Uno dei numerosi miglioramenti del piano di esecuzione in SQL Server 2012 è stata l'aggiunta della prenotazione del thread e delle informazioni sull'utilizzo per i piani di esecuzione parallela. Questo post esamina esattamente il significato di questi numeri e fornisce ulteriori informazioni sulla comprensione dell'esecuzione parallela.
Considera la seguente query eseguita su una versione ingrandita del database AdventureWorks:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Query Optimizer sceglie un piano di esecuzione parallela:
Plan Explorer mostra i dettagli sull'utilizzo del thread parallelo nella descrizione comando del nodo radice. Per visualizzare le stesse informazioni in SSMS, fai clic sul nodo principale del piano, apri la finestra Proprietà ed espandi ThreadStat nodo. Utilizzando una macchina con otto processori logici disponibili per SQL Server, le informazioni sull'utilizzo del thread da un'esecuzione tipica di questa query sono mostrate di seguito, Plan Explorer a sinistra, vista SSMS a destra:
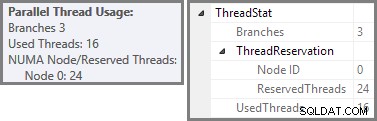
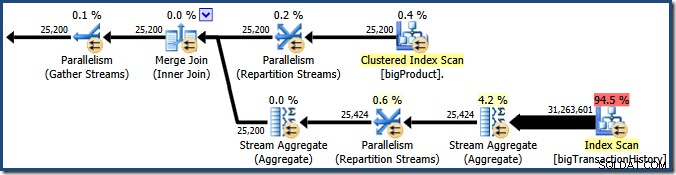
Lo screenshot mostra che il motore di esecuzione ha riservato 24 thread per questa query e ne ha usati 16. Mostra inoltre che il piano di query ha tre rami , anche se non dice esattamente cos'è un ramo. Se hai letto il mio articolo Simple Talk sull'esecuzione di query parallele, saprai che i rami sono sezioni di un piano di query parallele delimitate da operatori di scambio. Il diagramma seguente disegna i confini e numera i rami (clicca per ingrandire):

Ramo due (arancione)
Diamo prima un'occhiata al ramo due un po' più in dettaglio:
Con un grado di parallelismo (DOP) di otto, sono presenti otto thread che eseguono questo ramo del piano di query. È importante capire che questo è l'intero piano di esecuzione per quanto riguarda questi otto thread, non sono a conoscenza del piano più ampio.
In un piano di esecuzione seriale, un singolo thread legge i dati da un'origine dati, elabora le righe tramite una serie di operatori del piano e restituisce i risultati alla destinazione (che potrebbe essere una finestra dei risultati di una query SSMS o una tabella di database, ad esempio).
In una filiale di un piano di esecuzione parallela, la situazione è molto simile:ogni thread legge i dati da un'origine, elabora le righe tramite una serie di operatori del piano e restituisce i risultati alla destinazione. Le differenze sono che la destinazione è un operatore di scambio (parallelismo) e anche l'origine dati può essere uno scambio.
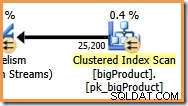
Nel ramo arancione, l'origine dati è una scansione dell'indice cluster e la destinazione è il lato destro di uno scambio di flussi di ripartizione. Il lato destro di uno scambio è noto come lato produttore , perché si collega a un ramo che aggiunge dati allo scambio.
Gli otto thread nel ramo arancione collaborano per eseguire la scansione della tabella e aggiungere righe allo scambio. Lo scambio assembla le righe in pacchetti di dimensioni pagina. Una volta che un pacchetto è pieno, viene spinto attraverso lo scambio all'altro lato. Se lo scambio ha un altro pacchetto vuoto disponibile da riempire, il processo continua fino a quando tutte le righe dell'origine dati non sono state elaborate (o lo scambio esaurisce i pacchetti vuoti).
