TeamCity è un server di integrazione continua e consegna continua costruito in Java. È disponibile come servizio cloud e in locale. Come puoi immaginare, l'integrazione continua e gli strumenti di distribuzione sono fondamentali per lo sviluppo del software e la loro disponibilità non deve essere influenzata. Fortunatamente, TeamCity può essere distribuito in una modalità ad alta disponibilità.
Questo post del blog tratterà la preparazione e la distribuzione di un ambiente a disponibilità elevata per TeamCity.
L'ambiente
TeamCity è composto da diversi elementi. C'è un'applicazione Java e un database che ne esegue il backup. Utilizza anche agenti che comunicano con l'istanza TeamCity principale. La distribuzione ad alta disponibilità consiste in diverse istanze di TeamCity, in cui una funge da primaria e le altre secondarie. Tali istanze condividono l'accesso allo stesso database e alla directory dei dati. Uno schema utile è disponibile nella pagina della documentazione di TeamCity, come mostrato di seguito:

Come possiamo vedere, ci sono due elementi condivisi: la directory dei dati e la banca dati. Dobbiamo garantire che anche quelli siano altamente disponibili. Esistono diverse opzioni che puoi utilizzare per creare una cavalcatura condivisa; tuttavia, utilizzeremo GlusterFS. Per quanto riguarda il database, utilizzeremo uno dei sistemi di gestione dei database relazionali supportati, PostgreSQL, e utilizzeremo ClusterControl per creare uno stack ad alta disponibilità basato su di esso.
Come configurare GlusterFS
Iniziamo dalle basi. Vogliamo configurare nomi host e /etc/hosts sui nostri nodi TeamCity, dove implementeremo anche GlusterFS. Per farlo, abbiamo bisogno di configurare il repository per gli ultimi pacchetti di GlusterFS su tutti loro:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updatePoi possiamo installare GlusterFS su tutti i nostri nodi TeamCity:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS utilizza la porta 24007 per la connettività tra i nodi; dobbiamo assicurarci che sia aperto e accessibile da tutti i nodi.
Una volta stabilita la connettività, possiamo creare un cluster GlusterFS eseguendo da un nodo:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Ora possiamo testare l'aspetto dello stato:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Sembra tutto a posto e la connettività è a posto.
Successivamente, dovremmo preparare un dispositivo a blocchi da utilizzare da GlusterFS. Questo deve essere eseguito su tutti i nodi. Innanzitutto, crea una partizione:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Quindi, formatta quella partizione:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Infine, su tutti i nodi, dobbiamo creare una directory che verrà utilizzata per montare la partizione e modificare fstab per assicurarci che venga montata all'avvio:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabVerifichiamo ora che funzioni:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Ora possiamo usare uno dei nodi per creare e avviare il volume GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successSi prega di notare che utilizziamo il valore di '3' per il numero di repliche. Significa che ogni volume esisterà in tre copie. Nel nostro caso, ogni mattone, ogni volume /dev/sdb1 su tutti i nodi conterrà tutti i dati.
Una volta avviati i volumi, possiamo verificarne lo stato:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksCome puoi vedere, sembra tutto a posto. L'importante è che GlusterFS abbia scelto la porta 49152 per accedere a quel volume e dobbiamo assicurarci che sia raggiungibile su tutti i nodi in cui lo monteremo.
Il prossimo passo sarà installare il pacchetto client GlusterFS. Per questo esempio, è necessario che sia installato negli stessi nodi del server GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Successivamente, dobbiamo creare una directory su tutti i nodi da utilizzare come directory di dati condivisa per TeamCity. Questo deve avvenire su tutti i nodi:
example@sqldat.com:~# sudo mkdir /teamcity-storageInfine, monta il volume GlusterFS su tutti i nodi:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageQuesto completa i preparativi per l'archiviazione condivisa.
Costruzione di un cluster PostgreSQL ad alta disponibilità
Una volta completata la configurazione dell'archiviazione condivisa per TeamCity, ora possiamo costruire la nostra infrastruttura di database ad alta disponibilità. TeamCity può utilizzare diversi database; tuttavia, utilizzeremo PostgreSQL in questo blog. Sfrutteremo ClusterControl per distribuire e quindi gestire l'ambiente del database.
La guida di TeamCity alla creazione di un'implementazione multi-nodo è utile, ma sembra tralasciare l'elevata disponibilità di tutto ciò che non è TeamCity. La guida di TeamCity suggerisce un server NFS o SMB per l'archiviazione dei dati, che, di per sé, non ha ridondanza e diventerà un singolo punto di errore. Abbiamo affrontato questo problema utilizzando GlusterFS. Citano un database condiviso, poiché un singolo nodo di database ovviamente non fornisce un'elevata disponibilità. Dobbiamo costruire uno stack adeguato:

