Panoramica
Oracle Data Mining (ODM) è un componente dell'opzione Oracle Advanced Analytics Database. ODM contiene una suite di algoritmi di data mining avanzati incorporati nel database che ti consentono di eseguire analisi avanzate sui tuoi dati.
Oracle Data Miner è un'estensione di Oracle SQL Developer, un ambiente di sviluppo grafico per Oracle SQL. Oracle Data Miner utilizza la tecnologia di data mining incorporata in Oracle Database per creare, eseguire e gestire flussi di lavoro che incapsulano le operazioni di data mining. L'architettura di ODM è illustrata nella figura 1.
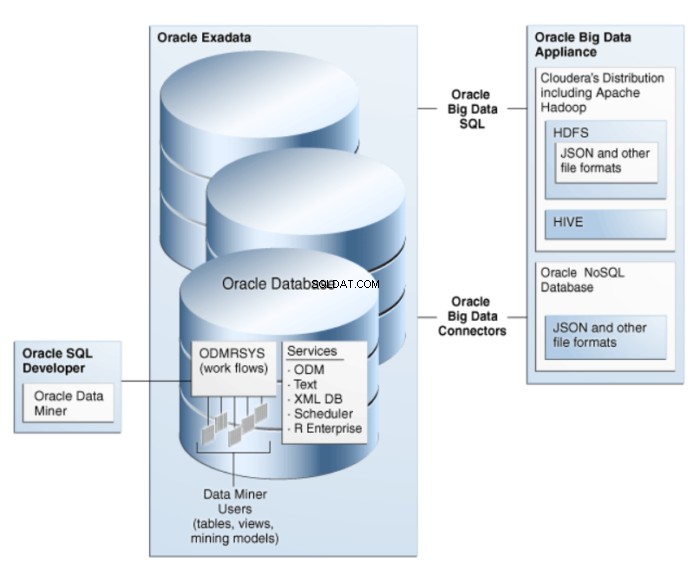
Figura 1:Architettura di Oracle Data Mining per Big Data
Gli algoritmi sono implementati come funzioni SQL e sfruttano i punti di forza di Oracle Database. Le funzioni di data mining SQL possono estrarre dati transazionali, aggregazioni, dati non strutturati, ad esempio tipo di dati CLOB (utilizzando Oracle Text) e dati spaziali.
Ogni funzione di data mining specifica una classe di problemi che possono essere modellati e risolti. Le funzioni di data mining rientrano generalmente in due categorie:supervisionate e non supervisionate.
Le nozioni di apprendimento supervisionato e non supervisionato derivano dalla scienza dell'apprendimento automatico, che è stata definita una sottoarea dell'intelligenza artificiale.
L'apprendimento supervisionato è anche noto come apprendimento diretto. Il processo di apprendimento è diretto da un attributo o obiettivo dipendente precedentemente noto. Il data mining diretto tenta di spiegare il comportamento del target in funzione di un insieme di attributi o predittori indipendenti.
L'apprendimento senza supervisione non è diretto. Non c'è distinzione tra attributi dipendenti e indipendenti. Non esiste alcun risultato noto in precedenza per guidare l'algoritmo nella creazione del modello. L'apprendimento non supervisionato può essere utilizzato per scopi descrittivi.