Possiamo vedere il numero di righe elaborate su ciascun thread utilizzando la vista Plan Tree in Plan Explorer:
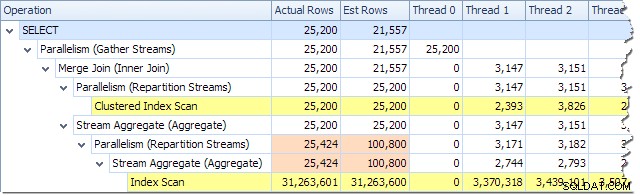
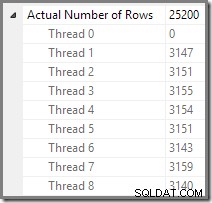
Plan Explorer rende facile vedere come le righe sono distribuite tra i thread per tutti le operazioni fisiche nel piano. In SSMS, sei limitato a vedere la distribuzione delle righe per un singolo operatore del piano. A tale scopo, fare clic sull'icona di un operatore, aprire la finestra Proprietà, quindi espandere il nodo Numero effettivo di righe. Il grafico seguente mostra le informazioni SSMS per il nodo Repartition Streams al confine tra i rami arancione e viola:
Ramo tre (verde)
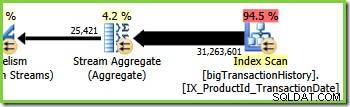
Il ramo tre è simile al ramo due, ma contiene un operatore Stream Aggregate aggiuntivo. Anche il ramo verde ha otto fili, per un totale di sedici visti finora. Gli otto thread del ramo verde leggono i dati da una scansione dell'indice non cluster, eseguono una sorta di aggregazione e passano i risultati al lato produttore di un altro scambio di Repartition Streams.
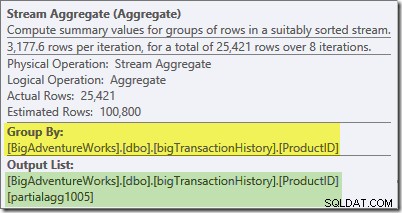
Il suggerimento di Plan Explorer per Stream Aggregate mostra che sta raggruppando per ID prodotto e calcolando un'espressione etichettata partialagg1005 :
La scheda Espressioni mostra che l'espressione è il risultato del conteggio delle righe in ciascun gruppo:

Lo Stream Aggregate sta calcolando un parziale (noto anche come 'locale') aggregato. Il qualificatore parziale (o locale) significa semplicemente che ogni thread calcola l'aggregato sulle righe che vede. Le righe della scansione dell'indice vengono distribuite tra i thread utilizzando uno schema basato sulla domanda:non esiste una distribuzione fissa delle righe in anticipo; i thread ricevono un intervallo di righe dalla scansione quando le richiedono. Quali righe finiscono su quali thread è essenzialmente casuale perché dipende da problemi di temporizzazione e altri fattori.
Ogni thread vede righe diverse dalla scansione, ma righe con lo stesso ID prodotto può essere visto da più di un thread. L'aggregato è "parziale" perché i totali parziali per un particolare gruppo di ID prodotto possono essere visualizzati su più thread; è "locale" perché ogni thread calcola il suo risultato in base solo alle righe che riceve. Ad esempio, supponiamo che nella tabella siano presenti 1.000 righe per l'ID prodotto n. Un thread potrebbe vedere 432 di quelle righe, mentre un altro potrebbe vederne 568. Entrambi i thread avranno un parziale conteggio delle righe per l'ID prodotto n. 1 (432 in un thread, 568 nell'altro).
L'aggregazione parziale è un'ottimizzazione delle prestazioni perché riduce il numero di righe prima di quanto sarebbe altrimenti possibile. Nel ramo verde, l'aggregazione anticipata fa sì che meno righe vengano assemblate in pacchetti e trasferite attraverso lo scambio Repartition Stream.
Ramo 1 (Viola)

Il ramo viola ha otto fili in più, ventiquattro finora. Ogni thread in questo ramo legge le righe dai due scambi Repartition Streams e scrive le righe in uno scambio Gather Streams. Questo ramo può sembrare complicato e poco familiare, ma sta solo leggendo righe da un'origine dati e inviando risultati a una destinazione, come qualsiasi altro piano di query.
Il lato destro del piano mostra i dati letti dall'altro lato dei due scambi Repartition Streams visti nei rami arancione e verde. Questo lato (a sinistra) dello scambio è noto come consumatore lato, perché i thread allegati qui stanno leggendo (consumando) righe. Gli otto fili viola sono consumatori di dati nei due scambi Repartition Streams.
Il lato sinistro del ramo viola mostra le righe scritte al produttore lato di uno scambio Gather Streams. Gli stessi otto thread (che sono consumatori negli scambi Repartition Streams) stanno eseguendo un produttore ruolo qui.
Ogni thread nel ramo viola esegue ogni operatore nel ramo, proprio come un singolo thread esegue ogni operazione in un piano di esecuzione seriale. La differenza principale è che ci sono otto thread in esecuzione contemporaneamente, ognuno dei quali lavora su una riga diversa in un dato momento, utilizzando istanze diverse degli operatori del piano di query.