Nel nostro caso. sarà composto da tre nodi PostgreSQL, uno primario e due repliche. Utilizzeremo HAProxy come bilanciatore del carico e useremo Keepalived per gestire l'IP virtuale per fornire un singolo endpoint a cui l'applicazione può connettersi. ClusterControl gestirà gli errori monitorando la topologia di replica ed eseguendo qualsiasi ripristino richiesto secondo necessità, ad esempio riavviando i processi non riusciti o effettuando il failover su una delle repliche se il nodo primario si interrompe.
Per iniziare, distribuiremo i nodi del database. Tenere presente che ClusterControl richiede la connettività SSH dal nodo ClusterControl a tutti i nodi che gestisce.

Quindi, scegliamo un utente che useremo per connetterci al database, la sua password e la versione di PostgreSQL da distribuire:

Successivamente, definiremo quali nodi utilizzare per la distribuzione di PostgreSQL :
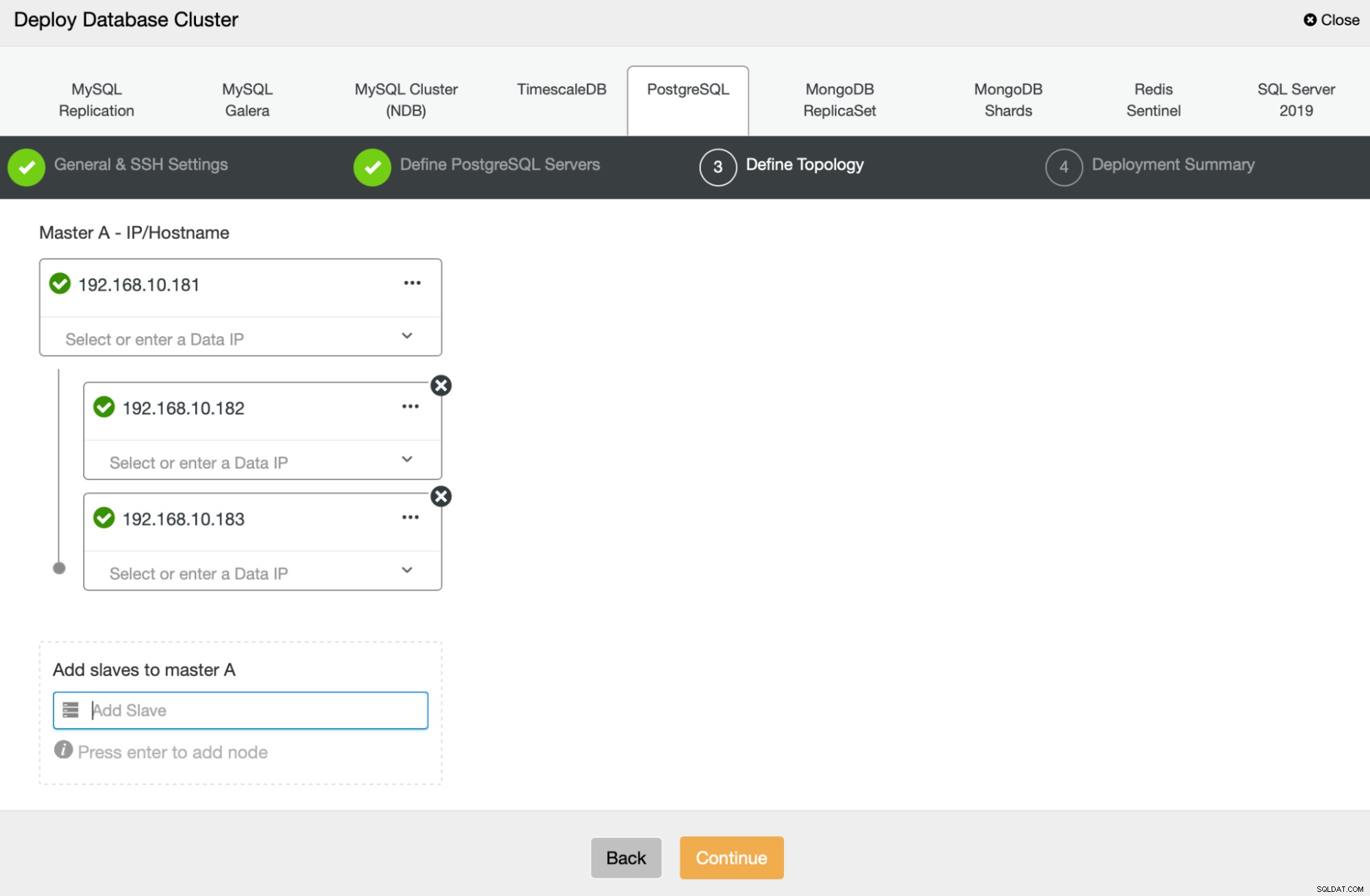
Infine, possiamo definire se i nodi devono utilizzare la replica asincrona o sincrona. La principale differenza tra questi due è che la replica sincrona garantisce che ogni transazione eseguita sul nodo primario venga sempre replicata sulle repliche. Tuttavia, anche la replica sincrona rallenta il commit. Ti consigliamo di abilitare la replica sincrona per la migliore durabilità, ma dovresti verificare in seguito se le prestazioni sono accettabili.

