A febbraio ho scritto un post sul blog sulla correzione automatica del piano in SQL Server e in questo post voglio parlare della gestione automatica degli indici, il secondo componente della funzionalità di ottimizzazione automatica. La gestione automatica degli indici è disponibile solo nel database SQL di Azure e attualmente non è prevista nella roadmap per essere disponibile nella prossima versione di SQL Server in locale. Questa opzione è abilitata indipendentemente dalla correzione automatica del piano e, come suggerisce il nome, gestirà gli indici nel tuo database. In particolare, può creare indici mancanti e rimuovere gli indici non utilizzati e quelli duplicati. Diamo un'occhiata a come ciò si verifica.
Sotto le coperte
La gestione automatica dell'indice si basa sui dati per prendere una decisione. Per la potenziale creazione dell'indice, utilizza le informazioni relative all'indice DMV mancante e le tiene traccia nel tempo e combina tali dati con un modello interno per determinare il vantaggio dell'indice. Utilizza anche Query Store per determinare se l'indice offre vantaggi, quindi deve essere abilitato per il database, proprio come con la correzione automatica del piano. Per quanto riguarda l'eliminazione degli indici, vengono utilizzati i dati della DMV di utilizzo dell'indice (sys.dm_db_index_usage_stats) e i metadati dell'indice (ad es. numero di colonne, tipi di dati di colonna).
Abilitazione della gestione automatica dell'indice
Come accennato, Query Store deve essere abilitato per il database. Questa operazione può essere eseguita in SSMS, con T-SQL e con l'API REST per il database SQL di Azure. Tieni presente che Query Store è abilitato per impostazione predefinita per i database in Azure e lo è dal 4° trimestre 2016.
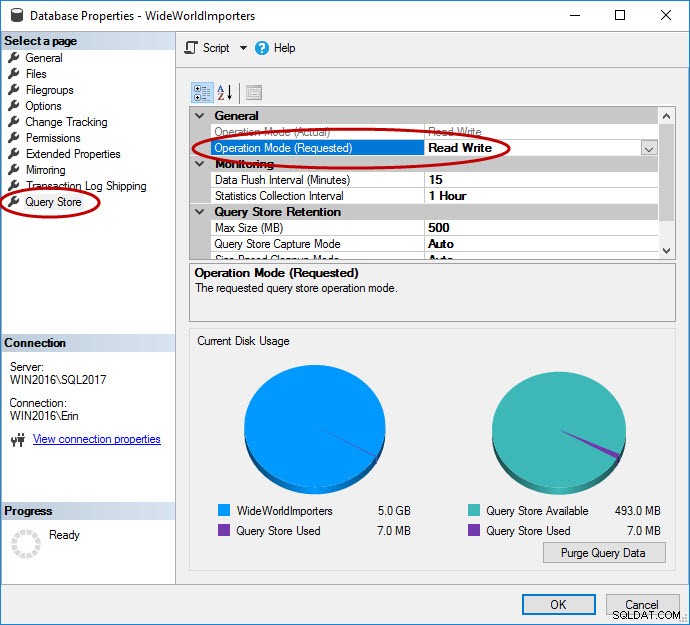
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
Una volta abilitato Query Store, è possibile usare il portale di Azure, l'API T-SQL o EST per abilitare la gestione automatica degli indici nel database SQL di Azure (C# e PowerShell sono in lavorazione).
