Nella parte precedente di questo articolo, abbiamo discusso come importare file CSV in SQL Server con l'aiuto dell'istruzione BULK INSERT. Abbiamo discusso la metodologia principale del processo di inserimento in blocco e anche i dettagli delle opzioni BATCHSIZE e MAXERRORS negli scenari. In questa parte, esamineremo alcune altre opzioni (FIRE_TRIGGERS, CHECK_CONSTRAINTS e TABLOCK) del processo di inserimento in blocco in vari scenari.
Scenario 1:possiamo abilitare i trigger nella tabella di destinazione durante l'operazione di inserimento in blocco?
Per impostazione predefinita, durante il processo di inserimento in blocco, i trigger di inserimento specificati nella tabella di destinazione non vengono attivati, tuttavia, in alcune situazioni potremmo voler abilitare questi trigger. Una soluzione a questo problema consiste nell'utilizzare l'opzione FIRE_TRIGGERS nelle istruzioni di inserimento in blocco. Voglio aggiungere un avviso che questa opzione può influenzare e ridurre le prestazioni dell'operazione di inserimento in blocco perché trigger/trigger possono eseguire operazioni separate nel database. Nel seguente esempio lo dimostreremo. Inizialmente, non imposteremo il parametro FIRE_TRIGGERS e il processo di inserimento in blocco non attiverà il trigger di inserimento. Nel seguente script T-SQL, definiremo un trigger di inserimento per la tabella Sales.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Regione] [varchar](50) , [Paese] [varchar](50) , [ItemType] [varchar](50) NULL, [ SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float) DROP TABLE IF EXISTS SalesLogCREATE TABLE SalesLog (OrderIDLog bigint)GOCREATE TRIGGER OrderLogIns ON SalesFOR INSERTASBEGIN SET NOCOUNT ON INSERT INTO SalesLogSELECT OrderId da insertendGOBULK INSERT SalesDA 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n' ); SELEZIONA Conte (*) DA SalesLog
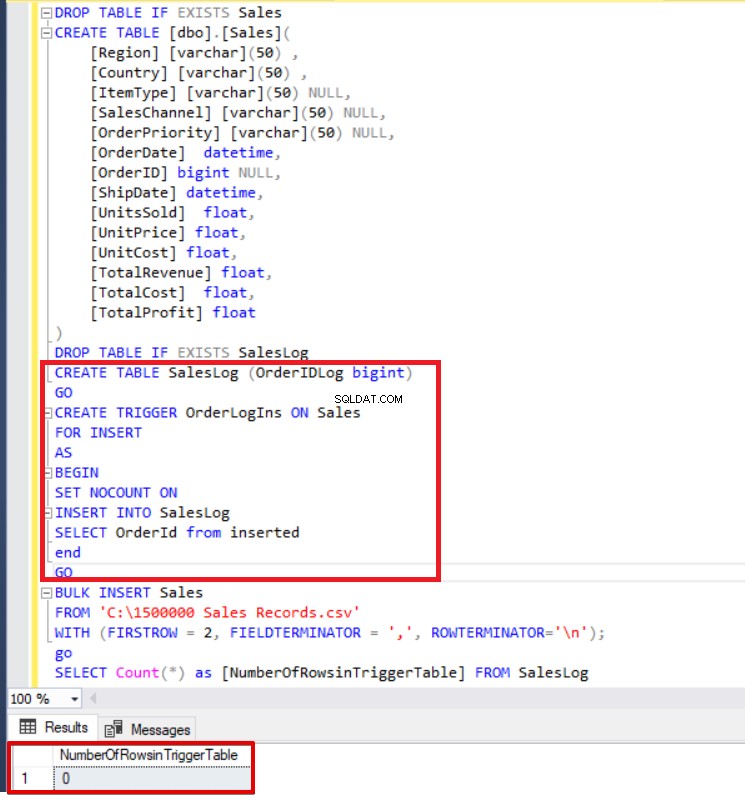
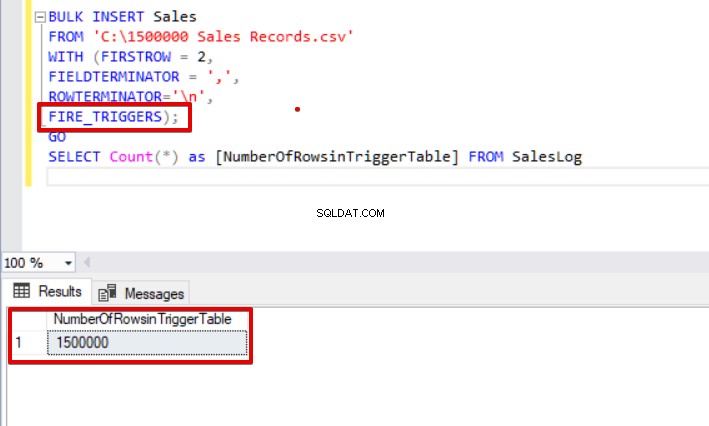