Lo Stream Aggregate in questo ramo è globale aggregato. Combina gli aggregati parziali (locali) calcolati nel ramo verde (ricorda l'esempio di un conteggio 432 in un thread e 568 nell'altro) per produrre un totale combinato per ciascun ID prodotto. La descrizione comando di Plan Explorer mostra l'espressione del risultato globale, denominata Espr1004:
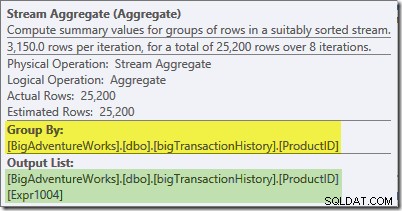
Il risultato globale corretto per ID prodotto viene calcolato sommando gli aggregati parziali, come illustrato nella scheda Espressioni:
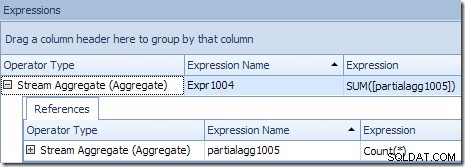
Per continuare il nostro esempio (immaginario), il risultato corretto di 1.000 righe per l'ID prodotto n. 1 si ottiene sommando i due subtotali di 432 e 568.
Ciascuno degli otto thread del ramo viola legge i dati dal lato consumer dei due scambi Gather Streams, calcola gli aggregati globali, esegue il Merge Join sull'ID prodotto e aggiunge righe allo scambio Gather Streams all'estrema sinistra del ramo viola. Il processo principale non è molto diverso da un normale piano seriale; le differenze sono nella posizione da cui vengono lette le righe, dove vengono inviate e come le righe vengono distribuite tra i thread...
Distribuzione delle righe di scambio
Il lettore attento si chiederà a questo punto un paio di dettagli. In che modo il ramo viola riesce a calcolare i risultati corretti per ID prodotto ma il ramo verde non potrebbe (i risultati per lo stesso ID prodotto sono stati distribuiti su più thread)? Inoltre, se sono presenti otto join di unione separati (uno per thread), in che modo SQL Server garantisce che le righe che si uniranno finiscano nella stessa istanza del join?
È possibile rispondere a entrambe queste domande osservando il modo in cui i due scambi Repartition Streams instradano le righe dal lato produttore (nei rami verde e arancione) al lato consumatore (nel ramo viola). Esamineremo prima lo scambio di Repartition Streams che confina con i rami arancione e viola:
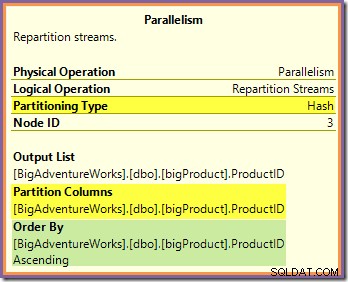
Questo scambio instrada le righe in entrata (dal ramo arancione) utilizzando una funzione hash applicata alla colonna ID prodotto. L'effetto è che tutte le righe per un determinato ID prodotto sono garantite da instradare allo stesso filo viola. I fili arancione e viola non sanno nulla di questo instradamento; tutto questo viene gestito internamente dallo scambio.
Tutti i thread arancioni sanno è che stanno restituendo le righe all'iteratore padre che le ha richieste (il lato produttore dello scambio). Allo stesso modo, tutti i thread viola "sanno" è che stanno leggendo righe da un'origine dati. Lo scambio determina in quale pacchetto andrà una riga di thread arancione in entrata e potrebbe essere uno qualsiasi degli otto pacchetti candidati. Allo stesso modo, lo scambio determina da quale pacchetto leggere una riga per soddisfare una richiesta di lettura da un thread viola.
Fai attenzione a non acquisire un'immagine mentale di un particolare filo arancione (produttore) collegato direttamente a un particolare filo viola (di consumo). Non è così che funziona questo piano di query. Un produttore di arance può finiscono per inviare righe a tutti i consumatori viola:l'instradamento dipende interamente dal valore della colonna ID prodotto in ogni riga che elabora.
Si noti inoltre che un pacchetto di righe allo scambio viene trasferito solo quando è pieno (o quando il lato produttore esaurisce i dati). Immagina lo scambio che riempie i pacchetti una riga alla volta, in cui le righe per un particolare pacchetto possono provenire da qualsiasi thread lato produttore (arancione). Una volta che un pacchetto è pieno, viene passato al lato consumer, dove un particolare thread consumer (viola) può iniziare a leggerlo.