Algoritmi supervisionati di Oracle Data Mining
| Tecnica | Applicabilità | Algoritmi (breve descrizione) |
|---|---|---|
Classificazione | Tecnica più comunemente utilizzata per prevedere un esito specifico, ad esempio l'identificazione delle cellule tumorali del cancro, l'analisi del sentimento, la classificazione dei farmaci, il rilevamento dello spam. | Regressione logistica dei modelli lineari generalizzati - tecnica statistica classica disponibile all'interno del database Oracle in un'implementazione paralizzata, scalabile e altamente performante (si applica a tutti gli algoritmi OAA ML). Supporta testo e dati transazionali (si applica a quasi tutti gli algoritmi OAA ML) Naive Bayes - Veloce, semplice, comunemente applicabile. Supporta Vector Machine - Algoritmo di apprendimento automatico, supporta il testo e dati ampi. Albero decisionale - Algoritmo ML popolare per l'interpretabilità. Fornisce "regole" leggibili dall'uomo. |
Regressione | Tecnica per prevedere un risultato numerico continuo come l'analisi dei dati astronomici, la generazione di approfondimenti sul comportamento dei consumatori, la redditività e altri fattori aziendali, il calcolo delle relazioni causali tra i parametri nei sistemi biologici. | Modelli lineari generalizzati Regressione multipla:tecnica statistica classica ma ora disponibile all'interno del database Oracle come implementazione paralizzata, scalabile e altamente performante. Supporta la regressione della cresta, la creazione di funzionalità e la selezione delle funzionalità. Supporta testo e dati transazionali. Supporta Vector Machine - Algoritmo di apprendimento automatico, supporta testo e dati wide. |
Importanza attributo | Classifica gli attributi in base alla forza della relazione con l'attributo target. I casi d'uso includono la ricerca dei fattori più associati ai clienti che rispondono a un'offerta, i fattori più associati ai pazienti sani. | Lunghezza minima della descrizione:considera ogni attributo come un semplice modello predittivo della classe target e fornisce un'influenza relativa. |
Algoritmi non supervisionati di Oracle Data Mining
| Tecnica | Applicabilità | Algoritmi |
|---|---|---|
Raggruppamento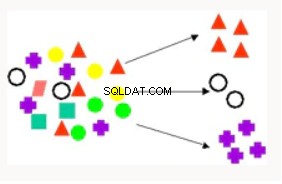 | Il clustering viene utilizzato per partizionare i record di un database in sottoinsiemi o cluster in cui gli elementi in un cluster condividono un insieme di proprietà comuni. Gli esempi includono la ricerca di nuovi segmenti di clienti e i consigli sui film. | Mezzi K:supporta l'estrazione di testo, il clustering gerarchico, basato sulla distanza. Gruppo di partizioni ortogonali:il clustering gerarchico, basato sulla densità. Massimizzazione delle aspettative:tecnica di clustering che funziona bene nei problemi di data mining di dati misti (densi e sparsi). |
Rilevamento di anomalie | Il rilevamento delle anomalie identifica punti dati, eventi e/o osservazioni che si discostano dal comportamento normale di un set di dati. Esempi comuni includono frode bancaria, un difetto strutturale, problemi medici o errori in un testo | Macchina vettoriale di supporto di una classe:esegue il training dei dati senza tag e tenta di determinare se un punto di test appartiene alla distribuzione dei dati di addestramento. |
Selezione ed estrazione delle funzioni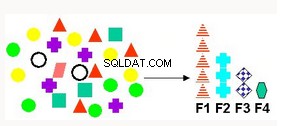 | Produce nuovi attributi come combinazione lineare di attributi esistenti. Applicabile per dati di testo, analisi semantica latente (LSA), compressione dei dati, scomposizione e proiezione dei dati e riconoscimento di modelli. | Fattorizzazione della matrice non negativa:mappa i dati originali nel nuovo set di attributi Principal Components Analysis (PCA):crea nuovi attributi compositi che rappresentano tutti i attributi. Decomposizione vettoriale singola:metodo consolidato di estrazione delle caratteristiche che ha un'ampia gamma di applicazioni. |
Associazione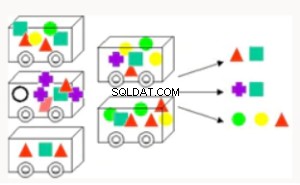 | Trova le regole associate agli articoli che si trovano frequentemente in concomitanza, utilizzate per l'analisi del paniere di mercato, il cross-sell e l'analisi della causa principale. Utile per il raggruppamento di prodotti e l'analisi dei difetti. | Apriori - Ha eseguito l'hashing di un albero per raccogliere informazioni in un database |
Abilitazione dell'opzione Oracle Data Mining
Da 12c Release 2, Oracle Advanced Analytics L'opzione include funzionalità di Data Mining e Oracle R.