Come puoi vedere sopra, il trigger di inserimento non si è attivato perché non abbiamo impostato l'opzione FIRE_TRIGGERS. Ora aggiungeremo l'opzione FIRE_TRIGGERS all'istruzione di inserimento collettivo in modo che questa opzione consenta di inserire un trigger di incendio.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n',FIRE_TRIGGERS);GOSELECT Conte (*) come [NumberOfRowsinTriggerTable] FROM SalesLog
Scenario 2:come è possibile abilitare un vincolo di controllo durante l'operazione di inserimento in blocco?
I vincoli di controllo ci consentono di imporre l'integrità dei dati nelle tabelle di SQL Server. Lo scopo del vincolo è controllare i valori inseriti, aggiornati o cancellati secondo la loro regolazione sintattica. Ad esempio, il vincolo NOT NULL prevede che una colonna specificata non possa essere modificata dal valore NULL. Ora ci concentreremo sui vincoli e sull'interazione di inserimento in blocco. Per impostazione predefinita, durante il processo di inserimento in blocco qualsiasi controllo e vincolo di chiave esterna vengono ignorati, ma questa opzione presenta alcune eccezioni. Secondo la documentazione Microsoft “I vincoli UNIQUE e PRIMARY KEY sono sempre applicati. Durante l'importazione in una colonna di caratteri per la quale è definito il vincolo NOT NULL, BULK INSERT inserisce una stringa vuota quando non è presente alcun valore nel file di testo." Nel seguente script T-SQL, aggiungeremo un vincolo di controllo alla colonna OrderDate che controlla la data dell'ordine maggiore di 01.01.2016.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Regione] [varchar](50) , [Paese] [varchar](50) , [ItemType] [varchar](50) NULL, [ SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float) ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_CheckCHECK(OrderDate>'20160101')BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2 , FIELDTERMINATOR =',', ROWTERMINATOR='\n' );GOSELECT COUNT(*) AS [UnChekedData] FROM Sales WHERE OrderDate <'20160101'
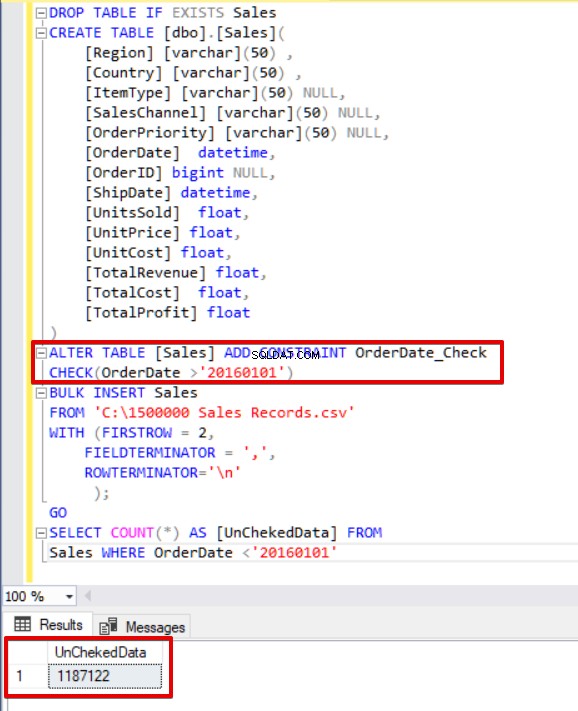
Come puoi vedere nell'esempio precedente, il processo di inserimento in blocco salta il controllo del vincolo di controllo. Tuttavia, SQL Server indica il vincolo di controllo come non attendibile.
