bisogno di ogni riga che è o dopo le 8:30 su 20110802 e prima o dopo le 21:30 su 20110805. E questo ci porta a:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
O è terribile, lo so. Può anche portare a scansioni, anche se non necessariamente. Qui vedo tre ricerche di indice, concatenate e quindi controllate per l'unicità. Query Optimizer ovviamente si rende conto che non dovrebbe restituire la stessa riga due volte, ma non si rende conto che le tre condizioni si escludono a vicenda. E in realtà, se lo facessi su un intervallo in un solo giorno, otterresti risultati sbagliati.
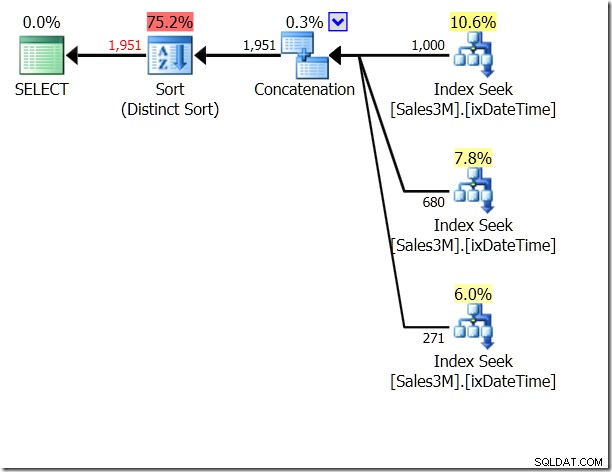
Potremmo usare UNION ALL su questo, il che significherebbe che al QO non importerebbe se le condizioni si escludono a vicenda. Questo ci dà tre Seek che sono concatenati:è abbastanza buono.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Ma sono ancora tre ricerche. Statistics IO mi dice che sono 20 letture sulla mia macchina.

Ora, quando penso alla sargability, non penso solo a evitare di inserire colonne di indici all'interno delle espressioni, penso anche a cosa potrebbe aiutare qualcosa a sembrare sargabile.
Prendi WHERE LastName LIKE 'Far%' per esempio. Quando guardo il piano per questo, vedo un Seek, con un Seek Predicate che sta cercando qualsiasi nome da Far fino a (ma non incluso) FaS. E poi c'è un predicato residuo che controlla la condizione LIKE. Questo non è dovuto al fatto che il QO considera che LIKE sia sargable. Se lo fosse, sarebbe in grado di utilizzare LIKE nel Seek Predicate. È perché sa che tutto ciò che è soddisfatto da quella condizione LIKE deve essere all'interno di quell'intervallo.