L'opzione Oracle Advanced Analytics è abilitata per impostazione predefinita durante l'installazione di Oracle Database Enterprise Edition. Se desideri abilitare o disabilitare un'opzione del database, puoi utilizzare l'utilità della riga di comando chopt .
chopt [ enable | disable ] oaa
Per abilitare l'opzione Oracle Advanced Analytics:
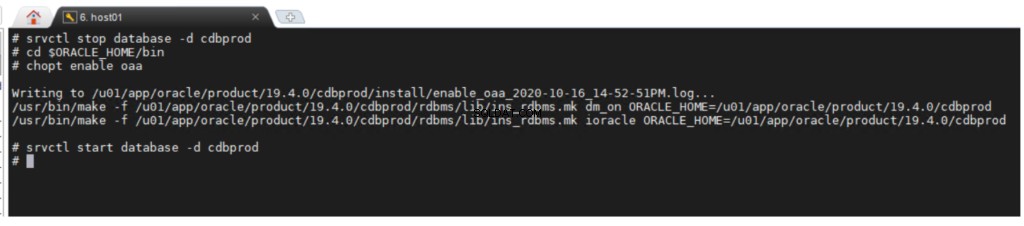
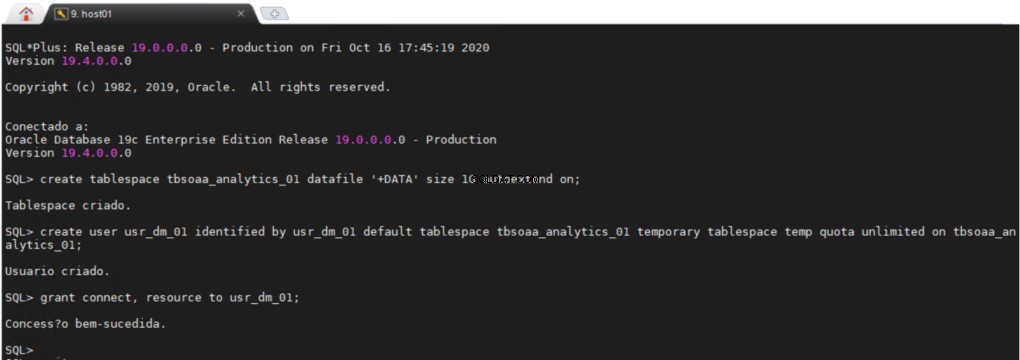
Creazione del tablespace di uno schema ODM
Tutti gli utenti richiedono uno spazio tabella permanente e uno spazio tabella temporaneo in cui svolgere il proprio lavoro, può essere molto utile avere un'area separata nel database in cui è possibile creare tutti i tuoi oggetti di data mining.
Il usr_dm_01 schema conterrà tutti i tuoi lavori di data mining.
Creazione del repository ODM
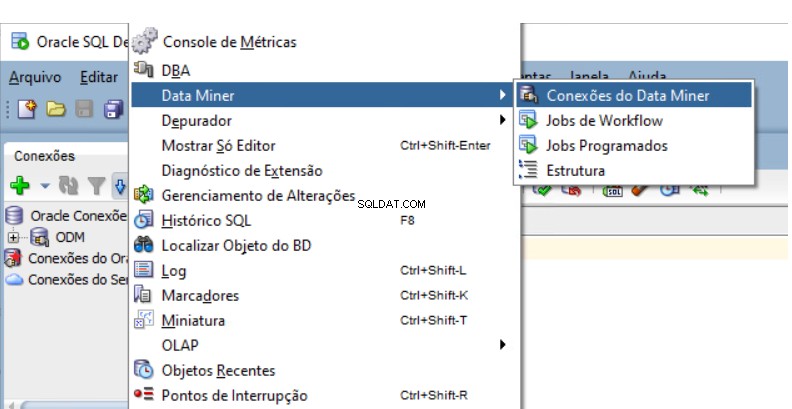
Devi creare un Repository di Oracle Data Mining nella banca dati. Vai a Data Miner Navigator in SQL Developer.