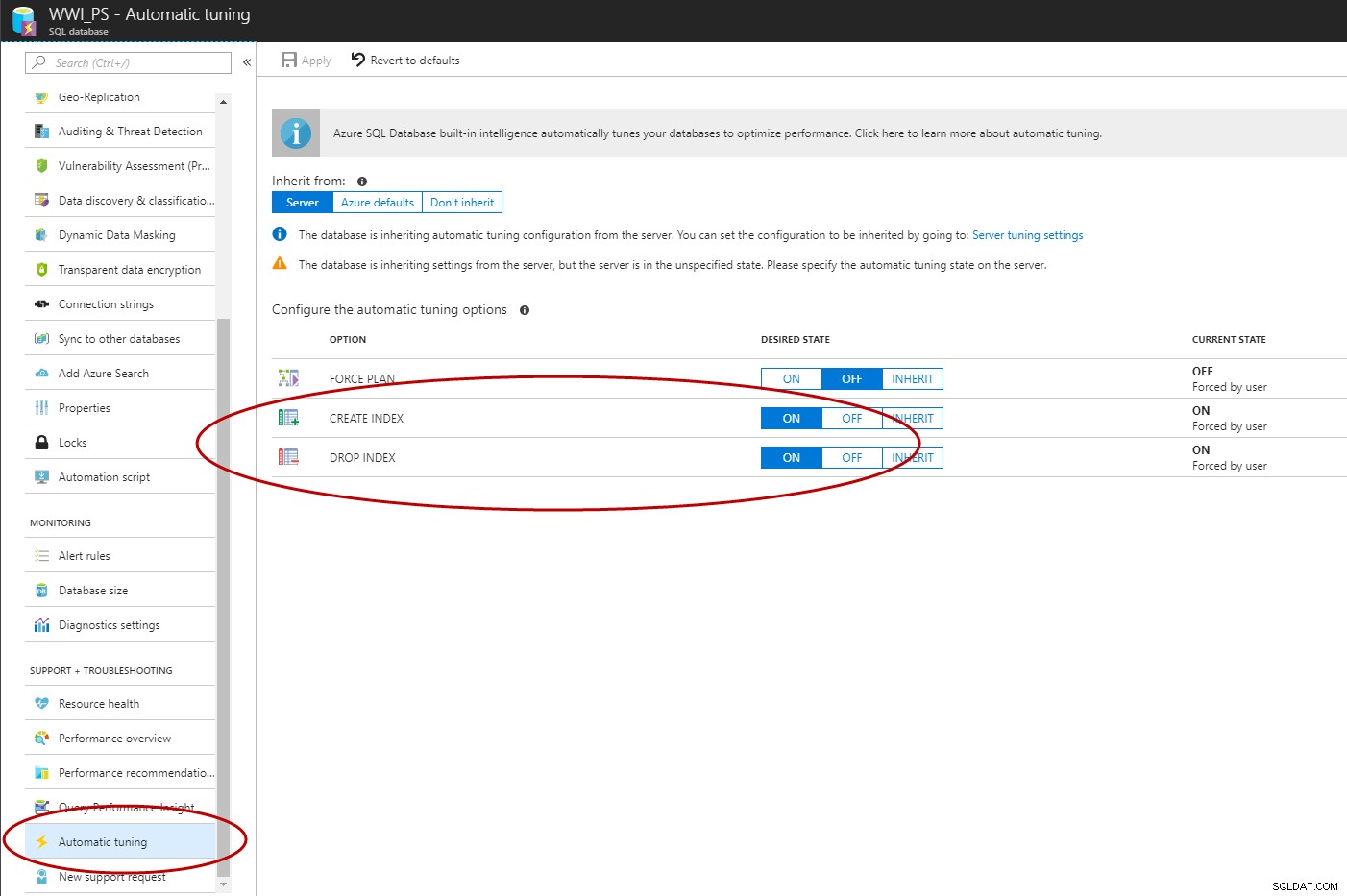
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
La gestione automatica degli indici sarà abilitata per impostazione predefinita per i nuovi database in Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/) nel prossimo futuro. A partire da gennaio 2018, Microsoft ha avviato il roll-out per abilitare l'ottimizzazione automatica per i database SQL di Azure che non lo avevano già abilitato, con notifiche inviate agli amministratori in modo che l'opzione possa essere disabilitata se lo si desidera. Questo processo richiede diversi mesi, quindi se non hai ancora ricevuto una notifica, non farti prendere dal panico!
Come funziona
Per la creazione dell'indice esiste, attualmente, una finestra mobile di sette (7) giorni* durante la quale vengono tracciati i dati e come minimo il modello necessita di nove (9) ore* di dati per consigliare un indice, insieme con 12 ore* di dati in Query Store che verranno utilizzati come baseline. Se viene stabilito che un indice fornirà un vantaggio significativo, SQL Server creerà l'indice.
*Questi valori possono cambiare in futuro, man mano che il modello si sviluppa.
Nota:al momento il modello unisce le raccomandazioni. Ovvero, se per una tabella sono consigliati più indici, ma è possibile creare un indice per coprire tutte le opzioni, è possibile creare quell'indice attualmente. Tuttavia, il modello non è attualmente sufficientemente intelligente per unire un indice consigliato con uno già esistente.
Dopo aver creato un indice, SQL Server verifica che offra vantaggi utilizzando Query Store (quindi deve essere abilitato per il database). Monitora le prestazioni di qualsiasi query che utilizza il nuovo indice e confronta la CPU della query prima dell'aggiunta dell'indice e quando si utilizza l'indice. Se si verifica una regressione nelle prestazioni della query a causa dell'indice, verrà ripristinato (eliminato) l'indice. SQL Server monitora le prestazioni delle query per un massimo di tre (3) giorni o fino all'analisi del 100% del carico di lavoro pertinente. Dopo tale periodo di tempo, se l'indice non mostra alcun segno di regressione, non rivedrà più la sua performance.