SELECT is_not_trusted ,* FROM sys.check_constraints dove name='OrderDate_Check'
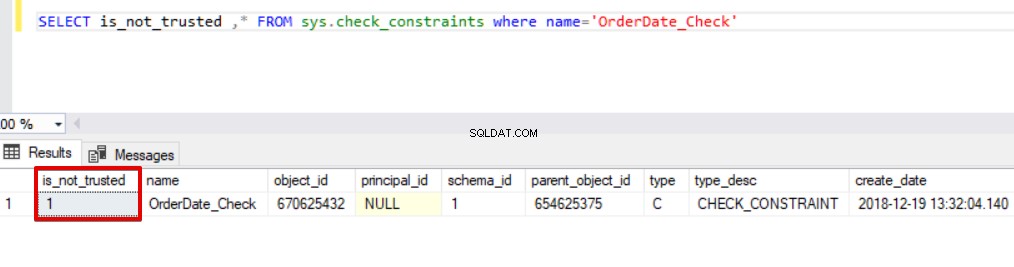
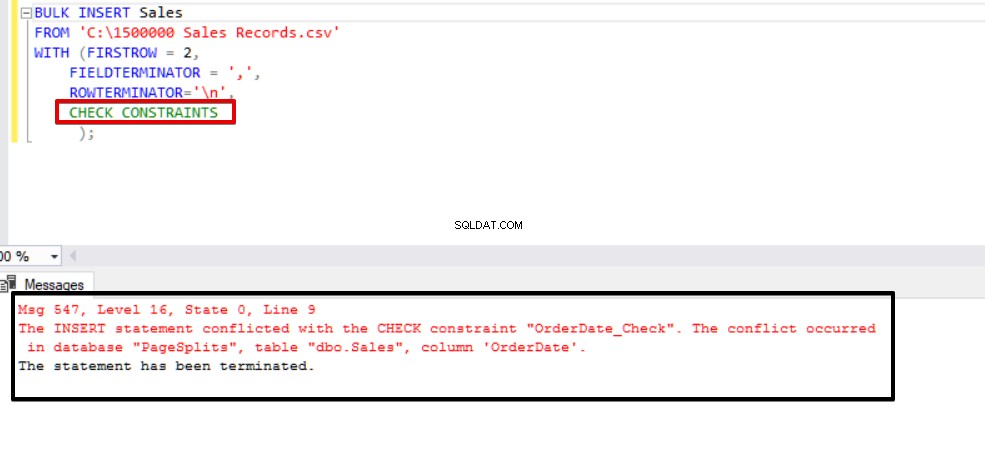
Questo valore indica che qualcuno ha inserito o aggiornato alcuni dati in questa colonna ignorando il vincolo di controllo, allo stesso tempo questa colonna potrebbe contenere dati incoerenti rispetto a quel vincolo. Ora proveremo ad eseguire l'istruzione di inserimento in blocco con l'opzione CHECK_CONSTRAINTS. Il risultato è molto semplice, il controllo del vincolo restituisce un errore a causa di dati non corretti.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n' );
Scenario 3:come aumentare le prestazioni in più inserimenti in blocco in una tabella di destinazione?