Seleziona Visualizza -> Data Miner -> Connessioni Data Miner:
Si apre una nuova scheda accanto alla scheda Connessioni esistente:
Per aggiungere usr_dm_01 schema a questo elenco, fare clic sulle finestre più verdi e OK
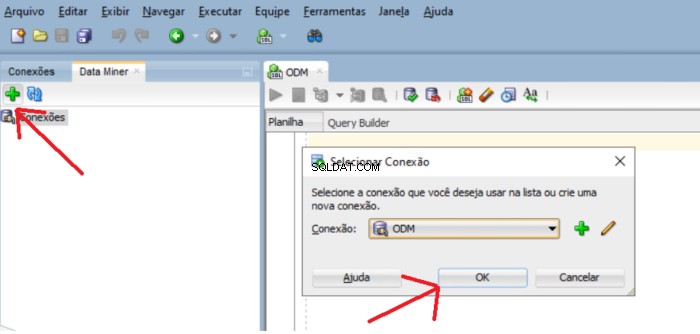
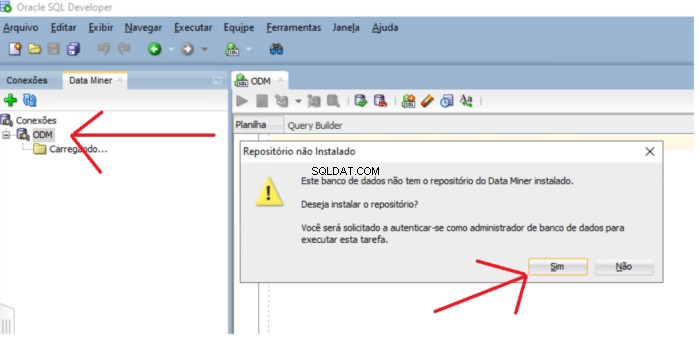
Se il repository non esiste, viene visualizzato un messaggio che chiede se si desidera installare il repository. Fai clic su Sì pulsante per procedere con l'installazione.
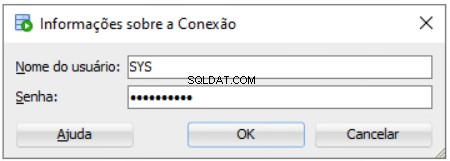
Devi inserire la password SYS
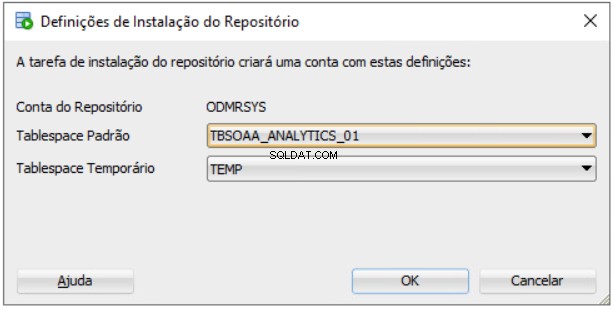