Dopo aver fatto clic su "Distribuisci", verrà avviato un processo di distribuzione. Possiamo monitorarne l'andamento nella scheda Attività nell'interfaccia utente di ClusterControl. Alla fine dovremmo vedere che il lavoro è stato completato e il cluster è stato distribuito correttamente.

Distribuisci le istanze HAProxy andando su Gestisci -> Bilanciatori di carico. Seleziona HAProxy come bilanciatore del carico e compila il modulo. La scelta più importante è dove vuoi distribuire HAProxy. In questo caso è stato utilizzato un nodo di database, ma in un ambiente di produzione è molto probabile che tu voglia separare i servizi di bilanciamento del carico dalle istanze del database. Quindi, seleziona quali nodi PostgreSQL includere in HAProxy. Li vogliamo tutti.

Ora inizierà la distribuzione di HAProxy. Vogliamo ripeterlo almeno un'altra volta per creare due istanze HAProxy per la ridondanza. In questa distribuzione, abbiamo deciso di utilizzare tre bilanciatori di carico HAProxy. Di seguito è riportato uno screenshot della schermata delle impostazioni durante la configurazione della distribuzione di un secondo HAProxy:
Quando tutte le nostre istanze HAProxy sono in esecuzione, possiamo distribuire Keepalived . L'idea qui è che Keepalived sarà collocato con HAProxy e monitorerà il processo di HAProxy. Una delle istanze con HAProxy funzionante avrà l'IP virtuale assegnato. Questo VIP dovrebbe essere utilizzato dall'applicazione per connettersi al database. Keepalived rileverà se tale HAProxy diventa non disponibile e si sposta su un'altra istanza HAProxy disponibile.
La procedura guidata di distribuzione ci richiede di passare le istanze HAProxy che vogliamo monitorare con Keepalived. Dobbiamo anche passare l'indirizzo IP e l'interfaccia di rete per VIP.