Lo scopo principale del meccanismo di blocco in SQL Server è proteggere e garantire l'integrità dei dati. Nell'articolo Concetto principale del blocco di SQL Server è possibile trovare dettagli sul meccanismo di blocco. Ora ci concentreremo sui dettagli di blocco del processo di inserimento in blocco. Se si esegue l'istruzione di inserimento in blocco senza l'opzione TABLELOCK, acquisisce il blocco delle righe o della tabella in base alla gerarchia dei blocchi. Tuttavia, in alcuni casi, potremmo voler eseguire più processi di inserimento in blocco su una tabella di destinazione, in modo da poter ridurre il tempo di operazione dell'inserimento in blocco. Inizialmente, eseguiremo due istruzioni di inserimento in blocco contemporaneamente e analizzeremo il comportamento del meccanismo di blocco. Apriremo due finestre di query in SQL Server Management Studio ed eseguiremo contemporaneamente le seguenti istruzioni di inserimento in blocco.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n' );
Quando eseguiamo la seguente query dmv (Dynamic Management View), che aiuta a monitorare lo stato del processo di inserimento in blocco.
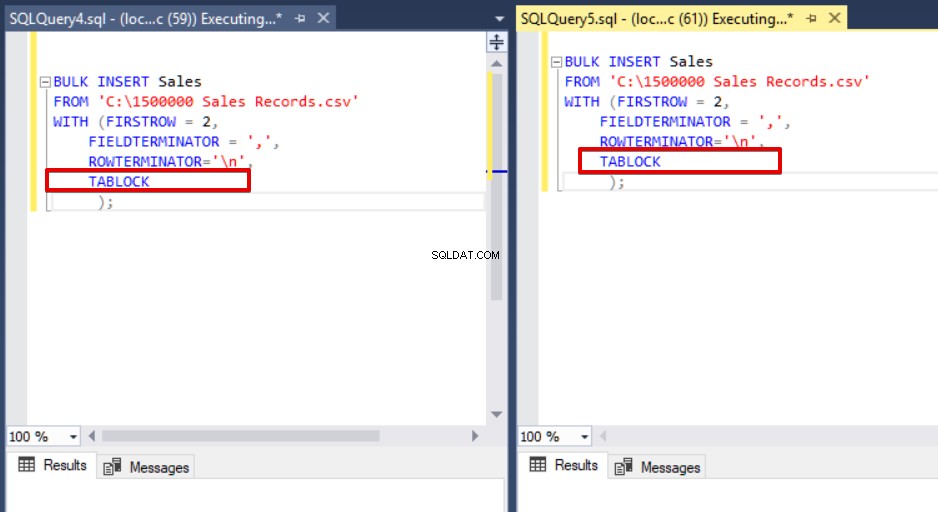