Impostazioni di installazione del repository
Installa la finestra di avanzamento del repository di Data Miner
Attività completata con successo
File di registro
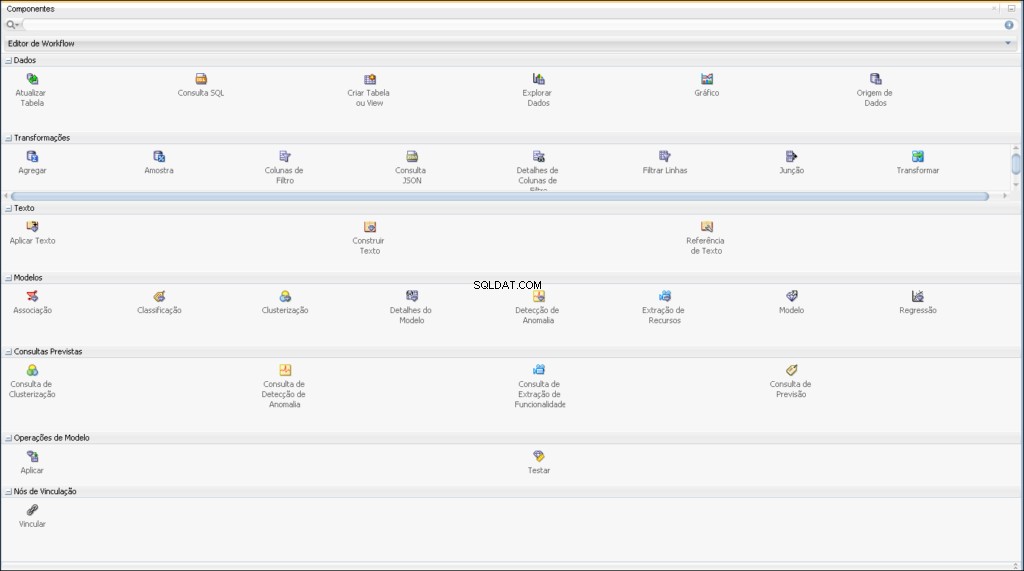
Componenti di Oracle Data Mining
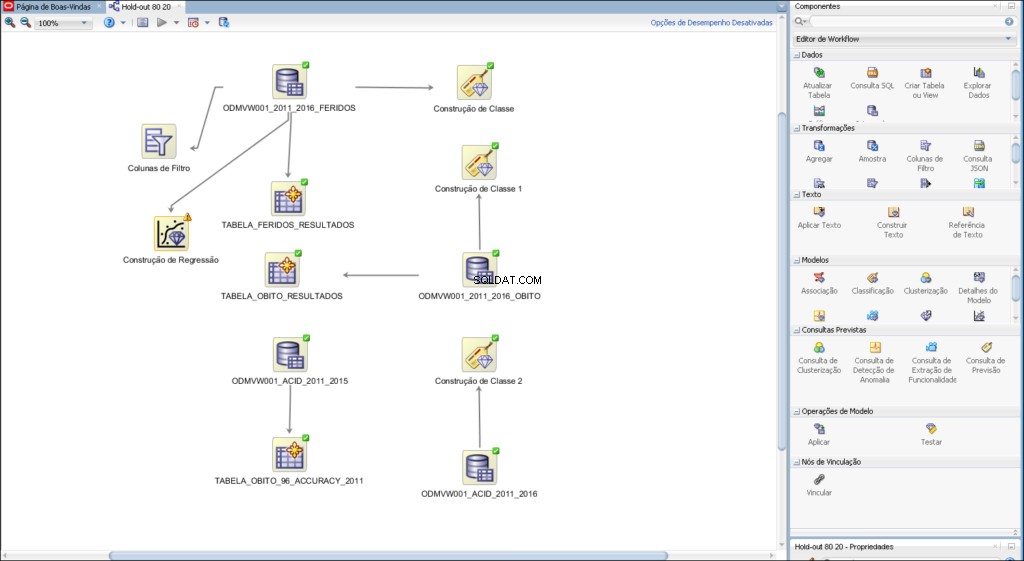
Il flusso di lavoro ti consente di costruire una serie di nodi che eseguono tutte le elaborazioni richieste sui tuoi dati.
Esempio di flusso di lavoro sviluppato per l'analisi predittiva
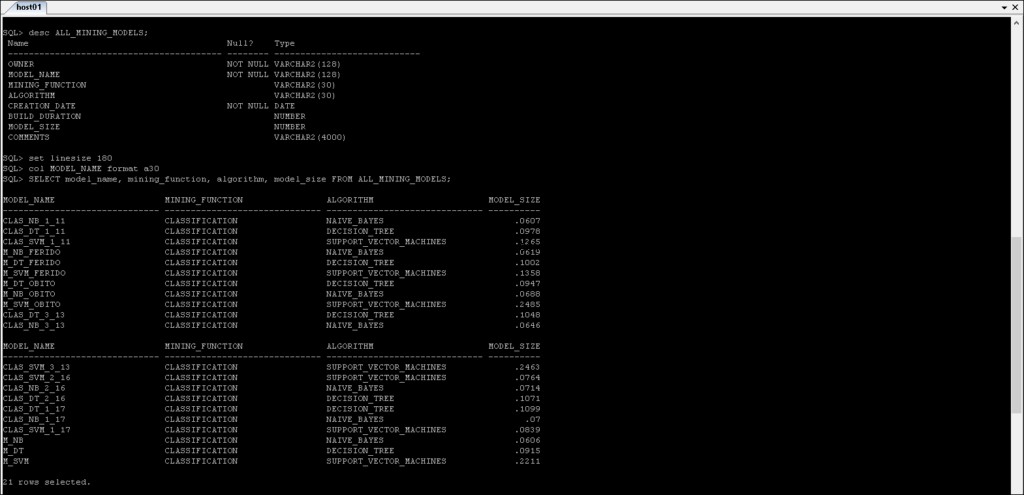
Viste del dizionario dei dati ODM
Puoi ottenere informazioni sui modelli di mining dal dizionario dei dati.