Lo scambio di Repartition Streams che delimita i rami verde e viola funziona in modo molto simile:
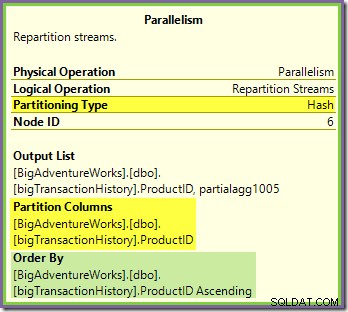
Le righe vengono instradate ai pacchetti in questo scambio utilizzando la stessa funzione hash nella stessa colonna di partizionamento come per lo scambio arancione-viola visto in precedenza. Ciò significa che entrambi Repartition Streams scambia le righe di route con lo stesso ID prodotto allo stesso thread viola.
Questo spiega come lo Stream Aggregate nel ramo viola è in grado di calcolare aggregati globali:se una riga con un particolare ID prodotto viene visualizzata su un particolare thread del ramo viola, quel thread è garantito per vedere tutte le righe per quell'ID prodotto (e non l'altro thread lo farà).
La colonna di partizionamento di scambio comune è anche la chiave di unione per l'unione di unione, quindi tutte le righe che possono eventualmente unirsi sono garantite per essere elaborate dallo stesso thread (viola).
Un'ultima cosa da notare è che entrambi gli scambi sono preserva gli ordini (conosciuto anche come "unione"), come mostrato nell'attributo Ordina per nei suggerimenti. Ciò soddisfa il requisito di unione di unione che prevede che le righe di input siano ordinate sulle chiavi di unione. Nota che gli scambi non ordinano mai le righe da soli, possono semplicemente essere configurati per conservare ordine esistente.
Filo zero
La parte finale del piano di esecuzione si trova a sinistra dello scambio Gather Streams. Funziona sempre su un singolo thread, lo stesso utilizzato per eseguire l'intero piano seriale regolare. Questo thread è sempre etichettato come "Thread 0" nei piani di esecuzione ed è talvolta chiamato thread "coordinatore" (una designazione che non trovo particolarmente utile).
Il thread zero legge le righe dal lato consumer (sinistro) dello scambio Gather Streams e le restituisce al client. Non ci sono iteratori di thread zero a parte lo scambio in questo esempio, ma se ce ne fossero, verrebbero tutti eseguiti sullo stesso thread singolo. Nota che Gather Streams è anche uno scambio di fusione (ha un attributo Order By):

Piani paralleli più complessi possono includere zone di esecuzione seriale diverse da quella a sinistra dello scambio finale di Gather Streams. Queste zone seriali non vengono eseguite nel thread zero, ma questo è un dettaglio da esplorare un'altra volta.
Thread riservati e utilizzati rivisitati
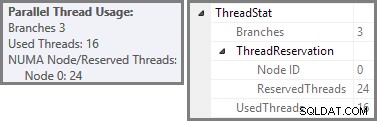
Abbiamo visto che questo piano parallelo contiene tre rami. Questo spiega perché SQL Server riservato 24 fili (tre rami a DOP 8). La domanda è perché solo 16 thread sono segnalati come "usati" nello screenshot qui sopra.
Ci sono due parti per la risposta. La prima parte non si applica a questo piano, ma è comunque importante conoscerla. Il numero di rami segnalati è il numero massimo che può essere eseguito contemporaneamente .
Come forse saprai, alcuni operatori del piano stanno "bloccando", il che significa che devono consumare tutte le loro righe di input prima di poter produrre la prima riga di output. L'esempio più chiaro di un operatore di blocco (noto anche come stop-and-go) è Ordina. Un ordinamento non può restituire la prima riga nella sequenza ordinata prima di aver visto ogni riga di input perché l'ultima riga di input potrebbe essere ordinata per prima.
Gli operatori con più input (join e sindacati, ad esempio) possono bloccare rispetto a un input, ma non bloccare ("pipeline") rispetto all'altro. Un esempio di questo è l'hash join:l'input di compilazione sta bloccando, ma l'input del probe è pipeline. L'input di compilazione si blocca perché crea la tabella hash rispetto alla quale vengono testate le righe del probe.
La presenza di operatori di blocco significa che uno o più rami paralleli potrebbero essere garantito per il completamento prima che altri possano iniziare. In questo caso, SQL Server può riutilizzare i thread utilizzati per elaborare un ramo completato per un ramo successivo nella sequenza. SQL Server è molto prudente riguardo alla prenotazione dei thread, quindi solo i rami sono garantiti per completare prima che ne inizi un altro, utilizza questa ottimizzazione della prenotazione del thread. Il nostro piano di query non contiene alcun operatore di blocco, quindi il conteggio delle filiali riportato è solo il numero totale di filiali.