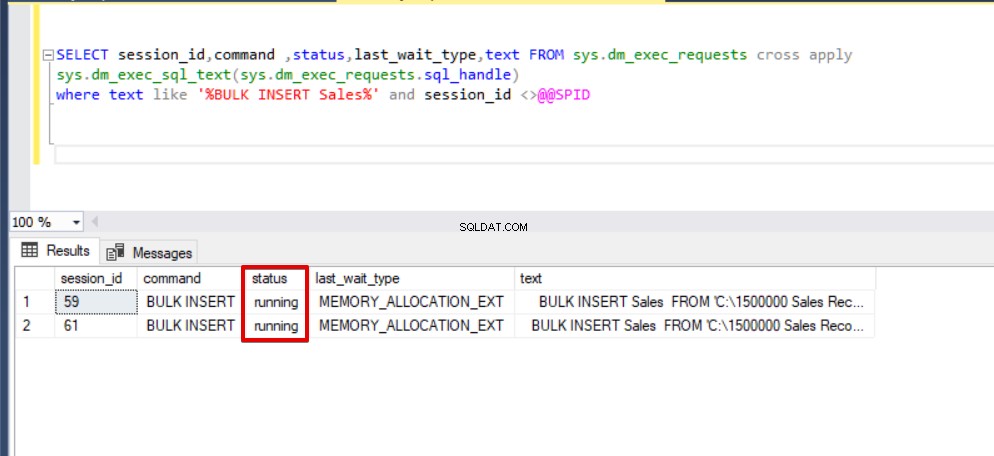
SELECT session_id,command,status,last_wait_type,text FROM sys.dm_exec_requests cross apply sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle) dove testo come '%BULK INSERT Sales%' e session_id <>@@SPID
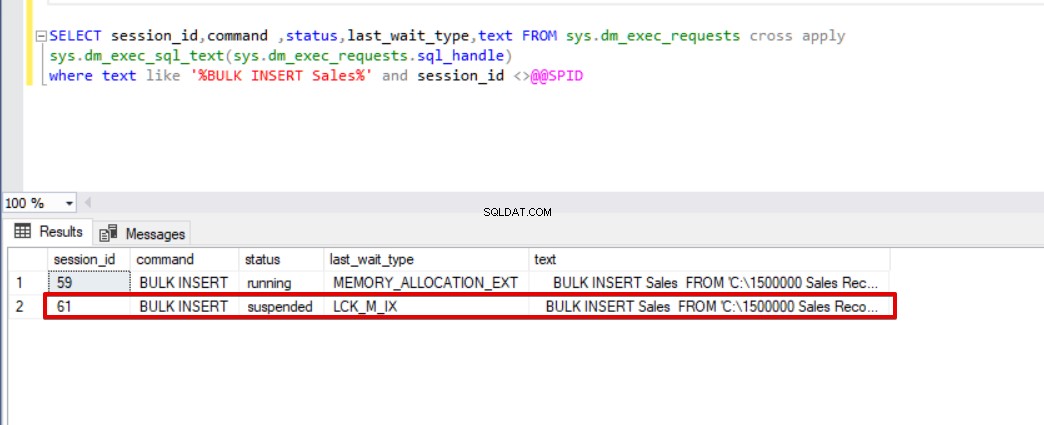
Come puoi vedere nell'immagine sopra, sessione 61, lo stato del processo di inserimento in blocco è sospeso a causa del blocco. Se verifichiamo il problema, la sessione 59 blocca la tabella di destinazione dell'inserimento in blocco e la sessione 61 attende il rilascio di questo blocco per continuare il processo di inserimento in blocco. Ora aggiungeremo l'opzione TABLOCK alle istruzioni di inserimento collettivo ed eseguiremo le query.
Quando eseguiamo nuovamente la query di monitoraggio dmv, non possiamo vedere alcun processo di inserimento in blocco sospeso perché SQL Server utilizza un tipo di blocco speciale chiamato blocco dell'aggiornamento in blocco (BU). Questo tipo di blocco consente di elaborare più operazioni di inserimento in blocco contemporaneamente sulla stessa tabella e questa opzione riduce anche il tempo totale del processo di inserimento in blocco.