Le visualizzazioni del dizionario dei dati di Data Mining sono riepilogate come segue:
Nota:* può essere sostituito da ALL_, USER_, DBA_ e CDB_
*_MINING_MODELS :informazioni sui modelli di mining che sono stati creati.
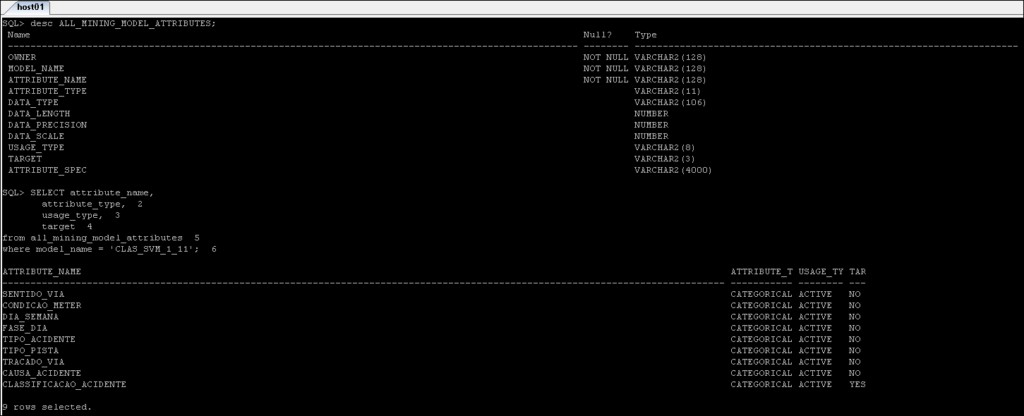
*_MINING_MODEL_ATTRIBUTES :contiene i dettagli degli attributi che sono stati utilizzati per creare il modello Oracle Data Mining.
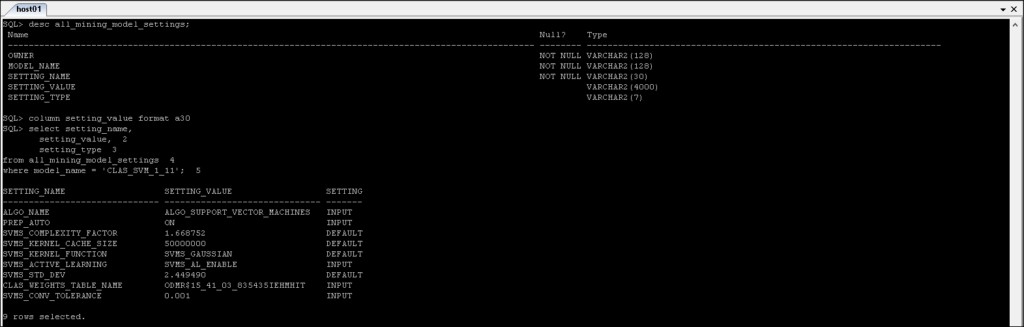
*_MINING_MODEL_SETTINGS :restituisce informazioni sulle impostazioni per i modelli di mining a cui hai accesso.
Riferimenti
Guida per l'utente di Oracle Data Mining. Disponibile su:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining:analisi predittiva scalabile all'interno del database. Disponibile su:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Panoramica del sistema Oracle Data Miner. Disponibile su:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124