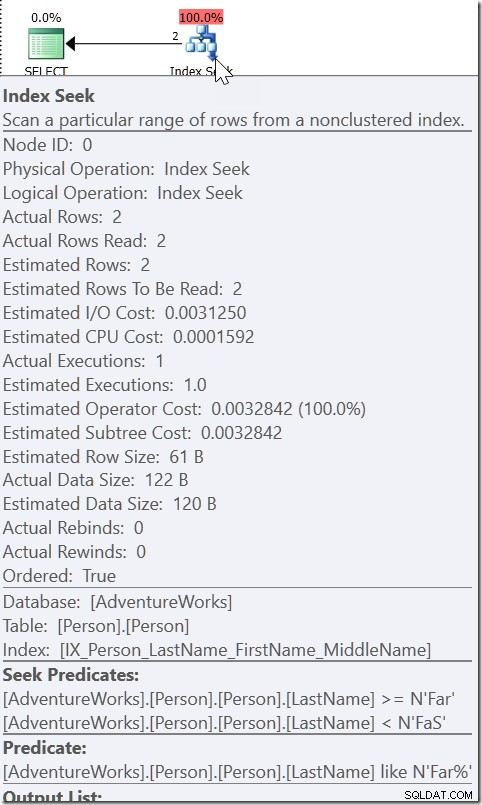
Prendi WHERE CAST(OrderDate AS DATE) ='20110805'
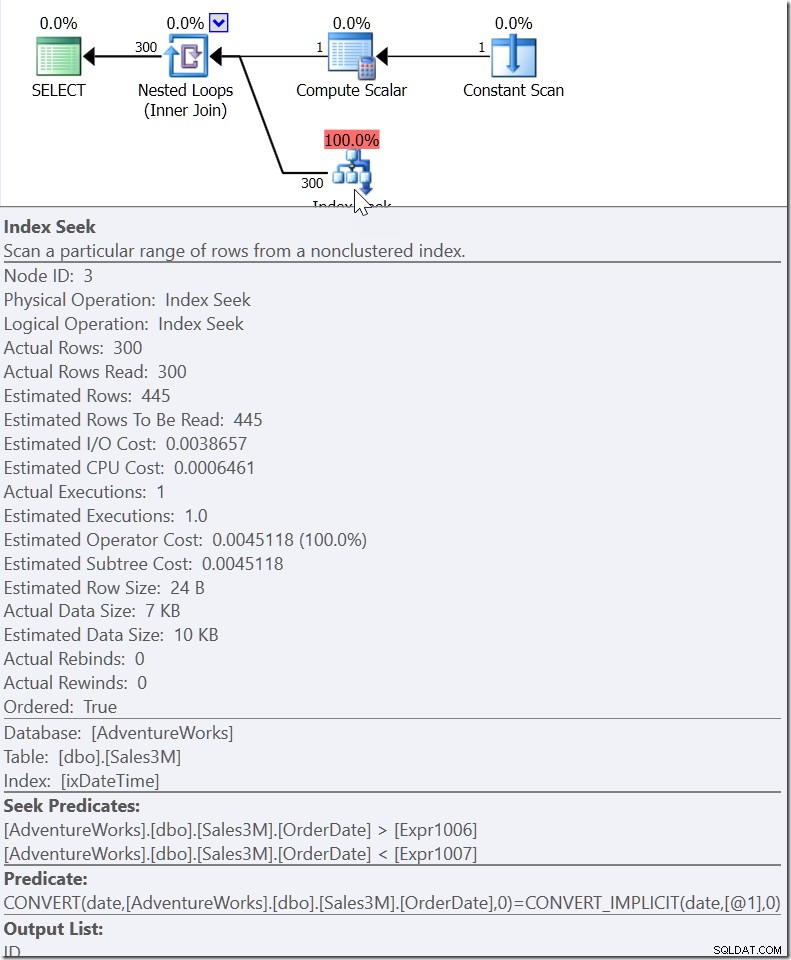
Qui vediamo un predicato di ricerca che cerca i valori OrderDate tra due valori che sono stati elaborati altrove nel piano, ma creando un intervallo in cui devono esistere i valori corretti. Questo non è>=20110805 00:00 e <20110806 00:00 (che è quello che l'avrei fatto), è qualcos'altro. Il valore per l'inizio di questo intervallo deve essere inferiore a 20110805 00:00, perché è>, non>=. Tutto ciò che possiamo davvero dire è che quando qualcuno all'interno di Microsoft ha implementato il modo in cui il QO dovrebbe rispondere a questo tipo di predicato, ha fornito informazioni sufficienti per elaborare quello che chiamo un "predicato di supporto".
Ora, mi piacerebbe che Microsoft rendesse più funzioni selezionabili, ma quella particolare richiesta è stata chiusa molto prima che ritirassero Connect.
Ma forse quello che voglio dire è che facciano più predicati di supporto.
Il problema con i predicati di supporto è che quasi sicuramente leggono più righe di quelle che desideri. Ma è comunque molto meglio che guardare l'intero indice.
So che tutte le righe che voglio restituire avranno OrderDate tra 20110802 e 20110805. È solo che ce ne sono alcune che non voglio.