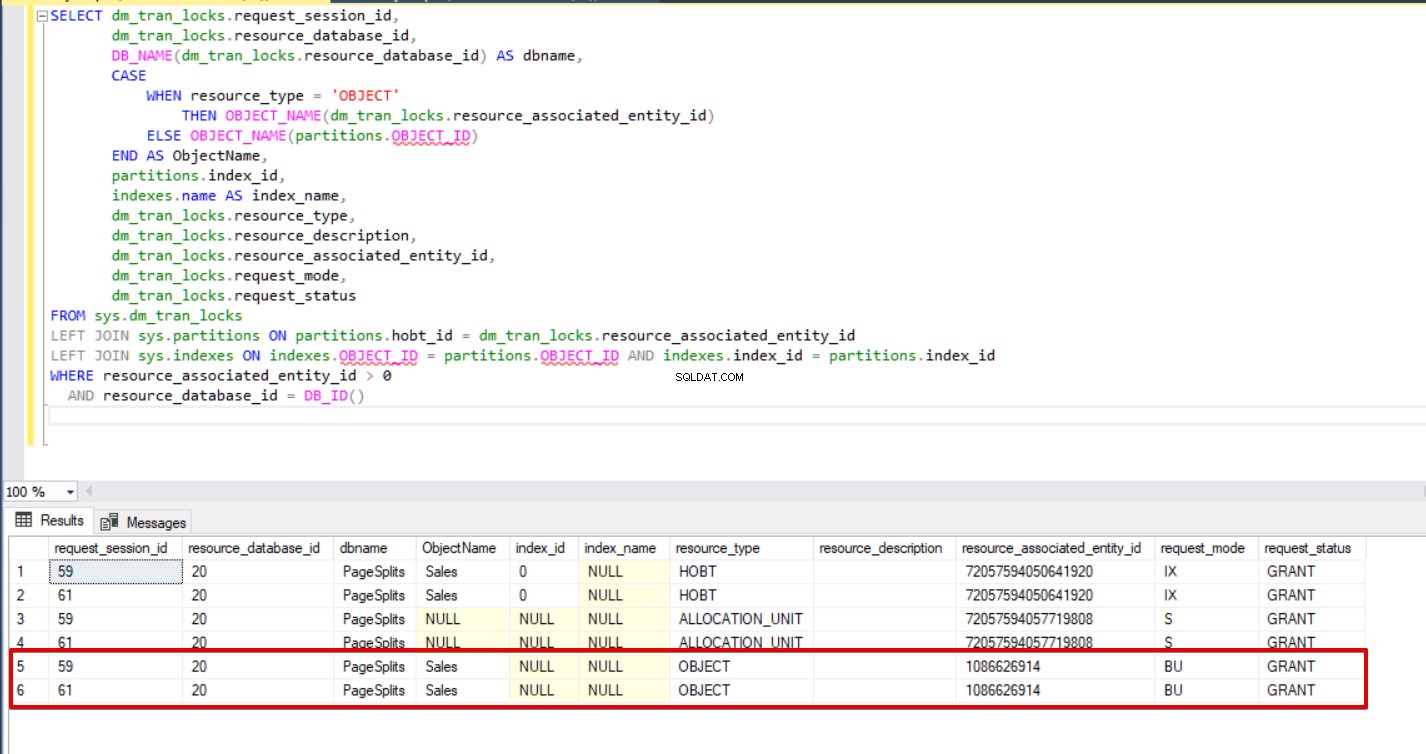
Quando eseguiamo la seguente query durante il processo di inserimento in blocco, possiamo monitorare i dettagli di blocco e i tipi di blocco.
END indexes.name AS index_name, dm_tran_locks.resource_type, dm_tran_locks.resource_description, dm_tran_locks.resource_associated_entity_id, dm_tran_locks.request_mode, dm_tran_locks.request_statusFROM sys.dm_tran_locksLEFT JOIN sys.partitions ON partitions.hobt_id =dm_tran_locks.resource_associated_entity_idLEFT JOIN sys.indexes ON indexes.OBJECT_ID =partitions .OBJECT_ID AND indexes.index_id =partitions.index_idWHERE Resource_associated_entity_id> 0 AND Resource_database_id =DB_ID()
Conclusione
In questo articolo sono stati esaminati tutti i dettagli dell'operazione di inserimento in blocco in SQL Server. In particolare, abbiamo menzionato il comando BULK INSERT e le sue impostazioni e opzioni, e abbiamo anche analizzato vari scenari che sono vicini ai problemi della vita reale.
Riferimenti
INSERTO BULK (Transact-SQL)
Prerequisiti per la registrazione minima nell'importazione in blocco
Controllo del comportamento di blocco per l'importazione in blocco
Ulteriori letture
Esportazione di dati in file flat con l'utilità BCP e importazione di dati con inserimento collettivo
Strumento utile:
dbForge Data Pump:un componente aggiuntivo SSMS per il riempimento di database SQL con dati di origine esterni e la migrazione dei dati tra i sistemi.