L'ultimo e ultimo passaggio sarà la creazione di un database per TeamCity:

Con questo abbiamo concluso l'implementazione del cluster PostgreSQL ad alta disponibilità.
Distribuzione di TeamCity come multinodo
Il passaggio successivo consiste nel distribuire TeamCity in un ambiente multi-nodo. Utilizzeremo tre nodi TeamCity. Innanzitutto, dobbiamo installare Java JRE e JDK che soddisfano i requisiti di TeamCity.
apt install default-jre default-jdkOra, su tutti i nodi, dobbiamo scaricare TeamCity. Installeremo in una directory locale, non condivisa.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzPoi possiamo avviare TeamCity su uno dei nodi:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logUna volta avviato TeamCity, possiamo accedere all'interfaccia utente e iniziare la distribuzione. Inizialmente, dobbiamo passare la posizione della directory dei dati. Questo è il volume condiviso che abbiamo creato su GlusterFS.

Quindi, scegli il database. Utilizzeremo un cluster PostgreSQL che abbiamo già creato.

Scarica e installa il driver JDBC:

Successivamente, inserisci i dettagli di accesso. Useremo l'IP virtuale fornito da Keepalived. Si noti che utilizziamo la porta 5433. Questa è la porta utilizzata per il backend di lettura/scrittura di HAProxy; punterà sempre verso il nodo primario attivo. Quindi, scegli un utente e il database da utilizzare con TeamCity.

Al termine, TeamCity inizierà a inizializzare la struttura del database.

Accetta il contratto di licenza:

Infine, crea un utente per TeamCity:

Ecco fatto! Ora dovremmo essere in grado di vedere la GUI di TeamCity:

Ora dobbiamo configurare TeamCity in modalità multi-nodo. Innanzitutto, dobbiamo modificare gli script di avvio su tutti i nodi:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shDobbiamo assicurarci che le seguenti due variabili siano esportate. Verifica di utilizzare il nome host, l'IP e le directory corretti per l'archiviazione locale e condivisa:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Una volta fatto, puoi avviare i nodi rimanenti:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startDovresti vedere il seguente output in Amministrazione -> Configurazione nodi:un nodo principale e due nodi standby.

Tieni presente che il failover in TeamCity non è automatizzato. Se il nodo principale smette di funzionare, dovresti connetterti a uno dei nodi secondari. Per fare ciò, vai su "Configurazione nodi" e promuovilo al nodo "Principale". Dalla schermata di accesso, vedrai una chiara indicazione che si tratta di un nodo secondario:

Nella "Configurazione nodi", vedrai che un nodo ha eliminato dal cluster:

Riceverai un messaggio che ti informa che non puoi scrivere su questo nodo. Non preoccuparti; la scrittura richiesta per promuovere questo nodo allo stato "principale" funzionerà perfettamente:

Fai clic su "Abilita" e abbiamo promosso con successo un nodo TimeCity secondario:

Quando node1 diventa disponibile e TeamCity viene riavviato su quel nodo, lo faremo guardalo rientrare nel cluster:

Se desideri migliorare ulteriormente le prestazioni, puoi distribuire HAProxy + Keepalived davanti all'interfaccia utente di TeamCity per fornire un unico punto di ingresso alla GUI. Puoi trovare i dettagli sulla configurazione di HAProxy per TeamCity nella documentazione.
Conclusione
Come puoi vedere, l'implementazione di TeamCity per l'alta disponibilità non è così difficile:la maggior parte è stata trattata in modo approfondito nella documentazione. Se stai cercando modi per automatizzare alcune di queste operazioni e aggiungere un back-end di database a disponibilità elevata, valuta la possibilità di valutare ClusterControl gratuitamente per 30 giorni. ClusterControl può distribuire e monitorare rapidamente il back-end, fornendo failover, ripristino, monitoraggio, gestione dei backup automatizzati e altro ancora.
Per ulteriori suggerimenti sugli strumenti di sviluppo software e sulle best practice, scopri come supportare il tuo team DevOps con le proprie esigenze di database.
Per ricevere le ultime notizie e le migliori pratiche per la gestione della tua infrastruttura di database open source, non dimenticare di seguirci su Twitter o LinkedIn e iscriverti alla nostra newsletter. A presto!