La seconda parte della risposta è che i thread possono ancora essere riutilizzati se accadono da completare prima dell'avvio di un thread in un altro ramo. Il numero completo di thread è ancora riservato in questo caso, ma l'utilizzo effettivo potrebbe essere inferiore. Il numero di thread effettivamente utilizzati da un piano parallelo dipende, tra le altre cose, da problemi di temporizzazione e può variare tra le esecuzioni.
I thread paralleli non iniziano tutti a essere eseguiti contemporaneamente, ma anche in questo caso i dettagli dovranno attendere un'altra occasione. Esaminiamo nuovamente il piano di query per vedere come i thread potrebbero essere riutilizzati, nonostante la mancanza di operatori di blocco:
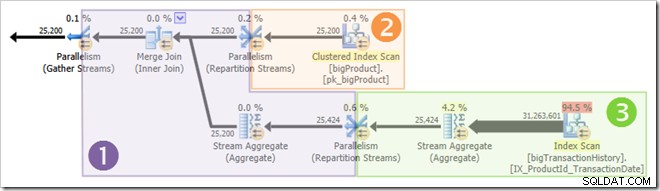
È chiaro che i thread nel ramo uno non possono essere completati prima che i thread nei rami due o tre vengano avviati, quindi non vi è alcuna possibilità di riutilizzo del thread lì. Anche il ramo tre è improbabile da completare prima dell'avvio del ramo uno o del ramo due perché ha così tanto lavoro da fare (quasi 32 milioni di righe da aggregare).
Il ramo due è un'altra questione. Le dimensioni relativamente ridotte della tabella dei prodotti indicano che esiste una discreta possibilità che la filiale possa completare il proprio lavoro prima si avvia il ramo tre. Se la lettura della tabella del prodotto non comporta alcun I/O fisico, non ci vorrà molto prima che otto thread leggano le 25.200 righe e le inviino allo scambio di flussi di ripartizione con limite arancione-viola.
Questo è esattamente ciò che è successo nelle esecuzioni di prova utilizzate per gli screenshot visti finora in questo post:gli otto fili del ramo arancione sono stati completati abbastanza rapidamente da poter essere riutilizzati per il ramo verde. In totale sono stati utilizzati sedici thread univoci, quindi questo è quanto riportato dal piano di esecuzione.
Se la query viene rieseguita con una cache a freddo, il ritardo introdotto dall'I/O fisico è sufficiente per garantire che i thread del ramo verde vengano avviati prima del completamento di qualsiasi thread del ramo arancione. Nessun thread viene riutilizzato, quindi il piano di esecuzione riporta che tutti i 24 thread riservati sono stati effettivamente utilizzati:
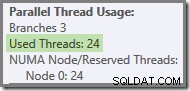
Più in generale, è possibile un numero qualsiasi di 'thread utilizzati' tra i due estremi (16 e 24 per questo piano di query):
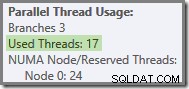
Infine, nota che il thread che esegue la parte seriale del piano a sinistra dell'ultimo Gather Streams non viene conteggiato nei totali dei fili paralleli. Non è un thread aggiuntivo aggiunto per consentire l'esecuzione parallela.
Pensieri finali
La bellezza del modello di scambio utilizzato da SQL Server per implementare l'esecuzione parallela è che tutta la complessità del buffering e dello spostamento delle righe tra i thread è nascosta all'interno degli operatori di scambio (parallelismo). Il resto del piano è suddiviso in ordinate "rami", delimitate da scambi. All'interno di una filiale, ogni operatore si comporta come in un piano seriale:in quasi tutti i casi, gli operatori della filiale non sono a conoscenza del fatto che il piano più ampio utilizza l'esecuzione parallela.
La chiave per comprendere l'esecuzione parallela è rompere (mentalmente) il piano parallelo ai confini dello scambio e rappresentare ogni ramo come DOP seriale separato piani, tutti in esecuzione simultanea su un distinto sottoinsieme di righe. Ricorda in particolare che ciascuno di questi piani seriali esegue tutti gli operatori in quel ramo:SQL Server non esegui ogni operatore sul proprio thread!
Comprendere il comportamento più dettagliato richiede un po' di riflessione, in particolare su come le righe vengono instradate all'interno degli scambi e su come il motore garantisce risultati corretti, ma poi la maggior parte delle cose che vale la pena sapere richiedono un po' di riflessione, vero?