Potrei semplicemente rimuoverli e questo sarebbe valido:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
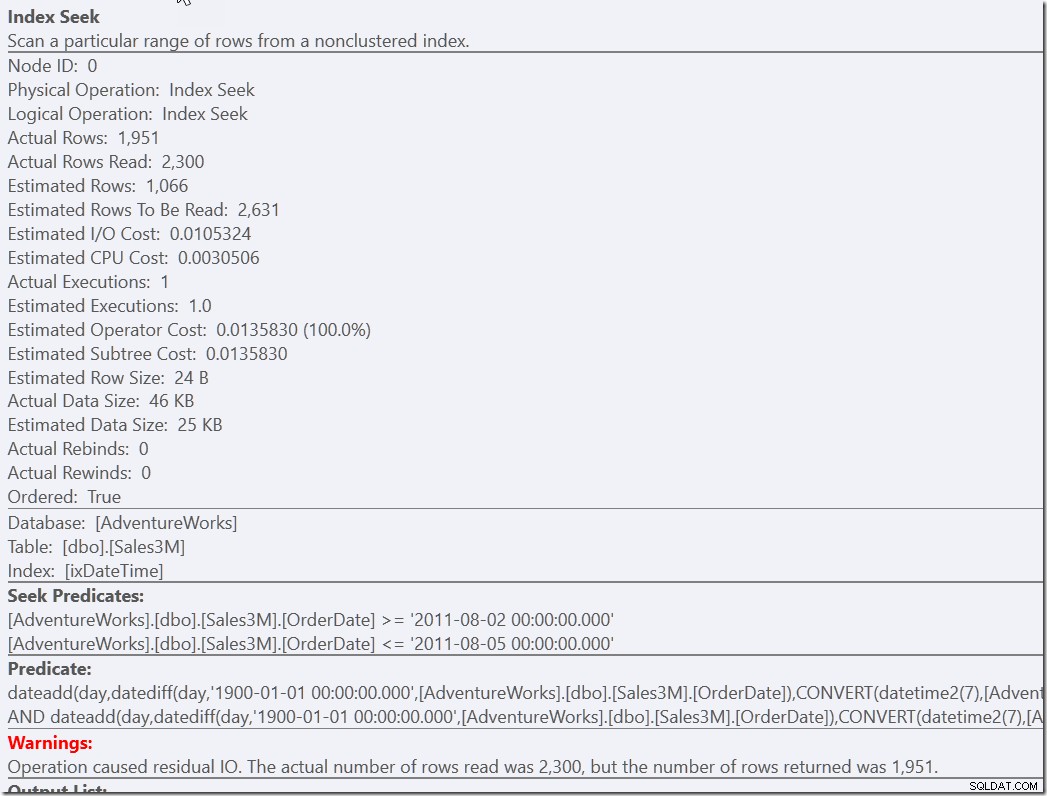
Ma sento che questa è una soluzione che richiede uno sforzo di pensiero per trovare. Uno sforzo minore da parte dello sviluppatore consiste nel fornire semplicemente un predicato di supporto alla nostra versione corretta ma lenta.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Entrambe queste query trovano le 2300 righe che si trovano nei giorni giusti e quindi devono controllare tutte quelle righe rispetto agli altri predicati. Uno deve controllare le due condizioni NOT, l'altro deve eseguire alcune conversioni di tipo e calcoli. Ma entrambi sono molto più veloci di quello che avevamo prima e fanno una singola ricerca (13 letture). Certo, ricevo avvisi su un RangeScan inefficiente, ma questa è la mia preferenza rispetto a tre efficienti.
In un certo senso, il problema più grande con quest'ultimo esempio è che una persona ben intenzionata vedrebbe che il predicato dell'helper era ridondante e potrebbe eliminarlo. Questo è il caso di tutti i predicati di supporto. Quindi inserisci un commento.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Se hai qualcosa che non si adatta a un bel predicato sargable, elaborane uno che lo sia e poi scopri cosa devi escludere da esso. Potresti trovare una soluzione migliore.
@rob_farley