Tieni presente che se Gestione automatica dell'indice crea un indice e due mesi dopo il carico di lavoro cambia e trarrà vantaggio dallo stesso indice creato automaticamente in precedenza ma con una colonna aggiuntiva, SQL Server creerà, al momento, un nuovo indice. Al momento non esiste alcuna logica per modificare un indice esistente creato automaticamente, ma tale funzionalità è nella tabella di marcia per la funzione.
Per quanto riguarda l'eliminazione degli indici, se un indice non ha ricerche o scansioni per 90 giorni, ma ha un costo di manutenzione (il che significa che ci sono inserimenti, aggiornamenti o eliminazioni), verrà eliminato. Verranno rimossi anche gli indici duplicati, presupponendo che siano un duplicato esatto (e lo schema viene utilizzato per determinare se gli indici sono esattamente gli stessi). Se sono presenti indici duplicati in termini di colonne chiave e colonne incluse (se pertinente) ma uno o più di essi hanno un filtro, non sono realmente duplicati e nessun indice verrà eliminato.
Per riferimento, nel database SQL di Azure sono disponibili il doppio dei consigli DROP INDEX rispetto ai consigli CREATE INDEX.
Quando si abilita l'opzione DROP INDEX, SQL Server eliminerà gli indici creati dall'utente. Quando si abilita l'opzione CREATE INDEX, SQL Server ha la possibilità di creare indici automaticamente e può anche eliminare tali indici (ma non eliminerà gli indici creati dall'utente). Infine, gli indici vengono creati ed eliminati durante i periodi di carico di lavoro non di punta, come determinato da DTU. Se il carico di lavoro è superiore all'80% DTU, SQL Server attende la creazione o l'eliminazione dell'indice finché il carico del sistema non diminuisce.
Lascerò davvero il controllo a SQL Server?
Forse. La mia raccomandazione su questa funzione, inizialmente, richiede un approccio "fiducia ma verifica".
Come per la correzione automatica del piano, la gestione automatica dell'indice è stata sviluppata con una notevole quantità di dati acquisiti da quasi due milioni di database SQL di Azure. La funzionalità di gestione automatica degli indici è disponibile nel database SQL di Azure dal primo trimestre del 2016, come parte di Index Advisor.
Gli algoritmi utilizzati dalla funzione si sono evoluti e continuano ad evolversi nel tempo, man mano che più database lo utilizzano e più dati vengono acquisiti e analizzati. Tuttavia, al momento ci sono alcune limitazioni.
- Le raccomandazioni sugli indici non vengono valutate rispetto agli indici esistenti, pertanto il consolidamento degli indici tra indici nuovi ed esistenti non è attualmente disponibile.
- Se un indice fornisce vantaggi per un SELECT, il sovraccarico delle modifiche dovute a INSERT, UPDATE e DELETE non è noto prima della creazione. SQL Server esegue il monitoraggio di questo sovraccarico durante il processo di verifica, dopo l'implementazione dell'indice.
Ci sono vantaggi della gestione automatica degli indici che vale la pena sottolineare:
- Per chiunque debba gestire un database SQL Server, ma non è un DBA, i consigli sugli indici possono essere estremamente utili.
- I consigli sugli indici vengono acquisiti nella DMV sys.dm_db_tuning_recommendations anche se le opzioni degli indici CREATE e DROP non sono abilitate. Pertanto, se non sei sicuro delle modifiche che SQL Server potrebbe apportare, puoi rivedere ciò che viene acquisito nella DMV e quindi prendere una decisione per implementare manualmente il consiglio.
Nota:se si implementa manualmente la raccomandazione, SQL Server non esegue alcuna convalida. Se si implementa la raccomandazione tramite il portale (utilizzando il pulsante Applica) o l'API REST, verrà eseguita come se fosse un'azione automatica e verrà eseguita la convalida (e l'indice potrebbe essere ripristinato automaticamente in caso di regressione).
- La funzionalità continua a migliorare. Come ho detto prima, Microsoft non sta cercando di programmare DBA o sviluppatori senza lavoro, sta cercando di affrontare i frutti a basso impatto in modo da avere più tempo per le attività e i progetti che non possono essere automatizzati in modo intelligente.
Riepilogo
Se non sei pronto a cedere le redini della gestione dell'indice, ho capito. Ma se hai almeno un database SQL di Azure, dovresti controllare regolarmente il DMV sys.dm_db_tuning_recommendations per vedere cosa consiglia SQL Server e confrontarlo con i dati che tu o il tuo strumento di monitoraggio di terze parti potreste acquisire sull'utilizzo dell'indice. Dopotutto, quando è stata l'ultima volta che hai eseguito una revisione completa e approfondita dei tuoi indici per capire cosa manca, cosa viene realmente utilizzato e cosa sta semplicemente generando un sovraccarico nel database?